
Wstęp
Dwa wieki temu Adam Smith ustanowił zasady architektoniczne, które określają sposób organizacji i funkcjonowania przedsiębiorstw. My przedstawiamy zupełnie nowy sposób myślenia o tym, jak przedsiębiorstwa powinny się organizować i funkcjonować w erze cyfrowej. Prezentujemy architekturę korporacyjną na przyszłość: architekturę, która rozpoznaje siłę powstającego środowiska technologicznego, umożliwia przedsiębiorstwom szybką reakcję do potrzeb rynku i innowacji oraz przewiduje takie potrzeby, wykrywając w czasie rzeczywistym ważne zmiany w środowisku wewnętrznym i zewnętrznym. Przedsiębiorstwa nieustannie starają się być wydajne i konkurencyjne na różne sposoby. Pod wpływem TQM i radykalnych zmian w inżynierii lat 80. i 90. XX wieku wiele przedsiębiorstw próbowało przyjąć orientację procesową jako klucz do wydajności i zróżnicowania konkurencyjnego. Jednak większość osiągnęła jedynie ograniczony sukces w zakresie wydajności procesu. Może to być w dużej mierze spowodowane tym, że w dzisiejszym
dynamicznym środowisku biznesowym statyczny i niereagujący charakter większości paradygmatów technologicznych hamuje znaczący postęp. W ostatnich latach zalew informacji cyfrowych, zwany Big Data, spotęgował to wyzwanie i otworzył przed firmami jeszcze jeden front, w którym można uwzględnić ich strategie. Większość przedsiębiorstw jest poważnie ograniczona z powodu niemożności zmiany swoich procesów w odpowiedzi na potrzeby rynku. Pomimo całej dbałości o zarządzanie procesami biznesowymi i orientację na procesy, firmy nadal borykają się z problemami czasu i elastyczności technologii. Technologia zamiast umożliwiania takich zmian stała się poważnym inhibitorem. Zmiana procesów biznesowych wbudowanych w aplikacje jest często długim, żmudnym procesem pełnym przekroczeń kosztów, przekroczonych terminów i awarii. Szybkie tempo przestarzałej technologii nadal wymaga specjalistycznego szkolenia i umiejętności oraz jeszcze bardziej zaostrzyło ten problem. Aby nadążyć za wymaganiami biznesowymi, firmy skłaniały
się ku pakietom aplikacji przynajmniej do tego, co postrzegali jako funkcje inne niż podstawowe, takie jak planowanie zasobów i rachunkowość finansowa. W przypadku większości przedsiębiorstw utrzymywanie niestandardowej aplikacji technologicznej jest zbyt drogie i trudne środowisko. Początkowo powszechnie uważano, że nowy światowy porządek biznesowy oznacza standaryzację procesów biznesowych, nawet poza funkcjami noncore. Argumentowano, że firmy będą dążyć do ujednolicenia procesów biznesowych z kilku powodów - w celu ułatwienia komunikacji, umożliwienia sprawnego przekazywania połączeń między granicami procesów oraz umożliwienia analiz porównawczych w podobnych procesach. Założono, że zrewolucjonizuje to, w jaki sposób firmy. Ale takie myślenie spowodowało, że przedsiębiorstwa zostały zmuszone do działania w granicach dominujących paradygmatów technologicznych. Zjawisko internetowe pojawiło się jeszcze na przełomie lat 80. i 90. Od połowy lat 90. Internet stał się wszechobecny w życiu osobistym
przedsiębiorstw i ludzi; tempo przepływu nowych informacji było i jest oszałamiające. Szybko rozwijający się Internet przedmiotów obiecuje nadać zupełnie nowy wymiar informacjom w niezwykłej skali. Jeśli dodamy wirusowe rozprzestrzenianie się mediów społecznościowych do nadmiaru informacji, korporacje staną przed ogromnym wyzwaniem i szansą inteligentnego wykorzystania bogactwa wiedzy i wglądu zawartych w takich informacjach. Jednak w ciągu ostatniej dekady przepaść między "technologią mów" a "biznesem mówienia" znacznie się zmniejszyła. Możliwość tworzenia i utrzymywania aplikacji technologicznych jest znacznie łatwiejsza. Era wysoce elastycznych, zorientowanych na proces ram oprogramowania, które umożliwiają korporacji konfigurowanie procesów biznesowych, jest teraz dostępna dla przedsiębiorstw. Jednocześnie pojawiła się zupełnie nowa klasa technologii, aby pomóc przedsiębiorstwom poradzić sobie z gwałtownym wzrostem ilości danych, a rozwój przetwarzania kognitywnego zapewnia szereg możliwości,
które umożliwią maszynom znacznie więcej niż przechowywanie i ułatwianie danych. Przedsięwzięcie jutra ma szansę być inteligentnym i wydajnym. Wymaga to ciągłego monitorowania i analizowania wewnętrznych i zewnętrznych zagrożeń i szans oraz dostosowywania procesów operacyjnych w celu przeciwdziałania takim zagrożeniom lub wykorzystywania szans. W ten sposób nie wystarczy przeanalizować ogromną ilość nieuporządkowanych informacji, które stały się dostępne. Inteligentne przedsiębiorstwo będzie musiało bezproblemowo zintegrować takie procesy analityczne z normalnymi procesami operacyjnymi. Te dwa światy nie są odrębne i dychotomiczne; raczej są część tego samego kontinuum. Bez zintegrowania tych dwóch zestawów procesów przedsiębiorstwa nie osiągną pożądanych rezultatów. Pamiętaj, że przedsiębiorstwa są dalekie od rozwiązania problemu szybkiego dostosowania procesów operacyjnych do dynamicznego środowiska biznesowego. Większość firm wciąż stara się zmusić swoje niezliczone systemy do komunikowania się ze
sobą, problemy z jakością danych wciąż ich dręczą, a lista jest długa. Te zmiany zapowiadają ogromną zmianę w sposobie, w jaki przedsiębiorstwa same się projektują i działają. Historyczne ograniczenia nieodpowiadających paradygmatów technologii będą teraz historią. Dzięki możliwości konfiguracji technologii aby sprostać potrzebom procesów biznesowych, przedsiębiorstwa będą mogły odejść od ciasno spakowanych aplikacji bez kosztów związanych z utrzymaniem niestandardowego oprogramowania. W połączeniu z możliwością potencjalnego zrozumienia nieustrukturyzowanych danych oprócz danych ustrukturyzowanych, przedsiębiorstwa mają możliwość myślenia zupełnie inaczej. Innym faktem jest to, że dzisiejsza architektura korporacyjna jest w dużej mierze skoncentrowana na ludziach. Ludzie byli w dużej mierze klejem do wykonywania procesów biznesowych w przedsiębiorstwie. W wielu przedsiębiorstwach ludzie pełnią funkcję koordynatorów procesów, a zwłaszcza w branżach opartych na wiedzy, ludzie często wykonują swoje
zadania ręcznie. Nadszedł czas, aby technologia stała się organiatorem procesów w przedsiębiorstwie, kontrolowała wykonywanie procesów biznesowych, umożliwiając coraz bardziej automatyczne wykonywanie powtarzalnych zadań. Ludzie będą mieli okazję skupić się na projektowaniu, a nie na powtórnym wykonaniu. Elastyczne ramy oprogramowania i umiejętność zrozumienia znaczenia nieustrukturyzowanych dokumentów zapewnią przedsiębiorstwom ogromną moc w projektowaniu całkowicie nowej architektury prowadzenia działalności gospodarczej. To jest nasza centralna idea. Mamy trzy części. Część I określa bardziej szczegółowo wyzwania, przed którymi stoją przedsiębiorstwa - wyzwania epoki cyfrowej, konieczność dostosowania się do coraz bardziej dynamicznego środowiska biznesowego, brak elastyczności systemów i niemożność zmiany procesów biznesowych w razie potrzeby, ograniczenia związane z pracą w ciasnych warunkach granice spakowanych aplikacji, wady dostosowywania spakowanych aplikacji, unieważniając w ten sposób ich
główne zalety, a także gwałtowny wzrost ilości informacji oraz powstałe przeciążenie i asymetria. Część II przedstawia architekturę inteligentnego przedsiębiorstwa. Jak przedsiębiorstwa powinny się projektować w erze cyfrowej? Czy technologia biznesowa jest wystarczająco dojrzała, aby umożliwić firmom dowolną konfigurację i ponowną konfigurację procesów biznesowych? Czy jesteśmy w punkcie, w którym firmy mogą digitalizować procesy biznesowe bez kosztów związanych z kosztownym tworzeniem i utrzymywaniem niestandardowego oprogramowania? W jaki sposób przedsiębiorstwa mogą systematycznie wykorzystywać dane wywiadowcze na podstawie tych wszystkich danych? Po pierwsze, jedna sekcja dotyczy wydajności i sprawności, koncentrując się na korzyściach i wyzwaniach przedsiębiorstwa zorientowanego na procesy. Wszyscy zdajemy sobie sprawę, że outsourcing oparty na arbitrażu pracowniczym wyraźnie nie stanowi odpowiedzi w perspektywie długoterminowej. Dyskusja poprowadzi Cię przez obecny stan technologii biznesowej i
powody, dla których nawet współczesne platformy i metody tworzenia oprogramowania nie zapewniają wydajności i sprawności przedsiębiorstwa muszą być konkurencyjne. Może to zabrzmieć zaskakująco, ale zwinne metody nie zapewnią szybkości i elastyczności, których potrzebują firmy. Żadna platforma oprogramowania oparta na modelu kodu z bogatym zestawem abstrakcyjnych komponentów opartych na modelu nie jest w stanie sprostać wyzwaniu związanemu z wydajnością i sprawnością. Zamiast tego taka platforma może umożliwić w czasie rzeczywistym elastyczne tworzenie oprogramowania i skrócić typowe cykle życia oprogramowania do ułamka tego, czym są inaczej. Dyskusja prowadzi czytelnika przez platformę opartą na modelu bez kodu, która sprawia, że tworzenie oprogramowania w czasie zbliżonym do rzeczywistego staje się rzeczywistością. Część 3 dotyczy wymiaru inteligencji ze szczególnym uwzględnieniem dużych zbiorów danych i sztucznej inteligencji. Celowo wykluczyłem dyskusję na temat wizji komputerowej ze względu na
przestrzeń i czas. Przedstawiono tu taksonomię problemów związanych z AI i ich wyniki w celu wyjaśnienia tego czytelnikowi. Poniżej przedstawiono przegląd popularnych metod rozwiązań AI. Starałem się zrównoważyć nauczanie, które jest zbyt techniczne, a jednocześnie zapewniłem czytelnikowi wystarczającą ilość szczegółów, aby docenić naturę tych metod. Odnosząc te metody z powrotem do taksonomii, mam nadzieję, że czytelnik rozwinie ogólne zrozumienie, w jaki sposób i gdzie AI jest korzystne. Dziewięćdziesiąt procent wzrostu zawartości w Internecie to tekst nieustrukturyzowany. Zwłaszcza, że odnosi się do obsługi języka naturalnego, w rozdziale poruszono ważną kwestię, że większość obecnych metod, platform i narzędzi, w tym IBM Watson i Google, opiera się na statystykach obliczeniowych i nie próbuje zrozumieć tekstu w języku naturalnym. w ogóle. W tej części przedstawiono czytelnikowi ramy inteligencji poznawczej, które próbują opisać język naturalny i zapewnić odpowiednie kontekstowo wyniki. Ponadto
należy dokonać kompromisu między metodami zapewniającymi rozwiązania czarnej skrzynki a metodami zapewniającymi identyfikowalne, odpowiednie kontekstowo rozwiązania. Ramy inteligencji poznawczej przedstawione w tym rozdziale nie są czarną skrzynką, a jej wyniki i rozumowanie są całkowicie identyfikowalne. Część 4 przedstawia architekturę dla przedsiębiorstwa wywiadowczego. Architektura integruje paradygmat architektoniczny oparty na meta-modelu oparty na braku kodu dla wydajności i zwinności z oraz ramy identyfikowalnej inteligencji poznawczej z .Powstała architektura będzie składać się z inteligentnych maszyn uczących się od ludzi i danych. Zasadniczo sugeruję, że w jutrzejszym przedsiębiorstwie aspekty wykonawcze firmy będą w dużej mierze obsługiwane maszynowo, przy czym ludzie będą kierowani przez maszyny, a aspekt projektowy firmy zostanie poinformowany o maszynie w wyniku inteligencji zgromadzonej przez maszyny. Przeglądam także wpływ takiej architektury na obecne miejsce pracy zorientowane na
ludzi. W szczególności ponownie omawiamy debatę o ludziach i maszynach oraz potencjalny wpływ inteligentnego przedsiębiorstwa na miejsca pracy. Część III przedstawia trzy studia przypadków z realnego świata, zawierające pomysły omówione w poprzednich sekcjach. Kolejna sekcja przedstawia architekturę nowej generacji dla firm doradczych w zakresie zarządzania majątkiem. Branża zarządzania majątkiem przeżywa gwałtowne zmiany sejsmiczne w związku z ogromną przemianą milenijną, uznaniem, że historyczny nacisk na dywersyfikację bez wyraźnego uwzględnienia potrzeb inwestorów jest nieoptymalny, a wzrost liczby doradców-robotów rzuca wyzwanie hegemonii dużych domów z drutu. Opisujemy elastyczną inteligentną platformę obejmującą inteligentne maszyny, które mogą umożliwić firmom doradczym ds. Bogactwa i doradcom przejście do wersji E4.0. Przedstawiamy aplikację do systematycznego wykorzystywania danych wywiadowczych w czasie rzeczywistym, aby umożliwić aktywnym podmiotom zarządzającym aktywami generowanie alfa
w celu uzyskania lepszych wyników na rynkach finansowych. Konsekwentne znajdowanie alfy to Święty Graal w świecie zarządzania aktywami. Niewiele sektorów w gospodarce jest dotkniętych tak fundamentalnie, jak świat inwestycji, przy ogromnym wzroście dostępności i przepływu informacji. Opisana aplikacja jest elastycznym kompleksowym rozwiązaniem, które obejmuje rozumienie języka naturalnego w celu inteligentnego przetwarzania ogromnych ilości informacji i identyfikowania ewentualnych nieefektywności. Przy takim podejściu aktywne zarządzanie aktywami przejdzie na E4.0. Kolejna część opisuje wykorzystanie inteligencji maszyn w zawodzie audytora. Przemysł ten jest gotowy na poważne zakłócenia. Proces audytu powierniczego i zapewniania jest dziś w dużej mierze ręczny i niewiele się zmienił od lat siedemdziesiątych. Rozwiązanie przedstawione w sekcji stanowi inteligentną architekturę dla firmy audytorskiej. Jak pokazuję w tej książce, dzisiaj istnieje fundamentalnie przekształcająca szansa na
wykorzystanie technologii, jak nigdy dotąd, w projektowaniu cyfrowej transformacji dowolnego przedsiębiorstwa. Okazja wkrótce stanie się koniecznością. Mam nadzieję, że główne idee pomogą liderowi biznesu lub technologii zobaczyć ogromne możliwości zmian. Prawdziwe rozwiązania i opcje, które ilustrują tę tezę, zostały przedstawione w studiach przypadków, pokazują, jak zrealizować te możliwości.
Kryzys nie minął…
Dziś żadna firma nie jest zadowolona z szybkości, z jaką może reagować na szybko zmieniające się warunki rynkowe. Dynamika konkurencji faktycznie się zwielokrotniła, a Internet generuje informacje w zadziwiającym tempie i dodaje kolejny wymiar do i tak już złożonego krajobrazu, z którym mają do czynienia firmy - informacje. Media społecznościowe ostatnio dołączyły do gry, zwiększając zarówno spektrum niekontrolowanego przepływu informacji, jak i możliwość bezpośredniego dotarcia do konsumentów, jak nigdy dotąd. Era radykalnej przebudowy została poprzedzona dwoma innymi ruchami zbiorowymi, mającymi na celu poprawę konkurencyjności, określanymi jako zarządzanie całkowitą jakością (TQM) i Six Sigma. Przeprojektowanie procesów biznesowych (BPR) było kolejną dramatyczną próbą wprowadzenia zmian w firmie. Firma BPR została opisana przez jej zwolenników jako "fundamentalne przemyślenie i przeprojektowanie procesów biznesowych w celu osiągnięcia radykalnej poprawy krytycznych miar wydajności, takich jak koszt, jakość, obsługa i szybkość". BPR zaoferował narzędzia do bardziej efektywnego działania firmy, dzieląc procesy biznesowe i identyfikując bardziej wydajne podejścia. Analizy tych procesów miały być kompleksowe i obejmowały różne dziedziny funkcjonalne. Argumentem było to, że grupy funkcjonalne z czasem staną się chroniące swoją trawę i nie będą informować w obawie, że zmiany mogą w pewnych okolicznościach doprowadzić do wyeliminowania ich kroków w tym procesie. Z pewnością brak widoku dużego zdjęcia procesu biznesowego przedsiębiorstwa często prowadzi do nieoptymalnych decyzji na poziomie funkcji, bez względu na wydajność całego procesu. Jednak strategia BPR zaproponowała analizę, której rezultatem byłoby ponowne złożenie procesu biznesowego w bardziej radykalnie wydajny sposób. Wśród kilku korporacji, które entuzjastycznie przyjęły BPR i procesy Six Sigma, były Motorola i General Electric. Chociaż nie można zaprzeczyć, że Six Sigma uświadomiła ,że jakość procesu i dokładny pomiar, badanie, modelowanie, gromadzenie, a następnie wdrażanie optymalnych procesów trwało zbyt długo. Było to korzystne tylko w operacjach biznesowych, w których istnieje względna stabilność, i że w dzisiejszym szybkim świecie znaczna rzadkość. Chociaż odnotowano kilka znaczących sukcesów, ogólnie rzecz biorąc, reengineering nie znalazł takiego sukcesu, jaki sugerowałaby niekontrolowana popularność książki z 1994 roku. Hallmark podobno całkowicie przeprojektował proces nowego produktu, a Kodak przeprojektował czarno-biały film, aby skrócić o połowę czas reakcji firmy na nowe zamówienia. Krytycznym niepowodzeniem ruchów BPR i TQM w tym czasie był brak wyrafinowanych paradygmatów technologii. Bez paradygmatów technologicznych zgodnych z myślami stojącymi za BPR lub TQM, nie było realnej szansy na powszechny sukces. Chociaż zwolennicy BPR, w tym Champy i Hammer, uznali technologię za czynnik umożliwiający, nie uznali technologii za kluczowy czynnik umożliwiający przeprojektowanie. Ich pogląd na nowy świat pracy koncentrował się na reorganizacji procesów biznesowych z dala od mentalności silosu - jednej osoby wykonującej proces biznesowy od końca do końca zamiast tworzenia zespołu różnych osób skupionych na różnych aspektach tego procesu. Najprawdopodobniej systemowi przeciwnicy BPR wyrzucili wizjonerskie pomysły lub sprowadzili je do zwykłych gier. Spośród wielu innych przeszkód najbardziej rozpowszechnionym inhibitorem był i nadal jest fragmentaryczny, nieelastyczny, kosztowny, niereagujący krajobraz technologii biznesowej, który leży u podstaw wszystkich kluczowych procesów biznesowych, na których działają duże organizacje. W rzeczywistości najlepsi liderzy biznesu i genialni technolodzy muszą z powodzeniem obejść to obciążenie i realizować cele transformacji biznesowej, pomimo ograniczenia technologii, która dopiero niedawno była uważana za zmianę gry. Poniższe studia przypadków oparte są na prawdziwych doświadczeniach. Pokazują, w jaki sposób to wyzwanie poprawiło uruchomienie nowych firm, generowanie przychodów z istniejących firm, zadowolenie klientów i wydajność operacyjną.
Studium przypadku 1: Wdrożenie klienta do usług opieki zdrowotnej
Jeden z największych zewnętrznych administratorów świadczeń opieki zdrowotnej usiłował skalować się, aby zaradzić zmienności systemów klienckich i skutecznie je wdrożyć
• Czas wdrożenia u klienta ,jednego z największych zewnętrznych administratorów ,list płac i świadczeń był dłuższy niż 90 dni.
• Wdrożenie u nowych klientów nie było możliwe dla około trzech kilka miesięcy w roku, podczas gdy dotychczasowi klienci musieli przechodzić coroczne odnowienia.
• Proces ten był wielokrotnie badany przez każdego nowego lidera biznesu, przeprojektowany, częściowo offshorowany przez lata, wprowadzono nowe systemy informatyczne, ale 90-dniowa bariera pozostała nie do pokonania.
• Wdrożenie u każdego klienta było projektem rozwoju oprogramowania; to samo dotyczyło każdej zmiany w istniejących klientach.
• Wynikająca z tego roczna utrata przychodów w wysokości 25% od nowych klientów i niedopuszczalne wrażenia dla obecnych klientów były stałym źródłem znacznej frustracji w branży.
• Firma rutynowo traci klientów.
Najbardziej opłacalna alternatywa. Kontynuuj ukierunkowywanie usprawnień procesów za pomocą projektów Six Sigma i identyfikuj ulepszenia wydajności. Zaakceptuj 25% wskaźnik rezygnacji z dochodów.
Studium przypadku 2: Wprowadzenie nowego produktu globalnej firmy usług finansowych dla jej klientów
Wprowadzenie nowego produktu było kluczowym elementem jego przyszłej strategii wzrostu i było wrażliwe na czas.
• Firma zainwestowała znaczne środki w działania związane z generowaniem popytu, co doprowadziło do uruchomienia.
• Była to transakcja związana z zaciąganiem pożyczek, wymagająca całkowicie zautomatyzowanej platformy klasy korporacyjnej.
• Sześć miesięcy przed uruchomieniem firma utknęła w martwym punkcie jeszcze przed uruchomieniem. Podstawowa struktura technologii procesowej trwała zbyt długo, aby przygotować produkcję.
• Sygnały przed wprowadzeniem na rynek wskazywały na znaczące dostosowania specyfikacji produktu. Aplikacja, na którą liczyła organizacja, została już dostosowana poza punkt krytyczny i przypominała starszą aplikację przed pierwszym dniem produkcji.
Droga do przodu. Zamknij projekt lub zapewnij dodatkowe fundusze na rozpoczęcie działalności, poinformuj rynek o 18-miesięcznym opóźnieniu, opracuj zestaw jasnych wymagań (które pozostaną stabilne w tym 18-miesięcznym okresie) i zaangażuj nowego partnera technologicznego.
Studium przypadku 3: Największa na świecie firma zarządzająca majątkiem, która chce przekształcić swoje usługi dotyczące klientów i doradców finansowych poprzez modernizację raportowania wyników końcowych
Firma musiała poprawić jakość obsługi klienta, aby utrzymać swoich cenionych klientów.
• Narzędzia do raportowania i analizowania wydajności, uzupełnione wewnętrznie opracowanymi rozwiązaniami punktowymi, były niezawodne i solidny, ale nieelastyczny i przestarzały.
• Dwóch zewnętrznych dostawców, którzy otrzymywali wyciągi z portfela od wielu depozytariuszy, ręcznie wprowadzało dane z wyciągów papierowych, często o długości ponad 500 stron.
• Liczba pracowników outsourcingowych rosła szybko, ponieważ firma oferowała swoim klientom szersze usługi raportowania wielostronnego.
• Raporty od wielu powierników były generowane raz na kwartał i były dostępne 45 dni po zakończeniu kwartału, przy czym transakcje dokonane podczas kwartału były zgłaszane gdziekolwiek między 45 a 135 dniem opóźnienia, co czyni je bezużytecznymi.
• Narażenie regulacyjne z minimalnie zarządzanych procesów zlecanych na zewnątrz i utrata krytycznej dla misji nieudokumentowanej wiedzy plemiennej z nieplanowanym zniszczeniem rosła.
Droga do przodu . Utrzymaj koszty operacyjne na płasko, przenosząc zasoby do lokalizacji o niskich kosztach, skróć czas cyklu poprzez obsadzenie personelu, zarządzaj jakością procesów i ryzykiem regulacyjnym poprzez wdrażanie procesów zarządzania dotykiem. Było to ustawienie nieskalowalne. Koszt operacji lub transakcje rosły, ponieważ wzrost liczby błędów przewyższał wszelkie korzyści skali. Lub zaoferuj raportowanie wielostronne mniejszej liczbie klientów, co zniweczyłoby znaczącą przewagę konkurencyjną firmy.
Studium przypadku 4: Zmieniające się na rynku pozyskiwanie przez globalną korporację
Zgodnie z normą wartość transakcji zakładała bezproblemową i udaną integrację przejmowanej firmy oraz uzyskanie wszystkich wynikających z tego synergii.
• Firma przejmująca posiadała 800 głównych aplikacji informatycznych i niezliczone rozwiązania punktowe rozmieszczone w kilku warstwach sedymentacyjnych przez ponad czterdzieści lat lub dłużej.
• W tym czasie każdy kolejny CIO odziedziczył coraz bardziej złożone środowisko z misją standaryzacji, uproszczenia i ustanowienia IT jako strategicznego zasobu dla firmy, ale ostatecznie wiążąc ekosystem aplikacji w coraz ściślejszych węzłach, z powodu sił niezależnych od nich. Gotowe rozwiązania stały się odporne na uaktualnienia.
• Przejęta firma była znacznie mniejsza i posiadała 150 dużych aplikacji. Plan migracji został zaksięgowany przez zbieżne księgi rachunkowe w dniu 1 oraz zintegrowany proces od zamówienia do zapłaty do dnia 365.
Droga do przodu . Plany integracji opracowane przez zespół fuzji i przejęć przy ograniczonym wkładzie technologicznym muszą zostać ponownie zaplanowane od podstaw. Analiza kursowa przeprowadzona przez doświadczony zespół technologiczny firmy przejmującej wykazała, że rozmieszczenie 150 głównych aplikacji w przejmowanej firmie (niezależnie od tego, czy są one zachowane w stanie niezmienionym, zachowane, ale zmodyfikowane, migrowane lub zamknięte) zajęłoby co najmniej pięć lat, gdyby były utrzymane, silny i kaskadowy sponsoring (kadra, finansowanie) w tym okresie, nawet gdy pojawiły się inne priorytety i zmieniło się przywództwo. Żadna z firm nigdy nie doświadczyła niczego zbliżonego do tego. Gdy technologia była ukierunkowana na znaczące cele synergii po przejęciu w pierwszym roku, nawet najbardziej entuzjastyczni członkowie zespołu byli sceptyczni.
Domyślna ścieżka naprzód pokazana dla każdej firmy była prawdopodobnie najlepszym wyborem w danych okolicznościach. Poza tymi przykładowymi przykładami większość inicjatyw związanych z transformacją biznesu jest chroniona, hamowana przez starszą infrastrukturę aplikacji technologicznych, pomimo posiadania najnowszego zarządzania procesami biznesowymi [BPM] oraz innych platform i narzędzi.
Wyzwania związane z obecnymi paradygmatami technologii: chroniczne problemy z czasem wprowadzenia na rynek i elastycznością
Cztery przykłady z życia w poprzedniej sekcji obszernie ilustrują chroniczne wyzwania związane z czasem wprowadzenia na rynek i elastycznością technologii biznesowej. Duże przedsiębiorstwa obfitują w kadrę kierowniczą, sfrustrowaną niezdolnością technologii do sprostania ich wymaganiom. Aplikacje opracowane 20 i 30 lat temu wciąż napędzają znaczną część naszego świata biznesu, nawet jeśli większość otaczających ich rzeczy została wymieniona, odnowiona i opracowana na nowo, w tym sprzęt, na którym działają. Niestety niewiele dużych korporacji ma luksus cofania przeszłości i rozpoczynania od czystej listy technologii. Plany dla nowych firm i plany ambitnej transformacji muszą opierać się na istniejącej, wcześniejszej infrastrukturze aplikacji, która jest wstępnie obciążona następującymi wyzwaniami:
• Nieaktualne starsze aplikacje oparte na przestarzałej technologii obsługującej krytyczne procesy biznesowe, w których koderzy / programiści nie są już dostępni.
• Wiele standardów danych i technologii. Wyjątkowo duży spis narzędzi i aplikacji oraz wynikowa nieoptymalna baza dostawców.
• Gotowe, spakowane rozwiązania, które zostały spersonalizowane poza ich przeznaczeniem i są teraz nowymi aplikacjami starszymi, odpornymi na aktualizację i kilkoma wersjami.
• Wewnętrzne rozwiązania punktowe, które zostały opracowane z wielką intencją, po prostu dodały jeszcze jednego punktu awarii w już wrażliwym środowisku.
• Odpady IT z poprzednich zakupów, które nigdy nie zostały w pełni zintegrowane.
• Firma, która wymaga coraz szybszego reagowania, a IT jest pozbawiona praw.
• Koszty IT są nieproporcjonalnie wysokie.
Nasz krajobraz technologii biznesowych nadal wygląda jak czarno-biały film. Jesteśmy dalecy od posiadania responsywnych aplikacji biznesowych. Nieodpowiadające aplikacje nie mogą obsługiwać środowiska o wysokiej entropii. Dlaczego tak jest? Wyzwanie polega na niezdolności obecnych paradygmatów technologii do spełnienia wymagań dotyczących szybkiego wdrożenia technologii w celu operacjonalizacji działań biznesowych lub strategii. Więc jakie są największe przeszkody, które należy rozwiązać, aby umożliwić znacznie bardziej responsywną architekturę biznesową. Technologia biznesowa musi stawić czoła czterem wyzwaniom, aby umożliwić efektywną architekturę korporacyjną - niezawodność, elastyczność, czas wprowadzenia na rynek i wiedzę. W ciągu ostatnich trzech lub czterech dekad niezawodność została w dużej mierze rozwiązana. Dzisiaj, jeśli szczegółowe specyfikacje zostaną dostarczone wykwalifikowanemu zespołowi technologicznemu, zespół dostarczy niezawodne aplikacje. Istnieje wielu wykwalifikowanych programistów i architektów, którzy mogą dostarczyć stały zestaw specyfikacji. Wraz z pojawieniem się takich standardów, jak Model zdolności do określania zdolności (CMM) i dostępność solidnych baz danych, stosy oprogramowania typu open source stały się kluczowymi czynnikami umożliwiającymi osiągnięcie niezawodności. Jednak elastyczność w zakresie zaspokajania zmieniających się potrzeb biznesowych i czasu wprowadzania na rynek pozostaje znaczącym wyzwaniem. Żadna specyfikacja biznesowa nigdy nie jest kompletna. Żaden ekspert, bez względu na to, jak dobry jest, nie może wyrazić swojej wiedzy specjalistycznej na kilku posiedzeniach. Wiedzę ekspercką można podzielić na wiedzę łatwą do odzyskania i trudną do zdobycia, która pojawia się we właściwym kontekście. Elastyczność w zakresie tego, czego nie znasz, jest znaczącym wyzwaniem w obecnych paradygmatach technologicznych. Większość aplikacji korporacyjnych zajmuje od 12 do 24 miesięcy od rozpoczęcia do pierwszego wdrożenia i często w ograniczonym zakresie. Tak długi cykl często powoduje, że nowa funkcjonalność staje się przestarzała, nawet zanim nowa aplikacja jest gotowa. Czas na wprowadzenie na rynek to ogromne wyzwanie, ponieważ szybkość wdrożenia jest odwrotnie proporcjonalna do elastyczności. Jeśli chcesz znacznej elastyczności, zajmuje to więcej czasu, niż myślisz. Wreszcie wiedza jest stosunkowo nowym wymiarem. Odnosi się do zdolności do proaktywnej analizy ogromnej ilości ustrukturyzowanych i nieustrukturyzowanych danych, którymi dysponujemy, oraz zapewnia wgląd w proaktywne działania. Dlaczego zbudowanie i wdrożenie solidnej aplikacji klasy korporacyjnej zajmuje od 12 do 24 miesięcy? Główna przyczyna leży w metodach, których używamy do tworzenia aplikacji. Każdy stos technologii aplikacji ma trzy segmenty - technologię tworzenia aplikacji (AD), metodologię i infrastrukturę. Infrastruktura poczyniła ogromne postępy i doprowadziła do powstania dwóch pozostałych wymiarów. Pojawienie się "chmury" i możliwość zapewnienia infrastruktury na żądanie w mniejszym lub większym stopniu wyeliminowało infrastrukturę jako wąskie gardło. Podczas gdy dzisiejsze technologie tworzenia aplikacji są znacząco ulepszene w porównaniu z technologiami nawet 5-10 lat temu, miały niewielki wpływ na ogólny czas, jaki upłynął dla aplikacji. Pojawiło się wiele platform technologicznych, takich jak Java, J2EE, Spring / Hibernate, .Net., Java Script i wiele narzędzi typu open source. Dzięki temu programowanie jest łatwiejsze i często szybsze. Nie miały one jednak wielkiego wpływu na upływający cykl ze względu na podstawowy charakter stosowanej metodologii. W konwencjonalnym cyklu rozwoju oprogramowania programowanie jest w rzeczywistości etapem tłumaczenia bez wartości dodanej w procesie tworzenia oprogramowania
Pojawienie się aplikacji w pakiecie
Nastąpiła także znacząca zmiana w środowisku AD od lat 90. XX w., Głównie komercyjne oprogramowanie pakowane zyskuje na popularności, takie jak aplikacje ERP, takie jak SAP i Oracle. Tak powszechne stosowanie aplikacji w pakiecie było w dużej mierze spowodowane długością czasu potrzebną do zbudowania aplikacji wewnętrznych i szybkimi zmianami w krajobrazie technologicznym, z którymi organizacje wewnętrzne nie były w stanie dotrzymać kroku. Istnieją jednak także ogromne luki między takimi aplikacjami a sposobem prowadzenia działalności przez przedsiębiorstwa. Większość luk dotyczyła braku orientacji na procesy biznesowe w tych aplikacjach. Dlatego oprogramowanie nie zapewnia elastyczności, z której można korzystać po wyjęciu z pudełka i wymagało znacznych i kosztownych dostosowań. Co więcej, dostosowania wymagają obszernego programowania i często zajmują zbyt dużo czasu. Oprogramowanie do zarządzania procesami biznesowymi (BPM) pojawiło się dopiero w ostatnim dziesięcioleciu, aby wypełnić lukę między aplikacjami w pakiecie a potrzebami przedsiębiorstwa w zakresie procesów biznesowych. Początkowo pakiety BPM zapewniały obsługę wyjątków i funkcjonalność przepływu pracy. Nawet dzisiaj oferują one bardzo szczegółowe wsparcie dla procesów biznesowych w przedsiębiorstwach. Ponieważ większość z tych pakietów nie została zaprojektowana do obsługi procesu od podstaw i od końca do końca, upłynie trochę czasu, zanim osiągną one drobnoziarnistą elastyczność w rozwiązaniu problemu dynamicznego charakteru potrzeb biznesowych. Chociaż istnieje duża liczba dostawców oprogramowania BPM, większość z nich zasadniczo nie zajęła się elastycznością i czasem wprowadzania problemów na rynek. Oprogramowanie BPM nie jest tanie, szybkie ani elastyczne, chyba że pasuje do gotowego rozwiązania oferowanego przez dostawcę oprogramowania BPM i rzadko jest tak ścisłe. Niezmiennie, biorąc pod uwagę gruboziarniste wsparcie dla procesów biznesowych przez wszystkie obecne BPMS, wdrożenie zazwyczaj wymaga dużej ilości konwencjonalnego programowania. Oczywiście wynikiem jest długi cykl wdrażania i brak elastyczności. Przejście na aplikacje w pakiecie wiązało się jak dotąd z kosztem. Odebrało to zdolności przedsiębiorstwa do konkurowania. Jest to szczególnie dotkliwe w usługach finansowych, w których proces biznesowy jest produktem. Wyjaśnia to, dlaczego firmy świadczące usługi finansowe nadal budują we własnym zakresie stosunkowo wysoki poziom aplikacji. Pakiety aplikacji do podstawowej rachunkowości i innych funkcji prowadzenia dokumentacji, które są statyczne bez możliwości tworzenia przewagi konkurencyjnej, są całkiem zrozumiałe. Jednak aplikacje w pakiecie stają się aplikacjami starszymi od momentu ich wdrożenia, chyba że oferują znaczną elastyczność, którą można dostosować do potrzeb przedsiębiorstwa. Dlatego nawet dziś aplikacje stają się bardziej elastyczne, w większości zapewniają klientom ograniczoną elastyczność. Przejście na aplikacje pakietowe może być przyznaniem się do porażki przez biznesmenów i technologów ze względu na ich niezdolność do dostarczania technologii zgodnej z potrzebami biznesowymi. Chociaż rozsądne może być kupowanie rozwiązań pakietowych zamiast zatrudniania eksperta do tworzenia oprogramowania od zera, ostatecznym celem powinna być możliwość dostosowania lub skonfigurowania takiego rozwiązania w celu dostosowania go do zmian potrzeb biznesowych
Nowy front: informacja, Big Data nie jest nowy, nowością jest informacja nieustrukturyzowana
Ogromny niewykorzystany potencjał strategiczny i operacyjny ukryty w zasobach informacji i wiedzy w cyberprzestrzeni to najnowszy nowy wymiar, który wpłynie i ukształtuje architekturę przedsiębiorstwa w przyszłości. Oferuje kuszące możliwości inteligentnej architektury korporacyjnej w czasie rzeczywistym. Technologia uwalniająca potencjał dużych zbiorów danych i sprawiająca, że jest praktyczna i ma zastosowanie w tworzeniu nowej wartości dla starych (i nowych) firm, jest wciąż w powijakach i opóźnia szum wokół dużych zbiorów danych z dużej odległości. Analityka predykcyjna (statystyczna analiza przeszłości w celu prognozowania przyszłości) istnieje od dziesięcioleci i stanie się jeszcze potężniejsza, ponieważ będzie wskazywać na coraz większe, ale ustrukturyzowane dane. Analizy mediów społecznościowych, nowsze zjawisko, pobudziły wyobraźnię i inwestycje organizacji, które chcą poznać opinię publiczną na temat swoich produktów, marki lub firmy w oparciu o rozmowy na platformach społecznościowych, a następnie za pomocą tych samych mediów do kierowania opinii lub podejmij inne działania. Istnieje również szybko rosnąca populacja naukowców zajmujących się danymi, którzy mają za zadanie oswajanie dużych zbiorów danych poprzez stosowanie matematyki, wspierane przez organizację. To, co nadal pozostaje poza zasięgiem analizy predykcyjnej, podstawowego słuchania w mediach społecznościowych i lekko uzbrojonych naukowców zajmujących się danymi, to ogromny i wykładniczo rosnący wszechświat nieustrukturyzowanych danych, zarówno na zewnątrz, jak i wewnątrz murów korporacyjnych. Jak zauważono w badaniu IDC Digital Universe Study sponsorowanym przez EMC Inc., 90% wszystkich danych było nieuporządkowanych, a biorąc pod uwagę ówczesną technologię, głównie niedostępnych dla przetwarzania maszynowego. Branża technologii dużych zbiorów danych rozwija się w szybkim tempie od 40 do 60%, w zależności od źródła, któremu ufasz. Jednak ponad 80% tych wydatków jest przeznaczone na infrastrukturę, pamięć masową i bazy danych. Tylko 20% tej inwestycji jest przeznaczone na aplikacje biznesowe dla dużych zbiorów danych (wikibon, 2012). Z 20% tylko niewielka część koncentruje się na wykorzystaniu największej możliwości dużych zbiorów danych - analizie nieustrukturyzowanych danych. Fakt, że produkujemy informacje w tempie, które od dawna przewyższa możliwości przetwarzania ludzi, doprowadził nas nawet do stosowania słów i zwrotów, takich jak "szum", "paplanina" i "przeciążenie informacją", aby opisać to zjawisko o niskim stosunku sygnału do szumu, tak jakby problem był w jakiś sposób związany z informacją, a nie z naszą zdolnością radzenia sobie z nią. Większość przedsiębiorstw stara się jednocześnie uzyskać dostęp do informacji pochodzących z tak ogromnej ilości nieuporządkowanych danych i wykorzystać je. Podczas gdy pośpiech do dużych zbiorów danych przyciągnął najlepsze umysły i duże pieniądze, pozostawanie na czele i odkrywanie znaczenia w oceanie niepowiązanych fragmentów informacji, pojawiających się nieustannie i dostępnych 24 godziny na dobę przez cały czas rosnących ilości, okazało się być przeważnie przegrana bitwa o pionierów. Czołowi analitycy branżowi sugerują, że hype i obietnica związana z dużymi zbiorami danych przeważnie ustąpiła miejsca mniej ambitnemu wewnętrznemu ukierunkowaniu w dużych korporacjach w dającej się przewidzieć przyszłości. Poszukiwanie wglądu w wewnętrzne dane strukturalne sprawiło, że wykorzystano potencjał świata nieustrukturyzowanych informacji "tam" na kolejny dzień.
Architektura korporacyjna: obecny stan i implikacje
Zasadnicze znaczenie dla kwestii konkurencyjności przedsiębiorstw ma pytanie, w jaki sposób przedsiębiorstwa organizują się i konkurują? Taka architektura korporacyjna ma zasadnicze znaczenie dla problemów przedstawionych powyżej i może ulec głębokiej transformacji w miarę pojawiania się rozwiązań wyżej wymienionych problemów. Post Adam Smith architektura korporacyjna oparta była na zasadzie podziału pracy i koncentrowała się na wyspecjalizowanych funkcjach. Każda funkcja miała stać się wysoce kompetentna i zapobiegać fragmentacji umiejętności w zakresie wytwarzania produktu końcowego na dużą skalę. W epoce nowożytnej ze znacznie płaskim światem i wszechobecnym wpływem technologii było wielu zwolenników procesu biznesowego i architektury centrycznej. Hammer i Champy zdecydowanie wyrazili swoje stanowisko w swojej zasadniczej pracy w 1993 roku. Dużo dyskutowano na temat tego, czy przedsiębiorstwo powinno być zorganizowane według funkcji czy procesu. Wszystkie te struktury sugerują jednak, że architektura jest "prowadzona przez ludzi". Ludzie są w centrum organizacji i realizacji pracy. W związku z tym możemy myśleć o architekturze przedsiębiorstwa jako o projekcie / strategii i wykonaniu. Procesy biznesowe są projektowane przez ludzi posiadających niezbędną wiedzę fachową i odzwierciedlają ich wizję, wiedzę i ogólną misję organizacji. Po zaprojektowaniu i wdrożeniu wszystkich komponentów, wszystkie odpowiednie transakcje biznesowe stanowią wielokrotnie wykonywany proces biznesowy.
Inteligentne przedsiębiorstwo jutra
Postęp technologiczny, gwałtowny wzrost informacji i pojawienie się natychmiastowej komunikacji wirusowej połączyły się, tworząc dynamicznie zmieniające się środowisko dla przedsiębiorstw. Ma to dalekosiężne konsekwencje dla samego projektu architekta. Uważamy, że aby przedsiębiorstwa odniosły sukces w takim środowisku, muszą od nowa przemyśleć każdy aspekt swojej działalności. Rzeczywiście może się zdarzyć, że podstawowe podejście do architektury korporacyjnej "kierowane przez ludzi" powinno się zmienić, aby umożliwić maszynom pełnienie większej roli w architekturze korporacyjnej. Jaką rolę mogą odgrywać maszyny w architekturze? Z pewnością będzie się to różnić w zależności od branży i firmy, ale nie ma wątpliwości, że maszyny będą coraz bardziej przejmować rolę wykonawczą. I w coraz większym stopniu będą pomagać ludziom w aspekcie projektowym dzięki zgromadzonej inteligencji, której ludzie po prostu nie mogą zebrać samodzielnie. Niemniej jednak maszyny będą musiały zostać poinstruowane przez ludzkich
ekspertów w zakresie gromadzenia takiej inteligencji, a takie instrukcje będą musiały być stale monitorowane i dostosowywane. Takie są wyzwania omówione w tej książce. W kolejnych sześciu rozdziałach staramy się nakreślić, jaką formę przyjęłaby optymalna architektura dla inteligentnego przedsiębiorstwa.
Wydajność i zwinność
WPROWADZENIE
Większość przedsiębiorstw stara się być bardziej wydajna i zwinna w reagowaniu na zmieniające się wymagania swoich klientów i zmieniającą się dynamikę otoczenia biznesowego. Jednak w dzisiejszym połączonym świecie prawdziwym kluczem do osiągnięcia wydajności i sprawności jest skuteczne wykorzystanie technologii. Jak omówiono w poprzednim rozdziale, technologia jak dotąd nie zapewniła wydajności i sprawności, której większość firm oczekuje i potrzebuje. W tym rozdziale omawiamy nasze kroki poprzez ewolucję paradygmatu technologii, który może umożliwić elastyczne tworzenie oprogramowania w czasie rzeczywistym. Wierzymy, że zapoczątkuje to erę niespotykanej szybkości i szybkości reakcji.
PRZEDSIĘBIORSTWO ZORIENTOWANE W PROCESIEM
W prasie popularnej toczy się znaczna dyskusja na temat zalet organizacji zorientowanych na procesy. Obecnie większość firm uważa, że aby być konkurencyjnym i wydajnym, musi być zorientowana na proces pod względem struktury organizacyjnej, zamiast organizować z funkcjonalną orientacją. Wiele korporacji jest nadal zorganizowanych w sposób funkcjonalny, hierarchiczny. Są one zorganizowane hierarchicznie w obszarach funkcjonalnych, takich jak sprzedaż, marketing, finanse lub produkcja. Odzwierciedlają wagę przywiązywaną do umiejętności w wewnętrznie ukierunkowanym spojrzeniu na zarządzanie organizacyjne. Ta struktura korporacyjna pojawiła się w rewolucji postindustrialnej, gdy duże korporacje posunęły podział pracy i specjalizację w celu ujednolicenia procesów produkcyjnych i utrzymania konkurencyjnych korzyści skali. Powszechnie wiadomo, że taka struktura organizacyjna zapewnia spójność w wytwarzaniu towarów i rozpowszechnianie standardów w ramach tej funkcji. W organizacjach koncentrujących się na poprawie korzyści skali, implikacje międzyfunkcyjne są rozpatrywane na wyższych szczeblach zarządzania w organizacji. Jednak takie organizacje często tworzą funkcjonalne silosy w swoich strukturach. Takie organizacje, z kilkoma wyjątkami, często zapewniają klientom mniej niż optymalne doświadczenia. Wynika to z faktu, że organizacja nie ma holistycznego nacisku na zapewnienie wyjątkowej obsługi klienta. Często zdarzają się awarie w przekazywaniu podczas wykonywania procesu między obszarami funkcjonalnymi, co powoduje mieszanie w celu ochrony doświadczenia klienta. Podczas gdy organizacje zorientowane na funkcje umożliwiły przedsiębiorstwom skalowanie w erze rewolucji postindustrialnej, pojawienie się Internetu wraz z postępami w dziedzinie komunikacji mobilnej i technologii wyraźnie pokazały słabości organizacji zorientowanej na funkcje. W tym płaskim, dynamicznym świecie zdolność do dostosowywania i wprowadzania innowacji w procesach biznesowych stała się kluczowa dla utrzymania przewagi konkurencyjnej. Kluczową cechą organizacji zorientowanej na procesy są natomiast procesy biznesowe. Hammer i Champy określają proces biznesowy następująco:
…Zbiór działań, które wymagają jednego lub więcej rodzajów danych wejściowych i tworzą wyniki, które są wartościowe dla klienta.
Thomas Davenport (1993) definiuje proces bardziej zwięźle:
Po prostu ustrukturyzowany, mierzony zestaw działań zaprojektowanych w celu uzyskania określonej produkcji dla konkretnego klienta na rynku. Oznacza to duży nacisk na sposób wykonywania pracy w przedsiębiorstwie, w przeciwieństwie do nacisku skoncentrowanego na produkcie na czym. Proces jest zatem specyficznym uporządkowaniem czynności roboczych w czasie i miejscu, z początkiem, końcem i jasno określonymi danymi wejściowymi i wyjściowymi: strukturą działania.
W definicji procesu Davenporta istnieje kluczowe rozróżnienie między "sposobem wykonywania pracy" a "tym, co jest wykonywane". "Proces" jest dokładniej ograniczony do "jak". W obu interpretacjach kładziony jest wyraźny nacisk na ostateczną wartość dla klienta. Rummler i Brache rozszerzają definicję, wprowadzając rozróżnienie między procesami podstawowymi a procesami wsparcia w oparciu o to, czy wartość klienta jest bezpośrednio dostrzegalna w procesie, niezależnie od tego, czy jest ona jednak niezbędna. Nasza definicja procesu biznesowego jest znacznie bardziej całościowa. Definiujemy firmę (lub korporację) jako zbiór procesów o odpowiednich celach wobec interesariuszy (klientów, pracowników, inwestorów, organów nadzoru itp.). Naszym zdaniem proces jest zdefiniowaną sekwencją działań biznesowych z parametrami wejściowymi i wyjściowymi dla każdego zadania oraz z jasno określonymi celami w odniesieniu do interesariusza. Proces ten dotyczy zarówno "jak" zadań do wykonania, jak i "jakie" zadań do wykonania. Uważamy, że "co" w większości przypadków nie da się oddzielić od "jak", ponieważ często "co" określa cele "jak" w procesie. W ten sposób w definicji procesu nie brakuje celu i pomiaru. Nie definiujemy procesu synonimicznie z przepływem pracy, ponieważ znacznie osłabia to definicję procesu poprzez ignorowanie "pracy" w procesie lub głównych zadań biznesowych procesu. Nasza definicja procesu jest bardziej kompleksowa i obejmuje zarówno "pracę", jak i "przepływ pracy" związany z procesem. Każdy proces biznesowy w organizacji zorientowanej na procesy zazwyczaj należy do "właściciela procesu". Zespoły procesowe kierowane przez właściciela procesu będą obejmować członków z różnych grup umiejętności lub grup funkcyjnych i będą mieli pełny widok. Dlatego zespoły procesowe koncentrują się na ostatecznych celach procesu, niezależnie od tego, czy chodzi o dostarczenie doświadczenia klienta, czy, powiedzmy, o gotówkę. Zorientowana na proces struktura organizacyjna eliminuje funkcjonalne silosy i ułatwia konwergencję w kierunku celu procesu. Nie ma tarcia między różnymi grupami funkcjonalnymi, które wykonują swoje oddzielne zadania w tym procesie. Mogą bardziej naturalnie wykorzystywać swoje umiejętności i dalej wprowadzać innowacje. Niezależnie od zalecanych przez nie podejść i metod ukierunkowania na proces, wielu autorów dostrzega znaczące korzyści dla organizacji zorientowanych na proces. Hammer (2007) przekonuje, że organizacje mogą poprawić jakość swoich produktów i usług, czas wprowadzania na rynek, rentowność i inne wymiary, koncentrując się na procesach zorientowanych na klienta. Hirzel (2008) podobnie przytacza skrócenie czasów cyklu dostarczania produktu, odpowiadając na potrzeby klientów w wyniku przyjęcia ukierunkowania na proces. Ligus (1993) podaje bardzo szczegółowe szacunki dotyczące poprawy różnych wskaźników - skrócenia czasu dostawy o 75-80%, zmniejszenia poziomu zapasów nawet o 70%, a nawet zwiększenia udziału w rynku przy ukierunkowaniu na proces. Kohlbacher wymienia wzrost zadowolenia klientów, poprawę jakości produktów i usług, ogólne obniżenie kosztów, poprawę szybkości reagowania na potrzeby klientów, jako główne zalety przyjęcia systemu zorientowanego na proces. Rzeczywiście wydaje się, że istnieje znaczna zgoda co do tego, że orientacja procesowa zapewnia organizacji większą wydajność i sprawność w porównaniu z brakiem orientacji procesowej.
Zorientowanie na proces
W rzeczywistości niewiele organizacji było w stanie osiągnąć prawdziwą orientację na proces głównie ze względu na ograniczenia technologii i znaczną zmianę kultury wymaganą do osiągnięcia takiej orientacji. Nawet te organizacje, które utworzyły i wykorzystują funkcje ukierunkowane na procesy, mają trudności z efektywnym zarządzaniem zmianami kulturowymi wymaganymi do uruchomienia systemów zorientowanych na procesy. Prawdziwa orientacja na proces wykracza daleko poza organizowanie według procesów. Wymaga to zmiany w sposobie myślenia członków organizacji i internalizacji tego, co to znaczy być zorientowanym na proces. Hammer wskazuje, że władza większości firm opiera się na pionowych jednostkach - czasem koncentrujących się na regionach, czasem na produktach, a czasem na funkcjach - i te lenna wciąż zazdrośnie strzegą swojej ziemi, ludzi i zasobów. Powoduje to, że środowisko przyciąga ludzi w różnych kierunkach, podnosi tarcia organizacyjne i obniża wydajność organizacji. Stwierdzamy również, że ostatecznie skrajna frustracja związana z niezdolnością organizacji zorientowanych na funkcje do reagowania na potrzeby rynku prowadzi do dużych projektów transformacyjnych ukierunkowanych na procesy. Frustracje te mogą narastać do tego stopnia, że wewnętrzne nieefektywności prowadzą do hurtowego mandatu do wewnętrznej lub zewnętrznej transformacji. Takie projekty często przekraczają linie funkcjonalne. Często słyszysz o projektach typu "jeden i zrobiony", co oznacza, że wiele zbędnych punktów interakcji, wprowadzania informacji lub dotyku klienta, spowodowanych orientacją funkcjonalną, należy zredukować do jednego zintegrowanego punktu. Pewnego razu pracowałem z dużą firmą zajmującą się produktami informatycznymi, która miała 19 różnych systemów, które gromadziły mniej więcej te same podstawowe dane finansowe firmy. Często występowały błędy i poważne problemy z jakością w tym, co dostarczali swoim klientom. Kwestie narosły do tego stopnia, że kierownictwo wyższego szczebla musiało usankcjonować projekt transformacji zatytułowany "jeden i zrobiony". Projekt miał międzyfunkcyjnego właściciela, który miał wsparcie kierownictwa wyższego szczebla, aby przecinać silosy organizacyjne w celu wdrożenia "jednego i gotowego". Ostatnio natknąłem się na globalną firmę logistyczną, która ma wiele systemów na całym świecie, zorganizowanych według położenia geograficznego, które współdziałają w obsłudze zamówień klientów. Ta firma nie jest w stanie zapewnić spójnej i dokładnej odpowiedzi na zapytania i skargi klientów, w wyniku czego poziom zadowolenia klientów jest niski. Nie ma skoordynowanego procesu reakcji klienta i często ten sam klient działający w dwóch różnych regionach geograficznych otrzymuje różne usługi w zależności od tego, gdzie rejestruje swoją opinię. Odpowiedzi przedstawicieli obsługi klienta różnią się jakością w oparciu o ich wiedzę o produktach i procesach firmy. Firma stwierdziła, że często początkowa klasyfikacja skargi klienta była nieprawidłowa i często klasyfikacja zmieniała się podczas interakcji z klientem. Kontrowersje z klientem spowodowały wiele frustracji po stronie klienta. Ta firma rozpoczęła teraz ogromny projekt transformacji. Projekt ma jednego właściciela z różnych obszarów geograficznych i funkcji oraz ma uprawnienia do tworzenia zdolności do zapewniania klientom spójnych, dokładnych i terminowych odpowiedzi. Oba powyższe przypadki były przypadkami narastania problemów do momentu, w którym organizacja zmuszona jest dokonać radykalnej zmiany, aby nadal funkcjonować. Oczywiście, zanim organizacja uzna potrzebę, wiele jej reputacji uległo pogorszeniu. Istnieje znaczna literatura na temat mierzenia poziomu orientacji procesowej osiągniętej przez firmę i jej poziomu dojrzałości procesowej. Badacze i praktycy zaproponowali szereg modeli dojrzałości procesów biznesowych - model dojrzałości zorientowanej na procesy biznesowe, ramy możliwości BPM, model dojrzałości procesów i przedsiębiorstw oraz model dojrzałości procesów biznesowych grupy zarządzania obiektami należą do często określanych modeli. Tarhan i in. stwierdzili jednak, że po wszechstronnym przeglądzie literatury brakuje dowodów na powiązanie poziomu dojrzałości procesowej organizacji, mierzonej za pomocą jednego z powyższych modeli dojrzałości, do poprawy wyników biznesowych. Chociaż wydaje się, że jest to nieco sprzeczne z cytowanymi wcześniej ustaleniami dotyczącymi korzyści z orientacji na proces, różnica prawdopodobnie leży w stopniu korzyści i definicji modeli dojrzałości procesów biznesowych. W praktyce większość organizacji jest hybrydą podejść zorientowanych na procesy i funkcje. Nawet te organizacje, które dokonały przejścia do zorientowania na proces, są zorientowane na proces do pewnego momentu i stają się hierarchiczne ponad pewien poziom.
Dlaczego musimy wybrać?
Dlaczego organizacje muszą wybierać między orientacją procesową a funkcjonalną? Debata na temat zalet i wad procesu w porównaniu z orientacją funkcjonalną nieodłącznie odzwierciedla ograniczenia technologii i ograniczoną rolę, jaką technologia odegrała w umożliwieniu organizacjom zwiększenia wydajności i sprawności. Uważamy, że brak skutecznych paradygmatów technologii jest głównym powodem, dla którego firmy napotykają takie trudności w ukierunkowaniu procesu od podstaw. Gdyby paradygmaty technologii były elastyczne, wówczas firmom byłoby znacznie łatwiej zorientować się na proces. Możemy nawet pójść o krok dalej. Dlaczego technologia nie może umożliwić organizacjom posiadania dynamicznych struktur, które bezproblemowo zaspokajają potrzeby zarówno funkcjonalne, jak i procesowe? Dzięki postępowi technologicznemu uważamy, że organizacja może być jednocześnie zorientowana na proces i funkcjonalność, bez pociągania w obu kierunkach. Taki scenariusz przedstawiamy w dalszej części
Projekt i wykonanie
Istnieje jeszcze jeden wymiar organizacji przedsiębiorstwa, któremu nie poświęcono wiele uwagi w literaturze - projekt kontra wykonanie. Ważne jest, aby dostrzec różnicę między projektowaniem a wykonaniem w architekturze przedsiębiorstwa. Projektowanie odnosi się do projektowania różnych strategii, modeli biznesowych i procesów biznesowych. Każdy proces biznesowy jest zaprojektowany przez osobę i jest wykonywany przez jedną lub więcej osób w organizacji. Czasami są to ci sami ludzie. Te dwie role są jednak bardzo różne i oddzielne w dojrzałej organizacji. Leymann i Alternhuber [1994] uznają, że procesy biznesowe mają aspekt kompilacji i czasu wykonywania. Po zaprojektowaniu procesów biznesowych są one wielokrotnie wykonywane przez część wykonawczą organizacji. Niezależnie od tego, czy organizacja jest zorientowana na funkcję, czy na proces, niektóre osoby będą koncentrować się na projektowaniu i dużej części organizacji na realizacji. Część wykonawcza dowolnego procesu biznesowego została oczywiście dostosowana do automatyzacji ze względu na nieodłączną powtarzalność procesu montażu. Do niedawna projektowanie było w gestii ludzi. Projektanci określani są również jako "właściciele procesów" i często są ekspertami w tej dziedzinie lub ekspertami w zakresie operacji / procesów. Korzystają z wiedzy innych osób, myśląc o najlepszym sposobie zaprojektowania procesu. Natomiast wykonawcy są odpowiedzialni za wykonanie procesu określonego przez projektantów. Projektowanie wymaga odrębnego zestawu umiejętności, wiedzy i informacji. Wykonanie wymaga zupełnie innego zestawu umiejętności, wiedzy i informacji. Projekt jest oparty na wynikach wykonania.
ROLA OUTSOURCINGU W TWORZENIU EFEKTYWNOŚCI I ZWINNOŚCI
Offshoring jest obecnie uznawany za rewolucję społeczną na równi z rewolucją przemysłową. Przez długi czas produkcja była w dużej mierze wykonywana w rozwiniętym świecie dla rynków rozwiniętych, a usługi były podobnie wytwarzane i konsumowane na każdym oddzielnym rynku. Jednak w latach 80. outsourcing produkcji w lokalizacjach morskich, zwłaszcza w Chinach, stał się dość dobrze ugruntowany. Najczęściej mówionym i widocznym outsourcingiem było przeniesienie procesów produkcyjnych do krajów o bardzo niskich kosztach pracy. Spowodowały one znaczne zakłócenia w całych branżach w Stanach Zjednoczonych, zwłaszcza w produkcji tekstyliów. Te operacje produkcyjne przeniosły się na cały świat, przenosząc się do nowych lokalizacji, gdy zmieniają się różnice w względnych kosztach pracy. Wiele organizacji początkowo zlecało produkcję do Meksyku, a następnie do krajów azjatyckich. Outsourcing usług związanych z technologią pojawił się pod koniec lat 80. XX wieku i nadal znacząco rośnie w latach 90. i późniejszych. Covansys, z siedzibą w Farmington Hills w stanie Michigan, był jednym z pierwszych, którzy specjalizowali się w pomaganiu amerykańskim firmom w przeprowadzce za granicę i utworzeniu indyjskiego zakładu w 1992 r. American Express od 1994 roku przenosi różne funkcje biznesowe do Indii. Moje pierwsze przedsięwzięcie, eCredit, wyjechało za granicę z centrum rozwoju oprogramowania dla niewoli w Bangalore w 1994 roku. GE Capital uruchomił w Indiach firmę GE Capital International Services (GECIS) w Indiach , która od tego czasu została wydzielona jako niezależna firma Genpact. Wszystkie główne firmy świadczące usługi finansowe wykorzystały czynniki kosztów, aby uzasadnić offshoring wielu funkcji, od opracowywania oprogramowania po obsługę klienta. Między 1989 r., Kiedy Kodak zlecił outsourcing technologii informatycznej, a 1995 r., Rynek outsourcingu IT wzrósł do 76 miliardów dolarów. Zarówno outsourcing produkcji, jak i procesów biznesowych był w dużej mierze oparty na kosztach arbitrażu. Koncepcyjnie offshoring i outsourcing są realizacją przyjęcia doktryny wolnego handlu i zakorzenione w zasadach wytwarzania towarów i usług, w których można to zrobić najskuteczniej. Sawhney nazwał tę dźwignię względnych różnic kosztów w poszczególnych krajach "globalnym arbitrażem". Moxon empirycznie zbadał niedrogą siłę roboczą jako podstawową motywację do produkcji offshore dla przemysłu elektronicznego. Znaczenie kosztów produkcji zasugerowano również w badaniach systemu informacyjnego. Najwyraźniej postęp w dziedzinie technologii komunikacyjnych i komputerowych w ostatnich latach sprawił, że ten argument stał się jeszcze bardziej wiarygodny, a możliwości offshoringu coraz bardziej realne, szczególnie w dziedzinie usług. Wraz ze wzrostem "eksportu" wysoko wykwalifikowanych, wysoko płatnych miejsc pracy wzrosło również oczekiwanie na korzyści kosztowe. Chociaż istnieją inne argumenty wspierające na rzecz outsourcingu, takie jak jakość i czas dostawy, nie ma dowodów na dużą skalę potwierdzających te argumenty jako główną przyczynę. Podczas gdy liczba miejsc offshoringowych wzrosła z biegiem lat, a Chiny, Malezja, Filipiny i Republika Południowej Afryki szybko wkraczają w Indie (The Economist, 2003a, b), Indie nadal pozostają najważniejszym miejscem docelowym outsourcingu procesów biznesowych. Wykorzystując dane indyjskiego przemysłu BPO jako przybliżenie dla globalnego przemysłu BPO, od gwałtownego wzrostu o ponad 60% w latach 2003-2004, stopy wzrostu w branżach BPO i ITES w Indiach znacznie spadły do niskich podwójnych cyfr w latach 2014-2015, ponieważ z następujących czynników:
• Inflacja płac: Przewaga kosztowa Indii jako miejsca docelowego offshoringu, jej atutu, spadła o 30-40%. I z każdym rokiem spada.
• Wysokie ścieranie: przy 40-50% ścierania, BPO mają najwyższy wskaźnik ścierania spośród wszystkich branż, a firmy muszą zatrudniać połowę siły roboczej każdego roku.
• Zwiększone regulacje i kontrole: Outsourcing rynku finansowego
Na przykład outsourcing kluczowych zadań nadzorczych przez globalne banki (brytyjskie giganty HSBC i Standard Chartered) do Indii znalazł się pod kontrolą audytora regulacyjnego w krajach goszczących pod kątem nieskutecznej kontroli podejrzanych transakcji finansowych. Praca wykonana przez inny zestaw ludzi w innym miejscu nie spowoduje żadnej transformacji procesu. Inkrementalne inicjatywy Six Sigma nie przyniosą wiele w przypadku procesu, który już działa przy 99,5% umów SLA opracowanych w oparciu o proces ręczny. Z punktu widzenia outsourcerów czysty outsourcing bez znaczącej przebudowy procesów nie sprawi, że firmy będą bardziej wydajne i sprawne. Po udanej fali outsourcingu opartego na arbitrażach kosztowych kolejna fala będzie musiała zostać poprowadzona przez jakość i czas na uzyskanie przewagi rynkowej. Wymaga to dźwigni technologicznej i wiedzy specjalistycznej. Outsourcowie zaczynają przechodzić od modelu outsourcingu opartego wyłącznie na FTE do usług zarządzanych. Co ważniejsze, nalegają na zrozumienie i zobaczenie, w jaki sposób firmy BPO zastosują technologię i automatyzację w celu ulepszenia swoich procesów zlecanych na zewnątrz. Trwa idealna burza, w której klienci starają się ograniczyć dodatkowe koszty backoffice z powodu ciągłej presji budżetowej, podczas gdy dostawcy próbują stworzyć dodatkowe usługi i związane z nimi przychody. W analizie indyjskiego przemysłu offshoringowego analiza McKinsey stwierdza: "Innowacje będą kluczem do utrzymania, a nawet rozszerzenia ich udziału w rynku. Modele biznesowe, które nadal koncentrują się na niskich kosztach pracy, nie wystarczą ". Okazuje się, że w środowisku po recesji będzie istnieć ciągła presja na obniżanie kosztów i ulepszanie usług. Jak zauważono w wywiadzie dla magazynu Wharton Knowledge w 2009 r., Nigdy nie wierzyłem w długoterminową opłacalność czystego podejścia typu "lift and shift", które zdominowało przemysł BPO i nadal tak jest. O ile jednorazowa oszczędność kosztów wynikająca z arbitrażu kosztowego miała sens we wczesnych dniach, a być może nadal stanowi szybki pierwszy przystanek, pomysł po prostu przeniesienia procesów do innej lokalizacji, bez poprawy lub optymalizacji w razie potrzeby, nie ma sens na dłuższą metę. Przez kilka dziesięcioleci służył obu stronom bardzo dobrze, ale teraz nadszedł czas na fundamentalne przekształcenie branży BPO i ITES. Ostatnie postępy technologiczne stanowią okazję i wyzwanie, aby odkryć na nowo, w jaki sposób technologia jest wykorzystywana w celu zwiększenia wydajności i sprawności. To, czy firmy korzystające z usług BPO i usług informatycznych [ITES] będą w stanie je wykorzystać na swoją korzyść, dopiero się okaże. Obecnie rośnie konsensus, że marże w branży outsourcingu spadają. Przez ponad dekadę firmy outsourcingowe cieszyły się jednym z najwyższych poziomów rentowności w każdej branży, ale kombinacja sił przesuwa marże do poziomów bardziej typowych dla produktów i usług skodyfikowanych . Wiele firm BPO zmienia się na nowo, ostatecznie skupiając się na automatyzacji i zwiększonym wykorzystaniu technologii. Genpact wprowadził podejście Lean DigitalSM. Genpact dąży do umożliwienia dużym firmom przebudowy ich działań średnich i backoffice oraz uzyskania wymiernego wpływu, takiego jak wzrost, efektywność kosztowa i elastyczność biznesowa. "Lean Digital wprowadza nową erę w to, jak nasi klienci zbliżają się do transformacji cyfrowej - zmiana, która spowodowała przyjęcie tych metod w wielu naszych klientach bankowych, ubezpieczeniowych, produkcyjnych, naukach przyrodniczych i produktach konsumenckich, a także przyczyniła się do naszych inwestycji w tym stworzenie laboratorium innowacji w Dolinie Krzemowej w celu prototypowania i eksperymentowania z nimi "- powiedział Tiger Tyagarajan, prezes i dyrektor generalny Genpact. Firma Genpact ogłosiła niedawno strategiczne partnerstwo z RAGE Frameworks w celu połączenia sztucznej inteligencji z podejściem Lean DigitalSM, aby przesunąć granice automatyzacji w instytucjach finansowych. Podobnie Wipro spodziewa się, że inwestycje w automatyzację, sztuczną inteligencję (AI) i technologię cyfrową poprawią wydajność i spowodują zmniejszenie liczby pracowników o 30% w ciągu najbliższych trzech lat. Powielanie procesów obsługiwanych ręcznie było modne w firmach BPO. To zyskało na popularności, ponieważ duża część procesów BPO jest bardzo mechaniczna i wymaga wprowadzania danych do systemów klienckich. Chociaż roboty potrafią poradzić sobie z takimi procesami mechanicznymi, automatyzacja robotów nie jest długoterminowym rozwiązaniem zwiększającym zwinność i elastyczność na bardziej podstawowym poziomie procesów biznesowych. Davenport przewiduje, że z biegiem lat pojawi się szeroki zestaw standardów procesowych, które zapewnią miary i przejrzystość niezbędne do oceny, czy outsourcing będzie korzystny i ułatwi porównywanie usługodawców. Ta linia dyskursu nie uwzględnia transformacyjnego wpływu najnowszych technologii. W rzeczywistości zakłada, że technologia nadal nie będzie odpowiadać na potrzeby biznesowe. Chociaż opracowywanie oprogramowania oparte na standardach ułatwiło tworzenie niezawodnego oprogramowania, nie zmieniło ono szybkości, z jaką oprogramowanie jest opracowywane, i jego reakcji na potrzeby biznesowe. W nadchodzącym dziesięcioleciu sam proces tworzenia oprogramowania zmieni się diametralnie, powodując zwrot w podejściu firm do tworzenia oprogramowania oraz, co ważniejsze, co zlecają i jak zlecają. Wierzymy, że technologia transformacyjna pozwoli firmie inteligentnie zdecydować, które procesy, jeśli w ogóle, powinny zostać zlecone na zewnątrz, i bezproblemowo zintegrować procesy outsourcingowe z pozostałymi procesami firmy. Elastyczność, z jaką technologia ułatwi wykonywanie procesów biznesowych, może pozwolić firmom na posiadanie nawet nie-podstawowych procesów, jeśli dostrzegą w tym pewne korzyści. Taka transformacyjna technologia wprowadzi nową erę innowacji we wszystkich procesach, zarówno podstawowych, jak i innych.
ROLA TECHNOLOGII W WYDAJNOŚCI I ZWINNOŚCI
Technologia ma kluczowe znaczenie dla wydajności i sprawności. Historycznie zauważono znaczącą rolę, jaką technologia powinna odgrywać w umożliwianiu przedsiębiorstwom konkurencyjności. W ciągu ostatniej dekady i więcej stało się tak jeszcze bardziej dzięki ogromnemu rozwojowi Internetu i wzajemnym połączeniom firm na całym świecie.
Aktualne wyzwania związane z technologią
Technologia od dawna niesie obietnicę ułatwienia bardziej wydajnych i elastycznych sposobów prowadzenia działalności oraz umożliwienia konkurencyjnego zróżnicowania. Historycznie także każde duże przedsiębiorstwo obfitowało w kadrę kierowniczą, która jest głęboko sfrustrowana niezdolnością technologii do sprostania ich wymaganiom. Technologowie obwiniają technologie tworzenia aplikacji (AD), mimo że technologie AD znacznie się rozwinęły od pierwszych dni przetwarzania. Widzieliśmy poważne zmiany ewolucyjne w środowiskach programistycznych, architekturach i metodologiach w wyniku wiedzy zdobytej na każdym etapie ewolucji. Jednak mimo że dzisiejsze technologie AD stanowią wyraźną poprawę w stosunku do technologii sprzed 5 do 10 lat temu, pozostaje kilka podstawowych kwestii, takich jak czas wprowadzenia na rynek, potrzeba radzenia sobie z szybkimi zmianami środowisk i standardów technologicznych oraz dostępność wykwalifikowanych zasobów. Nastąpiła także poważna zmiana w środowisku AD od lat 90. XX wieku, a wiele aplikacji w pakiecie zyskało znaczną przyczepność. Jednak aplikacje te wymagały znacznych dostosowań i nie zapewniły elastyczności do użycia od razu po wyjęciu z pudełka. Dostosowania wymagają obszernego programowania i często zajmują nadmiernie dużo czasu. Wystąpiły również znaczne luki między takimi aplikacjami a sposobem prowadzenia działalności przez przedsiębiorstwa. Luka w aplikacjach pakietowych i potrzebach biznesowych wynika głównie z tego, że aplikacje te nie zostały zaprojektowane od samego początku zorientowane na proces. W większości przypadków firmy decydują się dostosować swoje procesy do sposobu budowania aplikacji lub dostosować aplikacje, co powoduje, że obietnica przyszłych aktualizacji jest nieważna. W ten sposób w przyszłości stanowią poważne obciążenie związane z utrzymaniem. Niemniej jednak większość z tych aplikacji nie zapewniła przedsiębiorstwom niezbędnej wydajności i sprawności.
Oprogramowanie BPM
Oprogramowanie do zarządzania procesami biznesowymi (BPM) pojawiło się w ostatnim dziesięcioleciu i później, aby wypełnić lukę między aplikacjami w pakiecie a potrzebami przedsiębiorstwa w zakresie procesów biznesowych. Początkowo pakiety BPM zapewniały obsługę wyjątków i funkcjonalność przepływu pracy. Jak sama nazwa wskazuje, BPM zdefiniowano jako zarządzanie projektowaniem i kontrolą procesów biznesowych (Leymann i Altenhuber, 1994). Rozróżniają między czasem projektowania a aspektami czasu wykonywania procesu biznesowego. Reijers (2003) definiuje BPM jako obszar projektowania i kontrolowania procesów biznesowych. Tradycyjne platformy zarządzania sprawami (CMF) oparte na platformie BPM zostały wprowadzone przez tradycyjnych dostawców BPM, aby skrócić czas wprowadzania produktów na rynek w oparciu o rozwiązania. CMF są gotowe do użycia, aby stworzyć unikalne niestandardowe rozwiązanie. CMF zalecono tam, gdzie pakiety rozwiązań nie są dostępne lub są uważane za nieodpowiednie ze względu na luki w wymaganiach, brak elastyczności i tym podobne. CMF oparte na platformie BPM różnią się od tradycyjnych bibliotek kodów wielokrotnego użytku lub spakowanych aplikacji komercyjnych, ponieważ są one generalnie sterowane modelami i polegają na silniku orkiestracji do sterowania wykonaniem. Wiele CMF wykonuje rozwiązanie bezpośrednio z metadanych, a nie z kodu generowanego z metadanych. Niektórzy dostawcy zbudowali specyficzne dla domeny ramy pionowe na CMF, takie jak operacje call center. Chociaż istnieje duża liczba dostawców oprogramowania BPM oferujących CMF, są one jednak w stanie obsłużyć tylko przebieg sprawy. Ponieważ większość tych pakietów nie została zaprojektowana od samego początku zorientowaniem na proces, upłynie trochę czasu, zanim będą w stanie osiągnąć drobnoziarnistą elastyczność w celu zaspokojenia dynamicznego charakteru potrzeb biznesowych. Z tego powodu nikt nie był w stanie skutecznie rozwiązać podstawowych problemów związanych z elastycznością i czasem wprowadzenia na rynek w powiązanych wysiłkach związanych z opracowywaniem aplikacji. Każdy projekt oparty na platformach BPM nadal nie jest niedrogi, szybki ani elastyczny, chyba że pasuje do gotowego rozwiązania oferowanego przez dostawcę oprogramowania BPM, a bardzo rzadko jest ściśle dopasowany. Niezmiennie, biorąc pod uwagę gruboziarniste wsparcie procesu biznesowego przez wszystkie obecne platformy BPM, wdrożenie pełnego projektu zazwyczaj wymaga dużej ilości konwencjonalnego programowania. Oczywiście wynikiem jest długi cykl wdrażania i brak elastyczności. W ostatnim przykładzie, w którym globalna instytucja finansowa potrzebowała kompleksowej aplikacji do obsługi pożyczek dla nowej linii produktów kredytowych, szacunki dotyczące początkowego wdrożenia przez wiodących dostawców usług IT korzystających z wiodących na rynku platform BPM, w tym tych z CMF, wynosiły od 18 do 24 miesięcy. Analiza wymagań ujawnia, że dostawcy BPM z ich bieżącym, gruboziarnistym wsparciem dla procesów biznesowych obsłużyliby jedynie 10-15% całkowitej funkcjonalności systemu. Resztę należałoby opracować przy użyciu współczesnych metod tworzenia oprogramowania. W tym przykładzie aplikacji typu greenfield czas na wprowadzenie na rynek wyzwań, nawet przy użyciu BPMS, był wynikiem braku funkcjonalności, która może obsłużyć pełne spektrum potrzeb dla tej aplikacji. Do tego dochodzi brak myślenia procesowego w projektowaniu takich BPMS. Oczywiście, przy wsparciu tylko 10-15% aplikacji, projekt nie mógł zyskać znaczącego czasu na wprowadzenie na rynek ani korzyści z elastyczności. Inną ważną kwestią do zapamiętania jest to, że BPM nie wpływają na analizę wymagań lub etapy testowania cyklu tworzenia oprogramowania. Oba są bardzo czasochłonne dla całego projektu, bez względu na zastosowaną metodologię, co omówimy w dalszej części.
Rola metodologii
Cykl życia oprogramowania (SDLC) ewoluował od sztuki idiosynkratycznej do dyscypliny inżynierskiej. Dni nauki sztuki od mistrza rzemieślnika oddały strukturę, standardy i dyscypliny podobne do inżynierii. SDLC składa się z wielu etapów, gdy pomysł przekształca się w aplikację. Na każdym etapie wyniki z poprzedniego etapu są tłumaczone, aby służyły celowi i odbiorcom obecnego etapu. Te pośrednie tłumaczenia są konieczne, aby ostatecznie stworzyć tłumaczenie, na którym komputer może działać. Z każdym tłumaczeniem staramy się zachować pełną informację i wiedzę z poprzedniego etapu. Oczywiście każdy etap dodaje cennego czasu do całego cyklu życia. Niektóre etapy wymagają specjalistycznych umiejętności, takich jak programowanie. Przez lata włożono wiele wysiłku w uczynienie SDLC skutecznym i przewidywalnym. Takie wysiłki można podzielić na dwie główne kategorie:
• Podejścia metodologiczne mające na celu poprawę komunikacji i tłumaczenia między poszczególnymi etapami cyklu życia poprzez ich standaryzację i ograniczenie nadmiarowości w pracach programistycznych.
• Podejścia automatyzacji mające na celu automatyzację jednego lub więcej etapów cyklu.
Nacisk na podejście metodologiczne podniósł SDLC do nauk inżynieryjnych i ogólnie zwiększył przewidywalność i niezawodność tworzenia oprogramowania. Metodologie te jednak w dużej mierze nie uwzględniły kwestii czasu na rynku i kwestii elastyczności. Wynika to z tego, że przyjęli SDLC zorientowane na przyszłość, jak podano.
Zwinność Nie równa się zwinności
Niedawno wydaje się, że metodyki zwinne zyskują na popularności. Wszystkie metodologie Agile, luźniej mówiąc, są krótszymi wersjami powyższej współczesnej metodologii. W dużej mierze wynikają one ze świadomości, że wymagania zmieniają się często i nie są często precyzyjne. Aby zaradzić takiej zmienności w procesie i zmniejszyć koszty odkrywania luk znacznie poniżej bieżącego etapu, metody zwinne zalecają krótsze iteracje i kładą mniejszy nacisk na etapy statyczne, takie jak dokumentacja. Zwinne projekty zaczynają się od frazy dotyczącej planowania wydania, po której następuje kilka iteracji, z których każda kończy się testem akceptacyjnym dla użytkownika. Gdy produkt spełnia minimalnie wykonalny zestaw funkcji, zostaje zwolniony. Użytkownicy piszą "historie użytkowników", aby opisać pożądaną funkcjonalność. Takie historie stanowią wymagania stosowane do oszacowania realizacji projektu. Wykonanie jest podzielone na tyle iteracji, ile potrzeba. Użytkownicy mogą dodawać więcej szczegółów do swoich historii, nawet w trakcie iteracji. Zmiany przyrostowe są uwzględniane w następnej iteracji. Pod koniec każdej iteracji użytkownicy testują aplikację, a błędy są po prostu częścią kolejnej iteracji. Użytkownicy mogą w dowolnym momencie zdecydować o wydaniu oprogramowania, jeśli dostępna jest wystarczająca liczba funkcji. Ważnymi różnicami filozoficznymi jest uznanie, że wymagania nie są statyczne oraz że niektóre kroki, takie jak pełna dokumentacja wymagań, są niepotrzebne i przeciągają proces w dół. Sukces Agile zależy od ciągłego posiadania eksperta od wymagań. Wynika to z tego, że historie użytkowników są bardzo krótkie. Metodologia opiera się w coraz większym stopniu na dokumentacji. Metodologie zwinne, pomimo tego, co można interpretować na podstawie nazwy, nie powodują znaczącego skrócenia czasu wprowadzenia produktu na rynek ani elastyczności. W rzeczywistości, podobnie jak w przypadku wszystkiego nowego, widzimy znaczne nieporozumienie co do metodologii Agile. Metodyki zwinne powinny znacznie zwiększyć prawdopodobieństwo akceptacji przez użytkowników, ponieważ użytkownicy często zobaczą małe fragmenty aplikacji i będą mieli możliwość wprowadzania modyfikacji przez cały czas. Jeśli na czele stoi prawdziwe MŚP, prawdopodobne jest nieznaczne skrócenie czasu wprowadzenia produktu na rynek w porównaniu z konwencjonalnym SDLC. Częściej niż nie, przewidujemy, że metody zwinne zwiększą czas opracowania aplikacji. Pamiętaj, że istnieje kilka kroków niepowodujących wartości dodanej, takich jak testowanie, które będą musiały być wykonywane bardziej powtarzalnie w porównaniu ze środowiskiem innym niż Agile. Zwinne nie oznacza więc zwinności. Jest to krytyczny wniosek, który przedsiębiorstwa muszą internalizować. I nie zajmuje się podstawowymi kwestiami czasu na rynku i elastyczności. Jest realistycznie prawdopodobne, że wpłynie tylko na niezawodność. Pomimo znacznego nacisku na poprawę cyklu życia oprogramowania (SDLC), żadne z tych podejść nie spowodowało znaczącej różnicy w odwiecznych kwestiach czasu na rynku i elastyczności. Co ważniejsze, odsetek niepowodzeń lub ogromnych przekroczeń kosztów projektów oprogramowania jest wciąż niedopuszczalnie wysoki
NOWY PARADYGMAT TECHNOLOGII DLA WYDAJNOŚCI I ZWINNOŚCI
Istnieją znaczące dowody na korzyści płynące z zorientowania na proces w porównaniu z czysto funkcjonalnymi organizacjami. Mimo to przedsiębiorstwom trudno jest w praktyce zorientować się na proces. Zauważyliśmy również, że technologia może odgrywać kluczową rolę w umożliwianiu przedsiębiorstwom zorientowania na procesy bez konieczności zarządzania wieloma zmianami. W tym momencie przedstawimy platformę technologiczną i metodologię, która może zająć się chronicznym czasem wprowadzenia na rynek i problemami z elastycznością oraz umożliwić firmom uzyskanie zarówno wydajności, jak i sprawności. Omawiamy platformę automatyzacji procesów biznesowych opartą na modelu meta, która może umożliwić tworzenie oprogramowania w czasie zbliżonym do rzeczywistego w dużej mierze bez programowania i wyłącznie przy użyciu metadanych.
Technologia i architektura zorientowana na proces
Zaczynamy od nakreślenia wysokiego poziomu koncepcyjnego związku między biznesem zorientowanym na proces a technologią. Zależność pokazano poniżej
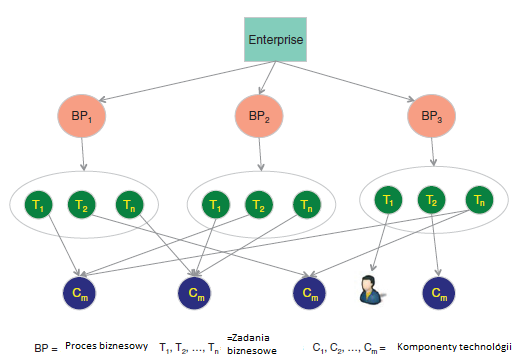
Rycina przedstawia hipotetyczny biznes. Jest on konceptualizowany jako zbiór procesów biznesowych, dlatego należy go postrzegać [BP1, BP2, BP3,
, BPm]. Możemy dalej myśleć o każdym procesie biznesowym jako o zestawie zadań biznesowych. Proces biznesowy to zestaw powiązanych ze sobą zadań, które są wykonywane w określonej kolejności przez połączenie ludzi i maszyn [T1, T2,
, Tn]. Sposób budowania aplikacji polega na programowaniu tych zadań za pomocą języka programowania lub frameworka. Co by było, gdybyśmy wyeliminowali programowanie poprzez obszerną warstwę abstrakcji? Prostym sposobem na odniesienie się do tego jest rozważenie każdego zadania jako odpowiadającego komponentowi technologii. Na poziomie abstrakcyjnym wiele z tych zadań jest wspólnych dla wszystkich aplikacji. W każdym ćwiczeniu tworzenia oprogramowania ciągle robimy to samo. Każda aplikacja potrzebuje wsparcia technologicznego dla podobnych zadań i funkcji - przepływu pracy, zarządzania sprawami, interfejsów z innymi systemami wewnętrznymi i zewnętrznymi, podejmowania decyzji, obliczeń, dynamicznego tworzenia dokumentów, kwestionariuszy opartych na logice i tak dalej. Możemy myśleć o wielu takich zadaniach, które są niezależne od domeny. Oczywiście możemy również myśleć o zadaniach specyficznych dla domeny. Powyższy rysunek ilustruje to poprzez połączenie wielu zadań w wielu procesach biznesowych z tym samym komponentem technologicznym. Będziemy myśleć o tych komponentach technologii w sposób abstrakcyjny, zgodny z modelem architektonicznym opartym na modelu, ale z jedną różnicą: zamierzamy zredukować taki model do metadanych, aby całkowicie wyeliminować programowanie. Na przykład, jeśli zadaniem jest przesłanie danych do innego system poprzez plik danych, wtedy możemy pomyśleć o abstrakcyjnym komponencie technologicznym o nazwie "konektor". Komponent konektora powinien być w stanie ułatwić łączność między systemami nie tylko dla tego konkretnego zadania, ale dla każdego takiego zadania interfejsu system-system. Zagłębmy się nieco w abstrakcyjny komponent złącza. Wszystkie interfejsy system-system przenoszą dane z systemu źródłowego do systemu docelowego za pomocą jednego z kilku protokołów transportowych. Dane ze źródła do celu mogą wymagać transformacji w taki sposób, aby pasowały do docelowych struktur danych. Następnie możemy stworzyć kompleksową abstrakcję funkcjonalności wymaganej do wdrożenia ogólnego interfejsu między dwoma systemami z danym protokołem. Taka abstrakcja staje się modelem komponentu. Abstrakcja jest pozbawiona jakiegokolwiek kontekstu, jedynie abstrakcyjna funkcjonalność wymagana do przenoszenia danych z jednego źródła do drugiego. Ta abstrakcja nie będzie zawierać wiedzy o źródle, celu ani ich strukturach danych. Taka abstrakcja może zostać ujawniona do wykorzystania w konkretnych projektach programistycznych poprzez zestaw właściwości modelu, zwany także metadanymi. Aby wdrożyć określony interfejs, użytkownik dostarczy szczegółowe informacje o źródle, celu, pliku źródłowym, pliku docelowym, każdej transformacji między źródłem a celem i tak dalej. Bardzo ważne jest, aby pamiętać, że takie szczegóły kontekstowe będą miały postać danych abstrakcyjnego modelu komponentu konektora. Celem abstrakcyjnego komponentu konektora jest umożliwienie analitykowi biznesowemu modelowania określonego interfejsu przy użyciu modelu komponentu abstrakcyjnego. Jeśli model jest kompleksowy, wdrożenie rzeczywistego interfejsu można sprowadzić do modelowania czystego. Takie modelowanie obejmuje dostarczanie jako danych parametrów, które będą specyfiką interfejsu, który analityk jest zainteresowany wdrożeniem. Rzeczywisty interfejs zostaje w ten sposób zredukowany do parametrów modelu abstrakcyjnego komponentu. Aby naprawdę umożliwić firmie osiągnięcie orientacji na proces, potrzebujemy platformy technologicznej, która ma szeroki zestaw takich abstrakcyjnych komponentów. Zestaw ten musi również zawierać komponenty dla zawiłych zadań opartych na wiedzy, takich jak ekstrakcja danych z dokumentów częściowo ustrukturyzowanych i nieustrukturyzowanych. Platforma będzie zawierała komponent do aranżacji, który pozwoli projektantowi łączyć procesy biznesowe od końca do końca za pomocą odpowiedniej kolekcji abstrakcyjnych komponentów technologicznych. Dzięki architekturze opartej na modelu meta, każdemu z tych abstrakcyjnych komponentów dostarczany jest kontekst wyłącznie w forma danych przy użyciu odpowiednich modeli abstrakcyjnych. Takie kontekstowe modele procesów biznesowych można modyfikować w dowolnym momencie. Uwaga: modyfikujemy nie tylko przepływ pracy, jak oprogramowanie BPM, ale cały proces biznesowy, w tym wszystkie / wszystkie jego zadania. Uważamy, że takie ramy BPA mogą zapewnić wydajność i sprawność, że każde przedsiębiorstwo musi być konkurencyjne. Przedsiębiorstwo może teraz naprawdę wyróżnić się swoją wiedzą specjalistyczną.
RAGE AI
RAGE AI (Rage) to oparta na wiedzy platforma automatyzacji, która została zaprojektowana do szybkiego tworzenia elastycznych, zorientowanych na proces aplikacji całkowicie za pomocą modelowania. Celem platformy Rage jest tworzenie "dynamicznych" aplikacji niemal w czasie rzeczywistym wyłącznie poprzez modelowanie i bez programowania. Jednocześnie można rozszerzyć, aby zespoły programistów mogły dodawać dowolne funkcje, których nie można modelować przy użyciu dostępnych komponentów. Platforma została oparta na przekonaniu, że inteligentna automatyzacja jest podstawą systemowej przewagi konkurencyjnej. Platforma może umożliwić przedsiębiorstwom przejście do prawdziwie zorientowanego na proces paradygmatu bez większego zarządzania zmianami. Ponieważ procesy są zinstytucjonalizowane w RAGE AITM, maszyny RAGE AITM mogą być klejem procesowym. RAGE AITM ucieleśnia przekonanie, że właściciele firm muszą być w stanie modyfikować procesy biznesowe w czasie zbliżonym do rzeczywistego, aby szybko zaspokajać stale zmieniające się potrzeby biznesowe i opłacalne, nie martwiąc się o niuanse technologiczne. Platforma opiera swoją orientację na proces na modelu procesowym firmy opisanym na rysunku powyżej. Platforma RAGE AITM zapewnia obecnie zestaw 20 abstrakcyjnych komponentów, zwanych "silnikami", wszystkie wykorzystujące architekturę opartą na meta modelach. Mechanizm wykonawczy platformy i wszystkie jej abstrakcyjne komponenty działają z metadanymi i nie tłumaczą żadnego z modeli procesów na kod. RAGE AITM przewiduje, że gdy użytkownicy wdrożą określoną domenę aplikacji, odkryją wspólne podprocesy i zadania, które można odizolować i bardzo łatwo wykorzystać ponownie, nawet w domenach wewnątrz firmy. Jak pokazano na rysunku powyżej, metodologia Rage ułatwia rozkład procesu biznesowego na zestaw zadań i włącza RAGE AI modeler do mapowania każdego zadania do jednego z 20 silników. W ten sposób realizacja zadania ogranicza się do dostarczenia parametrów kontekstowych do odpowiedniego modelu komponentu abstrakcyjnego. Silnik orkiestracji procesów umożliwia ponowne modelowanie orkiestracji przy użyciu modelu silnika orkiestracji. Praktycznie każdą zmianę w aplikacji można łatwo obsłużyć, zmieniając odpowiednie modele bez obawy o wygenerowany wcześniej kod i architekturę wdrażania. Dlatego rozwiązania RAGE AITM są zawsze "pod napięciem", a ich modyfikacje można łatwo, szybko i bez dodatkowych kosztów utrzymania. Jednocześnie Rage jest rozszerzalną platformą i łatwo się integruje ze starszymi aplikacjami. Twórcy aplikacji mogą dodawać starsze segmenty kodu jako zadania niestandardowe i rozszerzać funkcjonalność frameworka.
Składniki abstrakcyjne RAGE>
Platforma RAGE AI składa się z 20 silników. Każdy z 20 komponentów jest zgodny ze spójną architekturą opartą na modelach, co pozwala analitykom biznesowym na korzystanie z nich poprzez podanie parametrów modeli danego silnika. Modele te pozostają takie, jak są zbudowane. Natomiast większość oprogramowania BPM zapewnia 1 lub 2 z 20 silników. Wiele zapewnia akceleratory, które są wstępnie zbudowanymi aplikacjami dla określonych branż. Dzięki RAGE AITM cała aplikacja może być łatwo zaimplementowana w dowolnym momencie poprzez modelowanie przy użyciu przedstawionych 20 silników. Powróćmy do wcześniejszego przykładu przetwarzania pożyczki. Dzięki LiveBPA obraz dźwigni będzie wyglądał znacznie inaczej. Wszystkie zadania w przepływie wysokiego poziomu mogą być w pełni obsługiwane przez opartą na meta modelach platformę RAGE AITM w porównaniu z bardzo niskim poziomem zasięgu z popularnych platform BPM na rynku. Aby w pełni obsługiwać funkcjonalność, każde zadanie wymaga znacznie więcej niż silnika reguł i organizatora przepływu pracy. Akceleratory dla określonych domen pionowych mają ograniczone zastosowanie, ponieważ nie zapewnią elastyczności, jaką zapewnia szerszy zestaw składników abstrakcyjnych.
RIM - praktyczna, dynamiczna metodologia
Cykl życia rozwiązania RAGE AI do tworzenia oprogramowania, RIM, jest znacznie krótszy w porównaniu do współczesnego SDLC. RIMTM to metodologia zwinna, którą można porównać do Scrum1 na wysokim poziomie. Ponieważ jednak proces tworzenia oprogramowania przy użyciu platformy RAGE LiveBPA koncentruje się na projektowaniu i zasadniczo eliminuje kodowanie, istnieją znaczne różnice. RIM umożliwia zespołom programistycznym wdrażanie większej funkcjonalności o rząd wielkości w tym samym czasie, co metodologie Agile, ponieważ implementacja ogranicza się do modelowania przy użyciu komponentów abstrakcyjnych i nie ma tłumaczenia na kod. W RIM wymagania i implementacja są w dużej mierze synonimami. Poza tym implementacją są "modele". Podobnie jak XP i Scrum, nie ma nacisku na szczegółową dokumentację. Po ukończeniu modele są testowane pod kątem poprawności działania. Tradycyjne testy składniowe są ograniczone do opracowywanego kodu niestandardowego, jeśli taki istnieje. Etap "projektowania" w RIM jest dość nowy. Ogólne wymagania są rozkładane na składowy zestaw procesów biznesowych, zwany "domeną". Działająca storyboard jest szybko rozwijana za pomocą platformy LiveBPATM. Działająca storyboard jest podobna do prototypu, z tą zasadniczą różnicą, że storyboard jest działającą wersją i może być uważany za bardzo wczesną wersję alfa funkcjonalności. Poniżej przedstawia zestaw nowych pojęć, które zostały krótko wyjaśnione:
• Pomysł : Oświadczenie wysokiego poziomu lub schemat zakresu lub pomysłu.
• Domena : Zakres lub pomysł podzielony na procesy biznesowe wysokiego poziomu, które stanowią pomysł. Jest to krytyczny krok, ponieważ wymusza instytucjonalizację wiedzy specjalistycznej w dziedzinie.
• Storyboard : Funkcjonujący prototyp domeny na wysokim poziomie. Różni się od konwencjonalnego prototypu. Funkcjonująca storyboard ostatecznie ewoluuje w aplikację. Scenorys może zawierać jedną lub więcej historii użytkowników. Kluczem do historii użytkownika jest oczywiście to, że powinna być minimalnie opłacalna. Zbyt wiele implementacji Agile nie zwraca uwagi na ten podstawowy krok. Krytyczna potrzeba eksperta jest często pomijana.
• Modele : Procesy biznesowe wchodzące w skład Domeny i wdrażane przez zespół wdrażający za pomocą RAGE AITM. Większość funkcji aplikacji można modelować przy użyciu obszernego zestawu komponentów platformy RAGE AITM. W zależności od wielkości i skali nakładów prace związane z modelowaniem można rozdzielić między zespoły procesów biznesowych w celu ich wdrożenia.
• Testy funkcjonalne : Zastosowania zestawów powiązanych modeli procesów biznesowych, które są przechowywane jako dane. Nie ma potrzeby konwencjonalnego testowania. To, co należy przetestować, to dokładność funkcjonalna modeli.
• Zarządzanie projektem : Aktualizacja RIM kroków zarządzania projektem. Oprócz ogólnego planu projektu, codzienne aktualizacje projektu zapewniają, że wszelkie pojawiające się zagrożenia zostaną zidentyfikowane, gdy tylko się pojawią, a zespół projektowy podejmie odpowiednie kroki naprawcze. Wstępny plan projektu jest finalizowany, gdy scenorys jest gotowy. W razie potrzeby plan projektu jest aktualizowany, gdy modele scenariuszy zyskują więcej szczegółów i jasności
Po wydaniu cykl powtarza się od nowa. RIM jest lepszy od ogólnych metodologii Agile tylko dzięki bazowej platformie RAGE AITM. Platforma pozwala metodologii zredukować / wyeliminować etapy bez wartości dodanej konwencjonalnego SDLC, takie jak programowanie, testy składniowe.
Rozwój oprogramowania w czasie rzeczywistym
Poprzednia dyskusja przedstawiła moc RAGE AI z obszernym zestawem abstrakcyjnych komponentów, które pozwoliły firmie szybko i elastycznie wdrażać aplikacje o znaczeniu krytycznym wyłącznie poprzez modelowanie. Jednak cykl życia rozwiązania RAGE AITM nie kończy się na tym. Rozszerza swój paradygmat architektoniczny oparty na meta modelach dość dramatycznie aż do modelowania wymagań.
RAGE AITM zapewnia kompleksowe środowisko modelowania do wizualnego modelowania wymagań. Model wymagań opiera się na strukturze dekompozycji procesów biznesowych na rysunku powyżej Modeler może modelować wymagania przy użyciu palety abstrakcyjnych zadań biznesowych na wysokim poziomie i zapewniać odpowiednie informacje na poziomie zadania jako parametry zadań abstrakcyjnych. W momencie zbierania wymagań użytkownik będzie wiedział, jakie są podstawowe potrzeby informacyjne różnych zadań biznesowych, chociaż formalny kanoniczny model danych może jeszcze nie być dostępny. Modeler powinien zostać poproszony o podanie potrzeb informacyjnych każdego zadania wraz z atrybutami, takimi jak liczność. Następnie abstrakcyjny komponent do modelowania danych inteligentnie przekształca taki model informacji we wszystkich procesach biznesowych w szkicowy model kanoniczny. Taki automatycznie wygenerowany model danych może być udoskonalony przez architekta danych, jeśli to konieczne. Gdy wymagane modele mają wymagane odniesienia danych, inny inteligentny komponent w RAGE AITM konwertuje je automatycznie na modele implementacji. Konwersja odbywa się poprzez automatyczne mapowanie każdego zadania w modelach wymagań na jeden lub więcej komponentów w RAGE AITM. Komponent konwersji automatycznie wygeneruje również wartości parametrów wymagane dla modeli implementacji z odpowiednimi wartościami parametrów specyficznymi dla kontekstu. Platforma RAGE AITM, jak pokazano na rysunku, może umożliwić tworzenie oprogramowania w czasie rzeczywistym w celu wyeliminowania i znacznego ograniczenia programowania. Platforma zapewnia wieczną elastyczność dzięki architekturze opartej na meta modelach.
PODSUMOWANIE
Od dawna debatujemy nad metodami, które zapewniają, że przedsiębiorstwa stają się wydajne i elastyczne. Orientacja na proces, w przeciwieństwie do organizacji funkcjonalnej, była szeroko reklamowana jako najlepsze rozwiązanie do ponownej inżynierii, ale większości organizacji nie udało się zorientować na proces. Przez cały czas, gdy ta zmiana jest wciąż rozważana, technologia staje się coraz bardziej wszechstronnym czynnikiem umożliwiającym zaspokojenie potrzeb biznesowych. Jednak pomimo rosnącej krytyczności technologii, jej historyczna niezdolność do reagowania na potrzeby biznesowe jest piętą achillesową w dążeniu przedsiębiorstw do uzyskania wysokiej wydajności i sprawności. Metodologie zwinne nie sprawiają, że cykl tworzenia oprogramowania jest szybszy lub bardziej elastyczny. Nawet w celu zwiększenia wydajności, metodologie Agile potrzebują dobrze wyszkolonych ekspertów, którzy poprowadzą zmiany, a większość organizacji nie ma personelu przeszkolonego w zakresie korzystania z Agile. Również Agile wydłuża czas wprowadzania produktów na rynek i nie rozwiązuje podstawowego problemu elastyczności. W rezultacie większość organizacji nie zmieniła fundamentalnie paradygmatu inżynierii stosowanego we współczesnym tworzeniu oprogramowania. Prezentujemy zupełnie nową platformę o nazwie RAGE AITM. Jest to rewolucyjna platforma do tworzenia aplikacji dla przedsiębiorstw, która może zakłócać tradycyjny cykl życia oprogramowania o rząd wielkości. Dzięki obszernemu zestawowi komponentów opartych na abstrakcyjnych meta modelach, RAGE AITM skraca cykl życia oprogramowania, począwszy od wzbudzania wymagań, aż po implementację i ćwiczenia z modelowania wizualnego. Model jest w rzeczywistości aplikacją w RAGE AITM. Wierzymy, że RAGE AITM może naprawdę sprawić, że przedsiębiorstwa staną się wydajne i sprawne.
Wgląd i inteligencja
WPROWADZENIE
Od wydajności i skuteczności przechodzimy do wglądu i inteligencji. W tej części skoncentrowano się na kwocie nieuporządkowanych danych, którymi dysponujemy, oraz na potrzebie kontekstowo odpowiednich ram umożliwiających odkrycie danych wywiadowczych na podstawie takich informacji. Zaczynamy od podkreślenia powszechnego dziś przeciążenia informacyjnego. Badamy, dlaczego ważny jest terminowy dostęp i analiza informacji. I dyskutujemy, dlaczego wartość informacji różnicowych jest kluczowym czynnikiem konkurencyjnym w większości branż. Następnie przystępujemy do omawiania popularnych metod tworzenia inteligencji maszynowej i reprezentacji wiedzy. Wskazujemy, dlaczego mało prawdopodobne jest, aby metody "czarnej skrzynki" były powszechnie akceptowane. Prezentujemy strukturę, która może umożliwić zarabianie na maszynach i reprezentację wiedzy w kontekście kontekstowym, identyfikowalnym. Kończymy rozdział listami kilku rzeczywistych aplikacji, z których obecnie korzystają tysiące ludzi.
Ekscytacja wokół Big Data
Co rozumiemy przez "duże zbiory danych"? Dlaczego tak dużo szumu na temat dużych zbiorów danych? Jakie możliwości dają duże zbiory danych przedsiębiorstwom? Digital Intelligence Today podaje następujące fakty na temat technologii cyfrowej :
• 90% wszystkich danych na świecie zostało wygenerowanych w ciągu ostatnich dwóch lat.
• Zużycie informacji w Stanach Zjednoczonych jest rzędu 3,6 zettabajty (3,6 miliona gigabajtów).
• Dwadzieścia osiem procent czasu pracowników biurowych spędza się na wysyłaniu e-maili.
• Ludzki mózg ma teoretyczną pojemność pamięci 2,5 petabajtów (petabajt = milion gigabajtów).
• Maksymalna liczba informacji, które ludzki mózg może obsłużyć, wynosi 7 (prawo Millera).
Podobnie w corocznych badaniach wszechświata cyfrowego IDC stwierdza:
• W połowie badania podłużnego, poczynając od danych zebranych w 005, a kończąc na 2020 r., Nasza analiza pokazuje stale rozszerzający się, coraz bardziej złożony i coraz bardziej interesujący cyfrowy wszechświat.
• W latach 2005-2020 wszechświat cyfrowy wzrośnie 300-krotnie, ze 130 eksabajtów do 40 000 eksabajtów lub 40 trylionów gigabajtów (ponad 5200 gigabajtów na każdego mężczyznę, kobietę i dziecko w 2020 r.). Od teraz do 2020 r. Wszechświat cyfrowy będzie prawie dwa razy większy co dwa lata.
• Podczas gdy część wszechświata cyfrowego posiadająca potencjalną wartość analityczną rośnie, tylko niewielka część, mniej niż pół procenta, została zbadana według IDC. IDC szacuje, że do 2020 r. Aż 33% wszechświata cyfrowego będzie zawierać informacje, które mogą być cenne, jeśli zostaną przeanalizowane, w porównaniu z 25% obecnie.
Nieustrukturyzowany tekst stanowi nieproporcjonalnie dużą część nowych informacji, do których mamy dostęp. Według niektórych szacunków 90% wszystkich danych w Internecie to tekst nieuporządkowany. Co nam to wszystko mówi? Przedsiębiorstwa mają nie tylko ogromną szansę na uzyskanie wglądu w te wszystkie nieustrukturyzowane dane, ale stanie się to konkurencyjną koniecznością analizy wszystkich nieustrukturyzowanych danych pod kątem wszystkich możliwych wglądów. Big data istniał na każdym etapie ewolucji komputerów. Nasze spojrzenie na duże zbiory danych zostało ukształtowane przez dostępną nam infrastrukturę obliczeniową. We wczesnych dniach obliczeń nawet niewielka ilość danych (według dzisiejszych standardów) wydawała się bardzo duża. Istnieje wiele firm, które zawsze miały znaczące dane transakcyjne, takie jak instytucje finansowe, takie jak American Express lub Citigroup, lub firmy informacyjne, takie jak Dun & Bradstreet. Chociaż firmy te mogą twierdzić, że cały czas zajmowały się dużymi zbiorami danych, nastąpił kwantowy, nieliniowy skok w ilości i rodzaju danych dostępnych nam dzisiaj z powodu Internetu i mediów społecznościowych. Obecnie powszechnie określa się, że duże zbiory danych obejmują cztery wymiary: objętość, różnorodność, szybkość i prawdziwość. Dziesięć lat temu przedsiębiorstwa planowały przechowywanie danych w terabajtach, co uznano za duży skok w porównaniu z gigabajtami. Teraz rutynowo mówimy o petabajtach, a szybkość, z jaką produkujemy petabajty informacji, maleje. Duże zbiory danych wykraczają daleko poza tradycyjne dane ustrukturyzowane i obejmują różnorodne dane nieustrukturyzowane - tekst, dźwięk, obrazy itd. Duża część gwałtownego wzrostu danych jest nieustrukturyzowana. Wymiar Velocity ma dwa aspekty - ogromny wzrost przepływu danych na całym świecie, który wymaga znacznie większej i masowo równoległej infrastruktury obliczeniowej oraz coraz bardziej rzeczywisty charakter informacji oraz jej przetwarzanie / zużycie. W przeciwieństwie do tradycyjnych danych strukturalnych, w których źródła danych były znane i dokładne, znaczna część dużych zbiorów danych pochodzi dziś z nieznanych i niewiarygodnych źródeł i przedstawia niebanalną dokładność i wiarygodność wyzwania. Poza ogromnym wzrostem ilości danych i dostępnej mocy obliczeniowej, emocje związane z dużymi zbiorami danych moim zdaniem dotyczą dwóch powiązanych ze sobą wymiarów:
1. Zdolność komputerów do analizowania "pełnych" zestawów danych oraz, w razie potrzeby, w czasie rzeczywistym, zamiast ograniczania się do próbek. Mamy teraz moc obliczeniową do analizowania kompletnych informacji zamiast ograniczania się do próbek i dokonywania założeń dotyczących cech populacji i tego, jak dobrze próbka reprezentuje populację. Szczerze mówiąc, większość ludzi używa statystyk parametrycznych na ślepo, bez względu na trafność przyjętych założeń dotyczących próby i populacji podstawowej. Zdolność analizy całej populacji uwalnia nas od tych arbitralnych, a czasem nierealnych założeń!
2. Rosnąca zdolność komputerów do analizy podstawowej struktury nieuporządkowanego tekstu! Co ciekawe, nieustrukturyzowany tekst tak naprawdę nie oznacza, że nie ma w nim żadnej struktury. Każdy tekst w języku formalnym ma z definicji strukturę zgodną z zasadami tego języka! Zatem przez tekst nieustrukturyzowany tak naprawdę nie mamy na myśli, że tekst nie ma żadnej struktury, tylko że struktura nie jest czytelna ani zrozumiała dla komputera stosującego techniki rutynowo stosowane wcześniej. Te dwa zmiany radykalnie zmieniły naszą zdolność do uzyskiwania wglądu i inteligencji ze wszystkich danych w przeciwieństwie do niczego wcześniej. W następnej części tego rozdziału przedstawiamy krótki przegląd wyzwań związanych z przeciążeniem i asymetrią informacji, które motywują nas do wykorzystania sztucznej inteligencji do wykorzystania inteligencji we wszystkich danych oraz krótki przegląd statystycznych metod uczenia maszynowego dla danych strukturalnych i dla języka naturalnego. Metody te, z jednym wyjątkiem, są w większości czarnymi skrzynkami i pozbawione są jakiegokolwiek kontekstowego rozumowania lub teorii. Wprowadzamy potężne ramy, wykorzystujące językoznawstwo obliczeniowe i drzewa decyzyjne, które są przejrzyste w swoim rozumowaniu, mogą oceniać dane w kontekście i mogą odzwierciedlać wcześniejszą wiedzę lub teorię
PRZEŁADUNEK INFORMACJI, ASYMETRIA I PODEJMOWANIE DECYZJI
Przeciążenie informacji
Przeciążenie informacji oznacza po prostu "zbyt dużo informacji". Eppler i Mengis zapewniają kompleksowy przegląd różnych rodzajów przeciążeń i trwających badań. Wśród rodzajów przeciążenia informacyjnego już zidentyfikowanego przez społeczność akademicką są przeciążenie poznawcze, przeciążenie sensoryczne, przeciążenie komunikacyjne , przeciążenie wiedzą oraz zmęczenie informacją syndrom . Inne badania próbowały zlokalizować i sprawdzić rodzaje przeciążenia informacji w ramach profesjonalnych usług, od audytu do strategii, doradztwa biznesowego, spotkań kierownictwa i zakupów w supermarketach. Do tej pory badania takie definiowały przeciążenie informacji różnymi sposobami istotnymi kontekstowo i mierzyły ich wpływ na dokładność decyzji. Na przykład naukowcy zajmujący się marketingiem porównali ilość informacji ze zdolnością przetwarzania informacji przez osobę. Przeciążenie informacji występuje, gdy podaż przekracza pojemność. W inny pokrewny sposób porównuje się ilość informacji, które dana osoba może zintegrować z procesem decyzyjnym w określonym czasie z ilością informacji, które należy przetworzyć. Pod tym względem "czas" jest uważany za najważniejszy element, a nie charakterystykę informacji. Wszystkie te badania wykazały, że przekazanie informacji ma pozytywny wpływ na dokładność i szybkość podejmowania decyzji przez człowieka do pewnego limitu, a ponadto ma negatywny wpływ. Schick i in. twierdzą, że przeciążenie informacji może dezorientować jednostkę, wpływać na jej zdolność do ustalania priorytetów i utrudniać przywołanie informacji. W miarę gromadzenia się informacji możemy oczekiwać, że wskaźnik dokładności decyzji wzrośnie i wzrośnie do momentu, w którym wartość informacji przyrostowych zacznie spadać. Ostatecznie nadmierne informacje będą miały negatywny wpływ na dokładność decyzji. Schroder i in. jako pierwsi zaproponowali odwróconą krzywą U do zobrazowania związku między dokładnością decyzji a przeciążeniem informacji. Kilku autorów od tego czasu zauważyło, że specyficzne cechy informacji - takie jak poziom niepewności związany z informacją, poziom niejednoznaczności, nowości, złożoności i intensywności - mają zróżnicowany wpływ na zdolność przetwarzania informacji przez osobę, a tym samym na przeciążenie informacji. Co więcej, ważne jest, aby uznać, że przy przeciążeniu informacjami dobrze udokumentowany efekt sekwencyjnej pozycji może stać się dość wyraźny. Efektem sekwencyjnej pozycji jest tendencja osoby do przypominania pierwszego i ostatniego elementu o wiele lepiej niż środkowych. W przypadku przeciążenia informacyjnego liczba elementów pośrednich będzie oczywiście bardzo duża i prawdopodobnie szczególnie związana z podejmowaniem decyzji. Biorąc pod uwagę takie efekty prymatu i aktualności, informacje, które docierają do środka okna przetwarzania decyzji, mogą zostać zignorowane. Zatem, jak można intuicyjnie zrozumieć, zbyt duża ilość informacji wpływa na dokładność podejmowania decyzji. Dlatego ważne jest, aby znaleźć sposób, aby nie przegapić krytycznych informacji i zapewnić, aby decyzje były podejmowane na podstawie wszystkich dostępnych informacji.
Asymetria Informacji
Podczas gdy przeciążenie informacjami odnosi się do wszystkich informacji, które ludzki umysł musi przetworzyć, i jego wpływu na decyzje podejmowane przez ludzi, asymetria informacji odnosi się do różnicy w informacjach dostarczanych lub dostępnych dla dwóch lub więcej osób. Asymetria informacji leży u podstaw wszystkich transakcji i interakcji między osobami i korporacjami. Asymetria informacji była przedmiotem znacznych badań akademickich w zakresie finansów przedsiębiorstw w odniesieniu do rynków finansowych i inwestorów. Organy regulacyjne, takie jak Komisja Papierów Wartościowych i Giełd, wprowadziły przepisy, których celem jest zapewnienie przejrzystości i jednolitości wszelkich informacji udostępnianych przez podmioty publiczne. Chociaż takie symetryczne udostępnianie informacji jest konieczne dla ochrony inwestorów, to również asymetria informacji jest podstawą wszelkiego handlu. Gdy jedna osoba ma inny zestaw informacji od drugiej, tworzy to podstawę różnicy w postrzeganej wartości, stwarzając okazję do handlu. Asymetria informacji może być wielu rodzajów. Trzy poniższe rysunki przedstawiają trzy rodzaje asymetrii.
Powyższy rysunek pokazuje asymetrię wynikającą z różnicowego dostępu do informacji. Może się to zdarzyć z wielu powodów, w tym z przeciążenia informacją. Jeśli masz za dużo informacji do przetworzenia i nie możesz dostać się do ważnej informacji, którą ma ktoś inny, istnieje asymetria informacji między tobą a drugą osobą.
Powyższy rysunek pokazuje inny rodzaj asymetrii informacji zależnej od dostępu. Na rysunku powyżej dwie osoby A i B przetwarzają różne nie nakładające się informacje na ten sam temat. Taki symetryczny stan informacji może wystąpić, gdy jedna osoba nie może uzyskać dostępu do krytycznych informacji z jakiegokolwiek powodu. Asymetria będzie widoczna w A i B, potencjalnie dochodząc do innego wniosku na ten temat. Jeśli tematem jest firma, A i B mogą potencjalnie mieć różne poglądy na temat wartości firmy, co może mieć wpływ na handel na rynkach finansowych lub na rynkach aktywów.
Rysunek powyższy pokazuje rodzaj asymetrii informacji w oparciu o interpretację informacji, którymi dysponuje osoba. Interpretacja odzwierciedla oczywiście kompetencje danej osoby i jej zrozumienie. Osoby A i B mogą mieć doświadczenie zawodowe, które może wpływać na sposób interpretacji informacji. Różnice w interpretacji mogą również wystąpić, gdy interpretacja wymaga prognozowania trendów biznesowych. Prognozowanie wymaga dużej wiedzy niepowiązanej z dostarczonymi informacjami, a zatem przedstawia inny rodzaj asymetrii. Prognozy zwykle opierają się na założeniach dotyczących przyszłych stanów, przy czym różnice w założeniach wpływają na interpretowane informacje i inne informacje, do których osoby A i B mogą potrzebować dostępu przy dokonywaniu transakcji handlowych, które mogą być kupnem i sprzedażą, bezpośrednio lub za pośrednictwem rynku mechanizm taki jak giełda. Oczywiście asymetria informacji może być zamierzona. Osoba A może przekazywać błędne informacje osobie B, aby B działał na podstawie niewystarczających lub niedokładnych informacji
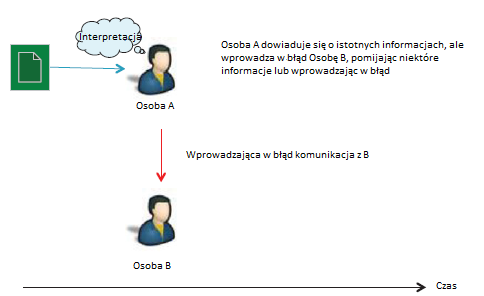
Wiele napisano na temat nierównowagi informacji rozpowszechnianej w niektórych branżach. Również konsumenci mają bardzo niewielki dostęp do obiektywnych informacji. Zasadniczo tego rodzaju asymetria informacji jest tym, co organy regulacyjne są zobowiązane ograniczyć lub usunąć. Wiele firm, zwłaszcza startupów, próbuje usunąć lub zmniejszyć taką asymetrię, zapewniając konsumentom taką samą ilość informacji, jaką mają sprzedawcy. Na przykład FindTheBest oferuje szeroki zakres informacji na temat produktów konsumenckich, w tym samochodów, smartfonów i szkół wyższych. W literaturze popularnej jest dodatkowo wiele innych przykładów asymetrii informacji, która została rozbita przez technologię. Ważne jest, aby zrozumieć, że rodzaje asymetrii zilustrowane na rysunkach powyżej są typowo niezbędne dla handlu. W rzeczywistości wszelka asymetria informacji nie jest zła; niektóre formy asymetrii są niezbędne. Aby być konkurencyjnym, przedsiębiorstwa nieustannie starają się znaleźć sposoby na odróżnienie siebie i swojej wartości produktu od wartości konkurencji. Ważnym czynnikiem umożliwiającym taką konkurencyjność jest wgląd, który przedsiębiorstwa mogą czerpać z dostępnych im danych. Im więcej asymetrii mogą stworzyć na swoją korzyść bez celowego wprowadzania w błąd innych uczestników rynku, tym większą przewagę konkurencyjną stworzą dla siebie. Ogólnie rzecz biorąc, ogromna eksplozja danych zaostrzyła wyzwanie związane z przeciążeniem informacją i stworzyła przedsiębiorstwom możliwości zwiększenia asymetrii informacji między nimi a ich konkurentami, niezbędnej do stworzenia lub utrzymania przewagi konkurencyjnej. Dziedzina sztucznej inteligencji wkroczyła, aby zapewnić rozwiązania zarówno w celu uzyskania przewagi konkurencyjnej, jak i przezwyciężenia wszelkich niekorzystnych warunków konkurencji wynikających z asymetrii informacji.
SZTUCZNA INTELIGENCJA na ratunek
Czy sztuczna inteligencja (AI) może poradzić sobie z gwałtownym wzrostem ilości informacji, przekształcić przeciążenie w korzyść, odkrywając krytyczne fragmenty informacji bez interwencji człowieka i wykorzystując wiedzę i doświadczenie ludzi? Istnieją znaczne dowody, że tak! AI jako dziedzina badań odnosi się do maszyn lub systemów, które mogą symulować pracę opartą na wiedzy wykonywaną przez ludzi. Badacze w tej dziedzinie definiują sztuczną inteligencję jako badanie i projektowanie inteligentnych agentów, dzięki którym agenci mogą działać na podstawie danych i podejmować decyzje tak, jak ludzie w racjonalnym środowisku. Jest to dziedzina interdyscyplinarna oparta na statystyce, informatyce, matematyce, psychologii, językoznawstwie i neuronauce.
Taksonomia rodzajów i metod problemów AI
Podstawowym celem sztucznej inteligencji jest po prostu uczynienie maszyn o wiele bardziej inteligentnymi, aby zbliżały się do ludzkiej inteligencji. Możemy przeanalizować ten podstawowy cel w wielu wymiarach (jak na rysunku 3.6), które obejmują rozumowanie, reprezentację wiedzy, automatyczne uczenie się, przetwarzanie języka naturalnego, postrzeganie oraz zdolność do przenoszenia i manipulowania obiektami. Pozyskiwanie i reprezentacja wiedzy stanowi podstawę inteligencji maszyn. My, ludzie, w ciągu naszego życia gromadzimy ogromną wiedzę, zarówno faktyczną, jak i osądzającą. Kluczowym aspektem inteligencji maszynowej jest zdobywanie i / lub osadzanie takiej wiedzy w maszynach. Podstawową metodą promowania zdobywania wiedzy przez maszyny jest rozumowanie dedukcyjne i indukcyjne. Uczenie maszynowe odnosi się do algorytmów obliczeniowych, które odkrywają i poprawiają wiedzę poprzez algorytmiczną analizę wzorców w informacji. Ważnym aspektem uczenia maszynowego jest zdolność maszyn do aktualizowania takiej inteligencji z lub bez specjalistycznej pomocy człowieka. Przetwarzanie języka naturalnego (NLP) zaspokaja potrzebę, aby maszyny były w stanie czytać i rozumieć języki, w których ludzie mówią lub piszą. Takie potrzeby można następnie wykorzystać w sytuacjach od prostego indeksowania dokumentów do interpretacji i generowania dokumentów takich jak ludzie rób te rzeczy. Niektóre osoby zaczynają nazywać to rozumieniem języka naturalnego (NLU). NLP lub NLU to uczenie maszynowe skoncentrowane na języku naturalnym. NLU jest przedmiotem lingwistyki komputerowej. Percepcja maszynowa lub widzenie komputerowe to zdolność do pobierania danych z czujników obiektów fizycznych, takich jak kamery, mikrofony, drony, sprzęt domowy i urządzenia medyczne, w celu wywnioskowania fizycznych wymiarów i właściwości implikowanych przez dane. Ściśle związana jest zdolność do radzenia sobie z czynnościami fizycznymi, takimi jak ruch i nawigacja, które wymagają maszyn posiadających możliwości zrozumienia lokalizacji, mapowania i planowania ruchu. Wizja komputerowa jest także formą uczenia maszynowego skoncentrowaną na ruchu i percepcji. Różne problemy biznesowe wymagają, aby maszyny mogły mieć jeden lub więcej z tych wymiarów. W miarę jak maszyny stają się bardziej inteligentne w stosunku do nich, będą coraz bardziej zdolne do podejmowania inteligentnych decyzji w różnych domenach aplikacji. Oczywiście jest to rozległe i złożone przedsięwzięcie o wielu wymiarach, obszarach tematycznych i złożoności.
Wyniki AI
Jak wspomniano powyżej, aplikacje AI koncentrują się na rozwijaniu inteligencji i wglądu, które maszyny mogą wnioskować na podstawie danych z pomocą człowieka lub bez niego. Różne wymiary inteligencji sztucznej lub maszynowej można przełożyć na rodzaj rozwiązań, które obsługiwały inteligentne maszyny. Możemy ogólnie podzielić wyniki rozwiązania AI na pięć typów: grupowanie, ekstrakcja, klasyfikacja, prognozowanie i interpretacja. Przydatne jest również szerokie kategoryzowanie wyników tych rozwiązań pod względem ich zaangażowania. Podejścia statystyczne parametryczne próbują modelować dane w oparciu o wstępnie zdefiniowane, wyraźnie zaprogramowane modele i algorytmy, takie jak regresja logistyczna, wielorakie analizy dyskryminacyjne oparte na ścisłych założeniach dotyczących danych w szerszej populacji. Metody uczenia maszynowego próbują pozwolić, aby dane sugerowały model i zazwyczaj przetwarzały całą populację danych zamiast losować próbkę. Wreszcie, ponieważ dotyczy tekstu w języku naturalnym, kluczowe rozwiązanie wynikiem jest potrzeba interpretacji i zrozumienia znaczenia tekstu. Klastrowanie odnosi się do procesu znajdowania klastrów obiektów, które są do siebie podobne i odróżniają się od danych, które są niepodobne. Domeny biznesowe, takie jak wykrywanie prawne, skargi klientów i wyszukiwanie ad hoc, mogą korzystać ze skutecznego grupowania danych wejściowych. Grupowanie odbywa się głównie w celu uzyskania wglądu w dane, i jest to oczywiście proces iteracyjny. Jest to ściśle związane z klasyfikacją. Poniżej pokazano cztery odrębne zestawy obiektów w celu zilustrowania czystego oddzielenia, które następuje przez grupowanie.
Dwie gromady - A i B - są zilustrowane, a linia między nimi jest odległością między nimi. W praktyce zestawy danych w świecie rzeczywistym są znacznie bardziej nieporządne, ponieważ wszystkie obiekty są ze sobą powiązane i nie są tak łatwe do oddzielenia, jak pokazano na rysunku. Grupowanie zestawów danych w świecie rzeczywistym wymaga iteracyjnego ustawiania parametrów i dostrajania. Klasyfikacja odnosi się do celu, jakim jest klasyfikacja dokumentu lub podmiotu w jednej z N wstępnie zdefiniowanych kategorii. Przykłady obejmują przewidywanie, czy firma zmierza w kierunku bankructwa lub jest w dobrej kondycji, klasyfikowanie dokumentu na temat, którego dotyczy, klasyfikowanie skargi klienta do kategorii usług i tak dalej. Bardzo duża liczba aplikacji AI wymaga klasyfikacji. Klasyfikacja jest naturalnym rozszerzeniem klastrowania. Główną różnicą jest to, że w klasyfikacji znamy kategorie z wyprzedzeniem, a w grupowaniu odkrywamy kategorie na podstawie danych. Klasyfikatory są opracowane na podstawie próbki, a
następnie wykorzystane do przewidywania kategorii nowego przedmiotu. Rysunek ilustruje klasyfikację na podstawie dwóch zmiennych - 1 i 2 - oraz dwóch kategorii - A i B.
W tym prostym przypadku dane starannie zestawiają się w dwie odrębne przestrzenie. Jak wspomniano w przypadku klastrowania, rzeczywiste zestawy danych są znacznie bardziej złożone i wymagają sporej ilości analizy danych i dostrajania modeli w celu osiągnięcia znaczącej dokładności klasyfikacji. W przypadku większości problemów z klasyfikacją istnieją cztery aspekty. Pierwszy to zestaw "niezależnych" zmiennych, które mogą być jakościowe [0, 1,…] lub ciągłe. Zakłada się, że ten zestaw zmiennych jest przyczynowo związany z wynikiem, zwany zmienną "zależną". W wyniku klasyfikacji zmienna zależna jest zawsze kategoryczna. Przykładem zmiennej zależnej jest prognoza bankructwa, w której interesuje nas, czy jednostka gospodarcza zbankrutuje. Drugi to przykładowe dane, zwane również zestawem danych szkoleniowych. Zbiór danych treningowych będzie zawierał wartości zarówno zmiennych zależnych, jak i niezależnych dla szeregu obserwacji reprezentatywnych dla populacji, dla której klasyfikator ma zostać zbudowany. Trzecim aspektem jest zestaw danych walidacyjnych, na który składają się obserwacje, na podstawie których klasyfikator może być walidowany. Ostatni, czwarty aspekt, to koszt błędnej klasyfikacji. Koszty błędnej klasyfikacji nie muszą być takie same dla każdej kategorii wyników. Na przykład koszt sklasyfikowania zdrowej firmy jako upadłej może nie być taki sam, jak koszt sklasyfikowania upadłej firmy jako zdrowej, jeśli jesteś pożyczkodawcą dla firmy. Niektórzy analitycy wiążą również wcześniejsze prawdopodobieństwo z każdym wynikiem w populacji. Model klasyfikacji nazywa się "klasyfikatorem". Ekstrakcja odnosi się do potrzeby wyodrębnienia określonych danych z dokumentów. Potrzeba ta może się objawiać, na przykład, gdy należy uzyskać dostęp do tabel danych w nieustrukturyzowanym lub częściowo ustrukturyzowanym dokumencie i umożliwić działanie. Typowym przykładem są dane finansowe, które należy pobrać ze sprawozdań finansowych w dokumencie takim jak raport z audytu. Ponieważ nie istnieją standardy zarówno w zakresie semantycznego, jak i fizycznego raportowania takich danych, ekstrakcja nie może wykorzystywać żadnej predefiniowanej logiki specyficznej dla lokalizacji. Ponieważ nie ma znormalizowanego sposobu opisywania pozycji sprawozdania finansowego, każda firma postępuje według własnego uznania przy tworzeniu sprawozdań finansowych - planu kont, formatu sprawozdania finansowego i tak dalej. Problemem ekstrakcji jest tutaj dokładne wyodrębnienie sprawozdania finansowego - etykiet, właściwości, takich jak wyciąg według dat, waluty, jednostki i wartości pozycji. Po wyodrębnieniu te wartości i elementy muszą zostać znormalizowane na kilku poziomach. Wyodrębnianie może również wiązać się z potrzebą zidentyfikowania i wyodrębnienia podziałów, które mogą być wymienione gdzie indziej w dokumencie PDF. Podział na pozycję Majątek i wyposażenie znajduje się w przypisie do sprawozdania finansowego. Podobnie bardzo trudnym problemem biznesowym jest konieczność uzgodnienia faktur z podstawowymi umowami prawnymi, na których są oparte. W takim przypadku wyświetlana jest główna umowa o świadczenie usług, a jako prosty przykład pobierana jest opłata rekrutacyjna określona w klauzuli w umowie w celu porównania z fakturą. Interpretacja odnosi się do potrzeby interpretacji treści nieustrukturyzowanych, w komunikatach prasowych, raportach z badań, umowach prawnych itp., W odniesieniu do określonego celu, jakim może być inwestycja, audyt kosztów, perspektywa sprzedaży lub dowolna liczba innych rzeczy. Spośród wymienionych powyżej typów wyników interpretacja nie poświęcała względnie uwagi dużej ilości literatury dotyczącej uczenia maszynowego, przetwarzania języka naturalnego i analizy sentymentów. Uważamy, że dzieje się tak głównie dlatego, że interpretacja języka naturalnego wymaga głębokiego zrozumienia języka. Jak dotąd większość prac nad uczeniem maszynowym opierała się na statystykach obliczeniowych, a nie na lingwistyce obliczeniowej.
Metody rozwiązywania AI
Opracowano szereg metod i narzędzi w celu rozwiązania różnych rodzajów problemów opisanych w poprzedniej sekcji. Metody te odkrywają wgląd i inteligencję z danych bazowych i osadzają tę inteligencję w maszynach. Metody wahają się od parametrycznych metod statystycznych, takich jak regresja, do metod nieparametrycznych, takich jak maszyny wektorów nośnych. Należy również zauważyć, że w przypadku niektórych takich problemów można zastosować więcej niż jedną metodę. Zainteresowani czytelnicy są kierowani do Alpaydim w celu uzyskania szczegółowych wyjaśnień technicznych aspektów wielu z tych metod. Ponieważ w tej książce koncentrujemy się na uczeniu maszynowym bez wstępnie zaprogramowanych algorytmów opartych na założeniach dotyczących danych lub populacji bazowej, dlatego dla zwięzłości podzielimy te metody na dwie kategorie - uczenie maszynowe ze statystykami obliczeniowymi i uczenie maszynowe języka naturalnego z obliczeniową językoznawstwo. Wszystkie metody ML, z wyjątkiem ML - językoznawstwa obliczeniowego - należą do uczenia maszynowego z kategorią statystyki obliczeniowej. Uczenie maszynowe na podstawie danych wyraźnie sugeruje dostępność danych. W problemy z klasyfikacją, takie dane w niektórych przypadkach będą również zawierać dane dotyczące pożądanego wyniku, często nazywane "etykietą". Dane mogą być uzupełnione wiedzą ludzką lub specjalistyczną. Rodzaj wiedzy i sposób jej reprezentowania jest funkcją typu problemu AI. Zadania uczenia maszynowego zazwyczaj dzieli się na trzy szerokie kategorie w zależności od poziomu ludzkiej lub specjalistycznej pomocy dostępnej dla maszyny:
• Uczenie się bez nadzoru : Żadne wyraźne "etykiety" nie są dostępne, a algorytm uczenia musi znaleźć własną strukturę w danych wejściowych. Uczenie się bez nadzoru jest wykorzystywane jako środek do osiągnięcia celu.
• Uczenie częściowo nadzorowane : Uczenie częściowo nadzorowane odnosi się do pewnej wiedzy dostępnej algorytmowi uczenia maszynowego, która może być niepełna. Algorytm uczenia się musi łączyć taką wiedzę z inną strukturą danych, aby zbudować swój model.
• Uczenie nadzorowane : Algorytm uczenia maszyny ma próbkę danych z danymi wejściowymi i pożądanymi danymi wyjściowymi i musi zbudować model, który będzie wykorzystywał dane wejściowe do przewidywania lub odwzorowywania pożądanego wyniku.
• Uczenie ze wzmocnieniem : Program komputerowy wchodzi w interakcję z dynamicznym środowiskiem, w którym musi osiągnąć określony cel (np. Prowadzić pojazd), bez nauczyciela wyraźnie mówiącego mu, czy osiągnął swój cel. Innym przykładem jest nauka gry w grę przeciwko przeciwnikowi. Ostatnio system Google Deepmind AlphaGo odniósł historyczne zwycięstwo nad koreańskim arcymistrzem Lee Sidolem w Go, wykładniczo bardziej złożoną grę niż szachy
NAUKA MASZYNY Z WYKORZYSTANIEM STATYSTYK OBLICZENIOWYCH
Mówi się, że program komputerowy uczy się z doświadczenia; to znaczy "… z doświadczenia E w odniesieniu do pewnej klasy zadań T i wydajności P, jeżeli jego wydajność na zadaniach w T, mierzona przez P, poprawia się wraz z doświadczeniem E". Odkąd Alan Turing zaproponował zastąpienie pytania "Czy maszyny mogą myśleć?" pytanie "Czy maszyny mogą robić to, co my (my jako myślące istoty)?", dostrzegło różnicę między terminami operacyjnymi a terminami poznawczymi. Jesteśmy jednak mniej przekonani, że może istnieć rzeczywiste rozróżnienie między operacyjnym a poznawczym warunki Breiman sugeruje, że istnieją dwie kultury w stosowaniu modelowania statystycznego do wyciągania wniosków z danych - model danych zakładający, że dane są generowane przez dany stochastyczny model danych i model algorytmiczny, który traktuje dane jako nieznane. Prawdopodobnie model danych, zwany także statystyką parametryczną, reprezentuje najwcześniejszą i najprostszą formę uczenia maszynowego. Parametryczne metody statystyczne radziły sobie ze stosunkowo prostymi interakcjami między danymi. Wielowymiarowa analiza dyskryminacyjna była najwcześniejszą rygorystyczną próbą zrozumienia wzorów w liniowej przestrzeni wielowymiarowej, która różnicowała dane należące do różnych kategorii Regresja logistyczna została powszechnie przyjęta jako sposób przezwyciężenia th Ograniczenia analizy dyskryminacyjnej. Srinivasan i in. wykorzystują regresję logistyczną do stworzenia modelu przewidywania bankructwa przedsiębiorstw. Wykazują skuteczność metody regresji logistycznej, znajdując dokładności prognoz nawet do 90% na okres do dwóch lat przed bankructwem. Niezależnie od powodzenia tych metod, parametryczne metody statystyczne mają poważne ograniczenia w modelowaniu pełnej złożoności rzeczywistych danych i procesów. Współczesne uczenie maszynowe (lub model algorytmiczny) pojawiło się jako dziedzina interdyscyplinarna z badania wzorców, obliczeniowej teorii uczenia się w AI, optymalizacji matematycznej, statystyki parametrycznej i lingwistyki obliczeniowej. Uczenie maszynowe bada badanie i budowę algorytmów, które można automatycznie wywnioskować z danych. Takie algorytmy uczą się, budując model z przykładowych danych, które zazwyczaj zawierają dane wyników. Obejmują one nadzorowane podejścia, takie jak sztuczne sieci neuronowe, automaty komórkowe, drzewa klasyfikacji i regresji, logika rozmyta, algorytmy genetyczne i programowanie, maksymalna entropia, maszyny wektorów nośnych i analiza falkowa. Ponadto istnieją podejścia do nauki bez nadzoru, które próbują ujawnić wzorce w danych bez wiedzy o wynikach, w tym sieci neuronowe Hopfielda (Hopfield, 1982) i mapy samoorganizujące się (Kohonen, 2001). Te metody algorytmiczne mogą modelować złożone, nieliniowe relacje w danych bez restrykcyjnych założeń wymaganych przez podejścia parametryczne (Guisan i Zimmermann, 2000; Peterson i Vieglais, 2001; Olden and Jackson, 2002a; Elith i in., 2006). Poniżej krótko opisujemy najpopularniejsze metody uczenia maszynowego
Drzewa decyzyjne
Drzewa klasyfikacji i regresji (CART) pojawiły się w ostatnim czasie jako potężne podejście modelujące do automatycznego opracowywania klasyfikatorów w złożonych zestawach danych, szczególnie tam, gdzie można przewidywać, że zmienne predykcyjne będą oddziaływać w sekwencji, takiej jak hierarchiczna. CART popiera przekonanie, że wiele rzeczywistych wyników nie jest spowodowanych jednoczesnym oddziaływaniem wszystkich zmiennych przyczynowych, krytycznym założeniem we wszystkich statystykach parametrycznych i wielu współczesnych metodach uczenia maszynowego opisanych w tym rozdziale. CART jest szeroko stosowany w wielu naukach stosowanych, w tym w medycynie, informatyce i psychologii). De'ath i Fabricius dostrzegają zalety CART podczas modelowania danych nieliniowych zawierających zmienne niezależne podejrzane o interakcję w sposób hierarchiczny. Olden i in. przeglądali dużą liczbę aplikacji CART w ekologii. Frydman, Altman i Kao zastosowali CART do opracowania modelu predykcyjnego upadłości korporacyjnej CART
to binarna metoda partycjonowania rekurencyjnego, która przyjmuje jako dane wejściowe kategoryczne oraz ciągłe zmienne dane i generuje drzewo decyzyjne jako model klasyfikacji, który klasyfikuje obserwacje do pożądanych kategorii wyników. Model budowany jest przez podzielenie obserwacji na partycje binarne w oparciu o kryterium wykorzystujące zmienne niezależne. Obserwacje, reprezentowane przez węzeł w drzewie decyzyjnym, są powtarzalnie dzielone na dwa węzły potomne, w tym, w razie potrzeby, ciągle tę samą zmienną. Zatem każdy węzeł nadrzędny może dać początek dwóm węzłom podrzędnym, a z kolei każdy węzeł podrzędny może być podzielony, tworząc dodatkowe elementy podrzędne. Ten proces podziału powoduje sekwencyjne i wielokrotne dzielenie zestawu danych, co pozwala modelowi wynikowemu odkryć głębsze wzorce klasyfikacji w danych. Budowanie modelu CART obejmuje instrukcje dla maszyny, aby rozpocząć budowanie drzewa, zatrzymać proces budowania drzewa, a następnie pozwolić człowiekowi przycinającemu drzewo
wybrać optymalne drzewo. Tworzenie drzewa rozpoczyna się w węźle głównym z całym zestawem danych. Wszystkie możliwe warunki podziału dla każdej możliwej wartości dla wszystkich zmiennych niezależnych są określone. Drzewo jest następnie dzielone przez wybranie warunku podziału, który maksymalizuje "czystość" wynikowego podziału, przy czym czystość jest definiowana albo jako miara oparta na informacji (entropia), albo wskaźnik Giniego dla klasyfikacji i sum kwadratów wokół średnich grupowych dla drzew regresji . Tworzenie drzewa kończy się, gdy przyrostowy przyrost od następnego podziału węzła nie jest znaczący. Można również zatrzymać budowę drzew z zewnętrznie narzuconymi ograniczeniami, takimi jak określona liczba obserwacji w każdym z węzłów potomnych lub liczba podziałów w drzewie. Wybór ostatecznego klasyfikatora (drzewa) może obejmować etap przycinania, w którym człowiek eliminuje węzły klasyfikatora z powodu kosztów lub złożoności lub z powodu braku przyczynowego uzasadnienia. Wyboru klasyfikatora
można również dokonać automatycznie poprzez X-krotną walidację krzyżową . Istnieją metody, takie jak przyspieszanie i workowanie, których celem jest automatyczne generowanie bardziej wytrzymałych i możliwych do uogólnienia drzew. Breiman wykazał, że użycie zestawu drzew, w którym każde drzewo rośnie w losowo wybranych podzbiorach danych, może zapewnić znaczny wzrost dokładności klasyfikacji. Losowe lasy, jak się je nazywa, pojawiły się jako potężny sposób tworzenia drzew decyzyjnych, które są bardziej ogólne i solidne. Rysunek ilustruje klasyfikator CART do przewidywania bankructwa przedsiębiorstw na podstawie danych finansowych.
Zestaw danych i zmienne opisano w Srinivasan. Kluczowymi zmiennymi wybranymi przez klasyfikatora są: Skorygowany szybki stosunek, Przepływy pieniężne z operacji do sprzedaży, Zadłużenie do aktywów ogółem i Współczynnik bieżący. Należy zwrócić uwagę na trzy rzeczy dotyczące klasyfikatora CART. Przede wszystkim jest identyfikowalny i przejrzysty. Widzimy zmienne i logikę, które składają się na model i decydujemy, czy pasuje on do naszej wcześniejszej wiedzy. To nie jest czarna skrzynka. Po drugie, klasyfikator CART jest znacznie prostszy do interpretacji niż inne modele uczenia maszynowego i popularne parametryczne modele statystyczne, takie jak wielowymiarowy model regresji logistycznej. Po trzecie, klasyfikator CART jest wysoce skalowalny, szybki i może obsłużyć bardzo dużą liczbę zmiennych wejściowych bez powodowania nadmiernego dopasowania drzew. Wreszcie, nieodłączna "logika" w CART jest łatwo widoczna i ma sens finansowy.
Sztuczne sieci neuronowe (ANN)
Modele sztucznej sieci neuronowej (ANN) lub, bardziej ogólnie, perceptron wielowarstwowy, to podejście modelujące, które podobno zainspirowane jest funkcjonowaniem ludzkiego mózgu (Alpaydim, 2010). Ludzki mózg składa się z bardzo dużej liczby jednostek przetwarzających (104). Te jednostki przetwarzające, zwane neuronami, działają poprzez łączenie z kolei z około 104 innymi neuronami poprzez połączenia zwane synapsami. W ludzkim mózgu neurony te działają równolegle. W ludzkim mózgu neurony komunikują się ze sobą za pomocą sygnałów elektrycznych, które przemieszczają się wzdłuż "aksonu" do odbierającego neuronu
Punkt, w którym akson łączy dendryt komórki odbiorczej, ma ścianę zwaną synapsą. Komunikacja między neuronami odbywa się poprzez uwalnianie różnych rodzajów chemikaliów w odpowiednich ilościach odzwierciedlających to, co ma być przekazane. ANNs próbują replikować tę strukturę. Chociaż istnieje wiele nadzorowanych i nienadzorowanych metod uczenia się dla ANNs, opisujemy bardzo często stosowaną metodę: jedną ukrytą, nadzorowaną, przekaźnikową sieć neuronową przekazywaną do przodu szkoloną przez algorytm propagacji wstecznej .
pojedyncza sieć przesyłania dalej ukrytej warstwy zawiera warstwę wejściową [xi], pośrednią nieliniową warstwę transformacji zwaną warstwą ukrytą [zh] i warstwę wyjściową [ym], przy czym każda warstwa zawiera jeden lub więcej neuronów. Może być więcej niż jedna ukryta warstwa. W przypadku wielu ukrytych warstw maszyna podejmie próbę modelowania kolejnej ukrytej warstwy w podobny sposób jak transformacja poprzedniej ukrytej warstwy. Liczba neuronów w ukrytej warstwie może być wybrana arbitralnie lub ustalona empirycznie przez modelera, aby zminimalizować kompromis między uprzedzeniem a wariancją. Podobnie jak inne modele statystyczne, dodanie neuronów i warstw zwiększy precyzję modelu w próbce treningowej, ale spowoduje nadmiernie dopasowany model, który spowoduje zmniejszenie przywołania modelu. Niższe wycofanie oznacza mniejszą uogólnienie. Szkolenie sieci neuronowej zazwyczaj wymaga algorytmu propagacji błędu, który wyszukuje optymalny zestaw generowanych wag połączeń sygnał wyjściowy z małym błędem w stosunku do obserwowanego wyjścia (tj. minimalizujący kryterium dopasowania). W przypadku ciągłych zmiennych wyjściowych powszechnie stosowanym kryterium jest funkcja błędu najmniejszych kwadratów, natomiast w przypadku dychotomicznych zmiennych wyjściowych powszechnie stosowanym kryterium jest funkcja błędu krzyżowania entropii, która jest podobna do logarytmu prawdopodobieństwa. Algorytm dostosowuje wagi połączeń wstecz, warstwa po warstwie, w kierunku najbardziej stromego zejścia, minimalizując w ten sposób funkcję błędu. Trening sieci jest procesem rekurencyjnym, w którym obserwacje z danych szkolenia są wprowadzane z kolei do sieci, za każdym razem modyfikując wagi połączenia wejściowego ukrytego i ukrytego wyjściowego. Procedurę tę powtarza się dla całego zestawu danych szkoleniowych (tj. dla każdej z n obserwacji) dla pewnej liczby iteracji lub epok, aż do osiągnięcia reguły zatrzymania (np. poziomu błędu). Przed szkoleniem sieci zmienne niezależne należy przekonwertować na wyniki Z (od 0 do 1) w celu ujednolicenia skal pomiarowych wejść do sieci. Podobnie jak w przypadku metod parametrycznych, metod uczenia maszynowego, w tym ANN, użyj zestawu danych treningowych do oszacowania modeli, a następnie sprawdź dopasowanie modelu za pomocą zestawu danych testowych. ANN z podejściem sprzężenia zwrotnego opartym na propagacji wstecznej mają kilka zalet w stosunku do tradycyjnych metod parametrycznych: (1) ich nieparametryczny charakter, ponieważ nie wymagają szczególnych założeń dystrybucyjnych zmiennych niezależnych, (2) zdolność do łatwego modelowania powiązań nieliniowych oraz (3) dostosowanie interakcji zmiennych bez specyfikacji z góry. Naszym zdaniem ANN mają jednak poważne ograniczenia. Pierwszą i najważniejszą jest to, że ANN są w dużej mierze "czarną skrzynką". Chociaż podjęto wysiłki w celu opracowania różnych sposobów zrozumienia wkładu zmiennych niezależnych, tutaj wciąż nie ma zrozumiałego wyjaśnienia wag połączeń i warstw. Przyjęcie takich nieprzejrzystych metod, szczególnie w przypadku aplikacji biznesowych o kluczowym znaczeniu, będzie trudne. Po drugie, i pokrewnym zagadnieniem, jest problem przyczynowości, szczególnie gdy stosuje się kilka ukrytych warstw. Ponieważ interakcje zmienne, które maszyna określa w ukrytych warstwach, nie są z góry określone, ryzykujemy, że model będzie bardzo specyficzny dla próbki i zidentyfikuje fałszywe zależności statystyczne. Natomiast w CART możemy obserwować interakcje zmiennych i decydować, czy mają one sens.
Maszyny jądra
Maszyny jądra, zwane również maszynami wektorów wsparcia (SVM), są nadzorowanymi modelami uczenia się z powiązanymi algorytmami uczenia się do klasyfikacji i prognozowania. Podczas gdy domyślny SVM jest algorytmem dwuklasowym, SVM może być również zastosowany do problemów wieloklasowych. SVM próbuje utworzyć klasyfikator, który dzieli kategorie w tych samych danych tak szeroko, jak to możliwe, przy użyciu podanych wartości zmiennych przyczynowych. Nowe przykłady są następnie mapowane w tę samą przestrzeń i przewiduje się, że należą do kategorii na podstawie strony, na którą wpadają. Bardziej formalnie, maszyna wektora nośnego uczy się oddzielającej hiperpłaszczyzny lub zestawu hiperpłaszczyzn w przestrzeni o dużych wymiarach (wartości dla wszystkich zmiennych niezależnych tworzą tę przestrzeń o dużych wymiarach), które mogą być używane do klasyfikacji, regresji lub innych zadań. Skuteczna hiperpłaszczyzna zmaksymalizuje odległość punktów danych treningowych dowolnej klasy do najbliższej granicy kategorii. Zbiór danych treningowych jest ogólnie określony za pomocą stałej liczby zmiennych i punktów danych; to znaczy reprezentuje przestrzeń o skończonych wymiarach. Z doświadczenia wiemy jednak, że większości zbiorów danych i zjawisk w świecie rzeczywistym nie da się tak łatwo oddzielić liniowo w przestrzeni skończonej. Ani klasyfikator A, ani B nie rozdzielają klas czysto na rysunku
Aby rozwiązać ten problem, SVM przekształca pierwotną przestrzeń o skończonych wymiarach w abstrakcyjną przestrzeń o wyższych wymiarach, używając kombinacji wektorów zmiennych za pomocą metody mnożenia wektora algebraicznego zwanej "iloczynem kropkowym". Zatem zmienne niezależne zostaną połączone, aby utworzyć nowe zmienne abstrakcyjne. Chodzi o to, że ta transformacja znacznie ułatwi separację w wynikowej przestrzeni o wyższych wymiarach. Hiperpłaszczyzny w przestrzeni o wyższym wymiarze są zdefiniowane jako zbiór punktów, których iloczyn skalarny z wektorem w tej przestrzeni jest stały. Wektory definiujące hiperpłaszczyzny można wybierać jako kombinacje liniowe z parametrami αa;i zmiennych, xi. Jednym rozsądnym wyborem jako najlepszej hiperpłaszczyzny jest ta, która reprezentuje największą separację lub margines między dwiema klasami. Więc wybieramy Wybieramy więc hiperpłaszczyznę, aby odległość od niego do najbliższego punktu danych z każdej strony była zmaksymalizowana. Rysunek poniżek ilustruje hiperpłaszczyznę, która osiąga maksymalne rozdzielenie dla dwóch klas A i B powyżej.
Jeśli dane treningowe są liniowo rozdzielne, możemy wybrać dwa hiperpłaszczyzny w taki sposób, aby oddzielić dane i nie ma między nimi punktów; wtedy możemy spróbować zmaksymalizować ich odległość. Punkty danych leżące na marginesach nazywane są wektorami pomocniczymi. Te hiperpłaszczyzny można opisać równaniami:
w ⋅ x - b = 1
i
w ⋅ x - b = ?1
gdzie ⋅ oznacza iloczyn skalarny, a w wektor normalny do hiperpłaszczyzny. Parametr b || w || określa odsunięcie hiperpłaszczyzny od początku wzdłuż wektora normalnego w. Klasyfikator SVM można sformułować jako problem wypukłego programowania kwadratowego, który ma wiele wydajnych algorytmów. Chociaż podstawową maszynę SVM można zastosować tylko do problemów dwuklasowych, można to pokonać za pomocą różnych technik. Najczęstszym z nich jest zmniejszenie problemu wieloklasowego na wiele problemów dwuklasowych. Crammer i Singer zaproponowali metodę SVM wieloklasową, która zamienia problem klasyfikacji wieloklasowej w pojedynczy problem optymalizacji, zamiast rozkładać go na wiele problemów klasyfikacji binarnej. Maszyny jądra są bardzo podobne do ANN. Mają te same mocne i słabe strony. Największą słabością z naszego punktu widzenia jest czarna skrzynka modelu i trudności związane z interpretacją parametrów ostatecznego modelu. Ogranicza to zastosowanie tej metody do problemów, w których zrozumienie komponentów modelu i ich logicznego dopasowania nie jest konieczne.
Architektury głębokiego uczenia się
Architektura głębokiego uczenia się opiera się na założeniu, że obserwowane dane są generowane przez interakcje wielu różnych czynników na różnych poziomach. Algorytmy dogłębnej nauki stały się dość popularne, szczególnie w dziedzinie widzenia komputerowego, które obejmuje takie aplikacje, jak jazda autonomiczna oraz rozpoznawanie obrazu i głosu. Konwolucyjne głębokie sieci neuronowe są wykorzystywane w wizji komputerowej, gdzie ich sukces jest dobrze udokumentowany (np. Patrz Lecun, 1998, aplikacja do rozpoznawania rozpoznawania znaków odręcznych). Bengio (2009) sugeruje, że aby nauczyć się skomplikowanych funkcji, które mogą reprezentować abstrakcje wysokiego poziomu, potrzeba wielu poziomów operacji nieliniowych, takich jak sieci neuronowe z wieloma ukrytymi warstwami. Argument leżący u podstaw głębokiego uczenia się polega przede wszystkim na tym, że aby właściwie reprezentować złożone interakcje, potrzebujemy metod reprezentacyjnych, które naśladują takie wielopoziomowe, wielowarstwowe abstrakcje. Metody głębokiego uczenia się próbują uczyć się, budując chciwe modele warstwa po warstwie, próbując rozplątać złożone abstrakcje. Metody głębokiego uczenia są konfigurowane jako podejście do uczenia się bez nadzoru, co eliminuje potrzebę dużej ilości danych oznaczonych. Ogólnie rzecz biorąc, wszystkie metody głębokiego uczenia się cierpią z powodu tej samej słabości - braku teorii lub wyraźnej przyczynowości wokół wielu metod. Są to czarne skrzynki z większością potwierdzeń ich ważności wykonanych empirycznie w formie ich wyników. Są to zasadniczo metody brutalnej siły, które rzekomo wykorzystują replikację funkcji ludzkiego mózgu jako motywację dla ich architektury. Naszym zdaniem, chociaż są one użyteczne i mogą być bardzo skuteczne w kilku klasach problemów, ich sukces zależy od dostępności ogromnych ilości jednorodnych danych odzwierciedlających wszystkie możliwe przyczyny kombinacje, w tym powiązany kontekst, co rzadko się zdarza. W tym sensie nie odtwarzają one w pełni funkcji ludzkiego mózgu. Mózg ma ogromną ilość zgromadzonej wiedzy i preferencji, które czerpie z działania na bieżące bodźce. W ludzkim mózgu neurony wiedzą, co komunikują się z innymi neuronami i dlaczego. Przesyłanie wiadomości między neuronami opiera się na zgromadzonej wiedzy, a nie wyłącznie na przypadkowej kombinacji zmiennych wejściowych. Ludzie nauczyli się przyczyny i skutku przez lata doświadczeń i formalnej edukacji. ANN próbują nauczyć się tego na podstawie danych. Działa to tylko wtedy, gdy dane są wystarczająco wyczerpujące, aby odzwierciedlić wszystkie związki przyczynowo-skutkowe. Dlatego uważamy, że SSN prawdopodobnie będą działać tam, gdzie istnieje stosunkowo wysoki poziom jednorodności danych szkoleniowych. W przypadku przetwarzania języka naturalnego brakującym elementem metod głębokiego uczenia się opartych na statystykach obliczeniowych jest brak wiedzy kontekstowej. Naszym zdaniem obecne architektury głębokiego uczenia oparte na statystykach obliczeniowych nie oddają w rzeczywistości sposobu, w jaki ludzki mózg zdobywa i wykorzystuje wiedzę. Mogą się wydawać, że robią to mechanicznie, ale są powierzchowne w swojej replikacji funkcji ludzkiego mózgu. Jak zauważa Marcus (2012), głębokie uczenie się dotychczasowych praktyk jest tylko częścią większego wyzwania związanego z budowaniem inteligentnych maszyn. W technikach takich brakuje sposobów reprezentowania związków przyczynowo-skutkowych, nie ma oczywistych sposobów przeprowadzania wnioskowania logicznego, a ponadto wciąż daleko im do zintegrowania wiedzy abstrakcyjnej, takiej jak to, czym są przedmioty, do czego służą i jak są zwykle używane. Watson IBM może wykorzystuje głębokie uczenie się jako jeden element zestawu technik, wszystkie te krytyki mają zastosowanie.
NAUKA MASZYNY Z JĘZYKIEM NATURALNYM
Uczenie maszynowe z tekstem w języku naturalnym obejmuje dwie klasy problemów - klasyfikację i interpretację tekstu. Większość dyskusji w literaturze na temat przetwarzania języka naturalnego dotyczy klasyfikacji tekstu. Istnieje niezależna praca związana z analizą sentymentów, która jest wąską wersją problemu interpretacyjnego. Omówiliśmy je wszystkie w tej sekcji. Wiele metod uczenia maszynowego omówiono w poprzedniej sekcji może być stosowany do klasyfikacji tekstu z wykorzystaniem języka naturalnego. Ponieważ jednak tekst różni się od liczb w reprezentacji, istnieją specjalne techniki reprezentowania tekstu w języku naturalnym w formie, którą te metody mogą wykorzystać do wygenerowania klasyfikatorów.
Reprezentacja "Bag-of-Words"
Reprezentacja "woreczka słów" tekstu w języku naturalnym jest najpopularniejszym sposobem redukcji tekstu do formy, z której mogą korzystać klasyfikatorzy statystyczni. W tej metodzie tekst zawierający zestaw znaków jest przekształcany w reprezentację odpowiednią dla algorytmu uczenia się i zadania klasyfikacji. Taka transformacja opiera się na dobrze znanym badaniu, z którego wynika, że pnie słów mogą być pseudonimicznym konstruktem reprezentacji. Słowo rdzeń wywodzi się z formy występowania słowa poprzez usunięcie informacji o wielkości liter i fleksji (Porter, 1980). Na przykład "obliczenia", "obliczenia" i "komputer" są odwzorowane na ten sam rdzeń "obliczenia" (Porter, 1980). Oczywiście ta metoda zakłada, że dokładna forma słowa jest mniej ważna w zadaniach klasyfikacyjnych. Przekształcenie redukuje tekst w wektor unikalnych słów wraz z częstotliwością ich występowania w tekście. Każde odrębne słowo, wi, jest postrzegane jako Termin [t], a termin częstotliwość jako tf. Częstotliwość terminów to inny sposób ważenia terminów, aby umożliwić odpowiednią klasyfikację dokumentu do klasy. Luhn (1957) wymyślił tę definicję ważenia terminów, opierając się na prostym założeniu, że waga terminu w dokumencie jest proporcjonalna do jego częstotliwości. Na przykład, aby znaleźć dokumenty, które można właściwie sklasyfikować w odpowiedzi na zapytanie "o sztucznej inteligencji", nie wystarczy po prostu znaleźć dokumenty zawierające trzy słowa: "o", "sztuczny" i "inteligencja". Nadal otrzymamy wiele nieistotnych dokumentów. Aby dodatkowo filtrować wyniki, Luhn zaproponował, abyśmy policzyli liczbę wystąpień każdego terminu w każdym dokumencie i zsumowali je wszystkie; liczba wystąpień terminu w dokumencie nazywana jest jego częstotliwością. Aby zmierzyć prawdziwą informację, jaką zapewnia słowo, i zminimalizować wpływ typowych słów, takich jak "o" lub "o", które nie zawierają żadnych konkretnych informacji i, stosowany jest odwrotny współczynnik częstotliwości dokumentów, który zmniejsza wagę takich powszechnie używanych słów. Jones (1972) zdefiniował odwrotny współczynnik częstotliwości dokumentów jako funkcję odwrotną do liczby dokumentów, w których występuje słowo. Inną powszechną techniką zmniejszania wymiarów wektorów słów jest usuwanie takich słów jak "to", "to", "i", "lub" i tak dalej. Są to tak zwane słowa "stop". Każde słowo wi odpowiada wektorowi o wartości tf (wi, d), który odpowiada liczbie wystąpień słowa wi w dokumencie d jako jego wartości. Odwrotną częstotliwość dokumentów dla terminu, t, w korpusie dokumentów D podano przez
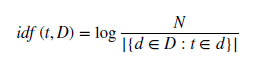
gdzie N jest całkowitą liczbą dokumentów. Odwrotna częstotliwość dokumentów dla terminu, t, jest miarą ilości informacji dostarczanych przez to słowo. Idf zmniejsza wpływ terminu, który występuje bardzo często i zwiększa wagę terminu, który występuje rzadko. Odwrotna częstotliwość słowa jest niska, jeśli występuje w wielu dokumentach, a najwyższa, jeśli słowo występuje tylko w jednym dokumencie. Rozważmy dokument zawierający 1000 słów, w którym słowo "inteligencja" pojawia się 50 razy, a korpus 1 miliona dokumentów ze słowem "inteligencja" pojawia się w 100 dokumentach.
tf ("inteligencja") = 50?1000 = 0,05
idf ("inteligencja") = log (1 000 000 ? 100) = 4
tf - idf = 0,05 × 4 = 0,20
Podjęto wiele prób eksploracji bardziej wyrafinowanych technik przedstawiania tekstu - w oparciu o statystyki słów wyższego rzędu, NLP, "jądra strunowe", klastry słów oraz wykresy słów, ale najbardziej popularna była stosunkowo prosta "torba słów". Wiele obliczeniowych metod statystycznych opisanych w poprzedniej sekcji może generować klasyfikatory na podstawie reprezentacji BOW. W rzeczywistości wszystkie polegają na BOW.
Analiza sentymentów
Analiza sentymentu języka naturalnego, zwana także eksploracją opinii, jest popularnym i rosnącym obszarem zainteresowań. Analiza sentymentów polega na określeniu "tego, co myślą inni" lub "jaką opinię wyraziła dana osoba". Analiza sentymentów polega na określeniu ogólnego sentymentu wyrażonego w dokumencie dotyczącym przedmiotu lub tematu i / lub opinii przypisanej konkretnemu interesariuszowi wyrażonemu w dokumencie, zazwyczaj w formie cytatu od tego interesariusza. Zasadniczo wymaga to identyfikacji obszaru dokumentu, w którym istnieje tekst ewaluacyjny, przypisania tego tekstu do przedmiotu lub tematu lub interesariusza oraz interpretacji sentymentu w tym tekście ewaluacyjnym. Ten rodzaj analizy został zastosowany do recenzji filmów, recenzji i opinii o produktach, blogów opiniotwórczych, recenzji książek, polityki i tak dalej. W niektórych przypadkach dokument źródłowy znacznie ułatwia zadanie identyfikacji, takie jak recenzje książek na Amazon. Wiemy, że są to recenzje książek i nie musimy tego określać na podstawie tekstu. Tekst swobodny stanowi jednak znacznie więcej wyzwań. Wykrywanie sentymentu w dokumencie obejmuje następujące aspekty: Po pierwsze, musimy ustalić, czy dokument zawiera sentyment. Po drugie, zakładając, że mamy opiniotwórczy dokument lub tekst, musimy określić polaryzację sentymentu - gdzie sentyment leży na kontinuum między sentymentem pozytywnym a negatywnym. Po trzecie, dokument może zawierać sentyment na wiele tematów i musimy odpowiednio przypisać sentyment jego tematowi. Po czwarte, dokument może zawierać sentyment wyrażony przez wielu interesariuszy lub zawierać sentyment autora na ten temat oraz dodatkowe cytaty odzwierciedlające sentyment innych interesariuszy. Wreszcie, sentyment może zależeć od wiedzy lub opinii spoza dokumentu. Większość metod analizy sentymentów opiera się na częstotliwości terminów (worek słów) lub pewnej ich zmienności, takich jak obecność terminów , pozycja terminu w jednostce tekstowej , części mowy i właściwości syntaktyczne . Hatzivassiloglou i McKeown próbowali grupować przymiotniki w dwie grupy, tak aby maksymalne ograniczenia były spełnione w oparciu o hipotezę dotyczącą rozdzielania przymiotników. Wiebe przeanalizował przymiotniki pod kątem gradacji i polaryzacji. Czynniki statystyczne są używane do przewidywania stopniowalności przymiotników. Kim i Hovy polegali na WordNet do generowania list słów o pozytywnej i negatywnej orientacji na podstawie list nasion. Takie metody mają słabość koherencji, ponieważ synonimy wykorzystujące Wordnet nie uwzględniają stopnia podobieństwa między synonimicznymi słowami i wieloma zmysłami. Godbole i in. zaproponował alternatywną metodę poprawy spójności zestawu synonimów w takim odkryciu. Pang i Lee zilustrowali użycie minimalnych cięć na wykresach do identyfikacji subiektywnych części rozpiętość tekstu w celu kategoryzacji ogólnego sentymentu zawartego w tekście. W centrum uwagi większości systemów analizy sentymentów - w tym analizy aspektowej - jest bardzo ograniczający, przy ogólnym założeniu, że nie jest dostępna wcześniejsza wiedza na temat podsumowywanej domeny. Ponadto żadna z tych metod nie interpretuje znaczenia tekstu w sposób odpowiedni dla kontekstu. Na przykład ten sam dyskurs może mieć odmienne zdanie na temat dwóch różnych odbiorców. Problem analizy sentymentów postrzegamy jako podzbiór problemu interpretacji tekstu. Bardziej holistyczna definicja problemu polega na tym, jak rozumieć znaczenie tekstu tak, jak robią to ludzie, bez względu na to, czy chodzi o analizę sentymentu lub opinii, czy też zrozumienie wpływu faktów i opinii w dokumencie na określony temat. Metody i aplikacje analizy sentymentów są ściśle skoncentrowane na jednym aspekcie zrozumienia. Metody te, koncentrując się tylko na sentymentach w analizowanym dokumencie, znajdują tylko lokalne (nieoptymalne) rozwiązania. Nie są w stanie znaleźć światowych sentymentów uwzględniających wcześniejszą wiedzę i opinie poza dokumentem. Aby maszyny analizowały tekst w języku naturalnym, musimy osadzić w nim głębokie zrozumienie języka naturalnego i wszystkich jego aspektów. Nie tylko muszą być w stanie przetwarzać tekst składniowo, ale także muszą być w stanie przetwarzać go semantycznie, tak jak my ludzie. Większość internetowych procesów przetwarzania tekstu, w tym wyszukiwarek, oraz innych aplikacji do pobierania, agregowania i przetwarzania, opiera się przede wszystkim na algorytmach stosujących właściwości składniowe tekstu w języku naturalnym. Algorytmy te są bardzo wydajne i dobre w dzieleniu tekstu, sprawdzaniu pisowni, analizowaniu tekstów, śledzeniu występowania słów i sekwencji słów, znajdowaniu określonych słów kluczowych i innych prostych zadań. Opierają się głównie na współwystępowaniu słów lub n-gramach lub ich odmianach. Algorytmy te są bardzo słabe pod względem zrozumienia znaczenia tekstu. W rzeczywistości ich możliwości są poważnie ograniczone pod tym względem. My, ludzie, przetwarzamy tekst nie tylko na podstawie słowa pisanego. Kiedy przetwarzamy tekst, nasz mózg aktywuje wiele informacji, które nie zostały zapisane. Wiele obszarów naszego mózgu jest aktywowanych, gdy czytamy tekst pisany. Bez wysiłku przypominamy sobie nasze rozumienie tego słowa dokładnie w kontekście, w którym jest ono używane, gdziekolwiek się da. W procesie zrozumienia mózg rozwiązuje wszelkie dwuznaczności związane z używaniem różnych słów, wszelkie wcześniejsze doświadczenia, które mogliśmy mieć z tym słowem, oraz koncepcje, które wywołuje w naszym mózgu. Rozumiemy sentencję pisarza, odnosząc się do twoich doznań zmysłowych i mapowania słów do nich.
Pozyskiwanie wiedzy i reprezentacja
Kluczowym aspektem przetwarzania języka naturalnego jest "wiedza". Każdy z nas stale gromadzi wiedzę. Aby maszyny mogły podchodzić do ludzkiej inteligencji w przetwarzaniu języka naturalnego, musi istnieć skuteczny sposób pozyskiwania, reprezentowania, przechowywania i dodawania wiedzy do maszyny. Zdobywanie wiedzy może być wspomagane, częściowo wspomagane lub w całości zapewniane przez ekspertów. Zostało to omówione wcześniej w tym rozdziale. Zdobyta wiedza musi być przechowywana i reprezentowana wewnątrz maszyny, aby była łatwo dostępna. Z czasem zaproponowano kilka schematów reprezentacji wiedzy. Jednym z popularnych schematów reprezentacji jest logika pierwszego rzędu (FOL) . FOL jest systemem dedukcyjnym składającym się z aksjomatów i reguł wnioskowania, które mogą obejmować wyrażenia składniowe, semantyczne, a nawet pragmatyczne. Składnia odnosi się do sposobu ułożenia grup symboli, aby można je było uznać za "dobrze uformowane", na przykład w poprawnie skonstruowanym zdaniu w języku angielskim. Semantyka odnosi się do znaczenia takich dobrze sformułowanych wyrażeń. Pragmatics określa, w jaki sposób można wykorzystać idiomatyczne i praktyczne użycie w celu poprawy semantyki, takie jak użycie "kserokopii" w znaczeniu "kopiowania". Jednak wiadomo, że FOL cierpi z powodu poziomu sztywności w reprezentacji wiedzy. FOL można uzupełnić o logikę wyższego rzędu, ale reprezentacja staje się dość złożona matematycznie. Reprezentacja wiedzy musi być elastyczna i dopuszczać wiele wyjątków. Wiedza musi ewoluować w miarę gromadzenia, a schemat reprezentacji musi umożliwiać łatwą modyfikację. Internetowy język ontologii (OWL) to kolejny schemat reprezentacji wiedzy. Podstawową strukturą leżącą u podstaw OWL jest model podmiot-predykat-obiekt, który czyni twierdzenia o zasobie. Rozszerza strukturę opisu zasobów (RDF), aby umożliwić kompleksową reprezentację ontologii, taką jak definicja i właściwości pojęć, relacje między pojęciami i ograniczenia dotyczące relacji między pojęciami i ich właściwościami. OWL najlepiej jednak nadaje się do wiedzy deklaratywnej. Nie pozwala na rozmytą wiedzę i zależności czasowe w wiedzy. Sieci to kolejna alternatywa reprezentacji wiedzy. Wszystkie zmienne razem są reprezentowane jako ukierunkowany wykres acykliczny, w którym łuki są przyczynowymi połączeniami między dwiema zmiennymi, a prawda pierwszej z nich bezpośrednio wpływa na prawdę drugiej. Na przykład sieci bayesowskie (znane również jako sieci przekonań) zapewniają sposób wyrażania łącznych rozkładów prawdopodobieństwa w wielu powiązanych ze sobą hipotezach. Innym rodzajem reprezentacji sieci jest sieć semantyczna (Sowa, 1987). Takie sieci reprezentują wiedzę w postaci połączonych ze sobą węzłów i łuków. Sieci semantyczne mogą być definicyjne i asertywne. Sieci definicji koncentrują się na relacjach IsATypeOf między koncepcją a nowo zdefiniowanym podtypem. Podtypy dziedziczą właściwości nadtypu. Sieć asercyjna zapewnia twierdzenia, które są warunkowo prawdziwe. Są one ogólnie oceniane w oparciu o zdrowy rozsądek. Rodzaj przyjętego schematu reprezentacji wiedzy jest funkcją rodzaju wiedzy, która ma być reprezentowana. Uważamy, że rozszerzona forma sieci semantycznych wykorzystująca więcej niż relacje definicyjne i asertywne oferuje najbardziej elastyczny i skuteczny schemat. Wyjaśnimy taki schemat w następnym Sekcja. Aby przyspieszyć odkrywanie wiedzy, stworzono kilka ogólnych baz wiedzy dla powszechnie rozumianej wiedzy. Wśród powszechnie używanych baz wiedzy są (1) Cyc, logiczne repozytorium zdrowej rozsądku; (2) WordNet , powszechnie stosowana uniwersalna baza danych zmysłów słów; oraz (3) projekt Open Mind Common Sense, baza danych commonsense drugiej generacji. Tłum projektu Common Sense czerpie swoją wiedzę za pośrednictwem wolontariuszy. Takie magazyny wiedzy były już niezwykle pomocne w wielu wysiłkach związanych z rozwojem aplikacji semantycznych.
GŁĘBOKIE RAMY NAUCZANIA DLA NAUKI I INFERENCJI
Podczas gdy badania NLP poczyniły ogromne postępy w wytwarzaniu sztucznie inteligentnych zachowań, żadna z platform (np. Google, Watson IBM i Siri Apple) nie rozumie, co robią - nie różni się niczym od papugi, która uczy się powtarzać słowa bez wyraźnego wyjaśnienia zrozumienie tego, co mówi. Obecnie nawet najpopularniejsze technologie NLP traktują analizę tekstu jako zadanie dopasowania słowa lub wzorca. Uważamy, że obecne podejścia do głębokiego uczenia się, z których niektóre zostały przeanalizowane w poprzedniej części, są w dużej mierze objawowe i nie odzwierciedlają rzeczywistego funkcjonowania ludzkiego mózgu ani logicznego wnioskowania. Dwie największe luki to brak wiedzy kontekstowej i bardziej realistyczna funkcjonalność architektury. Ramy, które proponujemy, mają swoje korzenie w obszernej literaturze na temat architektur poznawczych przyjrzyjmy się procesowi rozwoju ludzkiego mózgu. Z czasem zdobywamy wiedzę poprzez nasze doświadczenia, od otaczających nas ludzi i od ustrukturyzowanej edukacji, przez którą możemy przechodzić. Uczymy się, co jest dobre, a co złe, i wszystkie odcienie szarości dla wszystkich konteksty, których się uczymy. I jak popularne powiedzenie brzmi: "nauka nigdy się nie kończy". W badaniach neuronauki jest dobrze ustalone, że mózg integruje wiele źródeł informacji podczas uczenia się za pomocą wielu modalności. Wydaje się, że multisensoryczne przetwarzanie informacji jest nieodłączną częścią percepcji i rozpoznawania obiektów w życiu codziennym, dzięki czemu mózg integruje informacje z różnych modalności w spójny sposób . Ludzki mózg ewoluował, aby rozwijać się, uczyć i działać optymalnie w środowiskach multisensorycznych. W związku z przetwarzaniem języka naturalnego musimy uznać, że język jest stosunkowo nowym zjawiskiem kulturowym i ewolucyjne mechanizmy mózgowe przetwarzania skryptów pisanych nie istnieją. Ludzki mózg musiał się przystosować, aby rozwinąć zdolność rozpoznawania skojarzeń literowo-głosowych. W rzeczywistości Blomert i Froyen zwracają uwagę, że w ostatnim dziesięcioleciu badania neuroobrazowania zidentyfikowały obszar mózgu, który wykazuje specjalizację w zakresie szybkiego rozpoznawania słów, to znaczy domniemany obszar wizualnej formy słów w mózgu. Ponieważ płynność i automatyzacja są najbardziej znaczącymi cechami doświadczonego czytania (i z naszej perspektywy interpretacja), jest rzeczywiście prawdopodobne, że sieć neuronowa zaangażowana w rozpoznawanie obiektów wizualnych specjalizuje się w rozpoznawaniu liter wizualnych i form słów w ludzkim mózgu. Wiele lat po tym, jak dzieci po raz pierwszy uczą się dekodować słowa na litery, pojawia się forma percepcyjnej ekspertyzy, w której grupy liter szybko i bez wysiłku łączą się w zintegrowane postrzeganie wizualne, co jest procesem niezbędnym do płynnej czytania. Potrzebujemy lat wyraźnych instrukcji i praktyki, zanim zaczniemy wykazywać się biegłą znajomością wizualnego rozpoznawania słów. Kontrastuje to ostro ze sposobem, w jaki uczymy się języka mówionego. Niemowlęta i małe dzieci zaczynają wychwytywać i rozwijać wiele zawiłości języka mówionego bez wyraźnych instrukcji w czasach, gdy nauka czytania i pisania jest jeszcze daleko w przyszłości. Ostatnie dowody elektrofizjologiczne wykazały, że potrzeba kilku lat nauki czytania i praktyki, zanim pojawią się pierwsze oznaki automatycznej integracji liter i dźwięków mowy u normalnie rozwijających się dzieci. Powiązania dźwiękowe z literą i mową są interwencjami kulturowymi, a zatem z natury biologicznie arbitralnymi. Istnieje kilka kluczowych implikacji. Po pierwsze, przez lata nauki nauczyliśmy się wielu pojęć, przedmiotów i ich atrybutów w różnych kontekstach. Nauczyliśmy się rozpoznawać, że ten sam atrybut przypisany do tego samego obiektu może wywoływać w nas odmienne postrzeganie lub rozpoznawanie. Po drugie, kluczową implikacją jest to, że nasza wiedza jest dla nas widoczna. Chociaż nie wiemy wielu rzeczy, to, co wiemy, jest nam bardzo deterministycznie znane. Wiemy również z neuronauki, że wiedza jest zorganizowana w sposób hierarchiczny. Możemy rozumieć te abstrakcyjne, ale nie bardzo szczegółową wiedzę w wielu sytuacjach. Możemy znać wiele pojęć i tematów, ale w bardzo płytkim sensie. Bardzo głęboko znamy kilka pojęć i tematów. W obszarach, w których zdobyliśmy rozległą wiedzę, będziemy dobrze rozumieć wszystkie szczegółowe obiekty, pojęcia i atrybuty. Aby modelować to zachowanie poznawcze, musimy wyraźnie pozwolić na szeroką akwizycję wiedzy i reprezentację w architekturze, tak jak robi to mózg. Mózg ma do czynienia z wieloma rozmytymi sytuacjami, w których brakuje mu precyzyjnej wiedzy, aby zrozumieć informacje bez dwuznaczności. W takich sytuacjach mózg ucieka się do następnego wyższego poziomu struktury pod względem obiektu i próbuje na tej podstawie podjąć decyzję. Kiedy nie ma żadnych informacji, otrzymujemy "Nie wiem". Nasza przechowywana wiedza jest stale dostosowywana, gdy widzimy wyniki naszych wyborów i działań. Kiedy ustanawiam agresywny harmonogram działań i tak się nie dzieje, a dzieje się to kilka razy, dostosowuję swoją zgromadzoną wiedzę na podstawie tego doświadczenia. W pewnym momencie w przypadku podobnych projektów moja zgromadzona wiedza zaczyna zmieniać moją reakcję w zakresie ustawiania agresywnych terminów. Od tego momentu zaczynam ustalać konserwatywne terminy. Jeśli wiedza jest jasna i nie ma dwuznaczności, nasza decyzja jest bardzo szybka. Jeśli tak nie jest, robimy wszystko, co w naszej mocy. Zawsze jednak staramy się zdobywać bardziej szczegółową i szczegółową wiedzę w obszarach, które są nam potrzebne, aby nasza wiedza była bardziej kompletna, a decyzje mniej niejasne. Jeśli decyzja dotyczy przyszłości, staramy się ustalić nasze obecne poglądy na temat czynników przyczynowych w naszej przechowywanej wiedzy i prognozować przyszłość. RAGE AITM wdraża udoskonalony schemat reprezentacji wiedzy oparty na sieci semantycznej wynikający z teorii struktury retorycznej. RAGE AI agreguje, wyodrębnia, klasyfikuje i interpretuje tekst w odniesieniu do danego kontekstu w trybie nadzorowanym lub nienadzorowanym. Może być skutecznie wdrożony w każdym problemie, który wymaga wyszukiwania, klasyfikacji lub interpretacji. W szczególności moduły wysokiego poziomu w RAGE AITM obejmują:
• Odkrywca wiedzy (KD), który automatycznie wyszukuje wiedzę związaną z tematem lub podmiotem zainteresowania. Taka wiedza będzie odnosić się do wszystkich rodzajów wiedzy dotyczących tematu. KD można zastosować do dowolnego rodzaju treści publicznych lub prywatnych.
• KnowledgeNet (KN), który przechowuje wiedzę specyficzną dla domeny. Wiedza może być automatycznie odkryta przez KD i / lub dostarczona przez ekspertów. W razie potrzeby eksperci mogą również edytować automatycznie odkrytą wiedzę. KN przechowuje wiedzę, korzystając z rozszerzonej sieci semantycznej, o której mowa wcześniej.
• Categorizer, aby sklasyfikować dokument na jeden lub więcej tematów. Kategoryzator naturalnie grupuje dokument w podstawowe tematy, badając dokument i jego strukturę dyskursu. Nakłada także zewnętrzną sieć semantyczną specyficzną dla tematu na potrzeby klasyfikacji.
• Analizator wpływu, który ocenia sentyment / potencjalny wpływ dokumentu na interesujący go temat, w tym analizę nastrojów konkretnych interesariuszy, które mogą być wyrażone w dokumencie.
Interpretacje dokumentów mogą się różnić w zależności od kontekstu. Naszym celem jest zautomatyzowanie interpretacji znaczenia dokumentów w odniesieniu do kontekstu, przy wykorzystaniu zarówno wspomaganego, jak i samodzielnego odkrywania wiedzy. Takie podejście, które nazywamy "analizą wpływu", pozwala nam tworzyć aplikacje, które można wykorzystać do podejmowania decyzji. Zapewniamy ogólny przegląd architektury RAGE AITM. Ramy składają się z kroków, poprzez które osiąga się głęboką naukę i zrozumienie tekstu w języku naturalnym. Analizowana treść może być agregowana z różnych źródeł, w tym z internetowych adresów URL; źródła mikroblogowania, takie jak Facebook, Twitter i Tumblr; dokumenty wewnętrzne; oraz treści ze źródeł premium. Struktura zapewnia elastyczność dodawania nowych źródeł (adresy URL, użytkownicy Twittera, dokumenty wewnętrzne itp.) W locie. Mechanizm wydobywania informacji semantycznych ułatwia wydobywanie określonych rodzajów treści z dokumentu, takich jak dane finansowe ze sprawozdania finansowego, tabele z raportu z badań oraz warunki z umowy prawnej. RAGE AITM zawiera model dyskursu domenowego, który umożliwia tworzenie i przechowywanie właściwości strukturalnych specyficznych dla domeny. Na przykład historia wiadomości ma zazwyczaj tytuł i treść; raport z badań może mieć tytuł, podzielony na sekcje, zawierać odniesienia i załączniki; umowa prawna może mieć hierarchiczną strukturę części, dodatków i eksponatów; a artykuł akademicki zazwyczaj ma streszczenie, treść i odniesienia. Dodatkowe właściwości strukturalne mogą obejmować dowolne inne właściwości strukturalne, które mogą pomóc maszynie w ulepszeniu przetwarzania tekstu; na przykład artykuły informacyjne zwykle zawierają główną ideę artykułu w górnej części artykułu, a reszta jest w dużej mierze opracowana. Silniki przetwarzania tekstu i przetwarzania w języku naturalnym wykonują składniowe i płytkie parsowanie tekstu. Kroki te oczyszczają tekst, tokenizują, identyfikują role mowy w różnych słowach i identyfikują nazwane byty. Silnik semantyki obliczeniowej rozpoczyna proces głębokiego uczenia się. Stara się znormalizować pojęcia, ujednoznacznić zmysły słów, ponownie skalibrować role części mowy, ujednoznacznić pojęcia w oparciu o KnowledgeNet (KN) i wygenerować drzewa zależności. Ujednoznacznienie zmysłów i pojęć słownych jest funkcją przechowywanej wiedzy i chociaż silnik ten może nie być w 100% dokładny we wszystkich przypadkach, z czasem zbliży się do 100%. Silnik lingwistyki obliczeniowej (CLE) wykrywa klauzule i granice klauzul, semantyczne role różnych słów / fragmentów tekstu i korelacje w całym tekście; następnie grupuje dokument i tworzy mapę dokumentu (lub wykres). Wynik na tym etapie ma głęboką lingwistyczną reprezentację dokumentu tekstowego. Na koniec silnik zrozumienia poznawczego (CUE) próbuje naśladować ludzkie rozumienie dokumentu na podstawie danych wyjściowych z poprzednich kroków i, co najważniejsze, wyników CLE. CUE może sklasyfikować dokument, jeśli jest to pożądany wynik i / lub zinterpretować dokument w odniesieniu do określonego tematu, integrując KnowledgeNet, jeśli to konieczne. Wiedza eksperta, jeśli taka istnieje, może być również przechowywana w KnowledgeNet. Interpretacja może być czysto lokalny lub globalny z integracją KnowledgeNet i potencjalnie ekspertem, jeśli ekspert dostarczył swoją wiedzę do KnowledgeNet.
Konceptualna sieć semantyczna
Kluczowym centralnym aspektem RAGE AI jest konceptualna sieć semantyczna (CSE). CSE opiera się na wszystkich innych etapach głębokiej analizy i jest jednym z wyników silnika zrozumienia poznawczego. CSE jest wyczerpującym wyliczeniem relacji między dowolnymi dwoma tematami. Wymienia wszystkie możliwe relacje między dwoma pojęciami oprócz typowych relacji "definicyjnych" (synonim, hypernym, meronym) charakterystycznych dla typowej ontologii. Ma swoje korzenie w retorycznej teorii struktury, która jest szeroko akceptowanym ramem analizy dyskursu. Wcześniejsze prace nad automatyczną ekstrakcją relacji ograniczały się do relacji lokalnych, takich jak hipernyja i meronimia. Znacząco rozszerzamy taką pracę, wyodrębniając globalny zestaw relacji i łącząc ekstrakcję takich relacji z algorytmem bayesowskim w celu obliczenia i uszeregowania względnych sił takich relacji. Aby odkryć relacje i pokrewne pojęcia, poszerzamy ideę, że spójny tekst w dyskursie implikuje zestaw strukturalnych relacji między pokrewnymi pojęciami i ugruntowanymi w języku. Relacje są identyfikowane między dwoma pojęciami lub dwoma zdarzeniami lub pojęciem i zdarzeniem i viceversa. RAGE AI implementuje również złożony identyfikator pojęcia i normalizator pojęcia, który inteligentnie redukuje złożone wyrażenia rzeczownikowe do konkretnych znormalizowanych pojęć, dzięki czemu można zidentyfikować lub wywnioskować różne relacje dotyczące tego samego zdarzenia lub pojęcia. Silnik wnioskowania w ChZT może następnie wykonać kilka wnioskowania kontekstowego, aby stworzyć wielopoziomową, hierarchiczną, konceptualną sieć semantyczną. Niektóre relacje, które CSE próbuje znaleźć, są następujące:
1. Uznanie Podmiot nazwany A wyraża coś na temat pojęcia B (np. Francja powiedziała, że poprze Palestynę na status podmiotu obserwatora niebędącego członkiem).
2. Przyczynowy Zdarzenie_A powoduje zdarzenie_B (np. Zastój w branży mieszkaniowej w zeszłym miesiącu uzyskała rzadką poprawę, ponieważ więcej osób kupowało nowe domy po najgorszej zimie od prawie 50 lat).
3. Porównanie Event_A porównuje się do event_B (np. Sektor mieszkaniowy nadal pozostaje w tyle, podczas gdy inne sektory poważnie rozpoczęły odbicie).
4. Wniosek Event_A to wniosek event_B (np. Inflacja_stopa procentowa w dłuższym okresie określiła przede wszystkim politykę pieniężną a zatem komitet ma możliwość określenia długoterminowego celu inflacyjnego).
5. Warunkowe Jeśli Event_A, to event_B (np. Jeśli ceny domów ponownie spadną, wtedy konsumenci mogą ograniczyć wydatki).
6. Kontrast Event_A i event_B mają różne zachowania.
7. Przeciwwskazanie Zdarzenie_A występuje nawet wtedy, gdy wystąpiło zdarzenie_B, co było sprzeczne z oczekiwaniami (np. rynek mieszkaniowy nadal pozostaje niski, choć w marcu znacznie się poprawił).
8. Opracowanie Event_A jest opracowaniem event_B (np. Ekonomistów prognozy, że dochody również mogą wzrosnąć).
9. Hypernym Event_A jest hipernymem zdarzenia B (np. Detaliści tacy jak Home Depot Inc.).
10. Uzasadnienie Pojęcie_B służy do uzasadnienia zdarzenia dotyczącego pojęcia A.
11. Powód Zdarzenie_A spowodowało wystąpienie zdarzenia_B (np. Wyprzedaże_domowe_ oczekujące są uważane za wiodący_ wskaźnik, ponieważ śledzą podpisywanie umów).
12. Wynik Event_A jest wynikiem event_B (np. Rosnące dochody w poszczególnych krajach sprzyjają zwiększonej sprzedaży).
13. Temporal_Simultaneous Event_A wystąpił jednocześnie z event_B (np. W Bristolu sprzedaż spadła o 43,8% w kwietniu w porównaniu z analogicznym miesiącem ubiegłego roku, podczas gdy mediana ceny sprzedaży spadła o 3% do 225 000 $).
14. Temporal_Succession Event_A zastępuje event_B (np. Wiele rynków zaczęło spadać, gdy ulgi podatkowe wygasły w kwietniu).
Przykłady
"Zaufanie konsumentów w Stanach Zjednoczonych spadło w ubiegłym tygodniu do najniższego poziomu od sierpnia, ponieważ rosnące ceny ograniczają budżety domowe".
Klauzula 1: Zaufanie konsumentów w Stanach Zjednoczonych spadło w ubiegłym tygodniu do najniższego poziomu od sierpnia
Klauzula 2: gdy rosnące ceny ograniczają budżety domowe
Relacja 1: [wzrost cen] PRZYCZYNA [budżety gospodarstwa domowego]
Relacja 2: [wzrost cen] PRZYCZYNA wpływ na [budżety gospodarstwa domowego]
Relacja 3: (Pochodne) [budżety domowe] PRZYCZYNA wpływ na [zaufanie konsumentów]
Opcjonalnie uzyskujemy wynik ufności dla każdej relacji. Wynik ufności jest wprost proporcjonalny do dowodów konkretnego związku w naszym ciele. Z każdą nową relacją, która jest zidentyfikowana na podstawie tekstu, punktacja adaptacyjna jest przyznawana dla nowej relacji i wszystkich dowodów tej relacji w naszej bazie danych. Nasze podejście do stwierdzenia istnienia relacji korzysta z naszej zdolności do tworzenia znormalizowanych pojęć, które uniezależniają ją od części mowy.
Odkrywca wiedzy
Jak wspomniano wcześniej, uważamy, że "wiedza w dziedzinie" i zdobywanie wiedzy jest kluczowym brakującym ogniwem w większości obecnych metod i aplikacji do uczenia maszynowego. Jednocześnie zdobywanie wiedzy może być czasochłonnym zadaniem i dlatego zniechęca wielu do podjęcia próby. W kontekście języka naturalnego RAGE AITM radykalnie przyspiesza zdobywanie wiedzy dzięki swojemu odkrywcy wiedzy (KD). Biorąc pod uwagę interesujący temat, KD automatycznie odkrywa powiązane pojęcia i ich związki z interesującym tematem w docelowym korpusie. Korpus docelowy może być treścią publiczną i / lub prywatną. W razie potrzeby eksperci mogą również przekazywać wiedzę lub edytować zdobytą wiedzę. Ta interakcja może być iteracyjna. W ten sposób KD może działać w trybie całkowicie nienadzorowanym, częściowo nadzorowanym lub w pełni nadzorowanym. KD działa w połączeniu z KnowledgeNet. KD najpierw szuka w KnowledgeNet, aby odzyskać wszelką przechowywaną wiedzę na temat interesującej koncepcji. Wyniki są następnie opcjonalnie agregowane ze świeżym zapytaniem o treść publiczną i / lub prywatną, aby stworzyć najbardziej aktualną bazę wiedzy na temat tego pojęcia. Tak zaktualizowana wiedza jest następnie dostępna dla reszty środowiska RAGE AITM jak klasyfikator i analizator wpływu.
Silnik lingwistyki obliczeniowej
Silnik lingwistyki obliczeniowej (CLE) wykorzystuje dane wyjściowe wszystkich komponentów, które go poprzedzają, jak pokazano na rysunku 3.21. CLE analizuje wyniki poprzednich kroków i tekst, używając pojęć i reguł językowych, aby stworzyć głęboko przeanalizowaną interpretowalną wersję tekstu. Obejmuje to wykrywanie klauzul i granic klauzul, ról semantycznych, rozwiązywanie odniesień i grupowanie tekstu albo według jego organizacji lokalnej (bez nadzoru), albo zgodnie z przechowywaną wiedzą lub zapytaniem (częściowo nadzorowane). CLE realizuje zarówno relacje anaforyczne, jak i kataforyczne. Podczas gdy większość modeli rozdzielczości z odniesieniami używa jednej funkcji w wielu wzmiankach w kontekście lokalnym, dobrze wiadomo, że taka lokalna rozdzielczość przyniesie słabą wydajność (Bengston i Roth, 2008; Finkel i Manning, 2008; Stoyanov, 2010). Raghunathan i in. (2010) zaproponowali sito wieloprzebiegowe, które stosuje poziomy deterministycznych modeli współzależnych pojedynczo od najwyższej do najniższej precyzji. Metoda rozstrzygania odniesienia CLE jest elastycznym, wieloprzebiegowym algorytmem. Oprócz deterministycznych reguł rozwiązywania problemów z odniesieniami nasze podejście pozwala na wdrożenie wielu ograniczeń kontekstowych i deklaratywnych pragmatycznych relacji istotnych dla kontekstu. Nasze podejście do identyfikacji "tematów" związanych z dokumentem polega na znalezieniu naturalnych klastrów pojęciowych w dokumencie. Takie klastry można znaleźć, identyfikując podobieństwa semantyczne między wszystkimi zdaniami i akapitami w dokumencie. Takie podobieństwo semantyczne obejmuje relacje wzajemnie referencyjne, relacje pojęciowe i odpowiednie relacje w KnowledgeNet.
Rysunek poniższy pokazuje dokument podzielony na klaster 1 i klaster 2 na podstawie relacji językowych między zdaniami w dokumencie. Klaster 1 został znaleziony jako klaster zdań S1, S2, S3 i S10, przy czym grubość strzałek relacji pokazuje siłę ich relacji językowych (lub podobieństwa semantyczne). Siła podobieństwa semantycznego między dwoma zdaniami, Sa(z M zwrotów rzeczownikowych), Sb (z N zwrotami rzeczownikowymi) w dokumencie jest reprezentowana przez S (a, b):
Stosuje się próg (T) oznaczający siłę podobieństwa semantycznego poinstruuj komputer, aby ignorował słabe dopasowania semantyczne. T można zdefiniować za pomocą nadzorowanego algorytmu lub po prostu za pomocą wartości uzyskanej empirycznie. Uzyskuje się zastosowanie progu dla S (a, b)
S (a, b) = S (a, b), jeśli S (a, b)> T
S (a, b) = 0, jeśli S (a, b)
Każdy klaster, C, jest powiązany z tematem podstawowym, T i tematami dodatkowymi (ST1… STn). Temat zdania głównego klastra jest wybrany jako główny temat klastra, C. CLE generuje mapę dokumentu jako acykliczny (jeśli nie rozważa katafory) wykres o następujących cechach:
1. Każdy węzeł to zdanie w dokumencie.
2. Każda krawędź reprezentuje siłę podobieństwa semantycznego między dwoma zdaniami. Krawędzie o zerowej wytrzymałości nie są uważane za krawędzie.
3. Wykres może składać się z kilku klików, w wyniku czego powstaje kilka podgrafów.
Biorąc pod uwagę węzeł główny w mapie dokumentu, jeśli podążymy za jedną krawędzią węzła głównego, podążalibyśmy za jednym z głównych tematów dokumentu. Każda klika w mapie dokumentu jest określana jako grupa zdań znaczących semantycznie. Gromada jest uważana za zestaw zdań należących do tej samej kliki. Siła klastra C ze zdaniami s0, s1,
, sL jest zdefiniowana przez
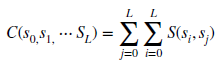
W przypadku nienadzorowanej kategoryzacji możemy łatwo zidentyfikować główny temat artykułu, identyfikując klaster o maksymalnej sile. W zależności od rodzaju dokumentu może istnieć jeden lub wiele klastrów (lub jednostek dyskursu). Poza nieodłącznymi cechami dokumentu opartymi na jego celu, wiele klastrów w dokumencie może wskazywać na użycie pragmatycznych pojęć, takich jak "kserokopia" dla "kopiowania". CLE jest w stanie zminimalizować takie nieznane pragmatyczne relacje na dwa sposoby. Po pierwsze, istnieje prawdopodobieństwo, że pragmatyczna relacja została już odkryta i zapisana w KnowledgeNet. CLE zajrzy do KnowledgeNet, aby sprawdzić, czy istnieją pragmatyczne relacje. Po drugie, KnowledgeNet zapewnia narzędzie do przechowywania znanych pragmatycznych relacji specyficznych dla domeny. W częściowo nadzorowanym trybie uczenia się sieci wiedzy przygotowane przez ekspertów można nakładać na klastry dokumentów. Zdanie, w którym znajduje się temat z sieci wiedzy dostarczonej przez eksperta, staje się zdaniem głównym i głównym tematem dla klastra. CLE pozwala na określenie właściwości dyskursu specyficznych dla domeny w określaniu siły powiązania dokumentu z tematem. Na przykład użytkownicy mogą przepisać różne wagi dla różnych części dokumentu w zależności od lokalizacji i / lub na podstawie semantycznej roli tematu w zdaniu (temat, obiekt itp.)
Analiza wpływu
Aby przeanalizować wpływ dokumentu na interesujący temat / podmiot, CUE ma rozbudowaną, elastyczną i potężną strukturę, która wyodrębnia frazy wpływające z dokumentów i interpretuje je w znormalizowany sposób w odniesieniu do interesującego tematu / podmiotu. Frazy wpływowe są znacznie bardziej rozbudowane w sensie "znaczeniowym" niż leksykony sentymentalne używane do analizy sentymentów. Wymagają pełnej analizy językowej dyskursu i identyfikacji struktury językowej. Na przykład platforma RAGE identyfikuje takie rzeczy, jak podmiot zdania, niezależnie od tego, czy jest to głos aktywny, czy pasywny, czy czasownik oznacza wpływ, czy czasownik jest czasownikiem przechodnim neutralnym dla uderzenia i tak dalej. Frazy wpływu to dowolny zestaw słów, które przekazują wpływ; mogą być czasownikami, rzeczownikami, przymiotnikami i przysłówkami. Zwroty określające wpływ są agregacją podstawowych słów wpływających i słów, które podkreślają wpływ; przymiotniki i przysłówki są zwykle używane do podkreślenia wpływu; nazywamy je "intensywnością uderzenia". Oprócz podstawowych zwrotów uderzeniowych system wyodrębnia atrybuty opisowe, takie jak czas, ilość i lokalizacja. Na przykład w "Rozpoczęciu budów znacznie wzrosło w styczniu o 3%", czasownik "róża" jest głównym słowem wpływającym, przysłówek "znacząco" opisuje intensywność, "3%" również odzwierciedla intensywność, a "styczeń" jest wskaźnikiem czasu. Takie wyrażenia mogą zawierać "negację", na przykład "Rozpoczęcie budowy mieszkań nie wzrosło w styczniu". Odwrócenie kierunkowe może czasem zachodzić w bardziej subtelny sposób; może to również przejawiać się przez użycie "anty" słów takich jak "antyimigracja" lub "bezrobocie". Aby osiągnąć spójność i porównanie między tematami, normalizujemy ocenę wpływu do dyskretnego zestawu wyników i powiązanych wyników; obecnie używamy pięciu dyskretnych kategorii: znacząco dodatnich, dodatnich, neutralnych, negatywnych i znacząco negatywnych. Ta sama fraza uderzeniowa może mieć całkowicie przeciwną interpretację dla dwóch tematów. Na przykład "wzrost cen ropy" będzie miał pozytywny wpływ na spółki naftowe i - na przedsiębiorstwa transportowe. Umożliwiamy konfigurację kierunku uderzenia na temat / znormalizowany poziom uderzenia.
Sformułowanie problemu analizy wpływu
Rozważmy dokument Dj oznaczony tematami T1, T2,…, TN. Dokument jest dalej podzielony na kilka poddokumentów (klauzule i zdania; decydowane dynamicznie), Dj1, Dj2,…, DjM. Każdy pod-dokument został przeanalizowany i przypisano wpływ Ij = Ij1, Ij2,…, IjM. Następnie wynik na poziomie dokumentu w odniesieniu do każdego tematu Tj jest zapisywany jako
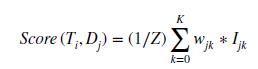
gdzie wjk jest masą uderzenia, jako funkcja dokumentu podrzędnego Djk, a Z jest współczynnikiem normalizacji. Ijk jest wykrywany przez analizator uderzeń pod względem językowym, przy użyciu wyrażeń uderzenia i wzmacniając je zgodnie z odpowiednimi wyrażeniami uderzenia i intensywności (w tym lokalizacjami, okresami i ilościami). Waga wpływu jest funkcją klastra dokumentu podrzędnego i informacji o położeniu. W najprostszej implementacji wjk ma wartość 1, gdy poddokument Djk należy do najsilniejszego klastra dla tego tematu, a 0 w przeciwnym razie. Nawet w klastrze, wjk może się różnić w zależności od pozycji dokumentu podrzędnego w najsilniejszym klastrze. Mamy kilka schematów punktacji, które pasują do różnych teorii analizy dyskursu. Ten rodzaj schematu oceniania przypisuje ocenę N-wymiarową (dla N tematów w systemie / ontologii) do dokumentu. To, postrzegane jako szereg czasowy, zapewnia ocenę tematu / zdarzenia lub bytu w funkcji czasu
PODSUMOWANIE
Istnieje duże zainteresowanie terminową analizą i interpretacją ogromnych ilości danych nieustrukturyzowanych i danych strukturalnych, które są tworzone w nowej erze cyfrowej. W tym rozdziale skoncentrowaliśmy się na wglądu i inteligencji. Omówiliśmy wydajność w rozdziale 2. Zaczęliśmy od przeglądu związku między informacją a podejmowaniem decyzji. Szczegółowo omówiliśmy motywację asymetrii informacji jako źródła wartości. Omówiliśmy organizację taksonomiczną oraz sztuczną inteligencję i uczenie maszynowe. Istnieje wiele zagadek związanych z uczeniem maszynowym. W szczególności różni ludzie bardzo różnie rozumieją, do czego zdolne jest uczenie maszynowe, a czego nie. Mamy nadzieję, że teraz czytelnik lepiej zrozumie, w jaki sposób metody i koncepcje uczenia maszynowego pasują do ogólnego schematu. Opisujemy również pokrótce najpopularniejsze metody uczenia maszynowego. Kończymy ten rozdział opisem RAGE AITM, który jest identyfikowalną strukturą głębokiej nauki inteligencji poznawczej. Twierdzimy, że niezależnie od tego, czy mamy do czynienia z danymi ustrukturyzowanymi lub nieustrukturyzowanymi, czy też z kombinacją obu tych elementów, pęd do tworzenia rozwiązań uczenia maszynowego koncentrował się dotychczas na statystykach obliczeniowych. Uczenie maszynowe oparte na statystykach obliczeniowych może być skuteczne w przypadku jednorodnych zestawów danych, ale nadal będzie wymagało znacznie dużego korpusu szkolenia. Jednak rozwiązania uczenia maszynowego, które są opracowywane przy użyciu podejść identyfikowalnych, takich jak RAGE AITM, prawdopodobnie będą bardziej zaufane i będą wymagały mniejszego korpusu do nauki. RAGE AITM został sprawdzony w wielu przedsiębiorstwach w różnych zestawach domen biznesowych:
• Ryzyko rentowności biznesowej Platforma służy do ciągłej oceny ryzyka biznesowego, podczas gdy inteligentna maszyna stale ocenia, czy rozwój sytuacji na całym świecie może potencjalnie wpłynąć na rentowność klienta, dostawcy lub partnera.
• Znalezienie alfa na rynkach finansowych Aplikacja oparta na RAGE AITM nieustannie ocenia wpływ wiadomości, opinii na blogach, badań i mediów społecznościowych na wewnętrzną wartość firmy. Sygnały te umożliwiają zarządzającym aktywami podejmowanie decyzji inwestycyjnych i wykorzystywanie nieefektywności rynku.
• Zadowolenie klienta Aby ocenić prawdziwy charakter skarg klientów oraz inteligentną, terminową i konsekwentną odpowiedź na klienta, RAGE AITM analizuje miliony skarg klientów wraz z powiązanymi interakcjami między przedstawicielami obsługi klienta a klientami w celu uzyskania ciągłego wglądu i inteligencji w podstawowa przyczyna problemów oraz jakość i dokładność odpowiedzi. Ogólnym celem jest skupienie się na prawdziwych problemach i utrzymanie zadowolenia klientów na najwyższym poziomie.
• Dział pomocy kognitywnej Podobnie jak aplikacja reklamacyjna klienta, inteligentna aplikacja, która rozumie żądania pomocy technicznej i reaguje inteligentnie i na czas. Maszyna jest przeszkolona w zakresie wszystkich dostępnych materiałów w systemach, zasadach i praktykach firmy.
• Informacje o klientach, rynku i konkurencji Aplikacja RAGE AITM stale analizuje i wyłania się z trendów we wszystkich sektorach biznesowych i branżach, aby zapewnić konsultantom i specjalistom ds. Marketingu wgląd w pojawiające się trendy, interesujące tematy i zachowania konkurencyjne. Użytkownicy mogą następnie zaprojektować odpowiednie odpowiedzi.
• Generowanie potencjalnych sprzedaży Aplikacja RAGE AITM interpretuje ogrom ilość ustrukturyzowanych i nieustrukturyzowanych treści w celu zidentyfikowania potencjalnych potencjalnych sprzedaży. Eksperci firmy mogą dostarczyć swoją wiedzę specjalistyczną do aplikacji RAGE AITM, aby dostosować je do własnych potrzeb. Firmy zazwyczaj ręcznie analizują wiadomości i inne informacje publiczne w celu zidentyfikowania potencjalnie wykwalifikowanych potencjalnych klientów. W jednej firmie stwierdziliśmy, że aplikacja wygenerowała o 200% trafniejszych potencjalnych klientów niż zespół ludzki i brakuje tylko 5-10%.
• Doradztwo w zakresie zarządzania majątkiem Rynek doradztwa w zakresie zarządzania majątkiem przechodzi poważną transformację. Historycznie rynek ten jest bardzo praktyczny, prowadzony przez doradców finansowych, którzy wykorzystują swoje doświadczenie i wiedzę, aby doradzać swoim klientom w zakresie zarządzania majątkiem. Aplikacja RAGE AITM jest wykorzystywana przez wiodące firmy zarządzające majątkiem do inteligentnej automatyzacji procesu od końca do końca w całym spektrum bogactwa - od sprzedaży detalicznej do wysokiej wartości netto i klientów instytucjonalnych.
• Skuteczność leków na receptę Istnieje wiele użytecznych informacji na temat skutków działania leków oraz ciągły strumień badań naukowych wysokiej jakości, które są publikowane w sposób ciągły. FDA publikuje również kwartalne statystyki dotyczące negatywnych skutków. Aplikacja RAGE AITM syntetyzuje wszystkie te informacje i próbuje zidentyfikować trendy i informacje, które powinny zainteresować konsumentów, firmy farmaceutyczne, ubezpieczycieli i organy regulacyjne. Stwierdziliśmy, że w wielu przypadkach aplikacja RAGE AITM mogła z łatwością przewidzieć działania FDA, takie jak ostrzeżenia z czarnej skrzynki, na długo przed tym, zanim akcja się wreszcie wydarzyła.
• Uzgodnienie RAGE AITM może uzgadniać transakcje na wielu dokumentach, czasem z wielu systemów. Na przykład duży producent i dystrybutor żywności musi pogodzić swoje planowane trasy transportu i koszty z kosztami transportu opartymi na rzeczywistych trasach oraz triangulować koszty w umowach z dostawcami transportu. W innym przykładzie globalna firma świadcząca usługi finansowe musiała uzgodnić faktury dla swoich klientów z umowami podstawowymi. W takich przypadkach aplikacje RAGE AITM zapewniają uzgadnianie w czasie rzeczywistym.
Te przypadki użycia dotyczą wielu branż - usług finansowych, logistyki, żywności i napojów, nauk przyrodniczych i usług konsultingowych. Inteligencja maszynowa w wyżej wymienionych przypadkach została nabyta w dużej mierze w sposób zautomatyzowany, a także skorzystała z wiedzy eksperckiej dostarczonej przez ekspertów. We wszystkich tych przypadkach czytelnicy powinni odrzucić fakt, że są to prawdziwe, działające aplikacje, które dostarczają dziś wgląd i inteligencję przedsiębiorstwom. To nie jest hipotetyczne. Poziom wglądu będzie nadal wzrastał w każdym z tych obszarów, ponieważ maszyny zdobywają więcej danych doświadczalnych, a eksperci dostarczają więcej wiedzy. Inną bardzo ważną rzeczą dla czytelnika jest to, że uczenie maszynowe nie musi być czarną skrzynką. Metody głębokiego uczenia się mogą być całkowicie kontekstualne i możliwe do prześledzenia.
Inteligentne przedsiębiorstwo jutra
DROGA DO INTELIGENTNEGO PRZEDSIĘBIORSTWA
U podstaw wszystkich przedsiębiorstw leży ich architektura komercyjna lub biznesowa. Jak są skonfigurowane do działania? W jaki sposób są zaprojektowane do działania w celu maksymalizacji wartości dla swoich interesariuszy? Jak są skonfigurowani do konkurowania? W jaki sposób są zaprojektowane, aby zapewnić reaktywność na rynku ?. Post Adam Smith architektura korporacyjna oparta była na podstawowym podziale pracy i koncentrowała się na wyspecjalizowanych funkcjach. Każda funkcja miała stać się wysoce kompetentna z ukierunkowaniem i umiejętnościami zespołów funkcjonalnych oraz zapobiegać fragmentacji umiejętności w zakresie wytwarzania produktu końcowego na dużą skalę. Było to środowisko, w którym technologia biznesowa nie istniała. Tak więc jedynym sposobem na zwiększenie skali była specjalizacja. Taki widok nie w pełni uwzględniał silosy, które utworzyłyby w organizacji i nie miał w pełni widocznych interesów klientów. W rezultacie wielu zwolenników architektury skoncentrowanej na procesach biznesowych. Hammer i Champy mocno wyrazili tę pozycję w swojej przełomowej pracy. W erze współczesnej z coraz bardziej płaskim światem i znacznie odmiennym krajobrazem technologicznym architektura zorientowana na procesy nabrała dużego rozmachu. Wiele korporacji są nadal zorganizowane w sposób funkcjonalny, hierarchiczny w swoich działach organizacyjnych. Organizacje funkcjonalne z kilkoma wyjątkami często zapewniają klientom mniej niż optymalne wrażenia. Występują częste awarie w wykonywaniu procesów, co prowadzi do starań o ochronę ich marki w reakcji na złe doświadczenia klienta. Z jednej strony zaletami organizacji funkcjonalnej jest to, że łatwiej jest przestrzegać standardów, ponieważ różne grupy specjalizują się w funkcji lub zadaniu, przyspiesza specyficzny dla funkcji lub wertykalny przepływ informacji, osiąga korzyści skali, ponieważ każda grupa funkcjonalna jest dedykowana tylko ta funkcja i role są przejrzyste. Z drugiej strony organizacja funkcjonalna jest zwykle znacznie wolniejsza w odpowiedzi na potrzebę zewnętrzną, ponieważ musi koordynować działanie lub reakcję w ramach wielu funkcji, brakuje elastyczności na poziomie procesu i nie zapewnia odpowiedniej widoczności ani przepływu informacji w całym procesie biznesowym obejmujący wiele funkcji. Stwierdzono, że funkcjonalna organizacja prowadzi do istotnych problemów z koordynacją i kontrolą oraz nie odpowiada na potrzeby klientów lub rynku. Z kolei organizacja zorientowana na procesy obraca się od końca do końca procesów biznesowych. Chociaż organizacja zorientowana na funkcje umożliwiła przedsiębiorstwom zwiększenie skali w erze rewolucji postindustrialnej, gwałtowny wzrost skali, wraz ze specjalizacją, doprowadził do powstania silosów organizacyjnych i sprawił, że mniej reagują na rynek, a zmiany oczekiwań klientów są napędzane Internet i komunikacja mobilna. Ta słabość organizacji zorientowanej na funkcje stała się bardziej widoczna w dzisiejszym bardzo dynamicznym świecie, w którym przedsiębiorstwa muszą koniecznie dostosować się i wprowadzać innowacje w swoich procesach od końca do końca. Procesy mogą być ze sobą powiązane na wyższych poziomach przedsiębiorstwa. Procesy biznesowe są zazwyczaj częścią większego obrazu. Właściciele firm mają obowiązek utrzymywania optymalnych procesów biznesowych przez cały czas. Mają kontrolę nad zasobami funkcjonalnymi wymaganymi w trakcie wykonywania dowolnego z procesów biznesowych. Zalet organizacji zorientowanej na procesy jest wiele. Ukierunkowanie na proces eliminuje funkcjonalne silosy i poprawia zdolność organizacji do reagowania na potrzeby klientów lub rynku. Promuje również innowacje na poziomie procesów biznesowych, a nie tylko na poziomie zadań. W rzeczywistości niewiele organizacji było w stanie osiągnąć prawdziwą reorientację procesów, głównie ze względu na ograniczenia technologiczne i znaczące zmiana kultury zaangażowana w przekształcanie ich orientacji. Niemniej jednak okazuje się, że często narastające frustracje wynikające z niezdolności organizacji zorientowanej na funkcje do reagowania na potrzeby rynku ostatecznie prowadzą do dużych projektów transformacji organizacyjnej, a tym samym zasadniczo zmuszają do transformacji zorientowanej na proces. Hasła takich projektów często odzwierciedlają te frustracje - "Jeden i zrobiony", "Globalny" i tak dalej. Warto wspomnieć o innym wymiarze projektowania korporacyjnego. Na tym polega różnica między projektowaniem a wykonaniem w architekturze korporacyjnej. Projektowanie odnosi się do projektowania strategii, modeli biznesowych i procesów biznesowych. Jednak po ustaleniu strategii procesy biznesowe są zaprojektowane tak, aby były wielokrotnie wykonywane przez zespół produkcyjny przedsiębiorstwa . Często w tych przedsiębiorstwach niektórzy członkowie zespołu produkcyjnego pomagają w projektowaniu architektury korporacyjnej. Niezależnie od tego, czy organizacja jest zorientowana na funkcje czy procesy, tylko kilku członków będzie zaangażowanych w projektowanie architektury; większość członków organizacji będzie zaangażowana w egzekucję. Każda organizacja dąży do stworzenia ciągłej pętli sprzężenia zwrotnego między częścią wykonawczą a projektową swoich procesów biznesowych. Tam, gdzie jest to dobrze skoordynowane, wszystko działa bardzo dobrze. W większości przypadków nie ma systematycznego projektu. Z czasem problemy narastają; kiedy rzeczy dochodzą do punktu, w którym są bardzo zauważalne, następuje reakcja, a ulepszenia procesu zwracają uwagę. Nie dzieje się tak dlatego, że przedsiębiorstwom brakuje chęci ciągłego doskonalenia, ale raczej z powodu ogromnego wysiłku, który zwykle wiąże się z wprowadzaniem nawet niewielkich zmian w procesach z powodu nieelastyczności lub braku odpowiedzi technologia.
EWOLUCJA ARCHITEKTURY PRZEDSIĘBIORCZOŚCI
Jak zauważyliśmy w rozdziałach 2 i 3, ostatnie postępy technologiczne oferują ekscytujące perspektywy zmian w architekturze przedsiębiorstw. Nasza teza jest taka, że postępy te umożliwią przedsiębiorstwu osiągnięcie tego, co nazywamy "inteligentnym" stanem. Co więcej, ta przyszła architektura będzie miała poważne implikacje dla roli ludzi w miejscu pracy i rodzaju pracy wykonywanej przez ludzi. Przedsiębiorstwa już wdrażają inteligentne maszyny, które automatyzują większość działań wykonywanych przez ludzi po stronie wykonawczej, a z czasem maszyny prawdopodobnie uzyskają wgląd dla ludzi w zakresie projektowania różnych procesów biznesowych. W tym rozdziale staramy się nakreślić drogę do takiego inteligentnego przedsiębiorstwo. Zanim opracujemy architekturę dla przedsiębiorstwa jutra, pokrótce prześledzimy ewolucję takich architektur w połączeniu z falami technologicznymi i strukturą pracy w czasie.
Ewolucja technologii
W naszym szkicu mapy drogowej inteligentnego przedsiębiorstwa widoczny jest znaczący wpływ technologii biznesowej. Technologia ewoluowała, pozostawiając niezatarty ślad na wszystkich aspektach procesów biznesowych. Zautomatyzowała przyziemne i mechaniczne prace, a śledzenie postępów technologicznych stało się głównym źródłem siły konkurencyjnej każdej firmy.
Technologia 1.0 : Każdy ważny etap ewolucji technologii miał odpowiedni wpływ na ewolucję architektury wykonawczej przedsiębiorstwa. W miarę ewolucji paradygmatów technologii, architektury korporacyjne dostosowywały się i zmieniały, wykorzystując nowe możliwości i wyzwania. Każdy kolejny etap ewolucji technologii z kolei wywoływał kaskadę zmian w projektowaniu samych przedsiębiorstw. Najnowsze postępy w dziedzinie technologii wymagają bardziej dramatycznych zmian w tym, jak przedsiębiorstwa mogą zracjonalizować swoje funkcje dzisiaj i w przyszłości. Na początku komputery były wykorzystywane głównie do prowadzenia dokumentacji w celu utrzymywania dokumentacji płacowej i finansowej. Pamiętam, że pod koniec lat 70. zamykanie ksiąg finansowych do 10. dnia następnego miesiąca było wielką sprawą. Wszystkie transakcje zostały zarejestrowane na papierze, a następnie przetworzone na koniec miesiąca. Używanie komputerów do podejmowania decyzji i analiz było odległym marzeniem. Jednak od 30 do 40 lat od tego czasu zaobserwowaliśmy skok kwantowy w zakresie możliwości obliczeniowych. Około 2-3 dekady temu interakcja człowiek-komputer zaczęła wykraczać poza prowadzenie rejestrów do podstawowej wydajności i komunikacji. Głównym przełomem był e-mail. A zapisywanie na komputerach mainframe zaczęło pojawiać się na mniejszych komputerach stacjonarnych, zwanych minikomputerami. Wiele innowacji w tamtych latach dotyczyło sprzętu komputerowego i mocy obliczeniowej. Dużo pracy wymagało drogiego przechowywania danych. Z biznesowego punktu widzenia maszyna do pisania IBM z lat 60. XX wieku ustąpiła miejsca edytorom tekstu z lat 70., takim jak Wang, a następnie pod koniec lat 80. szybko edytorom tekstu na PC .
Technologia 2.0 : Potem przyszedł komputer osobisty. Wprowadzenie IBM PC XT i IBM PC AT w 1984 i 1985 r. Miało miejsce w momencie, gdy pojawiły się aplikacje poprawiające podstawową produktywność (edytor tekstu, arkusz kalkulacyjny, prezentacja), a wraz z tym opracowaniem zaczęły pojawiać się punktowe rozwiązania dla bardziej zaangażowanych procesów biznesowych. pojawić się. Jednocześnie nastąpił znaczący przełom w dziedzinie obliczeń, polegający na oddzieleniu danych od programów komputerowych i powstaniu dedykowanych baz danych. Codd i Date wprowadzili relacyjny model danych, aksjomatyczne podejście do reprezentacji danych, które zapewniało zapewniony poziom integralności danych, gdy zaczęliśmy manipulować danymi w bazach danych.
Gdy zaczęły się rozpowszechniać rozwiązania punktowe, firmy zdały sobie sprawę, że aplikacje te są nieelastyczne, a ich modernizacja i udoskonalanie są drogie. Dyskutowano, że lepszym sposobem mogą być znormalizowane aplikacje przynajmniej do nie-podstawowych procesów biznesowych, takich jak planowanie zasobów i rachunkowość finansowa. Pojawiły się ERP i rozwiązania pakietowe. Programowanie strukturalne zostało wprowadzone w latach 80. Architektura klient-serwer ewoluowała, aby przenieść logikę w dół z komputerów mainframe i wykorzystać możliwości pulpitu. Metodologicznie dojrzałość zdolności uniwersytetu Carnegie Mellon Model (CMM) umożliwił rozwój oprogramowania z formy artystycznej o wysokim poziomie niezawodności i problemów jakościowych do nauki. Skupienie się na podejściach metodologicznych przekształciłoby cykl życia oprogramowania (SDLC) w inżynierię i zwiększyłoby przewidywalność i niezawodność tworzenia oprogramowania w ogóle. Niemniej jednak podejścia te zasadniczo nie były w stanie sprostać wyzwaniom związanym z rynkiem, elastycznością oraz wiedzą / wglądem. Ewolucja w SDLC próbowała sprawić, by SDLC była bardziej wydajna, ale nie udało się radykalnie zmienić samej SDLC.
Technologia 3.0 : Najważniejszą częścią technologii 3.0 była powszechna łączność z publiczną dostępnością Internetu w latach 90. Zwiastowało to bezprecedensową falę zmian w krajobrazie technologicznym. Aplikacje oparte na przeglądarce stały się popularne, wracając do modelu skoncentrowanego na serwerze od czasów komputerów mainframe. Uczenie maszynowe cicho wspierało wyszukiwanie w Internecie i nagle zaczęły się pojawiać nauki o zarządzaniu i modele algorytmiczne. Przetwarzanie języka naturalnego rozlane z akademickich laboratoriów do świata rzeczywistego; językoznawstwo komputerowe zyskało prawdziwy impet dzięki opracowaniu kluczowych narzędzi wspomagających, takich jak Wordnet. W tym okresie pojawiło się wiele platform technologii open source, takich jak Java, J2EE, Spring / Hibernate, .Net., JavaScript, Eclipse oraz duża liczba narzędzi Open Source. Ułatwiły one i przyspieszyły programowanie oraz umożliwiły przenoszenie między systemami operacyjnymi. Wszystkie były zmianami, które były niewyobrażalne w fazie Technologii 2.0.
Technologia 4.0 : Każda faza technologii zapoczątkowała nową falę możliwości i wpływu. Uważamy jednak, że następny etap ewolucji technologii przyniesie niespotykaną dotąd zmianę w sposobie projektowania i funkcjonowania przedsiębiorstw. Jak omówiono w rozdziale 2, cel technologii biznesowej w kontekście przedsiębiorstwa można postrzegać przez cztery wyzwania, które należy rozwiązać - niezawodność, elastyczność, czas wprowadzenia na rynek i wiedzę. Technologia 3.0, choć wyraźnie ogromna poprawa w porównaniu z poprzednimi możliwościami technologicznymi, nie rozwiązała podstawowych problemów związanych z czasem wprowadzenia na rynek, potrzebą radzenia sobie z szybkimi zmianami potrzeb biznesowych oraz zależnością od dostępności specjalistycznych zasobów. Pojawienie się Internetu sprawiło, że firmy muszą teraz zająć się eksplozją informacji. Całkiem niedawno korporacje zaczęły stosować metodyki zwinne. Jak w przypadku wszystkiego nowego, musimy jeszcze zobaczyć, co osiągną metodologie Agile. Metodologii zwinnej nie należy jednak mylić z poprawą czasu wprowadzania na rynek, a nawet elastycznością. Główną zaletą metodyki Agile jest poprawa niezawodności i zwiększenie prawdopodobieństwa, że produkt końcowy zaspokoi potrzeby biznesowe. Naprawdę ważne jest, aby zdać sobie sprawę, że zwinność nie równa się zwinności. Przyjęcie zwinnych metodologii nie rozwiąże problemów związanych z rynkiem i elastycznością. Niemniej jednak w obecnej fazie ewolucji technologii wprowadzono elastyczne, zorientowane na model platformy oparte na metadanych, które umożliwiają tworzenie oprogramowania w czasie zbliżonym do rzeczywistego, bez konieczności programowania. Utworzenie aplikacji o kluczowym znaczeniu dla przedsiębiorstwa nie zajmie już roku ani dwóch. Oprogramowanie będzie od podstaw zorientowane na proces, umożliwiając przedsiębiorstwom pełną elastyczność w modyfikowaniu oprogramowania w razie potrzeby, dosłownie w locie. Może to mieć ogromny wpływ na branżę oprogramowania. Odważmy się mówić, że programowanie wyginie za 10 do 20 lat!
Innym rozwojem, który ma znaczące implikacje dla wszystkich przedsiębiorstw, jest dojrzewanie technologii AI. Sztuczna inteligencja szybko wychodzi z laboratoriów badawczo-rozwojowych do głównego nurtu. Statystyki obliczeniowe odniosły znaczący sukces w aplikacjach komputerowych - takich jak autonomiczne pojazdy i rozpoznawanie twarzy. Technologie głębokiego uczenia się są obecnie z powodzeniem stosowane w głównych procesach biznesowych, co ilustruje kilka rozdziałów tej książki. Podczas gdy uczenie maszynowe oparte na statystykach obliczeniowych odniesie sukces w niektórych domenach, takich jak widzenie komputerowe, identyfikowalne metody uczenia maszynowego zyskają popularność i zaufanie. W szczególności uważamy, że identyfikowalne podejścia do rozumienia języka naturalnego będą miały ogromny wpływ na budowę inteligentnych maszyn. Rok 2010 zapowiada się na erę inteligencji maszynowej. Rozwój ten ma między innymi znaczące implikacje do taniego, ręcznego outsourcingu. Inteligentne maszyny prawdopodobnie zautomatyzują pracę opartą na wiedzy. Jak wspomniano, każdy etap ewolucji technologii miał ostateczny wpływ na projektowanie i architekturę przedsiębiorstwa. Prześledźmy teraz nasz pogląd na tę ewolucję.
Enterprise 1.0 - People Led, Manual; Nienaruszalne informacje Dzięki technologii 1.0 architektura korporacyjna w latach 60. była na tym etapie głównie skoncentrowana na ludziach. Pracownicy wiedzieli, jak mają być wykonywane procesy biznesowe; wiedza była przetwarzana tylko w umysłach pracowników i działali na podstawie informacji. Informacje przepływały między ludźmi w sposób manualny, a pracownicy wykonywali swoje funkcje. Ten etap przedsięwzięcia architektura została w znacznym stopniu włączona przez pocztę elektroniczną i komputery mainframe. Zarówno projekt, jak i wykonanie wykonano całkowicie ręcznie. Na tym etapie, jak pokazano na rycinie 4.6, firmy były całkowicie zależne od ludzkich wspomnień i możliwości, a instytucjonalizacja procesów biznesowych była niewielka lub żadna. Bardziej zorganizowane lub większe firmy miały na papierze wiele podręczników procedur. Każda osoba wykonywała swoje zadanie w procesie i zwracała się do następnej osoby, aby wykonać następne zadanie. W razie wątpliwości pracownicy mogli zapoznać się z instrukcją obsługi. Błędy były dość powszechne. Skalowanie i innowacje biznesowe były znacznie bardziej ograniczone.
Enterprise 2.0 - Wyspy nieelastycznej automatyzacji, sztywne przepływy informacji Dzięki technologii 2.0, rchitektura korporacyjna zaczęła odzwierciedlać wpływ technologii biznesowej (rysunek 4.7). Firmy zaczęły wdrażać rozwiązania punktowe i stworzyły wyspy automatyzacji. Odkrycie możliwości korzystania z technologii w postaci aplikacji prowadzi do eksplozji rodzimych, niestandardowych aplikacji. Przepływ pracy i informacji był w pewnym stopniu zautomatyzowany, ale faktyczną pracę pozostawiono ludziom. Na pewno istniały punktowe rozwiązania i technologie, które umożliwiły ludziom wykonywanie pracy znacznie efektywniej w porównaniu z Technologią 1.0. Procesy biznesowe zostały na stałe zakodowane w tych punktowych rozwiązaniach. Dopóki procesy biznesowe nie ulegną zmianie, a aplikacje będą wystarczająco solidne, firmy będą mogły skalować. Ale każda zmiana byłaby paraliżująca i wróciłaby z powrotem do Enterprise 1.0. Rozwój oprogramowania był nadal w dużej mierze formą sztuki w latach 80. Z biegiem czasu, ze względu na wysokie koszty utrzymania aplikacji niestandardowych i niepowodzenia większości projektów programistycznych, wprowadzono modułowe, strukturalne programowanie, a później standardy programowania, a ostatecznie CMM uczyniło tworzenie oprogramowania bardziej naukowym. Faza ta charakteryzowała się wysokim odsetkiem niepowodzeń projektów rozwoju oprogramowania oraz wysokim poziomem nieprzewidywalności w realizacji obietnicy technologii biznesowej. Oprogramowanie wykonało akty automatyzacji punktów. Brakowało elastyczności. Chociaż ogólnie zdawano sobie sprawę, że przedsiębiorstwa muszą być napędzane procesami, większość z nich to leksykon konsultanta ds. Strategii i niewiele można było wdrożyć w praktyce. Technologia pozostawała w tyle za potrzebą elastyczności i zmian.
Enterprise 3.0 - Standardowe aplikacje pakietowe; Przepływ pracy Oszołomiony niepowodzeniami związanymi z większością prac związanych z tworzeniem oprogramowania i wysoką konserwacją niestandardowych aplikacji, przedsiębiorstwa zdecydowały się na przyjęcie znormalizowanych pakietów oprogramowania. Oznaczało to oczywiście, że przedsiębiorstwa w dużym stopniu polegały na interpretacji procesów biznesowych w swojej branży i miały nadzieję, że uda im się je dostosować do własnych potrzeb. Na scenę wkroczyły systemy planowania zasobów przedsiębiorstwa (ERP). Wdrożenie ERP stało się własną branżą w latach 90. Wiele firm konsultingowych wprowadza ogromne praktyki, wdrażając tylko aplikacje ERS, takie jak SAP i Oracle. Kiedy czytasz publiczne raporty o tych implementacjach, oczywiste będzie, że były one sztywne, nieelastyczne i drogie. W rzeczywistości w latach 90. istniało tak wiele horrorów o tym, jak implementacje poszły strasznie źle lub spowodowały ogromne przekroczenie kosztów w dużych międzynarodowych korporacjach. Znam tak wiele firm z listy Fortune 500, w których ludzie drapali się po głowach, próbując obejść długoterminowe wdrożenie aplikacji ERP. Podczas tych wdrożeń często różne działy lub jednostki biznesowe korzystały z różnych aplikacji ERP i nie rozmawiały ze sobą. To pozostawiło zespoły operacyjne do zebrania jakiegoś patchworkowego rozwiązania lub skorzystania z pracy ręcznej, aby wykonać swoją pracę. Na przykład menedżerowie kredytowi musieliby wyszukiwać wiele systemów i ręcznie dodawać ekspozycje, aby uzyskać całkowitą ekspozycję dla klienta. Lub personel ds. Należności nie byłby w stanie przeglądać działów, aby zobaczyć, co jest winien klient i tak dalej. Wszechobecna adopcja i korzystanie z Internetu działały jak katalizator nowej klasy aplikacji pakietowych, które pojawiły się w tym okresie. Aplikacje te zmodyfikowały pomysł posiadania licencji na aplikację na pomysł używania aplikacji jako usługi. Dzisiaj SaaS lub aplikacje chmurowe, takie jak Salesforce, stały się bardzo popularne. Salesforce odniósł ogromny sukces głównie ze względu na łatwość adopcji, destrukcyjny model ekonomiczny i wbudowane środowisko programistyczne. Jednak widzimy ten sam poziom sztywności procesu w aplikacjach SaaS. "Tańsze" nie rozwiązuje podstawowych problemów związanych z czasem wprowadzenia na rynek i elastycznością. Te zapakowane produkty w najlepszym razie były w stanie dostarczyć kilka pokręteł i dźwigni, aby zmienić niektóre określone funkcje produktu. Wdrożenie kompleksowych procesów leżących u podstaw tych aplikacji jest w dużej mierze naprawione. Ten proces został naprawiony w tych aplikacjach. Można je modyfikować poprzez programowanie niestandardowe. Ale ustalony Ps tworzy sztywność. Dzięki tym zapakowanym produktom przedsiębiorstwa wciąż nie są w stanie szybko dostosować się do zmian warunków rynkowych. Większość przedsiębiorstw nadal jest nieefektywna, ale przyzwyczaiła się do długich cykli budowy technologii i ich względnej niezdolności do szybkiego dostosowania się do zmian rynkowych.
Enterprise 4.0 - Intelligent Enterprise of Tomorrow Technology 4.0 może powodować dramatyczne zmiany w architekturze korporacyjnej. Jest to oczywiście powód, dla którego uważamy, że przejście na Enterprise 4.0 spowoduje znacznie większą zmianę niż poprzednie fale zmian. Rysunek 4.9 pokazuje Enterprise 4.0 na znacznie większej wysokości niż Enterprise 3.0. Przedsiębiorstwo jutra może przenieść się na zupełnie inny płaskowyż.
W ciągu ostatnich 5-10 lat nastąpił ogromny postęp w zakresie możliwości technologicznych, który sprawia, że możliwe jest stworzenie zupełnie innej architektury korporacyjnej. Taka architektura umożliwi realizację "inteligentnego przedsiębiorstwa" o bardzo różnych rolach dla ludzi i maszyn. "Przyszłość pracy" będzie zupełnie inna. Jak wyjaśniliśmy w rozdziałach 2 i 3, widzimy trzy kluczowe czynniki tego przejścia na inny płaskowyż - elastyczny rozwój oprogramowania prawie w czasie rzeczywistym; umiejętność tworzenia inteligentnych maszyn, które będą wykonywać pracę opartą na wiedzy; oraz dostępność ogromnych informacji. Podsumowujemy krótko te trzy sterowniki i wprowadzamy architekturę odzwierciedlającą te sterowniki w Enterprise 4.0.
Elastyczne tworzenie oprogramowania w czasie zbliżonym do rzeczywistego
Jak opisano wcześniej, ramy technologii oparte na meta-modelach umożliwią tworzenie oprogramowania w czasie rzeczywistym bez żadnego programowania. Ramy te są od podstaw zorientowane na procesy biznesowe. Zapewniają one możliwość skonfigurowania całego procesu biznesowego do potrzeb konkretnego przedsiębiorstwa. Zostały zaprojektowane tak, aby całkowicie zrezygnować z programowania, ale można je rozszerzyć o programowanie w razie potrzeby. Opierają się na architekturze opartej wyłącznie na metadanych, wykorzystującej abstrakcyjny proces biznesowy jako "model". W konsekwencji całe aplikacje i wszystkie ich procesy biznesowe zostaną zredukowane do danych i zapisane jako dane. Wyobraź sobie aplikację jako zestaw schematów blokowych, które są jej procesami biznesowymi; wyobraź sobie, że jesteś w stanie zaimplementować te schematy przepływu wizualnie przy użyciu bloków konstrukcyjnych z ram technologicznych. Te bloki są abstrakcyjne i niezależne od kontekstu. Modeler lub analityk biznesowy zapewnia kontekst, jako metadane, takim abstrakcyjnym blokom. Mechanizm wykonawczy frameworka może wykonywać proces biznesowy, w tym dynamiczny interfejs użytkownika, w czasie wykonywania, buforując wszystkie metadane dla modelu procesu biznesowego. Takie ramy naprawdę umożliwią przedsiębiorstwom projektowanie i wdrażanie procesów biznesowych specyficznych dla ich firm i środowisk w sposób zbliżony do czasu rzeczywistego. Ramy te całkowicie z czasem wyeliminują programowanie specyficzne dla aplikacji. Oprócz takich horyzontalnych ram technologicznych pojawią się pionowe ramy rozwiązań odzwierciedlające najlepsze praktyki w różnych domenach. Są to wstępnie spakowane struktury procesów, które są przykładowymi modelami procesów biznesowych potrzebnych w domenie. Ramy LiveWealthTM, LiveCreditTM i LiveSpreadTM z RAGE Frameworks są przykładami takich ram wertykalnych. Są używane w globalnych przedsiębiorstwach i zapewniają im szybką, nieograniczoną elastyczność, a także znaczącą przewagę konkurencyjną. Te ramy pionowe można zestawić z aplikacjami w pakiecie. Ramy wertykalne pozwalają przedsiębiorstwom konfigurować je od podstaw przy bardzo niewielkim wysiłku i bez specjalistycznych umiejętności, takich jak programowanie. Możliwość umożliwienia przedsiębiorstwom konfigurowania swoich frameworków bez programowania uwolni wiele innowacji w branży aplikacji pakietowych w nadchodzących latach. Przewidujemy przyszłość, w której wszystkie aplikacje będą w pełni konfigurowalne od podstaw. Podobnie oczekujemy wielu zakłóceń w branży oprogramowania. Platformy takie jak RAGE AITM odwracają konwencjonalny zorientowany na przyszłość cykl rozwoju oprogramowania, jak omówiono w rozdziale 2. Przewidujemy znacznie mniejsze zapotrzebowanie na programowanie w ogóle.
Inteligencja maszyny
Drugim kluczowym sterownikiem dla Enterprise 4.0 ustawionym na podwyższone tempo zmian jest inteligencja maszyny. Jak wyjaśniono wcześniej, dostępność ogromnych ilości informacji w czasie rzeczywistym spowodowała zarówno przeciążenie informacji, jak i możliwość uzyskania wglądu wcześniej uważanego za niemożliwy. To dało impuls do dojrzewania technologii języka naturalnego i do ponownego skupienia się na "analizie tak ogromnej ilości informacji", popularnie zwanej także BigData Analytics. Przewiduje się, że takie analizy będą w stanie analizować ustrukturyzowane dane i / lub język naturalny. Analiza danych strukturalnych niekoniecznie jest nowa, choć objętość i podejście algorytmiczne są stosunkowo nowe. Analiza tekstu w języku naturalnym jest całkiem nowa. Inteligencję maszyn nazywamy automatyzacją takich analiz - od zdobywania wiedzy, poprzez automatyczne wyciąganie wniosków z ogromnej ilości danych, po automatyczną integrację takich wniosków z resztą procesów biznesowych. Szybkie dojrzewanie BigData Analytics, szczególnie możliwość analizowania nieustrukturyzowanego tekstu, oferuje przedsiębiorstwom ekscytującą okazję do zdobycia inteligentnych maszyn dedykowanych do różnych procesów biznesowych. Inteligencję maszynową można tworzyć nawet w przypadku procesów rozmytych, takich jak inteligencja konkurencyjna, w systematyczny i znaczący sposób. Skuteczne wykorzystanie tej możliwości stanowi sedno inteligentnego przedsięwzięcia jutra i będzie konieczną konkurencją
Architektura E4.0
Jak już obszernie omawialiśmy, tempo dostępności i wzrostu informacji tylko przyspiesza. Wystarczy powiedzieć, że z każdym urządzeniem, które zaczyna teraz emitować informacje, jeszcze niczego nie widzieliśmy! To prowadzi nas do Enterprise 4.0. W E4.0 przewidujemy dużą zmianę w sposobie interakcji ludzi z maszynami. Inteligentne maszyny będą miały znacznie większy udział w codziennym funkcjonowaniu przedsiębiorstwa. Wyobrażamy sobie taką architekturę, aby mieć inteligentne maszyny dedykowane do określonych procesów biznesowych i domen. Takie maszyny zostaną zbudowane na platformie takiej jak RAGE AIi będą pełnić dwie funkcje: dostarczać ludziom informacji umożliwiających optymalne projektowanie inteligentnych procesów biznesowych poprzez ciągłą analizę ogromnych ilości danych i automatycznie przeprowadzać transakcje biznesowe bez pomocy człowieka na podstawie zautomatyzowany proces biznesowy zaprojektowany przez ludzi. Maszyny analityczne zdobędą wiedzę na podstawie ciągłych analiz ogromnych ilości danych. Taka wiedza i wgląd pozwoli ludziom udoskonalić swoje projekty. Ludzie będą pełnić trzy ważne role: projektować inteligentne procesy biznesowe, udoskonalić pozyskiwane zautomatyzowane maszyny wiedzy i przetwarzaj wyjątki, których maszyna nie może obsłużyć. Inteligentne procesy biznesowe będą projektowane i wdrażane niemal w czasie rzeczywistym przy użyciu RAGE AITM. Ponieważ automatyczne pozyskiwanie wiedzy przez maszyny stanie się niezawodne i kompletne dopiero z czasem, ludzie będą potrzebni do przetwarzania transakcji wyjątkowych. Ludzie będą ponadto potrzebni do selekcji wiedzy zgromadzonej przez maszyny lub maszyny siewne z wiedzą początkową, lub do dostarczenia szerszej wiedzy tam, gdzie maszyny nie są w stanie jej zebrać. Inteligentna architektura korporacyjna składa się z dziewięciu komponentów:
1. Czujniki zewnętrzne. Są to inteligentne maszyny, które nieustannie wykrywają otoczenie zewnętrzne z różnych aspektów. Na przykład czujnik konkurencji może skanować środowisko zewnętrzne, aby monitorować rozwój konkurencji, nowe innowacje, modele biznesowe i tym podobne. Czujniki te są zaszczepione wiedzą dostarczoną przez ekspertów ludzkich zidentyfikowanych jako pozycja 4. Taka wiedza jest zawarta w magazynie wiedzy oznaczonym jako pozycja 6. Może ona przybrać formę szkieletowej mapy koncepcji, jak opisano w rozdziale 3. Platforma RAGE AITM ma umiejętność automatycznego odkrywania wiedzy w uzupełnieniu wiedzy o nasionach dostarczonej przez Ekspertów. Z czasem, gdy te inteligentne maszyny zdobędą coraz więcej wiedzy, będą w stanie dostarczyć wgląd, który pomoże ekspertom od ludzi ulepszyć ich produkty i procesy, jak pokazano w punkcie 3 - Projekt BP.
2. Czujniki wewnętrzne. Podobnie jak czujniki zewnętrzne, czujniki wewnętrzne monitorują i analizują wiedzę wewnętrzną zawartą w odpowiednich dokumentach. Wiele firm ma dogłębną wiedzę i informacje w wewnętrznych dokumentach, które na ogół nie są odpowiednio wykorzystywane. Wewnętrzne maszyny wykrywające zostaną również obsadzone przez ekspertów od ludzi odpowiednią mapą koncepcyjną.
3. Projektowanie BP / Odkrywanie wiedzy. Ten komponent jest rzeczywistym projektem inteligentnych procesów biznesowych i / lub wykonuje automatyczne wyszukiwanie wiedzy za pomocą RAGE AITM. Projektowanie BP może być wykonane przez ekspertów. Odkrywanie wiedzy może być automatycznie wykonywane przez maszyny opcjonalnie w oparciu o mapy koncepcji nasion dostarczone przez ekspertów.
4. Ludzcy eksperci .Eksperci projektują procesy biznesowe dla środowiska wykonawczego. Ich konstrukcja będzie odzwierciedlać modele biznesowe i cele procesów biznesowych. Taki projekt będzie informowany na podstawie wszelkich informacji, które czujniki odkryją na bieżąco. Eksperci mogą również zainicjować proces odkrywania wiedzy, dostarczając swoją wiedzę na temat biznesu i różnych wymiarów biznesu, takich jak przemysł i odpowiednie produkty.
5. Inteligentne maszyny. BPE Jest to podstawowe środowisko wykonawcze. Dla porównania, środowisko to obejmuje spakowane i niestandardowe aplikacje w dzisiejszym kontekście. W Enterprise 4.0 takie środowisko będzie obejmować inteligentne maszyny sterowane przez RAGE AITM i wykonujące procesy biznesowe do obsługi transakcji biznesowych. Tyle transakcji, na ile pozwala projekt BP, zostanie obsłużonych automatycznie. Wyjątki zostaną skierowane do ludzi poprzez proces wyjątków, jak pokazano w punktach 8 i 9.
6. Inteligentny magazyn. BP / Knowledge Store Ten sklep będzie zawierał wszystkie procesy biznesowe zaprojektowane przez ekspertów, a także całą wiedzę zgromadzoną przez maszyny. Technicznie taki sklep może przybierać różne formy, takie jak baza danych, system plików i tak dalej. Jak szczegółowo omówiono w części 2, te modele procesów biznesowych będą wykorzystywać elementy abstrakcyjne na platformie opartej na meta modelach, takich jak RAGE AITM, i wyeliminują programowanie.
7. Transakcje biznesowe. Są to transakcje biznesowe, w które angażuje się przedsiębiorstwo. Pochodzą one spoza przedsiębiorstwa. W Enterprise 4.0 będą obsługiwane przez inteligentne maszyny oznaczone pozycją 5.
8. Wyjątki. Transakcje, których inteligentna maszyna nie może podejmować ani podejmować na ich podstawie czynności, zostaną oznaczone jako wyjątki wymagające interwencji człowieka.
9. Pracownicy fizyczni. Wyjątki będą rozstrzygane przez pracowników ludzkich. W Enterprise 4.0 celem jest zminimalizowanie lub wyeliminowanie takich wyjątków. Okresowo eksperci od ludzi będą analizować wyjątki w celu zidentyfikowania ulepszenia w ich projekcie BP, aby wyeliminować je w przyszłości.
W powyższej architekturze implikuje się dramatyczną zmianę struktury i przepływu pracy w przedsiębiorstwie. W zakresie, w jakim transakcja biznesowa jest przetwarzana automatycznie przez inteligentną maszynę, nie będzie w tym procesie roli dla ludzi. Nawet gdy istnieje wyjątek, maszyny będą napędzać przepływ i przydział pracy ludziom w celu przetwarzania wyjątków na podstawie danych wywiadowczych dotyczących pracy i siły roboczej. W E4.0 procesy biznesowe można dowolnie projektować i modyfikować. Wdrożenie będzie prawie w czasie rzeczywistym. Przedsiębiorstwa nie będą już wiązane ograniczeniami czasowymi związanymi z tworzeniem oprogramowania. Spodziewamy się, że zachęci to przedsiębiorstwa do ponownego przemyślenia przyjęcia nieelastycznych pakietów aplikacji. Pobudzi także branżę aplikacji pakietowych do korzystania z platform takich jak RAGE AITM i do gruntownego przeprojektowania swoich aplikacji, aby były elastyczne na poziomie procesów biznesowych.
LUDZIE I MASZYNY
Czy to oznacza, że maszyny zastąpią ludzi? I że duża liczba miejsc pracy zostanie wyeliminowana? Idea, że technologia będzie przestarzała, była przedmiotem dyskusji od stuleci. Wielu ekspertów rutynowo podnosi alarmy, że automatyzacja dzięki nowej technologii spowoduje ogromną liczbę utraty pracy. Wszyscy oczywiście możemy zobaczyć, że pomimo znacznego postępu technologicznego w ciągu ostatnich kilku stuleci miejsca pracy nie zniknęły. Jak podkreśla Akst, w latach 30. XX w. nie mniej niż John Maynard Keynes, najbardziej wpływowy ekonomista XX wieku, martwił się chwilowym "bezrobociem technologicznym", które, jak obawiał się, wzrosłoby szybciej niż liczba miejsc pracy stworzonych przez nowe technologie. Niepokoje związane z wpływem automatyzacji technologicznej na zatrudnienie powróciły w popularnej książce The Second Machine Age, w której Brynjolfsson i McAfee (2014) twierdzą, że postęp technologiczny pozostawi po sobie ludzi, być może nawet wielu ludzi, ponieważ pędzi przed siebie. Ich zdaniem nigdy nie było gorszego czasu na bycie pracownikiem o zwykłych umiejętnościach i zdolnościach do zaoferowania, ponieważ komputery, roboty i inne technologie cyfrowe nabywają takie umiejętności manualne w niezwykłym tempie. Uważamy, że te obawy są dość realistyczne. Nikt nie wie, jaki jest stopień zastępowania starych miejsc pracy nowymi miejscami pracy w wyniku fali automatyzacji nowych technologii. Wprawdzie nastąpiła już wyraźna zmiana umiejętności w pracy, jednak pomysł, że automatyzacja technologiczna wyeliminuje jedno zadanie, ale stworzy pracę dla innej umiejętności lub innej osoby, został dobrze rozpoznany. Autor twierdzi, że handel (import z Chin i innych krajów) spowodował wzrost bezrobocia w Stanach Zjednoczonych, podczas gdy technologia przekształciła rynek pracy w coś w rodzaju klepsydry, z większą liczbą miejsc pracy w takich dziedzinach, jak finanse i usługi gastronomiczne, a mniej między nimi . Panuje powszechna zgoda, że automatyzacja dotychczas nieproporcjonalnie eliminowała mniej wykwalifikowane miejsca pracy i stworzyła zapotrzebowanie na bardziej wykwalifikowanych pracowników. Autor zauważa, że w ciągu ostatnich kilku dziesięcioleci nastąpiła "polaryzacja" rynku pracy, w której wzrost płac poszedł nieproporcjonalnie do osób na szczycie i na dole rozkładu dochodów i umiejętności, a nie do tych pośrodku. Historycznie tempo nowych miejsc pracy zasadniczo nadążało za tempem przesunięć. Jednak obecne odrodzenie się lęku jest wynikiem tego samego zjawiska, które pojawia się wraz z każdą większą falą technologiczną - nie znamy specyfiki interakcji między eliminacją starych miejsc pracy a tworzeniem nowych miejsc pracy. Ignorując czas szkolenia wymagany dla nowych miejsc pracy, w punkcie, w którym przesunięcie będzie równe nowym stanowiskom, będzie równowaga. Istnieje scenariusz, w którym nowe miejsca pracy nigdy nie nadążają za przesunięciami, co spowoduje utratę miejsc pracy netto. Ważne jest, aby uznać, że porównania te są na poziomie makro. Gdy spojrzymy na określone branże i obszary geograficzne, wpływ może być zupełnie inny. Na przykład w branży outsourcingu procesów biznesowych (BPO), w której wiele miejsc pracy można uznać za osoby o niskich kwalifikacjach, wskaźnik przesunięć może być potencjalnie nieproporcjonalnie wysoki. Wierzymy, że ta fala automatyzacji zastąpi wiele miejsc pracy w branży BPO i najprawdopodobniej spowoduje przesunięcie miejsc pracy do pewnego stopnia w branży outsourcingu procesów wiedzy (KPO). Konieczne jest, aby firmy BPO zaczęły szybko się przekształcać i przeskakiwać z tą falą technologiczną. Zawsze wierzyłem, że rynek BPO nie jest zrównoważony na dłuższą metę. W rzeczywistości w wywiadzie dla Knowledge @ Wharton wyjaśniam moje uzasadnienie w pewnym stopniu szczegółowości. Jestem pewien, że wielu w branży BPO widziało tę falę, ale nikt nie odczuwał żadnej presji, by zmienić kurs do niedawna. Teraz klienci zaczęli domagać się dźwigni opartej na technologii lub "automatyzacji", co w końcu powoduje, że niektóre firmy BPO rozpoznają to wyzwanie w swoim modelu biznesowym. Uznając zjawisko wypierania opartego na umiejętnościach, Autor (2015) argumentuje, że zadania, które okazały się najbardziej dokuczliwe w automatyzacji, to takie, które wymagają elastyczności, oceny i zdrowego rozsądku. Dochodzi do wniosku, że jest mało prawdopodobne, aby automatyzacja objęła te Domeny. Twierdzi się, że technologie uczenia maszynowego oparte wyłącznie na rozpoznawaniu wzorców, bez zrozumienia pełnego kontekstu, nie osiągnęły jeszcze poziomu dojrzałości, w którym maszyny mogą zastąpić ludzi w sytuacjach krytycznych dla misji. Podczas gdy komputer IBM Watson, który słynął z triumfu w grze Jeopardy z mistrzowskimi ludzkimi przeciwnikami, udzielił również spektakularnie niepoprawnej odpowiedzi drugiego dnia na pytanie: "Największe lotnisko zostało nazwane bohaterem II wojny światowej; jego druga co do wielkości, pod względem bitwy II wojny światowej ", jak Toronto, miasto w Kanadzie. Należy zauważyć, że podstawowe technologie - oprogramowanie, sprzęt i dane szkoleniowe - szybko się poprawiają. Niektórzy badacze spodziewają się, że wraz ze wzrostem mocy obliczeniowej i wzrostem baz danych szkoleniowych podejście do uczenia maszynowego z użyciem brutalnej siły zbliży się lub przekroczy ludzkie możliwości. Inni podejrzewają, że uczenie maszynowe zawsze tylko "poprawi to", pomijając wiele najważniejszych i istotnych wyjątków. Ostatecznie tym, co czyni przedmiot krzesłem, jest to, że jest ono zbudowane specjalnie dla człowieka, na którym można usiąść. Algorytmy nauczania maszynowego mogą mieć fundamentalne problemy z rozumowaniem "celowości" i zamierzonego zastosowania, nawet biorąc pod uwagę dowolnie dużą bazę danych z obrazami. Autor dochodzi do bardzo ważnego wniosku: "Ironią algorytmów uczenia maszynowego jest to, że nie mogą też" powiedzieć "programistom, dlaczego robią to, co robią." Wniosek ten stanowi jedno z podstawowych założeń rozdziału 3. Wiele obecnych technologii uczenia maszynowego unika metod brutalnej siły opartych na statystykach obliczeniowych. Będą działać dobrze dla niektórych klas problemów, ale nie dla wielu. Co ważniejsze, nie replikują one funkcjonowania ludzkiego mózgu, jak twierdzą zwolennicy. Dlatego nie potrafią powiedzieć, dlaczego to robią robią. Jak szczegółowo opisano w rozdziale 3, znaczna poprawa osiąga jednak inny rodzaj technologii uczenia maszynowego, identyfikowalne i odpowiednie kontekstowo technologie uczenia maszynowego, takie jak RAGE AITM. RAGE AITM z czasem z powodzeniem odtworzy ludzką inteligencję, ponieważ powiela sposób, w jaki ludzie myślą bardziej uważnie. Odnieśliśmy się do aplikacji do analizy rynku wykorzystującej RAGE AITM, która wykrywa ważne i strategiczne zmiany w 20 sektorach w czasie rzeczywistym. Jego dokładność w każdym temacie dla każdego sektora jest konsekwentnie większa niż 90% tydzień po tygodniu. W aplikacji do poszukiwania sprzedaży, o której mowa również w części 3, aplikacja znajduje 250% trafniejszych elementów niż zespół 20 osób, które ręcznie wyszukują potencjalnych klientów. W przypadku zastosowania uzgadniania przeglądu kontraktu dla dużych firm z listy Fortune 500 takie podejście umożliwia identyfikację nadmiernych rachunków od dostawców. We wszystkich tych aplikacjach uzasadnienie rozwiązania jest całkowicie identyfikowalne i przejrzyste. Maszyny mogą nam dokładnie powiedzieć, dlaczego robią to, co robią. Wierzymy, że wykrywalne uczenie maszynowe i tworzenie oprogramowania w czasie zbliżonym do czasu rzeczywistego zyska na popularności w nadchodzącej dekadzie. Takie technologie uczenia maszynowego to jedyne podejście, które odniesie sukces. Czarne skrzynki, podobnie jak wiele obecnie dostępnych na rynku, będą działać tylko tam, gdzie identyfikowalność nie jest ważna, a dane bazowe są wysoce jednorodne. Technologie te będą polegały na kontekstowo odpowiednich magazynach wiedzy, tak jak my, ludzie, rozwijamy się z czasem. Jest to bardziej realistyczne odzwierciedlenie działania ludzkiego mózgu. Głupotą jest myśleć, że uczenie maszynowe odniesie sukces bez głębokiej wiedzy specyficznej dla Domeny, w której związek przyczynowo-skutkowy jest przejrzysty i możliwy do zweryfikowania. Możemy oczekiwać, że nastąpi znaczny rozwój w zdobywaniu wiedzy, dzięki czemu maszyny nie będą musiały poświęcać tyle czasu, co my, ludzie, obecnie, aby zdobyć tę samą wiedzę. W niedalekiej przyszłości widzę, że wiele obecnych umiejętności jest całkowicie eliminowanych, a ogólnie wysoki poziom ich umiejscowienia. Niektóre z nich będą umiejętnościami i miejscami pracy opartymi na wiedzy. Poważnie ucierpią zarówno branże BPO, jak i KPO (outsourcing procesów wiedzy). Widzę też, że branża programistyczna mocno odczuwa skutki rozwoju oprogramowania w czasie zbliżonym do rzeczywistego z niewielkim lub zerowym programowaniem. Chociaż programowanie nie wyginie w najbliższym czasie, będziemy potrzebować o wiele mniej programistów na mieszkańca w ciągu następnych kilku dekad. Programiści będą musieli zmienić się, aby zostać analitykami biznesowymi, projektantami procesów biznesowych i architektami.
PODSUMOWANIE
Architektura przyszłości przedsiębiorstwa jest napędzana przez dwa ważne zmiany związane z technologią biznesową: tworzenie oprogramowania w czasie zbliżonym do rzeczywistego i sztuczną inteligencję. W tym rozdziale łączymy pomysły przedstawione w rozdziałach 2 i 3 i wprowadzamy zintegrowane ramy dla tych pomysłów. Wiele przedsiębiorstw stara się zrozumieć wszystkie zmiany technologiczne i eksplozję informacji. Wiedzą, że powinni coś zrobić, ale wciąż starają się objąć to, co to wszystko dla nich znaczy. Wiele z nich ma aktywne programy wykorzystujące metody analityczne do uzyskiwania wglądu w ogromne ilości danych, które zgromadziły z grup "dużych zbiorów danych" w swoich przedsiębiorstwach. Jak większość fal opartych na nowych technologiach, wokół takich grup jest dużo szumu. Wierzymy, że większość takich grup nie spełni swojej obietnicy. W tym rozdziale argumentujemy, że przedsiębiorstwa nie powinny myśleć o dużych zbiorach danych w oderwaniu. Powinni myśleć bardziej całościowo o architekturze na przyszłość i wykorzystywać wszystkie swoje osiągnięcia technologiczne w perspektywie. Zapewniamy ramy koncepcyjne dla takiej architektury. W ten sposób podnosimy obecną rozmowę wokół dużych zbiorów danych i uczenia maszynowego w dwóch kierunkach. Po pierwsze, zachęcamy przedsiębiorstwa do zastanowienia się nad identyfikowalnym uczeniem maszynowym i osadzenia ich w inteligentnych maszynach. Przedsiębiorstwa nie powinny ślepo przyjmować czarnych skrzynek. Po drugie, przedsiębiorstwa powinny zacząć wykorzystywać rozwój oprogramowania w czasie zbliżonym do rzeczywistego. Może to oznaczać, że odejdą od aplikacji pakietowych i opracują lub kupią od podstaw platformy rozwiązań ukierunkowane na proces. Takie ramy umożliwią im szybki dostęp do rynku i elastyczność w dostosowywaniu się do potrzeb rynku.
DODATEK: PODEJŚCIE PIĘCIU KROKÓW DO INTELIGENTNEGO PRZEDSIĘBIORSTWA
Większość przedsiębiorstw znajduje się na różnych etapach między przedsiębiorstwami 2.0 i 4.0 w odniesieniu do większości swoich funkcji biznesowych. Pierwszym krokiem jest oczywiście zdefiniowanie obszarów priorytetowych. Zazwyczaj robi to kierownictwo wyższego szczebla w firmie. Przejście będzie wymagało znacznych zmian w stylu zarządzania i ważne jest, aby uzyskać wsparcie kierownictwa wyższego szczebla w firmie. Następnym krokiem jest utworzenie laboratorium IE dla każdego z obszarów priorytetowych. Zespół IE Lab jest jak zespół SWAT. Musi mieć całą odpowiednią wiedzę specjalistyczną dla danego procesu biznesowego. Przewidujemy, że taki zespół laboratoryjny będzie miał właściciela, ekspertów merytorycznych i modelarzy RAGE AITM. Zespół IE Lab będzie musiał ocenić obecny stan i odwzorować przyszły stan IE oraz plan przejścia. Taki plan może składać się z faz, które doprowadzą funkcję biznesową do stanu IE. Etap realizacji będzie charakteryzował się szybkimi dostawami. Każda dostawa znaczącej jednostki zmiany zwykle nie powinna trwać dłużej niż 15 do 30 dni. Jest to całkowicie możliwe dzięki platformom technologicznym takim jak RAGE AITM. Ostatni krok jest kluczowym etapem monitorowania. Na tym etapie wyniki zmian będą stale monitorowane przez zespół IE Lab.
Aktywne doradztwo z inteligentnymi agentami
WPROWADZENIE
W tej części opisujemy inteligentną maszynę dla rynku doradztwa w zakresie zarządzania majątkiem. Oferowane przez nas rozwiązanie przeniesie tę branżę do Enterprise 4.0. Ta branża jest już świadkiem pierwszych incydentów poważnej transformacji z powodu wielu czynników. Najpierw opisujemy biznesowe i obecne praktyki, a następnie rozwiązanie RAGE AITM, które pomoże przekształcić tę branżę do stanu E4.0. To rozwiązanie jest już stosowane w globalnych firmach zarządzających majątkiem.
RYNEK DORADCZY INWESTYCYJNY
Rynek usług doradztwa inwestycyjnego przechodzi znaczące zmiany wynikające z wielu czynników. Z jednej strony zwiększone wymagania zgodności z przepisami podnoszą koszty prowadzenia działalności i wywierają presję na model biznesowy firm zarządzających aktywami i majątkiem. Z drugiej strony, szybko zmieniające się środowisko technologiczne umożliwia tworzenie nowych, przełomowych modeli biznesowych ("robo-doradców"), które grożą utowarowieniem "doradczego" modelu doradczego praktykowanego przez zarządzających aktywami i majątkiem. Jednocześnie ewolucja teorii finansów pozwala rozpoznać, że istnieje pomost między podejściem ściśle behawioralnym a ramami opartymi wyłącznie na średnich różnicach w zakresie optymalizacji bogactwa jednostki. Optymalne projektowanie portfeli było przedmiotem dużej uwagi i dyskursu w literaturze akademickiej. Ostatnio wykazano, że finanse behawioralne i konwencjonalne ramy wariancji średnich są zbieżne z odpowiednią definicją ryzyka . Kluczową konsekwencją jest uznanie, że musimy skoncentrować się na zachowaniach ludzi na różnych poziomach zamożności w celu opracowania optymalnego projektu portfela. Następstwem tego jest potrzeba optymalizacji wartości netto jednostki w porównaniu z tylko optymalizacją aktywów. Dzięki bezpośredniemu dostępowi do inwestorów w wyniku Internetu i szybkiemu postępowi technologicznemu doradcy robo stali się przełomowym modelem biznesowym na rynku detalicznym rynku zarządzania majątkiem. Ich atrakcyjność jest znacznie niższą opłatą w porównaniu z tradycyjnymi firmami zarządzającymi majątkiem typu houchouch. Doradztwo dla osób o wysokiej wartości netto [HNWI] jest znacznie bardziej złożone w porównaniu do rynku detalicznego. Każdy klient ma specyficzne potrzeby wynikające z szeregu czynników osobistych. Doradcy finansowi dla tych klientów stosują wysoce spersonalizowane usługi w celu zaspokojenia ich potrzeb. Oprócz specyfiki rynku HNWI, doradcy ds. Bogactwa (WA) muszą zrozumieć zupełnie nowe pokolenie, Millennials. Tysiąclecia kontrolują już znaczną część bogactwa, a transfer pokoleń z pokolenia wyżu demograficznego do pokolenia Millennials w Stanach Zjednoczonych jest ogromny. Chociaż nie można zaprzeczyć, że poziom złożoności wzrasta w miarę poruszania się w górę spektrum bogactwa obecny model doradczy wymaga znacznego dotyku i nie wykorzystuje skutecznie technologii. Jest to jeszcze ważniejsze, aby móc sprostać potrzebom pokolenia Milenialsów, którzy są przyjaźni technologicznie. Robo-doradcy pokazują, że obecnie nie ma nawet skutecznego efektu dźwigni technologii dla detalicznych, rzekomo prostych klientów. Liczba WA, które stosują optymalne podejścia do projektowania portfela zalecane w najnowszej literaturze, jest niewielka i daleka. Większość klientów nadal koncentruje się na historycznych wynikach i nie spędza wystarczająco dużo czasu na myśleniu o systematycznym zarządzaniu potrzebami i preferencjami klientów w sposób proaktywny. Wynika to głównie z braku holistycznych ram technologicznych, które umożliwiłyby im odzwierciedlenie zgromadzonej wiedzy i doświadczenia z korzyścią dla klientów. Szybki postęp technologiczny stworzył możliwości zmiany głębokości i zakresu dźwigni technologicznej w świadczeniu usług doradczych. Jak opisano w rozdziałach 2 i 3, przemysł ten może i przejdzie w stan inteligentnego przedsiębiorstwa. W tym rozdziale opisujemy taki inteligentny system i ramy.
CZEGO INWESTORZY NAPRAWDĘ POTRZEBUJĄ I CHCĄ
Wielu doradców i inwestorów postępuje zgodnie ze standardową doktryną tworzenia efektywnego portfela wariancji amean. Jednak nie w pełni oddaje to zachowanie inwestorów. Jak zauważa Statman (2004), służy to wyłącznie korzyściom użytecznym dla inwestora, a nie ich ekspresyjnym lub emocjonalnym korzyściom. Większość inwestorów wykazuje dwie emocje podczas oceny ryzykownych wyborów: strach i nadzieja. Na podstawie tej obserwacji Lopes opracował ramy dla wyborów dokonywanych w warunkach niepewności. Z drugiej strony jest dobrze ugruntowany, że ludzie upraszczają wybory, dzieląc wspólne rozkłady prawdopodobieństwa na różne konta mentalne lub koszyki. Shefrin i Statman łączą strukturę Lopes SP / A (S = bezpieczeństwo, P = potencjał i A = aspiracja) z ramą rachunkowości mentalnej Kahnemanna i Tversky′ego , aby opracować behawioralną teorię portfela (BPT). Uznając, że większość ludzi będzie miała wiele kont mentalnych (lub koszyków) ryzyka i aspiracji, BPT zapewnia ramy do projektowania optymalnych portfeli dla każdego konta mentalnego (poziomu) lub koszyka. Twierdzą, że takie optymalne wybory projektowe mogą nie być ściśle zgodne z portfelem o efektywnej wariancji średniej. Idea, że ludzie myślą inaczej na różnych poziomach zamożności, jest powszechnie obowiązująca. Równie ważne jest to, że ludzie na wszystkich poziomach zamożności mają obawy i aspiracje. Tak więc, z punktu widzenia zarządzania majątkiem, odpowiednie ramy wymagałyby od WA zrozumienia tego, czego inwestorzy naprawdę potrzebują i chcą na różnych poziomach bogactwa dostosowanego do ich obecnego stanu. Chhabra oraz Chhabra i Zaharoff są powszechnie uznawani za tworzenie ram zarządzania zasobami opartymi na celach w oparciu o zintegrowanie zasad finansowania behawioralnego i ram średnich wariancji. W Aspirational Investor Chhabra podaje wyraźny argument za takimi ramami i wyidealizowany przykład ilustrujący ich zastosowanie.
WYZWANIA DOTYCZĄCE WYSOKIEGO DOTYCZĄCA USŁUG DORADCZYCH
Pytania dotyczące wartości i zainteresowania
Podczas kryzysu finansowego w 2008 r. osiągnęliśmy niski poziom zaufania ludzi do branży usług finansowych w ogóle. Branża bankowości prywatnej i zarządzania majątkiem wyraźnie zależy od statusu zaufanego doradcy, aby funkcjonować i prosperować. Kryzys wysunął na pierwszy plan prawdziwe pytania o wartość i konflikty, które zawsze istniały. Gdzie koncentruje się na wynikach klienta? Jaką wartość ma dotknięcie WA przy znacznych opłatach z tym związanych? To stały się kluczowe pytania dla branży. Przed skoncentrowaniem się na opłatach i wartości istniały kwestie konfliktu z funduszami własnymi. Przemysł w dużej mierze zajął się tym, przechodząc do modelu otwartej architektury. Naprawdę istnieje potrzeba, aby WA lepiej rozumieli swoich klientów. Niedawna ankieta PwC (2013) wykazała w tym względzie, że chociaż respondenci ankiety jasno stwierdzili, że wiele aspektów ich relacji z klientami jest skutecznych, kluczowe trendy demograficzne (w tym wzrost znaczenia Pokolenia Y i kobiet jako określonych segmentów klientów), obecnie konieczne jest włączenie do technik segmentacji, zarządzanie zmianami nowej generacji musi ulec poprawie, pomiar rentowności musi stać się bardziej wyrafinowany. Respondenci ocenili się jako wymagający poprawy w niektórych kluczowych obszarach wartości dodanej dla klientów, zwłaszcza w zakresie raportowania dla klientów, ofert cyfrowych i świadczenia szeroko zakrojonych porad. Przemysł musi stać się mądrzejszy w zrozumieniu, co klienci naprawdę cenią, a tym samym, ile zapłacą za wartość dodaną. Jednak badanie pokazuje również, że prywatni klienci, do których włączono badanie, byli obecnie niezadowoleni z tego, jak komunikowali się z nimi ich zarządcy majątkowi. WA, w tym zarejestrowani niezależni doradcy [RIA], stają przed prawdziwym wyzwaniem, jeśli chodzi o odpowiedź na pytanie o wartość w stosunku do opłaty. Z kolei firmy z pełnym zakresem usług stoją przed poważnym wyzwaniem, jakim jest wsparcie kosztów modelu o wysokim poziomie dotyku. Stawiają czoła znacznej presji na marże. Nacisk kładziony jest teraz na rozwiązania i odchodzenie od postrzeganych produktów utowarowionych. Przemysłowy łańcuch wartości ewoluuje wraz z większą specjalizacją i koncentruje się na kluczowych determinantach sukcesu.
Ogromne zjawisko "przenoszenia majątku"
Każde pokolenie zmieniło swoje ogólne nastawienie i wartości, na które duży wpływ miały główne wydarzenia, których było świadkiem. W samych Stanach Zjednoczonych jest około 80 milionów pokolenia Milenialsów urodzonych między 1980 a 2000 rokiem, a najstarsi w tym pokoleniu wkraczają w wiek 30 lat. Poglądy i postawy tego pokolenia zostały ukształtowane przez szybką globalizację oraz wszechobecny wpływ i postęp technologii na wszystkie aspekty życia. Tysiąclecia kontrolują już około 2 bilionów dolarów w płynnych aktywach, a oczekuje się, że do końca dekady wzrośnie do 7 bilionów dolarów. Szacuje się, że w ciągu kilku następnych dziesięcioleci aktywa o wartości 30 bilionów dolarów zostaną przeniesione z wyżu demograficznego do ich spadkobierców w samych Stanach Zjednoczonych. Szacuje się, że przeniesienie osiągnie szczyt między 2031 a 2045 rokiem, kiedy 10% całkowitego bogactwa w Stanach Zjednoczonych będzie zmieniało właściciela co pięć lat (Accenture, 2012, 2013). Powszechnie donosi się, że milenialsi są bardzo nieufni wobec rynków finansowych, uważają społeczną odpowiedzialność za najważniejszy czynnik w inwestycjach, wierzcie w ich zdolności do zmiany świata, a większość z nich deklaruje się jako inwestorzy "samokierujący". Wierzą, że "robią dobrze, robiąc dobrze". WA nie mogą oczekiwać, że Tysiąclecia po prostu zgodzą się z poglądem swoich rodziców na świat i zasady inwestowania. WA muszą być zsynchronizowane z zupełnie innym spojrzeniem i podejściem swoich klientów do bogactwa.
Powstanie Robo-Advisors
Od 2009 r. ponad 200 firm włączyło się w działalność polegającą na pomaganiu inwestorom w zarządzaniu portfelem zarządzania aktywami online. Obejmują one zarówno start-upy wspierane kapitałem wysokiego ryzyka, jak i uznane firmy, takie jak Fidelity Investments, Vanguard Group i Charles Schwab. Firmy te próbują zakłócić tradycyjny rynek zarządzania majątkiem za pomocą automatyzacji wyboru portfela i niskich lub nawet żadnych opłat za swoje usługi. Inwestorzy mogą wybierać spośród gotowych portfeli lub budować własne portfele za pomocą łatwych w użyciu narzędzi. Niektóre firmy, w tym SigFig Wealth Management i FutureAdvisor, oferują bezpłatną analizę istniejących inwestycji inwestora i zalecam sposoby zmiany portfeli, aby osiągnąć optymalną kombinację papierów wartościowych. Za roczną opłatą w wysokości odpowiednio 0,25% i 0,5% SigFig i FutureAdvisor będą również zarządzać tymi aktywami. Opierając się na jakościowym zrozumieniu online profilu ryzyka inwestora z kwestionariusza, automatycznie zalecają alokację aktywów ze stosunkowo statycznego zestawu opcji w dużej mierze opartych na inwestowaniu opartym na indeksie i giełdowych funduszach inwestycyjnych (ETF). Jeśli firmy o ustalonej pozycji martwią się o te zwinne, destrukcyjne przedsięwzięcia modele? Jak powinny konkurować z takimi firmami? Na odwrocie po stronie, co te nowe firmy muszą zrobić, aby skutecznie obsługiwać segmenty o wyższym poziomie zamożności? Nic dziwnego, że ścieżki dla obu są podobne. Ustanowione firmy muszą wdrożyć znacznie bardziej elastyczną technologię, jeśli chcą konkurować z tymi nowymi firmami. Robo-doradcy muszą zrobić to samo, aby móc wejść na rynek i obsługiwać segmenty zamożności wyższego poziomu.
Technologia dla wyjątkowych potrzeb HNWI
Tradycyjna wiedza głosi, że rynek HNWI jest złożony, a każdy klient ma swoje unikalne i specyficzne potrzeby, a zatem wymaga usług houchouch. Chociaż z pewnością nie może być obsługiwany przez zautomatyzowane usługi "jeden rozmiar dla wszystkich", prawdą jest również to, że wiele WA nie wykorzystuje wszystkich dostępnych technologii, aby oferować swoje usługi w spójny i systematyczny sposób klientom HNWI. Niezależnie od jakichkolwiek konkurencyjnych potrzeb ze strony doradców robo, firmy o ugruntowanej pozycji mają szansę na zastosowanie elastycznej technologii, która może im pomóc HNWI potrzebuje znacznie bardziej efektywnie. Mogą używać technologii do szybkiego konfigurowania potrzeb HNWI na bardzo szczegółowym poziomie, nawet na poziomie członka rodziny, bez kosztu ręki i nogi. Powinni być w stanie odzwierciedlić różnorodne aspiracje i wartości swoich klientów, w tym pokolenia Millenialsów. Przyjęcie technologii nowej generacji pozwoli WA wykazać, w jaki sposób mogą wnieść wartość dodaną do swoich klientów HNWI. Obecnie wielu WA po prostu nie ma stałego wglądu w stan wartości netto klienta i tego, co może na nią wpłynąć. Mają głównie statyczne poglądy i generują obszerne raporty z historycznych wyników portfeli inwestycyjnych ich klientów, które mają ograniczoną lub zerową wartość. Powinny być w stanie systematycznie monitorować środowisko zewnętrzne i proaktywnie mapować zmiany w otoczeniu z potrzebami klientów. Dzisiaj jest to w dużej mierze epizodyczna aktywność napędzana pamięcią WA i umiejętnością łączenia kropek.
AKTYWNE DORADZTWO - RAMY OPARTE NA INTELIGENCJI MASZYNY
Przemysł ten jest gotowy na poważną transformację w wyniku zarówno postępu technologicznego, jak i innych czynników wyjaśnionych powyżej. Obecny stan tej branży scharakteryzowalibyśmy gdzieś pomiędzy E2.0 a E3.0. Wiele największych firm zarządzających majątkiem nie gromadzi nawet zasobów pochodzących od wielu powierników, ma ograniczoną lub nie ma elastyczności w zaspokajaniu potrzeb swoich klientów, a społeczność doradców musi pracować poza systemem, aby wdrożyć swoje pomysły o wartości dodanej. Przeniesienie tej branży do E4.0 jest całkiem wykonalne i nieuniknione. Doradztwo w zakresie zdrowia jest klasycznym procesem opartym na wiedzy, który można wspierać za pomocą inteligentnych maszyn. Różne aspekty tego procesu wymagają różnego rodzaju inteligentnych maszyn. Opisujemy LiveWealthTM, inteligentny system oparty na RAGE AITM, który może nieinwazyjnie przenieść dowolną firmę zarządzającą majątkiem lub doradcę na E4.0. Branża zarządzania majątkiem obsługuje klientów w szerokim zakresie spektrum bogactwa o różnych potrzebach i pragnieniach. Branża jest ogólnie podzielona na następujące segmenty: detaliczny, o wysokiej wartości netto i klienci instytucjonalni. Segment o wysokiej wartości netto można dalej podzielić na segmenty o wysokiej wartości netto i ultra wysokiej wartości netto. W przypadku segmentu detalicznego, jak wykazali doradcy robo, działania związane z zarządzaniem majątkiem mogą być wysoce zautomatyzowane i wymagają bardzo niewielkiego lub żadnego kontaktu z człowiekiem. Jednak doradcy Robo generalnie stworzyli bardzo specyficzne i ograniczone systemy, które odzwierciedlają bardzo deterministyczny pogląd czego chcą i potrzebują inwestorzy indywidualni. Są w wersji 3.0. Wykazują niewielką lub żadną elastyczność, bardzo specyficzne, ograniczone opcje, a na pewno brak poziomu inteligencji maszyny. Dzięki LiveWealthTM firmy zarządzające majątkiem mogą określić poziom automatyzacji, który jest najbardziej odpowiedni dla klienta i nie muszą arbitralnie ograniczać możliwości wyboru. Aby wykazać prawdziwą wartość, muszą zostać "aktywnymi doradcami". Muszą być stale świadomi tego, co cenią i dbają ich klienci, stale monitorować zmiany w otoczeniu zewnętrznym, które mogą wpływać na bogactwo klienta, oraz zmiany w środowisku osobistym klienta, które mogą wpływać na preferencje i cele klienta. Muszą przyjmować "aktywny" pogląd na doradztwo, a nie pogląd statyczny, okresowy lub epizodyczny. Wiele udanych WA próbuje być "aktywnych" poprzez zwykły wysiłek. Starają się być na bieżąco z wszystkimi wydarzeniami, które ich zdaniem mogą mieć wpływ na ich klientów. Biorąc pod uwagę ilość informacji i czynniki, które mogą mieć wpływ na pozycję majątkową klienta, prawdopodobnie nie będą one stale odnosić sukcesów. Poza tym jest to bardzo obciążający i niezrównoważony model. LW zmienia każdego doradcę w aktywnego doradcę. Platforma RAGE AITM została wykorzystana do stworzenia inteligentnych agentów, którzy mogą funkcjonować na żądanie WA. Monitorują zarówno ustrukturyzowane, jak i nieustrukturyzowane dane za pomocą logiki WA, w razie potrzeby i informują WA zgodnie z życzeniem. Struktura inteligentnych agentów obejmuje szeroki zestaw inteligentnych agentów, które można wysoce konfigurować. Można je skonfigurować dla każdego klienta lub członka rodziny klienta. Można je również skonfigurować tak, aby odzwierciedlały wiedzę specjalistyczną WAWA w zakresie analizy danych dotyczących wydajności i innych zmian. Te inteligentne agenty to zautomatyzowane roboty, które stale monitorują środowiska zewnętrzne i wewnętrzne. Zwracają uwagę WA na trendy i zmiany, które wymagają działania. Opiszemy tutaj kilka z tych agentów.
HOLISTYCZNE SPOJRZENIE NA POTRZEBY KLIENTA
Najważniejsze dla LW jest całościowe zrozumienie potrzeb klienta. Można tego dokonać poprzez odpowiedni zestaw pytań i kategoryzację sytuacji klienta i celów majątkowych. LW pozwala na ustalenie tylu kategorii celów i dla tylu członków rodziny, ile potrzeba. Oto przykładowy bilans gospodarstwa domowego uporządkowany według celów w trzech segmentach - Potrzeby, życzenia i życzenia. Potrzeby odzwierciedlają podstawowe koszty utrzymania klienta i powinny być odpowiednio inwestowane. Zwróć uwagę na dopasowanie aktywów i pasywów na każdym poziomie celu. Pragnienia to kolejny poziom dążenia do bogactwa, a wreszcie życzenia są aspiracyjnymi celami klienta. LW pozwala WA ocenić tolerancję ryzyka klienta na podstawie szeregu pytań. Te pytania można skonfigurować dla każdego klienta, aby odzwierciedlić jego unikalną sytuację. Jak wspomniano wcześniej, LW umożliwia WA ustawienie dowolnej liczby poziomów celów dla klienta. W razie potrzeby WA może nawet ustawić osobne poziomy dla różnych członków gospodarstwa domowego klienta. Agent oceny i monitorowania celów (ryc. 5.3, 5.4) stale weryfikuje i sprawdza cele klienta, rzeczywistą wydajność i potencjalne luki. Gdy cele są początkowo ustalane, agent dokonuje szybkiej oceny ich wykonalności. Po instalacji monitoruje je w sposób ciągły. Jeśli wykryje, że rzeczywista wydajność odbiega lub może odbiegać od celu dla któregokolwiek z celów, może również określić możliwe działania do wypełnienia przerw. Takie działania mogą obejmować sugerowanie przejścia na wyższą wydajność, dodatkowe wkłady i tym podobne. Wbudowane symulatory w LW pozwalają także WA symulować nieoczekiwane szoki i zdarzenia w środowisku klienta. Dzięki temu WA może zrozumieć wpływ takich wstrząsów i odpowiednio je zaplanować. WA jest powiadamiany za pośrednictwem pulpitu nawigacyjnego Active Advising. WA może zaakceptować i zatwierdzić zalecane działania lub je zastąpić i zdefiniować zmienione działania w celu wypełnienia luki między bieżącą pozycją klienta a jego celami. Agent agregujący automatycznie agreguje wszystkie aktywa i pasywa klienta z jednego lub więcej źródeł. Jest to oczywiście bardziej cenne w przypadku klientów, którzy mają wiele kont w różnych firmach - powiernikach, domach maklerskich i tym podobnych. Historycznie rzecz biorąc, większość doradców nawet w wielu największych firmach nie dysponowała technologią łatwego agregowania wszystkich danych z tych wielu kont na poziomie transakcji. Załóżmy, że masz relacje doradcze z JP Morgan Chase, konto maklerskie w Fidelity, a twoje 401 tys. Z Charlesem Schwabem, twój doradca w JP Morgan Chase musi zsumować wszystkie twoje aktywa (i pasywa) przed opracowaniem odpowiedniego planu finansowego . Obecnie nie ma łatwego sposobu, aby ten doradca automatycznie zgromadził wszystkie te informacje. W branży nie ma norm ani znormalizowanego procesu udostępniania informacji. Wielu doradców robi to ręcznie w arkuszach kalkulacyjnych na podstawie wyciągów papierowych lub dokumentów PDF, które otrzymują od swoich klientów. Niektóre z tych stwierdzeń mogą zawierać setki stron. Możesz sobie wyobrazić, jak niechlujny i podatny na błędy musi być ten proces!
Agent agregacji rozwiązuje to wyzwanie. Niezależnie od formatu i rodzaju dokumentu agent agregujący wyodrębnia odpowiednie informacje ze 100% dokładnością i 100% ścieżką audytu. Komponenty RAGE AITM inteligentnie rozpoznają wyciąg powierniczy, maklerski, finansowy lub bankowy. Automatycznie wyodrębniają dane i normalizują je w zestawieniach. Komponent języka naturalnego platformy kategoryzuje i interpretuje wyodrębnione dane - na przykład etykiety transakcji, dzięki czemu są one interpretowane zidentyfikować papier wartościowy, jego cechy charakterystyczne i inne atrybuty, takie jak kupon (na zabezpieczenie o stałym dochodzie), datę wymagalności i klasę aktywów. Agregacja jest interesującym przykładem automatyzacji opartej na wiedzy i obejmuje zarówno ekstrakcję, jak i przetwarzanie języka naturalnego. Jest to również przykład, w którym czarna skrzynka nie będzie działać z powodu wymogu kontroli. Ze względu na delikatny charakter problemu, a także wymogi prawne dotyczące obsługi faktur, na przykład wszystkie zagregowane dane i ich kategoryzacja muszą mieć pełne wsparcie. Agent równoważący monitoruje w sposób ciągły wartości portfela względem docelowej alokacji i, w oparciu o progi ustalone przez WA, określa, czy działanie równoważące może być terminowe. Agent określa również zestaw działań niezbędnych do przywrócenia równowagi. Ponadto, jeśli theWA zapewnia odpowiednie parametry, agent równoważący może również zidentyfikować zestaw rekomendacji, które są najbardziej odpowiednie dla klienta. Może to uwzględniać bieżące wyniki funduszy lub zmiany w jakichkolwiek okolicznościach klienta, w tym wszelkie zmiany celów i zobowiązań, a następnie stosuje określone reguły WA w celu ustalenia zaleceń dotyczących działań przywracających równowagę. Rysunek 5.5 pokazuje częściowy widok środka równoważącego. Jest to proces na żywo, a nie tylko schemat blokowy. WA może skonfigurować agenta równoważącego dla każdego klienta, a nawet w obrębie każdego klienta na bardziej szczegółowych poziomach. Rysunek 5.6 pokazuje przykładowy proces równoważenia na żywo zaimplementowany dla konkretnego klienta. Agent monitorujący cele w szczególności monitoruje trafność celów klienta oraz to, jak dobrze rzeczywiste pozycje klienta, zarówno aktywa, jak i pasywa, śledzą plan ustalony przez WA. Może uwzględniać takie scenariusze, jak możliwa zmiana stóp procentowych w przyszłości lub zmiana wartości nieruchomości, oprócz faktycznych wartości portfeli aktywów zbywalnych. Rysunek 5.7 pokazuje wyniki agenta monitorowania celów dla przykładowego klienta w danym momencie. Wykresy kołowe na rycinie 5.7 wskazują bieżącą wykonalność celu. Jeśli tak skonfigurowano, agent może automatycznie poprosić o aktualizację online osobistych okoliczności klienta, na których polegała usługa WAWA w celu stworzenia strategii maksymalizacji bogactwa. Większość WA na rynku HNWI woli robić to osobiście ze swoim klientem. Agent monitorowania celów może jednak pozwolić im przygotować się na spotkanie z klientem dzięki inteligentnemu budowaniu scenariuszy "Co-jeśli". Agent planowania podatkowego może wdrożyć strategie planowania podatkowego, w tym ewentualną logikę odzyskiwania strat podatkowych WA. WA może potencjalnie skonfigurować reguły / logikę odzyskiwania strat podatkowych specyficzne dla klienta. Agent planowania podatkowego może posunąć się daleko poza zwykłym odzyskiwaniem podatków i wdrażaniem złożonych technik efektywnego zarządzania podatkami. Agent optymalizacji pasywów może monitorować zobowiązania klienta, środowisko zewnętrzne i uruchamiać możliwości optymalizacji. Jest to szczególnie odpowiednie w przypadku wieloliniowej instytucji finansowej. Agent wykrywania portfela monitoruje środowisko zewnętrzne pod kątem zmian, które mogą mieć wpływ na portfolio klienta. Dzisiaj, WAWA nie mają systematycznego sposobu monitorowania wielu zdarzeń zewnętrznych, które mogą mieć wpływ na bogactwo klienta lub zdarzenia, na które dbają jego klienci. Ilość informacji cyfrowych, którymi dysponujemy, jest tak duża, że po ludzku niemożliwe jest, abyśmy byli na szczycie. Rycina 5.9 pokazuje mapę cieplną do WA Agent wykrywający rozwiązuje ten problem przeciążenia informacji za pomocą metod uczenia maszynowego i przetwarzania języka naturalnego w celu przetworzenia miliardów zdarzeń zewnętrznych na podstawie zestawu odpowiednich czynników dla każdego klienta w celu zidentyfikowania zdarzeń, które powinny być interesujące . WA może skonfigurować taką listę czynników, którą nazywamy ontologią semantyczną. Detektor może szybko wykryć wpływ rozwijających się wydarzeń, takich jak wiadomości, które niosą oświadczenie gubernatora Portoryko, że państwo nie może sobie pozwolić na zadłużenie. Może zidentyfikować wszystkich klientów, którzy posiadają obligacje komunalne w Puerto Rico, i obliczyć wielkość ekspozycji różnych klientów na obligacje w Puerto Rico, a także na jakie cele klientów może mieć wpływ wielkość środków wykrywający aktualizacje mapy cieplnej dla każdego klienta (lub bardziej szczegółowych jednostek). Dzięki temu WA mogą być bardziej proaktywni w zarządzaniu majątkiem swojego klienta.
PODSUMOWANIE
Rynek zarządzania majątkiem o wartości ponad 30 bilionów dolarów przeżywa znaczący wzrost zmiany wynikające z poważnych zmian makroekonomicznych na świecie, zmiany demograficzne w odniesieniu do transferu bogactwa do nowej generacji oraz zestaw zmian regulacyjnych wpływających na przemysł. Jednocześnie technologia ewoluowała i stworzyła możliwości radykalnej transformacji modeli biznesowych w branży. Modele doradcze z funkcją szybkiego dotyku można znacznie przekształcić, aby zmniejszyć poziom dotyku i zapewnić klientom wysoką wartość. Technologia może inteligentnie automatyzować rutynowe zadania w bardzo elastyczny sposób i może pomóc zarządcy majątku być bardziej proaktywnym nawet w zadaniach opartych na wiedzy. Ogólnie rzecz biorąc, pozwoli to WA zostać "aktywnym doradcą". Opisaliśmy inteligentny system, który może przenosić firmy zarządzające majątkiem i doradców w E4.0. System ma inteligencję do inteligentnego wdrażania polityk i strategii opracowanych przez WA. Może także automatycznie uzyskiwać dostęp do faktów dotyczących konkretnej dziedziny, od oświadczeń depozytariuszy po wyczucie, jakie zmiany w środowisku zewnętrznym mogą wpłynąć na klientów.
DODATEK: AUTOMATYZACJA PROCESU BIZNESU RAGE I PLATFORMA INTELIGENCJI KOŃCOWEJ
Platforma RAGE Enterprise Platform, oparta na 20 abstrakcyjnych silnikach, umożliwia szybkie tworzenie rozwiązań dla przedsiębiorstw w ciągu kilku godzin i dni (rysunek 5A.1). Platforma ma unikalną architekturę opartą na modelu, która sprowadza tworzenie oprogramowania do ćwiczenia modelowania. Korzystając z platformy RAGE, stworzyliśmy platformę Intelligent Agent, aby umożliwić aktywne doradztwo Rysunek 5A.2). Agenty to inteligentne procesy automatyzacji, które można tworzyć na żądanie na dowolnym poziomie szczegółowości, jakiego pragnie WA - klient, portfolio i tak dalej. Mogą obsługiwać dane strukturalne, takie jak zwroty wydajności, lub dane nieustrukturyzowane, takie jak wiadomości
WPROWADZENIE
Aktywni menedżerowie (fundusze wspólnego inwestowania, fundusze hedgingowe) stale szukają nieefektywności na rynkach. Jak znajdują takie nieefektywności? Korzystają z różnych strategii i czynników, aby budować swoje portfele. Wszystkie takie strategie i czynniki opierają się na zrozumieniu i wglądu ich personelu badawczego z wykorzystaniem informacji, które są w stanie przetwarzać. Skuteczność strategii aktywnego zarządzania wyraźnie zależy od umiejętności menedżera i personelu badawczego. Konwencjonalna wiedza oparta na kwartalnych kartach wyników Standard and Poor's Index versus Active (SPIVA) było to, że tylko niewielka liczba aktywnie zarządzanych funduszy wspólnego inwestowania osiągnęła lepsze wyniki niż wskaźnik referencyjny SPIVA. Ostatnie badania pokazują jednak, że aktywnie zarządzane fundusze przewyższają standardy, jeśli przyjrzymy się bliżej aktywnej części tych portfeli. Sugeruje to wyraźną wartość informacyjną. Arecent historyczne badanie inwestowania aktywnego i pasywnego
wskazuje, że aktywne zarządzanie zwykle osiągało lepsze wyniki niż zarządzanie pasywne podczas korekt rynkowych. Badanie dowodzi, że aktywne i pasywne zarządzanie zmieniało się cyklicznie. W niektórych cyklach o wysokim poziomie dyspersji i zmienności, aktywni menedżerowie zwykle przewyższają menedżerów pasywnych. W okresach o niskim poziomie dyspersji odwrotnie. Uważamy jednak, że dzisiejszy aktywny menedżer jest utrudniony z powodu niemożności przetworzenia gwałtownej ilości informacji, które stale docierają na rynek. Badania te nie są w stanie wyjaśnić, czy istnieje prawdziwa nieefektywność informacyjna na rynku, którą aktywni menedżerowie są w stanie wykorzystać. W dzisiejszym cyfrowym świecie uważamy, że skuteczność każdej aktywnej strategii inwestycyjnej zależy w decydujący sposób od możliwości przetworzenia ogromnej ilości informacji, które stale docierają cyfrowo. Uważamy, że tempo napływu nowych informacji znacznie przewyższa możliwości zarządzających inwestycjami oraz ich personel do
przetwarzania takich informacji. Ignorowanie jakiejkolwiek różnicy między aktywnymi menedżerami w interpretowaniu informacji, jest trochę trafieniem lub brakiem, jeśli chodzi o to, że menedżerowie przeglądają wszystkie istotne informacje na czas. Czasami mogą przejrzeć większość istotnych informacji, a innym razem nie. Naszym zdaniem nawet najbardziej systematyczni aktywni menedżerowie i fundusze hedgingowe walczą o przetworzenie wszystkich informacji, które napłyną na ich drodze. Charakteryzowalibyśmy aktywną branżę inwestycyjną między E2.0 a E3.0. W tym rozdziale opisano sposób przejścia do stanu inteligentnego.
ASYMETRIA INFORMACJI I RYNKI FINANSOWE
Wcześniej opisaliśmy różne rodzaje asymetrii informacji, które powodują transakcje handlowe. W kontekście rynków finansowych Fama definiuje efektywny rynek jako rynek, na którym wartości aktywów zawsze w pełni odzwierciedlają wszystkie dostępne informacje, hipoteza efektywnego rynku (EMH). Założeniem leżącym u podstaw EMH jest to, że gdy na rynku pojawiają się nowe informacje dotyczące podstawowej wartości składnika aktywów, jego cena powinna natychmiast reagować, co oznacza, że nowe informacje powinny natychmiast i idealnie się rozproszyć. Oczywiście lepszy lub różnicowy dostęp do informacji może przynieść lepsze zwroty. Istnieje również znaczna literatura na temat wpływu nastrojów inwestorów na ceny aktywów. DeBondt i Thaler tworzą portfele najlepiej i najgorzej działających firm w ciągu ostatnich trzech lat i obliczają odpowiadające im zwroty w ciągu następnych pięciu lat i stwierdzają, że o ile trendy długoterminowe ulegają odwróceniu, trendy krótkoterminowe są kontynuowane. Wiele badań donosiło o podobnych ustaleniach, twierdząc, że na rynkach finansowych występuje niedostateczna i nadmierna reakcja. Badania te racjonalnie zracjonalizowały brak reakcji z powolnym rozpowszechnianiem wiadomości, konserwatyzmem, skłonnością do zbyt wczesnego sprzedawania zwycięzców i zbyt długo trzymania przegranych. Podobnie, nadmierna reakcja jest argumentowana z powodu pozytywnego obrotu zwrotnego, nadmiernej pewności inwestorów, reprezentatywnej heurystyki oraz zachowań pasterskich. Miller twierdzi, że nie można zakładać, że chociaż przyszłość jest bardzo niepewna, a prognozy najprawdopodobniej zostaną pominięte, że w jakiś sposób wszyscy dokonują identycznych szacunków zwrotu i ryzyka z każdego zabezpieczenia. W praktyce sama koncepcja niepewności oznacza, że rozsądni ludzie mogą różnić się w swoich prognozach. W literaturze istnieją obecnie poważne wątpliwości, czy EMH zawsze może przetrwać w realnym świecie, ponieważ sentyment inwestorów w obliczu ograniczonego arbitrażu może utrzymywać się w długich horyzontach czasowych. Stambaugh stwierdza, że obserwowanie i prognozowanie zmian nastrojów przynosi efekty na rynkach finansowych, ponieważ arbitrzy śledzą trendy cenowe, wolumeny handlowe, wskaźniki zmienności, badania inwestorów i inne wskaźniki odzwierciedlające zmiany nastrojów. Niektórzy twierdzą zatem, że wpływ nastrojów na ceny aktywów jest niepodważalnym faktem życiowym, a jedyną kwestią jest to, jak je zmierzyć. W obszernym badaniu literatury na ten temat Bank i Brustbauer zauważają, że obecne badania nie rzucają żadnego światła na czynniki wpływające na indywidualną ocenę cech aktywów przez inwestorów. Sugerują, że przyszłe badania powinny koncentrować się na możliwych objawach nastrojów inwestorów, które czynią inwestorów podatnymi na sentyment. Uważamy, że istnieje ważny wymiar związany z rozpowszechnianiem informacji i sentymentem inwestorów, który nie przyciągnął zbyt wiele uwagi w literaturze. W tym rozdziale koncentrujemy się na tym, jak systematycznie interpretować informacje, gdy tylko się pojawią, i określić ich możliwy wpływ na ceny aktywów. W tym cyfrowym świecie, w którym szybkość i ilość dostarczanych informacji jest gwałtownie wysoka, uważamy, że niemożliwe jest natychmiastowe rozproszenie wszystkich informacji na rynku. Badamy możliwą hipotezę, że jeśli uda nam się uzyskać lepszy dostęp do wszystkich informacji i interpretując takie informacje bez uprzedzeń osobowości (lub stałego i niezmiennego nastawienia sentymentalnego), będziemy w stanie zmierzyć rozpowszechnianie informacji i jej wpływ na ceny aktywów. Przeprowadzono kilka badań dotyczących tempa rozpowszechniania informacji i wpływu rozpowszechniania informacji na ceny zabezpieczeń. Większość z tych badań analizowała zwroty z różnych rodzajów zdarzeń lub wokół nich, takie jak ogłoszenia o zarobkach. Kilka teorii usiłowało wyjaśnić obserwację empiryczną, że ceny akcji zwykle zmieniają się w czasie w tym samym kierunku, co początkowe nowe informacje. Zasadniczo badacze zbadali taki dryft w kontekście ogłoszeń o zarobkach i jest on określany jako dryf po ogłoszeniu zarobków (PEAD). Zasugerowano trzy wyjaśnienia takiego przesunięcia: (1) może to być premia za ryzyko, (2) może wynikać z wysokich kosztów transakcji i / lub (3) może być funkcją otrzymywanych przez agentów informacji. Trzecie wyjaśnienie jest najbardziej odpowiednie dla naszej dyskusji.
Istnieją dwie konkurujące ze sobą teorie, które próbują wyjaśnić argument informacji różnicowej. Z jednej strony teoria "behawioralna" sugeruje, że dryf wynika z różnicy między informacjami publicznymi i prywatnymi. Z drugiej strony teoria "racjonalnej niepewności strukturalnej" dowodzi, że liczy się rozkład informacji w gospodarce. Aby wyjaśnić PEAD, Vega (2006) sprawdza, która z tych dwóch teorii najlepiej opisuje dane empiryczne, wykorzystując zmienne, które rozróżniają informacje publiczne od prywatnych oraz wskaźnik napływu poinformowanych / niedoinformowanych handlowców. Vega konkluduje, że na dryf nie mają wpływu informacje publiczne ani prywatne. Liczy się raczej to, czy informacje są skoncentrowane. Vega mierzy niespodzianki w zakresie informacji publicznej (SUR) jako kombinację liczby przypadków, w których firma jest wymieniana w mediach bezpośrednio przed wydarzeniem, a codzienne nienormalne zwroty akcji:
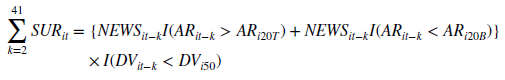
gdzie NEWSit-k jest zmienną fikcyjną równą jeden, jeśli firma i jest wymieniona w nagłówku lub wiodącym akapicie artykułu w dniu ti I (ARit-k > ARi20T) i I (ARit-k < ARj20B) są funkcjami wskaźnika równymi do jednego, jeżeli nienormalny zwrot akcji dla firmy i w dniu t lub dniu t + 1 jest odpowiednio powyżej górnej 20% i poniżej dolnej 20%, odpowiednio, dziennych nienormalnych zwrotów akcji dla tej firmy. I (DVit-k < DVi50) jest funkcją wskaźnika równą jedności, jeśli obniżony obrót dla firmy i w dniu t - k lub t - k + 1 jest niższy niż średni średni obrót dla firmy i. Badanie znajduje również poparcie dla argumentu, że informacje publiczne mogą czasami nie być łatwo interpretowalne, a poinformowani handlowcy, którzy są szczególnie umiejętni w analizowaniu takich wiadomości, mogą skorzystać z ich interpretacji. Chan stwierdza, że firmy objęte mediami doświadczają większego dryfu, a firmy, które doświadczają skoków cen akcji bez zauważalnych wiadomości publicznych, zwracają odwrócenie.
INTELIGENCJA MASZYNY I ALFA
Uważamy, że maszyny mogą być wykorzystywane do systematycznego przetwarzania ogromnej ilości informacji dostępnych dziś. Aktywni menedżerowie mogą nawet dostosować takie maszyny, aby odzwierciedlały ich preferencje i przekonania w razie potrzeby. Maszyny mogą stać się aktywnymi asystentami menedżerów lub być obsługiwane bez udziału człowieka. Jak argumentowaliśmy przez cały czas, takie uczenie maszynowe i inteligencja wcale nie muszą być czarną skrzynką. Zacznijmy od konceptualnego modelu wpływu informacji na wewnętrzną wartość firmy. Stawiamy następującą hipotezę: na firmę wpływają nie tylko związane z nią wiadomości, ale wszelkie zdarzenia lub informacje, które mogą wpłynąć na jej działalność lub model biznesowy. Może to być na przykład wprowadzenie nowego produktu przez konkurenta lub rozwój makroekonomiczny, który napędza popyt na produkty firmy. W rzeczywistości liczba sposobów oddziaływania na firmę jest duża i złożona i wymaga szeroko zakrojonego monitorowania / interpretacji wszechświata informacyjnego. Możemy pomyśleć o bliskości takich informacji do firmy na kilku poziomach hierarchicznych. Element informacyjny pierwszego rzędu to taki, który zawiera nazwę firmy, dzięki czemu można go zidentyfikować bezpośrednio z firmą. Przedmiot drugiego rzędu to taki, który ma jeden stopień oddzielenia od firmy. Przykładem tego jest pozycja informacyjna na temat branży, w której działa firma. Pozycja drugiego rzędu ma dwa stopnie separacji i tak dalej. Cokolwiek przekraczającego dwa stopnie separacji jest prawdopodobnie nieco zbyt odległe, aby można je było natychmiast rozważyć. Jeśli stanie się istotny, uważamy, że pojawi się ponownie w ciągu dwóch stopni separacji. Pozwolę sobie przedstawić zbiór informacji, który może wpłynąć na działalność firmy O, która z kolei jest interpretowana przez inwestorów i odzwierciedlana w cenie P akcji spółki:
I → O → P
O jest zbiorem czynników opisujących model operacyjny firmy w oparciu o działalność i branżę firmy (przykład znajduje się w załączniku na końcu tego rozdziału). Poziom asymetrii informacji i stopień rozpowszechnienia informacji o cenie akcji można zmierzyć poprzez systematyczną identyfikację I i ocenę jej wpływu na P poprzez skalibrowanie jej wpływu na O. W rzeczywistości uważamy, że to właśnie podejmują świadomi inwestorzy. Poinformowani inwestorzy używają złożonego modelu informacji, który musi przypominać O. Istnieją praktyczne wyzwania dotyczące skuteczności, z jaką dzieje się to nawet w przypadku świadomych handlowców. Przy braku systematycznego sposobu agregowania, sortowania i oceny pełnego zestawu informacji I i bez pełnego wyliczenia modelu operacyjnego O wskaźnik powodzenia poinformowanych handlowców jest ogólnie niski. Uznajemy, że kompletność powyższego modelu jest funkcją tego, jak kompletne są publiczne informacje o firmie, jak szeroki jest nasz dostęp do tych informacji publicznych oraz kompletność O. Ignorujemy prywatne informacje oparte na Chan (2003), oraz ignorujemy również emocje. Opracowaliśmy system powyższego modelu w oparciu o RAGE AITM i systematycznie oceniamy wpływ odpowiedniego I na O odpowiedniej firmy. System opiera się na technologiach językowych w celu automatycznej interpretacji informacji, określenia jej znaczenia dla jednej lub więcej firm " O i oceń wpływ informacji na podstawie zwrotów zawartych w informacjach. Oceny dokonuje się za pomocą heurystycznej skali oceny. Przeanalizowaliśmy związek między tym wynikiem wpływu, który jest szeregiem czasowym, a szeregiem cen, aby ustalić, czy wpływ prowadzi do zmian cen. Taki pomiar można zdefiniować jako miarę asymetrii informacji i przybliża szybkość rozpowszechniania informacji dla tej firmy. Następnie opisujemy inteligentny system, aw kolejnych sekcjach wyniki zastosowania systemu na dużym zbiorze informacji. Nasz system agreguje, klasyfikuje i interpretuje duże ilości informacji z bardzo dużej liczby źródeł globalnych, regionalnych i lokalnych w celu generowania potencjalnych sygnałów alfa dla poszczególnych firm. System wykorzystuje platformę RAGE AITM opisaną w rozdziale 3. W szczególności system zawiera następujące kluczowe elementy:
• Modele operacyjne specyficzne dla firmy (O), które obejmują sieć czynników, które mogą mieć wpływ na wewnętrzną wartość firmy.
• Kategoryzator RAGE AITM, aby podzielić informacje na jeden lub więcej tematów i określić ich znaczenie dla firmy poprzez zbadanie odpowiedniego modelu operacyjnego firmy.
• Analizator wpływu RAGE AITM w celu oceny potencjalnego wpływu informacji na firmę poprzez analizę zbiorczego wpływu odpowiednich fraz wpływu w dokumencie
Aby móc interpretować z drobiazgowym znaczeniem kontekstowym i być niezależnym od domeny, opracowaliśmy strukturę, którą określamy mianem modeli operacyjnych specyficznych dla firmy (O). Model operacyjny dla konkretnej firmy składa się z trzech sekcji wysokiego poziomu - makroekonomicznej, sektorowej i specyficznej dla firmy. Każda firma w branży będzie miała czynniki specyficzne dla firmy oprócz czynników makroekonomicznych i sektorowych. Opracowywanie takich modeli operacyjnych jest w znacznym stopniu zautomatyzowane przy użyciu narzędzia do odkrywania wiedzy RAGE AITM (KD) opisanego w rozdziale 3. Eksperci zaszczepili platformę kilkoma podstawowymi pojęciami, a następnie KD odkryło w sposób zautomatyzowany dodatkowe koncepcje i relacje. poprzez spożywanie ogromnej ilości treści, korzystanie z plików firmowych i indeksowanie publicznego Internetu. Rezultatem jest przyczynowa semantyczna sieć pojęć na poziomie przedsiębiorstwa. Sieć semantyczna kognitywna na poziomie firmy może być analizowana i edytowana przez analityka lub zarządzającego funduszem w celu odzwierciedlenia ich preferencji. Do analizy przedstawionej w dalszej części tego rozdziału zespół analityków z RAGE podał swoje preferencje.
Migawka modelu operacyjnego dla przemysłu naftowego i gazowego znajduje się w załączniku. Analizowana zawartość jest agregowana z bardzo dużej liczby i różnorodnych źródeł, w tym adresów URL, źródeł mikroblogowania, takich jak Twitter i Tumblr, oraz treści z serwisów informacyjnych. System zapewnia elastyczność dodawania nowych źródeł (adresów URL, użytkowników Twittera, dokumentów wewnętrznych itp.) Jako danych. Drugi etap dzieli treść na zdania, klauzule i frazy. Na tym etapie system rozwiązuje również współreferencyjną i kontekstową strukturę dokumentu. W wyniku tego powstaje zestaw klastrów, który opisuje konceptualną strukturę dokumentu. Gromada jest uważana za zestaw zdań należących do tej samej kliki. Siła klastra C ze zdaniami s0, s1,…, sL jest określona przez
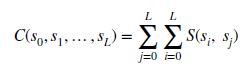
Można łatwo zidentyfikować główny temat artykułu, identyfikując klaster o maksymalnej sile. Dokument może mieć wiele klastrów, a zatem wiele tematów. Te tematy klastrów są następnie nakładane na ontologię przyczynową, aby podzielić dokument na główny temat i tematy drugorzędne. Na ostatnim etapie system przeprowadza analizę wpływu dokumentu. Analiza wpływu jest przeprowadzana na poziomie frazy i agregowana na poziomie klastra. Analiza rozpoczyna się od zdania głównego klastra i rozciąga się na wszystkie zdania w klastrze. Frazy wpływające w zdaniu głównym są identyfikowane przez głęboką analizę językową zdania i identyfikację słów i fraz, które opisują wpływ zdania. Frazy wpływowe są znacznie bardziej rozbudowane w sensie "znaczeniowym" niż leksykony sentymentalne używane do analizy sentymentów. Wymagają pełnej analizy językowej dyskursu i identyfikacji struktury językowej. Frazy wpływu to dowolny zestaw słów, które przekazują wpływ; mogą to być czasowniki, rzeczowniki, przymiotniki, przysłówki lub ich kombinacja w zdaniu. Zwroty określające wpływ są agregacją podstawowych słów wpływających i słów, które podkreślają wpływ. Każda klauzula w zdaniu zazwyczaj komunikuje wpływ. Klauzule podrzędne mogą modyfikować wpływ implikowany przez klauzulę główną, na przykład w użyciu "ale", co często właśnie to robi. Przymiotniki i przysłówki są zwykle używane do podkreślenia wpływu; nazywamy je "intensywnością uderzenia". Oprócz podstawowych zwrotów uderzeniowych system wyodrębnia atrybuty opisowe, takie jak czas, ilość i lokalizacja. Na przykład w "Rozpoczęciu mieszkalnictwa znacznie wzrosło o 3% w styczniu", czasownik "róża" jest głównym skutkiem słowa "znacząco" opisuje intensywność, "3%" odzwierciedla również intensywność, a "styczeń" jest wskaźnikiem czasu. Takie frazy mogą zawierać "Negacja", tak jak w "Rozpoczęcie budowy mieszkań nie wzrosło w styczniu". Odwrócenie kierunkowe może czasem zachodzić w bardziej subtelny sposób; może to również przejawiać się przez użycie anty słów - "antyimigracyjnych", "bezrobocia" i tak dalej. Aby osiągnąć spójność i porównanie między firmami i tematami, bez utraty ogólności, normalizujemy ocenę wpływu do dyskretnego zestawu wyników i powiązanych wyników; obecnie używamy pięciu odrębnych kategorii - istotnie pozytywnych, pozytywnych, neutralnych, negatywnych i znacząco negatywnych.
Ta sama fraza uderzeniowa może mieć całkowicie przeciwną interpretację dla dwóch tematów. Na przykład "wzrost cen ropy" będzie miał pozytywny wpływ na spółki naftowe i - na przedsiębiorstwa transportowe. Umożliwiamy konfigurację kierunku uderzenia na temat / znormalizowany poziom uderzenia. Ten rodzaj schematu oceniania przypisuje ocenę N-wymiarową (dla N tematów w systemie / ontologii) do dokumentu. To, postrzegane jako szereg czasowy, zapewnia ocenę tematu / zdarzenia lub bytu w funkcji czasu.
JAK DOBRZE DZIAŁA?
Dane
Zmierzyliśmy wydajność systemu na dużym korpusie zawierającym ponad 100 milionów elementów treści w ciągu ostatnich trzech do czterech lat w porównaniu z ręcznie wyselekcjonowanymi wynikami. Dzięki komponentowi agregacji danych w systemie zebraliśmy wiadomości w czasie rzeczywistym z ponad 200 000 źródeł na całym świecie. Źródła obejmują źródła wiadomości, strony internetowe i blogi. Mamy również osobne wyniki dotyczące treści z serwisu społecznościowego Twitter, które są zgłaszane osobno.
Mierzenie zależności lead-lag
Aby przetestować zależność między wyprzedzeniem a wyprzedzeniem między ceną akcji a wskaźnikiem RTI, szacuje się następujący model autoregresji wektorowej (VAR) przy użyciu zwykłego oszacowania metodą najmniejszych kwadratów (OLS) w każdym równaniu. Tutaj zarówno zmienne Stock, jak i RTI są endogeniczne.
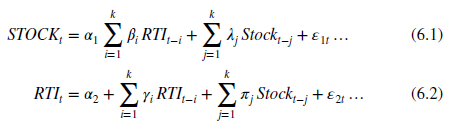
gdzie α1 i α2 są terminami przechwytującymi, współczynniki βi i γi mierzą wpływ opóźnionego RTI i opóźnionego zapasu na bieżący zapas. Podobnie, współczynniki λj i π j mierzą wpływ opóźnionego RTI i opóźnionego zapasu na bieżący RTI i ε są impulsami. Jeżeli oszacowane współczynniki opóźnionego R?TI w równaniu (1) są statystycznie różne od zera jako grupy (tj. βi≠ 0), a zbiór oszacowanych współczynników opóźnionego zapasu w równaniu (2) nie jest statystycznie różny od zera (tj. , γi = 0), następnie RTI prowadzi magazyn.
Przed oszacowaniem modelu VAR musimy zbadać stacjonarne właściwości szeregu i zdecydować o maksymalnej długości opóźnienia, k. Stan stacjonarny serii danych ocenia się za pomocą testu Augmented Dickey - Fuller (ADF). Wyniki testu są dość wrażliwe na długość opóźnienia. Opóźnienie k jest ustalane na podstawie kryterium wyboru, które daje najniższą wartość - kryteria informacyjne Akaike (AIC), kryteria Schwarza (SC), końcowe błędy prognostyczne (FPE) oraz kryterium informacyjne Hannan - Quinn (HQ).
Stacjonarność Szereg ekonomiczno-finansowy, który następuje po losowym przejściu, nazywa się z czasem "niestacjonarnym". Zmienna niestacjonarna może osiągnąć stacjonarność poprzez różnicowanie czasów t serii. Zmienna jest następnie określana jako I (t) lub zintegrowana z t procesów lub t jednostek podstawowych zawartych w szeregu. Aby przetestować pierwiastki jednostkowe, Dickey i Fuller opracowali następujące równanie regresji:
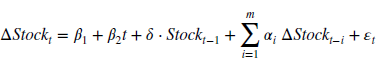
gdzie β1 jest dryfem, β2 reprezentuje współczynnik trendu czasowego t, a εt jest składnikiem błędu szumu białego. Tutaj hipoteza zerowa jest taka, że δ = 0; oznacza to, że istnieje korzeń jednostki, a szereg czasowy jest niestacjonarny. Alternatywna hipoteza jest taka, że ?? jest mniejsze niż zero; to znaczy szeregi czasowe są nieruchome. Oszacowana wartość t współczynnika Stockt-1 jest zgodna ze statystyką τ (tau). Jeśli obliczona wartość bezwzględna statystyki tau (| τ |) przekracza krytyczne wartości tau ADF, odrzucamy hipotezę, że δ = 0, w którym to przypadku szereg czasowy można uznać za stacjonarny. Przeciwnie, jeśli obliczone | τ | nie przekracza krytycznej wartości tau, nie odrzucamy hipotezy zerowej, co sugeruje, że szereg czasowy jest jest niestacjonarny. Podobnie możemy zbadać właściwości stacjonarne dla RTI.
Model zintegrowanej i wektorowej korekcji błędów (VECM) Jeśli zarówno zapas, jak i RTI są niestacjonarne w poziomach i stacjonarne w różnicach, istnieje szansa na relację kointegracji między nimi, która ujawnia długoterminową relację równowagi między nimi seria. Test kointegracji Engle - Granger (EG) może być zastosowany do zbadania długoterminowego związku między zapasami a RTI. Regresja współintegrująca oszacowana za pomocą zwykłej techniki najmniejszych kwadratów (OLS) to
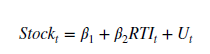
Możemy przepisać to wyrażenie jako
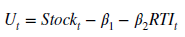
gdzie Ut jest terminem błędu. Jeśli zarówno Stock, jak i RTI są zintegrowane, Ut powinien być stacjonarny na swoim poziomie. Jeżeli zarówno Zapas, jak i RTI są ze sobą zintegrowane, istnieje między nimi długofalowa relacja równowagi, a w krótkim okresie może wystąpić nierównowaga. Dlatego można traktować termin błędu w równaniu kointegracji jako "błąd równowagi". Możemy użyć tego terminu błędu, aby powiązać krótkoterminowe zachowanie akcji z jej długoterminową wartością. Dlatego proces ten nazywa się "korekcją błędów". Jeśli Stock i RTI są ze sobą zintegrowane, to przyczynowość musi istnieć w co najmniej jednym kierunku. Aby przetestować przyczynowość, szacuje się następującą VECM za pomocą OLS w każdym równaniu:
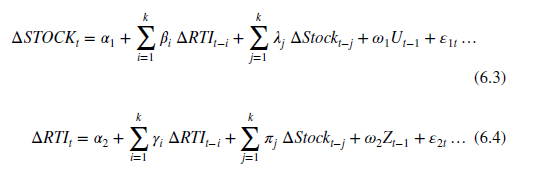
gdzie Δ jak zwykle oznacza pierwszą różnicę, εt jest składnikiem błędu losowego, Ut-1 = (Stockt-1 - β1 - β2 RTIt-1), a Zt-1 = (RTIt-1 - β1 -β2 Stockt-1) ; to jest opóźniona o jeden okres wartość błędu z regresji współintegrującej. Współczynniki na składowej korekcji błędów ω1 i ω2 mierzą tempo korygowania nierównowagi. Jeżeli oszacowane współczynniki opóźnionego RTI w równaniu (3) są statystycznie różne od zera jako grupy (tj. Σβi ≠ 0), a zbiór oszacowanych współczynników opóźnionego zapasu w równaniu (4) nie jest statystycznie różny od zera (tj. , Σπj = 0), następnie RTI prowadzi Stock.
Wyniki weryfikacji historycznej
Z wyłączeniem firm prywatnych, generujemy RTI dla 2761 spółek notowanych na giełdzie od września 2014 r. W całym portfelu do tej pory stwierdziliśmy, że RTI jest wiodącym wskaźnikiem zmian cen w około 15-20% firm. W pozostałych firmach nie znaleźliśmy żadnych statystycznie istotnych zależności między RTI a cenami zabezpieczeń. Prezentujemy wyniki z przykładowego portfela spółek naftowych i gazowych w naszym korpusie. Spośród 137 spółek w portfelu 31 (22,7%) wykazało pozycję lidera jako z końca sierpnia 2014 r. . Co tydzień próbka tych elementów treści jest ręcznie dobierana i porównywana z automatycznymi wynikami systemu. Gromadzimy próbkę każdego tygodnia i porównujemy cotygodniowe testy z rosnącą próbką ręcznie wyselekcjonowanych przedmiotów. Dokładność systemu wynosi prawie 85% w klasyfikacji i 80% w ocenie wpływu. Ocena dotyczy różnych sektorów i obejmuje a duża liczba czynników. Nasi analitycy próbują ustalić, czy jakieś firmy rezygnują z listy potencjalnych klientów lub czy istnieją nowe czynniki, które należy uwzględnić w modelach operacyjnych dla sektora lub dowolnej firmy. Wszelkie zmiany w działających modelach, O, są kalibrowane względem ręcznie wyselekcjonowanego zestawu Golden Content przy użyciu ładowania początkowego (Efron, 1993). Nowy model operacyjny firmy, O ', jest promowany do użytku produkcyjnego tylko wtedy, gdy wykazuje poprawę. Aby krótko przedstawić tę ocenę, na rycinie 6.4 przedstawiamy sygnały RTI losowo wybranej firmy z 31 spółek o wiodącej pozycji w portfolio próbek ropy i gazu - Norfork Southern. Zgodnie z naszymi testami wstecznymi, sygnał RTI firmy Norfolk Southern pokazuje przewrotną przewagę nad cenami akcji. Śledzimy również zmiany oceny analityków (ARC). Są one pokazane jako X na wykresie. Co ciekawe, w okresie od 13 listopada do 14 lutego większość ocen analityków była "neutralna", aw rzeczywistości co najmniej jedna firma obniżyła ocenę NSC.N do "trzymaj". Od 14 lutego oceny analityków zaczęły przewidywać bardziej pozytywne perspektywy dla NSC.N. Sygnały RTI pozostały jednak dodatni okres. Dodatkowo przeprowadziliśmy inny rodzaj weryfikacji historycznej, aby sprawdzić, czy transakcje oparte na sygnałach wygenerowały znaczącą wartość alfa po skorygowaniu o koszty transakcji.
Zasady handlu
1. Zaczynamy od ilości fantomowej, powiedzmy 1000 akcji, które są kupowane na początku okresu handlowego.
2. Kupujemy / sprzedajemy akcje w zależności od zmiany skumulowanego wyniku w RTI.
3. Ilość w kasie zmienia się przy każdej transakcji kupna / sprzedaży.
4. Jeśli ilości w kasie są ujemne (tj. Inwestor nie ma zapasów w zapasie), nie dojdzie do żadnej transakcji (brak obrotu marżą).
Obliczanie zysków / strat
1. Obliczamy zysk / stratę netto z obrotu, postępując zgodnie z prostą strategią handlową polegającą na kupowaniu akcji na początku okresu handlowego i sprzedaży akcji na koniec okresu handlowego.
2. Obliczamy zysk / stratę netto z obrotu, postępując zgodnie ze strategią handlową RTI, w której kupujemy / sprzedajemy akcje w zależności od zmiany skumulowanego wyniku w RTI.
3. Różnica 1 i 2 powyżej daje nam zysk / stratę handlową poprzez RTI.
PODSUMOWANIE
Przedstawiliśmy inteligentny system, który wykorzystuje uczenie maszynowe przy użyciu lingwistyki obliczeniowej i generuje sygnały alfa dla rynków finansowych. System agreguje i interpretuje wiadomości i inne treści z całego świata oraz, opierając się na modelu operacyjnym dla każdej firmy, określa potencjalne znaczenie i wpływ wiadomości i innych treści na wartość wewnętrzną każdej firmy. Taką istotność i wpływ określa się w kontekście kontekstowym i przyczynowym, a także zdolność rozumienia języka naturalnego przez platformę przy użyciu modelu operacyjnego każdej firmy, dzięki czemu system może przetwarzać informacje na różnych poziomach oddzielenia od firmy pod względem tego, co uważa za bezpośrednie. odniesienie do firmy. Według typu systemu opisanego w tym rozdziale, aktywni menedżerowie mogą przejść do stanu E4.0.
Czy audytorzy finansowi zostaną wygaszeni?
WPROWADZENIE
Audyty zewnętrzne stanowią kluczową część ram finansowych leżących u podstaw działalności przedsiębiorstw na całym świecie. Rzetelność i dokładność takich audytów była kluczowa dla promowania zaufania inwestorów i umożliwienia rozkwitu handlu. Wraz z powszechnym stosowaniem technologii przez przedsiębiorstwa, zainteresowanie technologią było znaczące, aby usprawnić proces kontroli i poprawić jakość kontroli. W rzeczywistości, biorąc pod uwagę wysoki stopień polegania na technologii przez korporacje w ogólności przy prowadzeniu działalności, firmy audytorskie muszą koniecznie polegać na automatyzacji w zakresie audytu zaawansowanych systemów technologicznych przyjętych przez ich klientów. Standardy rachunkowości zachęcają teraz firmy audytorskie do przyjmowania informatyki i korzystania w razie potrzeby ze specjalistów IT (AICPA 2002b, 2005, 2006b, PCAOB 2004b). Jeśli chodzi o badania naukowe dotyczące automatyzacji audytu, nawet we wczesnych dniach obliczeń, zauważono potencjalny wpływ automatyzacji na rachunkowość i audyt (Keenoy, 1958). Od tego czasu przeprowadzono znaczące badania akademickie i skupiono się na tym temacie, zarówno z perspektywy audytu wewnętrznego, jak i zewnętrznego. Vasarhelyi (1984) był pionierem badań nad potencjalnym wpływem automatyzacji audytu na procesy audytu. Większość badań akademickich, a także oprogramowania komercyjnego, koncentrowała się na punktowych rozwiązaniach i dość podstawowym wykorzystaniu technologii, takich jak poczta elektroniczna Microsoft Office (Janvrin i in., 2008), oraz na określonych aspektach funkcji kontrolnej, takich jak listy kontrolne kontroli według konta i harmonogramu. Głównym celem oprogramowania komercyjnego była pomoc w zarządzaniu audytem, a nie automatyzacja samego audytu. Rzeczywisty audyt pozostał w dużej mierze ręcznym przedsięwzięciem. Jednak nawet przyjęcie takiej podstawowej technologii zarządzania produktywnością i audytem miało znaczący wpływ na rachunkowość publiczną i produktywność firmy. Dzięki postępom w zakresie automatyzacji procesów biznesowych i technologii dużych zbiorów danych istnieje bardzo realna szansa na inteligentną automatyzację cyklu życia audytu od końca do końca. Kluczem do zrealizowania potencjalnie ogromnego wpływu jest elastyczność i adaptowalność rozwiązania. W dzisiejszym cyfrowym świecie oczywiste jest, że skuteczność każdej kontroli lub oceny ryzyka w sposób krytyczny zależy od możliwości przetworzenia ogromnej ilości informacji, które stale docierają cyfrowo. Audytorzy muszą być dobrze informowani o swoich klientach nie tylko podczas audytu, ale także w sposób ciągły. Uważamy, że wskaźnik napływu nowych informacji znacznie przewyższa zdolność firm audytorskich i ich personelu do przetwarzania takich informacji. W tym rozdziale opisano adaptacyjną, inteligentną maszynę do audytu na cały cykl życia audytu zewnętrznego. Rozwiązanie jest wyjątkowe ze względu na swoją dużą elastyczność i zdolność do ciągłego uczenia się, automatyzacji badania audytu i szybkiego dostosowywania się do zmian w procesach audytu, standardach i wiedzy. Rozwiązanie czerpie swoją zdolność uczenia się, elastyczność i możliwości adaptacji z rozbudowanej architektury opartej na modelu platformy RAGE AI. Rozwiązanie dyskretnie włącza dwa rodzaje inteligencji maszynowej w procesach audytu. Obejmuje ono możliwe do skontrolowania odkrycie reguł, uzasadnienie oparte na regułach i wiedzę ekspercką do automatycznej analizy danych strukturalnych i deterministycznych. W przypadku danych nieustrukturyzowanych, zawiera unikalne możliwości RAGE AI do rozumienia języka naturalnego i automatycznego uczenia maszynowego w wysoce kontekstowy, kontrolowany sposób, który naszym zdaniem jest absolutną koniecznością w większości kontekstów decyzyjnych. Zespół audytowy musi być w stanie zrozumieć dokładne powody każdej automatycznej interpretacji. Rozwiązanie jest rozszerzalne. Na przykład, chociaż rozwiązanie nie odnosi się wyraźnie do wykrywania oszustw, ponieważ wykrywanie oszustw nie jest częścią cyklu życia audytu zewnętrznego, algorytmy lub podejścia do wykrywania oszustw można łatwo zintegrować z ramą rozwiązania w nieinwazyjny sposób. Rozwiązanie i podejście można również rozszerzyć na wiele innych rodzajów audytów, takich jak audyty regulacyjne i audyty wewnętrzne.
ZEWNĘTRZNY AUDYT FINANSOWY
Chociaż istnieją różne warianty procesu audytu specyficzne dla branży i firmy, kroki na wysokim poziomie pozostają zasadniczo takie same. Proces ten rozpoczyna się od etapu zaakceptowania klienta przez firmę audytorską, a kończy wydaniem przez firmę audytorską niezależnej opinii o prawdziwości i rzetelności sprawozdania finansowego.
Zaangażowanie klienta
Przed przyjęciem klienta oczekuje się, że firma audytorska upewni się, że firma audytorska jest wystarczająco niezależna od klienta, jego dyrektorów i kadry kierowniczej wyższego szczebla. Ma to na celu zapewnienie integralności audytu. Po zweryfikowaniu niezależności firma audytorska sprawdza również, czy klient jest naprawdę gotowy na zewnętrzny audyt. W niektórych przypadkach, zwłaszcza większe firmy audytorskie, przeprowadzają również kontrole przeszłości kluczowych członków kierownictwa.
Planowanie audytu
Po wykonaniu listu zlecającego firma audytorska musi formalnie zaplanować badanie. Planowanie audytu dla spółek publicznych jest regulowane przez PCAOB Standard kontroli nr 9. W przypadku podmiotów niepublicznych od audytorów w Stanach Zjednoczonych oczekuje się przestrzegania wytycznych Amerykańskiego Standardu Rachunkowości nr 109 i 99. Amerykańskiego Instytutu Biegłych Księgowych. organy regulacyjne i zawód kładą duży nacisk na planowanie kontroli. Planowanie audytu koncentruje się na dogłębnym zrozumieniu ryzyk istotnych zniekształceń w sprawozdaniach finansowych klienta i ustalenie limitów istotności. Aby rozwinąć takie dogłębne zrozumienie, biegli rewidenci muszą dokładnie zapoznać się z jednostką, jej działalnością, branżą, w której działa, powiązanymi jednostkami, jej wcześniejszymi wynikami finansowymi i tak dalej. Zazwyczaj odbywa się to poprzez połączenie wizyty w siedzibie klienta, rozmowy z kluczowym kierownictwem i personelem klienta osobiście oraz poprzez kwestionariusze, ocenę projektu kontroli wewnętrznej, oraz przegląd dokumentów prawnych i finansowych firmy, w tym jej statut. Zrozumienie kluczowych wskaźników wyników finansowych odnoszących się do branży może pozwolić biegłemu rewidentowi ocenić racjonalność sprawozdań finansowych klienta i zidentyfikować wyjątkowe dane finansowe. Ocena ryzyka istotności i zniekształceń przez audytorów bezpośrednio określa charakter, harmonogram, wielkość i nacisk w procedurach kontrolnych. Na przykład biegły rewident może zdecydować o nierównym nacisku między testami kontroli wewnętrznej (testy przejścia kontroli wewnętrznej w rzeczywistych transakcjach) a testami wiarygodności (testy zaprojektowane w celu weryfikacji i potwierdzenia kompletności i dokładności transakcji i / lub sald kont).
Prace w terenie
Praca w terenie odnosi się do wykonywania procedur audytu zaprojektowanych na etapie planowania audytu. W przypadku testów kontroli wewnętrznej należy przeprowadzić testy, aby upewnić się, że kontrole były i faktycznie działają. Przykładową procedurą kontroli wewnętrznej jest podpisanie dwóch sygnatariuszy, gdy nastąpi przekazanie drutu powyżej progu. Testem kontrolnym tej kontroli będzie wybór losowego zestawu transakcji przelewowych powyżej progu i fizyczna weryfikacja, czy na każdym z nich było dwóch upoważnionych sygnatariuszy. Często merytoryczne testy stanowią większość prac terenowych przeprowadzanych przez audytorów. Zasadniczo w tych procedurach dane księgowe i ich wzajemne powiązania są badane w celu ustalenia "racjonalności" sald kont. Każda kwota lub saldo pozycji sprawozdania finansowego zawiera wiele stwierdzeń. Jeżeli twierdzenia są błędne, wówczas kwota sprawozdania finansowego zawiera zniekształcenia. Asercje są ogólnie podzielone na następujące dwie kategorie.
Twierdzenia dotyczące klas transakcji:
Atrybut : Definicja
Wystąpienie: Zarejestrowane transakcje faktycznie dotyczą jednostki
Kompletność: Żadne transakcje nie zostały pozostawione niezarejestrowane
Dokładność: transakcje zostały poprawnie i dokładnie zarejestrowane
Punkt odcięcia: transakcje zostały zarejestrowane we właściwym okresie obrachunkowym
Klasyfikacja: Transakcje zostały sklasyfikowane na odpowiednich kontach
Twierdzenia dotyczące sald kont na koniec okresu kontroli:
Atrybutu : Definicja
Istnienie: Istnieją aktywa, zobowiązania i kapitał własny
Prawa i obowiązki: Prawa podmiotu do sald nie są kwestionowane
Kompletność: Żadne transakcje nie zostały pozostawione niezarejestrowane
Wycena: Aktywa, zobowiązania i kapitał własny zostały prawidłowo wycenione
Celem audytu jest ustalenie ważności każdego stwierdzenia dotyczącego klasy transakcji i sald kont. Badania merytoryczne można przeprowadzić za pomocą kombinacji dwóch podejść:
1. Istotne procedury analityczne W tym podejściu biegły rewident bada wzajemne powiązania między saldami kont, aby ustalić ich zasadność.
2. Testy szczegółów W tym podejściu biegły rewident bada transakcje, które powodują saldo konta lub bezpośrednio analizuje składniki salda konta zamknięcia.
Testy merytoryczne pozwalają audytorowi zweryfikować ważność, kompletność i dokładność twierdzeń wynikających ze sprawozdania finansowego
Przegląd i szkic
Po zakończeniu badania merytorycznego biegły rewident musi ocenić ustalenia:
1. Ustal, czy istnieją zobowiązania warunkowe, które należy zarejestrować.
2. Przejrzyj kolejne zdarzenia przed i po podpisaniu raportu z audytu.
3. Ponowna ocena wiarygodności sprawozdania finansowego na podstawie założenia kontynuacji działalności.
4. Oceń ryzyko związane z nieskorygowanymi wpisami.
5. Przejrzyj i oceń zebrane do tej pory dowody kontroli oraz dokumenty robocze.
Na tym etapie biegły rewident przygotowuje projekt sprawozdania finansowego i przesyła go do klienta w celu uzyskania uwag.
INTELIGENTNA MASZYNA AUDYTOWA
W tej sekcji opisujemy inteligentną maszynę audytową (IAM) do audytu zewnętrznego. Celem IAM jest poprawa jakości i spójności między audytami, wprowadzenie ciągłego audytu, osiągnięcie znacznego ograniczenia ogólnego wysiłku związanego z audytami zewnętrznymi zarówno dla firmy audytorskiej, jak i klienta, oraz umożliwienie firmie audytorskiej zinstytucjonalizowanie standardów kontroli. Przewidujemy, że rozwiązanie IAM będzie używane przez zespoły kontrolne, klientów kontrolujących i osoby trzecie, które odgrywają rolę w procesie kontroli, na przykład dłużników potwierdzających wierzytelności. Przewidujemy samoobsługowy portal kontrolny, z którego będzie korzystał klient, aplikację dla zespołów audytorskich i firmy audytorskiej, a wreszcie portal do interakcji ze stronami trzecimi, na przykład bankami, wierzycielami i dłużnikami. Architektura rozwiązania jest bardzo elastyczna, ponieważ jest oparta na meta-modelu. Dzięki RAGE AI cała funkcjonalność jest zredukowana do zestawu modeli procesów biznesowych w środowisku bez kodu. Modele te można łatwo modyfikować bez programowania. Dzięki obszernemu zestawowi komponentów opartych na wiedzy w RAGE, IAM może zdobywać wiedzę w sposób ciągły na podstawie zarówno danych ustrukturyzowanych, jak i nieustrukturyzowanych oraz z pomocą ekspertów lub bez nich. Gdy zespoły kontrolne i użytkownicy identyfikują nową wiedzę lub usprawnienia procesów, można je wdrażać niemal natychmiast. Taka elastyczność w instytucjonalizacji wiedzy daje IAM możliwość dostosowania się do zmian w otoczeniu klienta oraz do zmian standardów i przepisów. Rysunek 7.3 przedstawia architekturę IAM i zestaw automatycznych agentów, które można konfigurować i wdrażać za pomocą platformy i komponentów RAGE AITM. Są to przykłady. Za pomocą platformy można łatwo skonfigurować dodatkowych agentów automatyzacji. Wiele, jeśli nie wszystkie, procesy audytu można całkowicie zautomatyzować, pozostawiając zespoły audytorskie skupione na zrozumieniu ryzyka związanego z rzetelnym i rozsądnym stwierdzeniem sytuacji finansowej klienta i uzyskaniu świadomej opinii.
Zaangażowanie klienta
Przewidujemy, że proces akceptacji zlecenia od końca do końca będzie znacznie zautomatyzowany i potencjalnie ulepszony w rozwiązaniu IAM. Komponentu kwestionariusza można użyć do skonfigurowania odpowiednich pytań i automatycznej analizy odpowiedzi. Rozwiązanie IAM może również umożliwić konfigurację pytań specyficznych dla klienta. IAM może automatycznie analizować odpowiedzi. IAM obejmuje kompleksowy zestaw drugorzędnych maszyn, które są zsynchronizowane w celu przeprowadzenia audytu przy użyciu projektu audytu i planu dostarczonego przez eksperta ds. Audytu, takiego jak partner klienta.
• Pod-maszyna 5 obsługuje proces angażowania.
• Pod-maszyna 6 zarządza i wykonuje proces planowania audytu.
• Pod-maszyna 7 wykonuje wszystkie prace terenowe. Ta pod-maszyna będzie miała wiele autonomicznych części lub agentów, które wykonują zadania w terenie. Na poziomie pozycji mogą istnieć agenci, na przykład agent potwierdzający AR, który zarządza wszystkimi otrzymywanymi potwierdzeniami i uzyskuje je, agent inwentaryzacyjny, który elektronicznie wydobywa informacje o inwentarzu, w razie potrzeby planuje fizyczną weryfikację i wykonuje zadania uzgadniania.
• Pod-maszyna 8 generuje projekt raportu z audytu zawierającego dane finansowe i przypisy.
Alternatywnie, oczywiście księgi KG i księgi pomocnicze mogą być cyfrowo podawane do IAM. Standardy i procedury audytu można również przekazać IAM. W częściowo nadzorowanym wdrożeniu IAM, takie standardy mogą zostać skodyfikowane w formie umożliwiającej działanie, dzięki czemu IAM może przetestować zgodność ze standardami. Rysunek 7.4 ilustruje bardziej szczegółowo rodzaje agentów i automatyzacji, które można osiągnąć w każdym obszarze. Rozwiązanie może również automatycznie integrować się z systemami zewnętrznymi, które przeprowadzają kontrole w tle. Oczekujemy również, że dodamy sieć niezależności, aby sprawdzić, czy zmiana sytuacji jednego dyrektora lub klienta byłaby konsekwencją dla innych klientów.
Planowanie audytu
Zadania planowania audytu obejmują przepływ pracy i ocenę ryzyka. Zadania przepływu pracy mogą być obsługiwane przez funkcje związane z planowaniem, kalendarzem, budżetowaniem i alokacją zasobów. Istnieje kilka komercyjnych produktów, które zapewniają tę funkcjonalność. Jednak ocena ryzyka jest obszarem planowania audytu, który IAM może znacznie ulepszyć. Pod tym względem odróżniamy ocenę ryzyka od wykrycia oszustwa. Celem audytu zewnętrznego w normalnym trybie nie jest wykrycie oszustwa. IAM może wykryć oszustwo, ale zazwyczaj jest to niezamierzony rezultat. Automatyczny agent zapisów księgowych sprawdzałby wszystkie zapisy księgowe i oznaczałby wpisy nietypowe lub podejrzane. W ramach IAM zespół audytowy może wdrożyć reguły analityczne i logikę przy użyciu obszernego zestawu komponentów opartych na wiedzy na platformie RAGE, głównie reguł, drzewa decyzyjnego, modelu i sieci modelowej. Taka logika może być na poziomie pozycji konta lub na poziomie klienta lub branży. Oprócz możliwości definiowania reguł i logiki, szeroki zestaw podstawowych wskaźników i parametrów oceny ryzyka może być automatycznie wykonywany i oceniany. Korzystając z komponentów do ekstrakcji i normalizacji opartych na języku naturalnym RAGE AITM, IAM może wyodrębniać i normalizować podstawowe dane bezpośrednio z dokumentów źródłowych, takich jak akta firmowe i raporty roczne. W przypadku firm z sektora prywatnego dostęp do takich danych można uzyskać ze wszystkich ksiąg rachunkowych i ksiąg pomocniczych w oddziałach, filiach oraz w razie potrzeby znormalizowanych / skonsolidowanych. IAM może również stale oceniać ryzyko jednostki, integrując i analizując informacje zewnętrzne, takie jak wiadomości i posty w mediach społecznościowych. Rycina 7.6 ilustruje taką analizę nieustrukturyzowanych informacji z całego świata i interpretację nieustrukturyzowanych informacji z punktu widzenia wypłacalności. Ta automatyczna pod-maszyna IAM może generować ciągły sygnał, dzięki czemu ryzyko może być uwzględnione w dowolnym momencie cyklu audytu. IAM można zintegrować ze źródłami informacji kredytowej we wszystkich krajach. Źródła te przekazują powiadomienia o firmach, które codziennie monitorują. IAM może dynamicznie tworzyć listy kontrolne kontroli według kont, a także generować żądania informacji dla klienta. W zależności od klienta żądanie może zostać przesłane za pośrednictwem portalu kontroli lub dokumentu drukowanego
Prace w terenie
Praca w terenie zajmuje większość czasu podczas większości audytów. Zespół audytowy poświęca znaczny wysiłek na merytoryczne testy twierdzeń. Praca w terenie jest również podatna na znaczną automatyzację. Jak zilustrowano na rysunkach 7.3 i 7.4, IAM może obejmować tyle drugorzędnych maszyn, ile to konieczne dla określonych pozycji, takich jak AR, AP, zapasy i wartości niematerialne. Każda z pod-maszyn może obsługiwać szczegóły konkretnego konta i w razie potrzeby przekazywać wyniki do innych maszyn.
Testy egzystencji
Na rachunkach finansowych istnienie aktywów i pasywów często angażuje strony trzecie, takie jak dłużnicy, wierzyciele, banki i powiernicy, i wiąże się z potwierdzeniem ich istnienia przez stronę trzecią. Jest to nazywane procesem "potwierdzania". Większość twierdzeń o istnieniu można zautomatyzować za pośrednictwem IAM. Zazwyczaj audytorzy weryfikują próbkę transakcji na rachunku, która prowadzi do bilansu zamknięcia aktywów i pasywów. Od inteligentnego wyboru próbka do wygenerowania potwierdzenia i przetworzenia odpowiedzi od strony trzeciej, IAM może zautomatyzować cały proces. W rzeczywistości IAM może automatycznie przetwarzać znacznie więcej potwierdzeń i nie ograniczać się do próbki, jak to zwykle ma miejsce w procesie ręcznym. Dzięki opatentowanemu składnikowi ekstrakcji proces dopasowywania potwierdzonych kwot i innych atrybutów do zarejestrowanych kwot i atrybutów można zautomatyzować.
Prawa i obowiązki
Audytorzy przeglądają również dokumenty umowne, aby zrozumieć prawa i obowiązki klienta jako strony umowy. Ważnym przykładem jest umowa na oprogramowanie w przypadku firmy programistycznej. Zespół audytowy będzie zainteresowany zrozumieniem warunków umowy, takich jak opłaty licencyjne na oprogramowanie, opłaty za wdrożenie lub konfigurację, zobowiązania wskazane przez język akceptacji oraz wszelkie zakresy gwarancji. Wszystko to jest potrzebne do ustalenia zasadności ujmowania przychodów przez klienta. Rozwiązanie IAM ma wyjątkową zdolność do automatycznego przeglądania umów i uzgadniania warunków z innymi pochodnymi danymi i dokumentami, takimi jak faktury i rachunki. Funkcje rozumienia języka naturalnego przez RAGE AITM umożliwiają taką automatyczną analizę dokumentów kontraktowych. Jego możliwości wykraczają daleko poza samą identyfikację i wyodrębnianie kluczowych terminów i rozciągają się na jakościową ocenę różnych klauzul lub semantyczne dopasowanie atrybutów do danych zewnętrznych.
Istotne procedury analityczne
IAM może dodatkowo zapewnić zautomatyzowaną pomoc w procedurach analitycznych, w których zespoły audytorskie badają wskaźniki w stosunku do przeszłych trendów, innych firm w branży i / lub całej branży. Audytorzy mogą być powiadamiani o nietypowych wartościach.
Testy bilansu zamknięcia
IAM może automatycznie tworzyć harmonogramy i dokumenty robocze na poziomie konta, identyfikując znaczące i nietypowe transakcje w tym procesie.
Analizuj i wystawiaj finanse
Przewidujemy, że IAM automatycznie generuje projekt sprawozdania finansowego i raportu z audytu ze wszystkimi odpowiednimi przypisami. IAM może również wygenerować pismo kierownicze w przypadku uchybień w kontroli wewnętrznej. Zespół audytowy powinien następnie edytować te dokumenty w systemie i wydawać je elektronicznie.
Standardy audytu
W dzisiejszym, w dużej mierze ręcznym świecie, standardy audytu są zwykle znane audytorom. W IAM firma audytorska może kodyfikować standardy i uczynić je bardziej praktycznymi (rysunek 7.7). Na przykład często normy są wyrażone w szeregu pytań i odpowiedzi, które pomagają określić sposób traktowania określonego elementu. Takie standardy można skodyfikować w IAM, dzięki czemu IAM nie tylko zidentyfikuje / uzyska odpowiedzi na takie pytania, ale potencjalnie dojdzie do wniosku, który będzie całkowicie możliwy do prześledzenia. Audytorzy mogliby następnie prześledzić uzasadnienie IAM w sposób zadowalający. Przykładem jest najnowszy standard wydany przez AICPA dotyczący rozpoznawania przychodów w przypadku umów Software as a Service (SaaS). Taki proces kodyfikacji wdrażania standardów przez firmę zmniejszyłby obciążenie kontrolerów w zakresie kontroli nowych i zaktualizowanych standardów w celu ich operacjonalizacji. Po skodyfikowaniu standardów przy użyciu struktury metadanych w RAGE AITM, są one skutecznie zinstytucjonalizowane i mogą wpływać na każdy audyt, na który wpływ mają nowe standardy. Taki proces może być również bardzo dobrze oceniany przez organy regulacyjne.
Przepływ pracy / konfiguracja
IAM może już inteligentnie kontrolować i zarządzać przepływem pracy w celu optymalizacji alokacji zasobów ze wszystkich stron na różnych etapach procesu audytu. Ta funkcja może dotyczyć funkcji planowania, kalendarza i zasobów. IAM jest w pełni konfigurowalny. Od dodawania i konfigurowania klientów do definiowania reguły interpretacji dla różnych sektorów, branż i typów kont do reguł generowania tekstu, firma audytorska może tworzyć metadane wielokrotnego użytku do automatyzacji audytów klientów w różnych branżach. Nowe standardy można skodyfikować i przyporządkować do odpowiedniego zestawu kont.
PODSUMOWANIE
W środowisku akademickim i wśród praktykujących audytorów panuje zgoda co do tego, że audyty zewnętrzne i wewnętrzne mogą znacznie skorzystać z technologii opartych na wiedzy. W tym rozdziale nakreśliliśmy naszą koncepcję kompleksowej inteligentnej maszyny do zewnętrznych audytów finansowych. Inteligentna maszyna audytowa, którą zaprojektowaliśmy, radykalnie zmieni sposób przeprowadzania audytów zewnętrznych. Głębokość i szerokość typowego audytu rozszerzy się, poprawiając jakość audytów. Spójność poprawi się również we wszystkich obszarach. Firmy audytorskie i klienci zauważą znaczne zmniejszenie wysiłku związanego z audytem. Firmy audytorskie przejdą do stanu Enterprise 4.0. Jak omówiono, IAM można rozszerzyć na wiele innych procesów audytu. Oprócz stosowania przez audytorów wewnętrznych, organy regulacyjne mogą konfigurować IAM do swoich celów, co znacznie zmniejsza obciążenia regulacyjne spoczywające na firmach podlegających regulacji, a jednocześnie poprawia jakość ich pracy.