Zachowanie agenta ukierunkowanego na cel
Do tej pory sprawdziliķmy agentów wykorzystujących architekturę opartą na skoņczonej maszynie stanów, w której zachowanie jest rozkģadane na kilka stanów, z których kaŋdy zawiera logikę umoŋliwiającą przejķcie do innych stanów. Ten rozdziaģ wprowadza nieco inne podejķcie. Zamiast stanów zachowanie agenta jest definiowane jako zbiór hierarchicznych celów. Cele mają charakter atomowy lub zģoŋony. Cele atomowe definiują pojedyncze zadanie, zachowanie lub akcję, takie jak dąŋenie do ustawienia lub przeģadowania broni, podczas gdy cele zģoŋone skģadają się z kilku podzadaņ, które z kolei mogą byæ atomowe lub zģoŋone, definiując w ten sposób zagnieŋdŋoną hierarchię. Kompozyty zwykle opisują bardziej zģoŋone zadania niŋ ich bracia atomowi, takie jak budowanie fabryki broni lub wycofywanie się i szukanie schronienia. Oba typy celów są w stanie monitorowaæ swój status i mają zdolnoķæ do przeplanowania, jeķli się nie powiedzie. Ta hierarchiczna architektura zapewnia programiķcie AI intuicyjny mechanizm definiowania zachowania agentów, poniewaŋ dzieli wiele podobieņstw z ludzkim procesem myķlowym. Ludzie wybierają abstrakcyjne cele wysokiego poziomu w oparciu o ich potrzeby i pragnienia, a następnie rekurencyjnie rozkģadają je na plan dziaģania, który moŋna zastosowaæ. Na przykģad w deszczowy dzieņ moŋesz zdecydowaæ się odwiedziæ kino. Jest to abstrakcyjny cel, którego nie moŋna zrealizowaæ, dopóki nie zostanie on podzielony na mniejsze cele cząstkowe, takie jak opuszczenie domu, podróŋ do kina i wejķcie do kina. Z kolei kaŋdy z nich jest abstrakcyjny i naleŋy go dalej podzieliæ. Proces ten jest zwykle przejrzysty, ale czasami zdajemy sobie z tego sprawę, gdy rozkģad wymaga wyboru. Na przykģad subgalowa podróŋ do kina moŋe byæ zaspokojona na wiele sposobów - moŋesz tam podróŋowaæ samochodem, komunikacją miejską, rowerem lub pieszo - i moŋesz spędziæ kilka chwil zastanawiając się nad wyborem. (Jest to szczególnie prawdziwe, jeķli wspóģpracujesz z kilkoma innymi ludžmi, aby osiągnąæ cel - przypomnij sobie ostatnią wizytę w wypoŋyczalni wideo / DVD ze znajomymi. Argh!) Ten proces trwa, dopóki cele nie zostaną rozģoŋone na podstawowe czynnoķci motoryczne, które twoje ciaģo jest w stanie wykonaæ. Na przykģad cel opuszczenia domu moŋna podzieliæ na następujące cele: iķæ do szafy, otworzyæ drzwi szafy, zdjąæ pģaszcz z wieszaka na pģaszcz, zaģoŋyæ pģaszcz, iķæ do kuchni, zaģoŋyæ buty, otworzyæ drzwi, wyjķæ na zewnątrz i wkrótce. Co więcej, ludzie nie lubią marnowaæ energii, więc generalnie nie marnujemy cennych kalorii na myķlenie o celu, dopóki nie będzie to absolutnie konieczne. Na przykģad nie zdecydowaģbyķ, jak otworzyæ puszkę fasoli, dopóki nie będziesz mieæ jej w dģoni, lub jak zawiązaæ sznurowadģa, dopóki buty nie staną na nogach. Celowy agent naķladuje to zachowanie. Kaŋda aktualizacja myķli agent sprawdza stan gry i wybiera zestaw predefiniowanych celów lub strategii wysokiego poziomu - ten, który wedģug niego najprawdopodobniej pozwoli mu zaspokoiæ najsilniejsze pragnienie (zazwyczaj wygraną). Następnie agent będzie próbowaģ podąŋaæ za tym celem, rozkģadając go na dowolne podzadania, speģniając kolejno kaŋdy z nich. Będzie to robiæ, dopóki cel nie zostanie speģniony lub nie uda mu się, lub dopóki stan gry nie będzie wymagaģ zmiany strategii.
Powrót Erica Chrobrego
Przyjrzyjmy się przykģadowi, uŋywając naszego ulubionego agenta gier, Erica, który niedawno znalazģ zatrudnienie w RPG "Dragon Slayer 2." Programista AI Erica opracowaģ dla niego kilka strategii, w tym Obroņ przed smokiem, Smokiem ataku, Kup miecz, Zdobądž jedzenie i Upij się. Strategie te reprezentują abstrakcyjne cele wysokiego poziomu, które skģadają się z mniejszych celów cząstkowych, takich jak Utwórz ķcieŋkę, Ķledž ķcieŋkę, Traverse Path Edge, Stab Dragon, Slice Dragon, Run Away i Hide. Dlatego, aby ukoņczyæ strategię, Eric musi ją rozģoŋyæ na odpowiednie podzadania i kolejno zaspokajaæ kaŋdy z nich (w razie potrzeby dalej je rozkģadając). Eric wģaķnie wszedģ do ķwiata gry, a poniewaŋ nie nosi broni i dlatego czuje się wraŋliwy, jego największym pragnieniem jest znalezienie jakiegoķ spiczastego kija, zanim smok go zauwaŋy. Jego "mózg" (specjalny rodzaj celu zdolny do podejmowania decyzji) bierze pod uwagę wszystkie dostępne strategie i stwierdza, ŋe Kup Miecz znakomicie pasuje do rachunku, więc jest to wyznaczone jako cel, do którego naleŋy dąŋyæ, dopóki nie zdecyduje inaczej
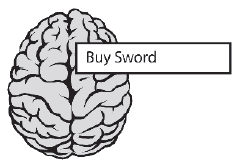
Eric nie moŋe jednak dziaģaæ zgodnie z tym celem, poniewaŋ na tym poziomie jest on zbyt abstrakcyjny i musi zostaæ rozģoŋony - lub rozszerzony, jeķli wolisz myķleæ o tym w ten sposób - na skģadowe podzadania. Na potrzeby tego przykģadu zaģoŋymy, ŋe Kup miecz skģada się z podzadaņ pokazanych na rysunku
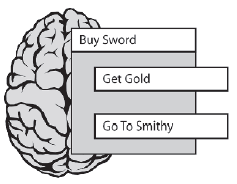
Aby zdobyæ miecz, Eric musi najpierw znaležæ trochę zģota, a następnie udaæ się do kužni, gdzie kowal chętnie przyjmie je jako zapģatę. Agenci realizują cele kolejno, więc Go To Smithy nie będzie oceniane, dopóki nie będzueGetGold. Jest to jednak kolejny zģoŋony cel, więc aby go zrealizowaæ, Eric musi dalej poszerzaæ hierarchię. Zdobądž zģoto skģada się z podzadaņ Plan Path (Goldmine), Follow Path i Pick Up Nugget.
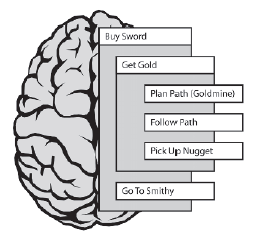
Cel Plan Path (Goldmine) jest speģniony, wysyģając zapytanie do Planowanie ķcieŋki, aby zaplanowaæ ķcieŋkę do kopalni zģota. Następnie jest usuwany z listy celów. Następną rzeczą, którą Eric rozwaŋa, jest Podąŋanie ķcieŋką, którą moŋna dalej rozģoŋyæ na kilka atomowych celów Traverse Edge, z których kaŋda zawiera logikę wymaganą do podąŋania za krawędzią ķcieŋki prowadzącej do kopalni zģota.
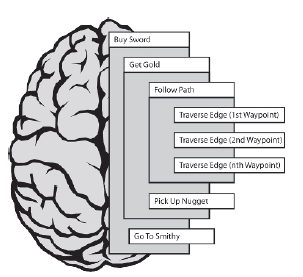
Ten proces rozkģadania i speģniania celów trwa, dopóki caģa hierarchia nie zostanie przemierzona, a Eric pozostanie z lķniącym nowym mieczem w rękach. Cóŋ, to jest to; zobaczmy teraz, jak to zrobiæ.
Realizacja
Hierarchie obiektów zagnieŋdŋonych, takie jak te wymagane do wdroŋenia hierarchicznych agentów opartych na celach, są często spotykane w oprogramowaniu. Na przykģad edytory tekstu, takie jak te, których uŋywam do pisania dokumentów z księgarni jako kolekcje elementów atomowych i kompozytowych. Najmniejsze elementy, znaki alfanumeryczne, są pogrupowane w coraz bardziej zģoŋone kolekcje. Na przykģad sģowo "filozofia" jest zģoŋonym skģadnikiem zģoŋonym z kilku skģadników atomowych, a zdanie "Myķlę, ŋe dlatego jestem" jest zģoŋonym skģadnikiem zģoŋonym z trzech obiektów zģoŋonych i dwóch obiektów atomowych. Z kolei zdania moŋna grupowaæ w obiekty akapitowe, które moŋna grupowaæ w strony i tak dalej. Jestem pewien, ŋe masz pomysģ. Naleŋy zauwaŋyæ, ŋe aplikacja jest w stanie równomiernie obsģugiwaæ obiekty zģoŋone i atomowe, niezaleŋnie od ich wielkoķci i zģoŋonoķci - tak samo ģatwo jest wyciąæ i wkleiæ sģowo, jak kilka stron tekstu. Jest to dokģadnie wģaķciwoķæ wymagana przez cele hierarchiczne. Ale jak to kodujemy? Zģoŋony wzór projektowy stanowi rozwiązanie. Dziaģa poprzez zdefiniowanie abstrakcyjnej klasy bazowej, która reprezentuje zarówno obiekty zģoŋone, jak i atomowe. Umoŋliwia to klientom identyczne manipulowanie wszystkimi celami, bez względu na to, jak proste lub zģoŋone mogą byæ.
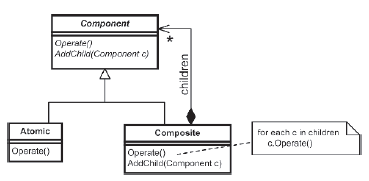
Na rysunku wyražnie pokazano, w jaki sposób obiekty kompozytowe agregują instancje komponentów, które z kolei mogą byæ kompozytowe lub atomowe. Zwróæ uwagę, w jaki sposób obiekty zģoŋone przekazują ŋądania klientów do swoich dzieci. W tym archetypowym przykģadzie ŋądania są przekazywane wszystkim dzieciom. Jednak inne projekty mogą wymagaæ nieco innej implementacji, jak ma to miejsce w przypadku celów. Rysunek pokazuje zģoŋony wzór zastosowany do projektowania celów hierarchicznych. Subgoale są dodawane przez popchnięcie ich na przód pojemnika subgoal i są przetwarzane w kolejnoķci LIFO (ostatnie wejķcie, pierwsze wyjķcie) w w taki sam sposób jak struktura danych podobna do stosu. Zwróæ uwagę, w jaki sposób ŋądania klientów są przekazywane tylko do subgoalu z przodu, zapewniając, ŋe subgoale są oceniane w kolejnoķci
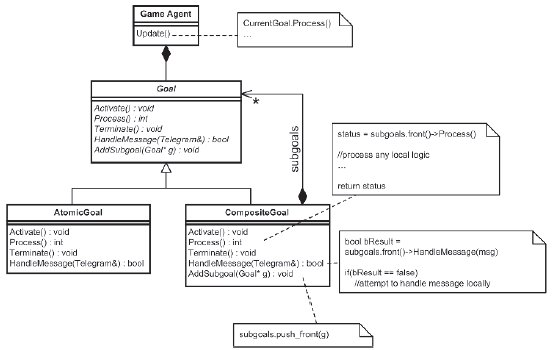
Obiekty bramkowe mają wiele podobieņstw z klasą State. Mają metodę obsģugi wiadomoķci, podobnie jak metody Stan, Aktywuj, Przetwarzaj i Zakoņcz, które mają podobieņstwa z metodami wprowadzania, wykonywania i wychodzenia stanu. Metoda Activate zawiera logikę inicjalizacji i reprezentuje fazę planowania celu. Jednak w przeciwieņstwie do metody State :: Enter, która jest wywoģywana tylko raz, gdy stan staje się aktualny, cel moŋe wywoģywaæ metodę Activate dowolną liczbę razy, aby wykonaæ operację ponownie, jeķli sytuacja tego wymaga. Proces, który jest wykonywany na kaŋdym etapie aktualizacji, zwraca wyliczoną wartoķæ wskazującą status celu. Moŋe to byæ jedna z czterech wartoķci:
• nieaktywne: Cel czeka na aktywację.
• aktywne: cel zostaģ aktywowany i będzie przetwarzany na kaŋdym etapie aktualizacji.
• zakoņczone: cel zostaģ osiągnięty i zostanie usunięty przy następnej aktualizacji.
• nie powiodģo się: cel nie powiódģ się i zostanie ponownie wyķwietlony lub usunięty przy następnej aktualizacji.
Metoda Terminate wykonuje wszelkie niezbędne porządki przed wyjķciem z bramki i jest wywoģywana tuŋ przed zniszczeniem bramki. W praktyce częķæ logiki zaimplementowanej przez cele kompozytowe jest wspólna dla wszystkich kompozytów i moŋna ją wyodrębniæ do klasy Goal_Composite, z której wszystkie konkretne cele kompozytowe mogą odziedziczyæ, w wyniku czego ostateczny projekt przedstawiono na rysunku 9.7. Diagramy UML dobrze opisują hierarchię klas celów. Nie będę marnowaæ papieru na listę ich deklaracji, ale myķlę, ŋe będzie pomocne, jeķli wymienię žródģo kilku metod Goal_Composite.
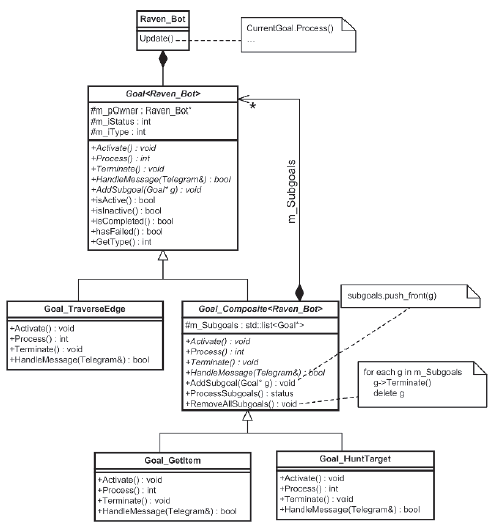
Goal_Composite :: ProcessSubgoals
Wszystkie zģoŋone cele nazywają tę metodę kaŋdym krokiem aktualizacji, aby przetworzyæ swoje podzadania. Metoda zapewnia, ŋe wszystkie zrealizowane i nieudane cele zostaną usunięte z listy przed przetworzeniem następnego podpolecenia w linii i zwróceniem jego statusu. Jeķli lista podrzędnych celów jest pusta, zakoņczona jest zwracana.
template < class entity_type >
int Goal_Composite
// usuņ wszystkie ukoņczone i nieudane bramki z przodu listy podrzędnej
while (!m_SubGoals.empty() &&
(m_SubGoals.front()->isComplete() || m_SubGoals.front()->hasFailed()))
{
m_SubGoals.front()->Terminate();
delete m_SubGoals.front();
m_SubGoals.pop_front();
}
// jeķli pozostaną jakieķ podzadania, przetworz to z przodu listy
if (!m_SubGoals.empty())
{
// chwyæ status czoģowego podrzędu
int StatusOfSubGoals = m_SubGoals.front()->Process();
// musimy przetestowaæ w specjalnym przypadku, w którym subgoal z przodu jest
// zgģasza "ukoņczono", a lista podrzędnych celów zawiera dodatkowe cele.
// W takim przypadku, aby upewniæ się, ŋe rodzic nadal przetwarza swoje
// lista podrzędna, zwracany jest status "aktywny"
if (StatusOfSubGoals == completed && m_SubGoals.size() > 1)
{
return active;
}
return StatusOfSubGoals;
}
// nie ma juŋ poddaņ do przetworzenia - zwróæ "zakoņczone"
else
{
return completed;
}
}
Goal_Composite::RemoveAllSubgoals
Ta metoda usuwa listę podrzędną. Zapewnia, ŋe wszystkie podzadania są niszczone, wywoģując metodę Terminate kaŋdego z nich przed usunięciem.
template
void Goal_Composite
{
for (SubgoalList::iterator it = m_SubGoals.begin();
it != m_SubGoals.end();
++it)
{
(*it)->Terminate();
delete *it;
}
m_SubGoals.clear();
}
UWAGA. Niektórzy z was mogą się zastanawiaæ, w jaki sposób cele atomowe implementują metodę AddSubgoal. W koņcu ta metoda jest bez znaczenia w tym kontekķcie (poniewaŋ cel atomowy nie moŋe z definicji agregowaæ celów potomnych), ale wciąŋ musi zostaæ zaimplementowany w celu zapewnienia wymaganego wspólnego interfejsu. Poniewaŋ klienci powinni wiedzieæ, czy cel jest zģoŋony, czy nie, i dlatego nie powinni nigdy wywoģywaæ AddSubgoal w celu atomowym, wybraģem metodę zgģaszania wyjątku
Przykģady celów uŋywanych przez Raven Bots
Boty Raven wykorzystują cele wymienione w Tabeli do zdefiniowania swojego zachowania.
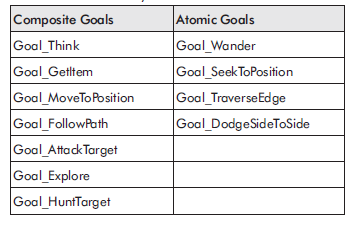
Goal_Think jest najwyŋszym celem wszystkich. Kaŋdy bot tworzy kopię tego celu, która trwa do momentu zniszczenia bota. Jego zadaniem jest wybieranie innych celów wysokiego poziomu (strategicznych) zgodnie z ich przydatnoķcią do aktualnego stanu gry. Niedģugo przyjrzymy się bliŋej Goal_Think, ale najpierw myķlę, ŋe dobrym pomysģem będzie zbadanie kodu kilku innych celów, abyķ mógģ poznaæ ich dziaģanie.
Goal_Wander
To najģatwiejszy do zrozumienia cel i najprostszy w palecie bota Raven. Jest to cel atomowy, który aktywuje zachowanie kierowania wędrówką. Oto jego deklaracja.
class Goal_Wander : public Goal< Raven_Bot >
{
public:
Goal_Wander(Raven_Bot* pBot):Goal
// musi zostaæ wdroŋony
void Activate();
int Process();
void Terminate();
};
Jak widaæ, deklaracja jest bardzo prosta. Klasa dziedziczy po celu i ma metody, które implementują interfejs celu. Rzuæmy okiem na kaŋdą z kolei po kolei.
void Goal_Wander::Activate()
{
m_Status = active;
m_pOwner->GetSteering()->WanderOn();
}
Metoda Active po prostu wģącza zachowanie kierowania wędrówką (patrz rozdziaģ 3, jeķli potrzebujesz odķwieŋenia) i ustawia status celu na aktywny.
int Goal_Wander::Process()
{
// jeķli status jest nieaktywny, wywoģaj Activate () i ustaw status na active
ActivateIfInactive();
return m_Status;
}
Goal_Wander :: Process jest równie prosty. ActivateIfInactive is wywoģywane na początku logiki procesów kaŋdego celu. Jeķli status celu jest nieaktywny (jak zawsze będzie to pierwsze wywoģanie Procesu, poniewaŋ m_Status jest ustawiony jako nieaktywny w konstruktorze), wywoģywana jest metoda Akctive, tym samym inicjując cel. Wreszcie metoda Terminate wyģącza zachowanie wędrówki.
void Goal_Wander::Terminate()
{
m_pOwner->GetSteering()->WanderOff();
}
Teraz przeanalizujmy bardziej zģoŋony cel atomowy
Goal_TraverseEdge
To kieruje bota wzdģuŋ krawędzi ķcieŋki i stale monitoruje jego postępy, aby upewniæ się, ŋe nie utknie. Aby to uģatwiæ, wraz z lokalną kopią krawędzi ķcieŋki, posiada ona czģonków danych do rejestrowania czasu aktywacji celu i czasu, jaki bot ma zająæ pokonanie krawędzi. Jest takŋe wģaķcicielem logicznego elementu danych, który rejestruje, czy krawędž jest ostatnią na ķcieŋce. Ta wartoķæ jest potrzebna do okreķlenia, jakie zachowanie kierownicze naleŋy zastosowaæ, aby przejķæ przez krawędž (szukaj normalnych krawędzi ķcieŋki, dotrzyj do ostatniej). Oto jego deklaracja:
class Goal_TraverseEdge : public Goal< Raven_Bot >
{
private:
// krawędž, którą podąŋy bot
PathEdge m_Edge;
// true, jeķli m_Edge jest ostatnim na ķcieŋce
bool m_bLastEdgeInPath;
// szacowany czas, przez który bot powinien przejķæ przez krawędž
double m_dTimeExpected;
// rejestruje czas aktywacji tego celu
double m_dStartTime;
// wraca true, jeķli bot utknie
bool isStuck()const;
public:
Goal_TraverseEdge(Raven_Bot* pBot,
PathEdge edge,
bool LastEdge);
// Podejrzani
void Activate();
int Process();
void Terminate();
};
Przed okreķleniem szacunkowego czasu potrzebnego do przejķcia, metoda Aktywuj wysyģa zapytanie do pola flagi krawędzi wykresu, aby ustaliæ, czy jest z nim powiązany jakiķ specjalny rodzaj terenu - bģoto, ķnieg, woda itp. - a zachowanie bota odpowiednio się zmienia . (Ta funkcja nie jest uŋywana przez Raven, ale chciaģem pokazaæ, jak sobie z nią poradziæ, jeķli Twoja gra korzysta z okreķlonych typów terenu). Metoda koņczy się kodem aktywującym odpowiednie zachowanie kierowania. Oto žródģo:
void Goal_TraverseEdge::Activate()
{
m_Status = active;
// flaga zachowania krawędzi moŋe okreķlaæ rodzaj ruchu, który wymaga znaku
// zmiana zachowania bota podąŋającego za tą krawędzią
switch(m_Edge.GetBehaviorFlag())
{
case NavGraphEdge::swim:
{
m_pOwner->SetMaxSpeed(script->GetDouble("Bot_MaxSwimmingSpeed"));
// ustawiæ odpowiednią animację
}
break;
case NavGraphEdge::crawl:
{
m_pOwner->SetMaxSpeed(script->GetDouble("Bot_MaxCrawlingSpeed"));
// ustawiæ odpowiednią animację
}
break;
}
// rejestruj czas, w którym bot rozpoczyna ten cel
m_dStartTime = Clock->GetCurrentTime();
// obliczyæ oczekiwany czas wymagany do osiągnięcia tego punktu. Ta wartoķæ
// sģuŋy do okreķlenia, czy bot utknąģ
m_dTimeExpected =
m_pOwner->CalculateTimeToReachPosition(m_Edge.GetDestination());
// uwzględni margines bģędu dla kaŋdego zachowania reaktywnego. 2 sekundy
// powinno byæ duŋo
static const double MarginOfError = 2.0;
m_dTimeExpected += MarginOfError;
// ustawiæ cel sterowania
m_pOwner->GetSteering()->SetTarget(m_Edge.GetDestination());
// Ustaw odpowiednie zachowanie kierowania. Jeķli to ostatnia krawędž ķcieŋki
// bot powinien dotrzeæ do pozycji, na którą wskazuje, w przeciwnym razie powinien szukaæ
if (m_bLastEdgeInPath)
{
m_pOwner->GetSteering()->ArriveOn();
}
else
{
m_pOwner->GetSteering()->SeekOn();
}
}
Po aktywowaniu celu przetworzenie go jest proste. Za kaŋdym razem, gdy wywoģywana jest metoda Process, kod sprawdza, czy bot utknąģ lub osiągnąģ koniec krawędzi i odpowiednio ustawia m_Status
int Goal_TraverseEdge::Process()
{
// jeķli status jest nieaktywny, wywoģaj Activate ()
ActivateIfInactive();
// jeķli bot utknąģ, bģąd powrotu
if (isStuck())
{
m_Status = failed;
}
// jeķli bot osiągnąģ koniec krawędzi powrót jest zakoņczony
else
{
if (m_pOwner->isAtPosition(m_Edge.GetDestination()))
{
m_Status = completed;
}
}
return m_Status;
}
Metoda Terminate wyģącza zachowanie kierownicy i resetuje maksymalną prędkoķæ bota do normy.
void Goal_TraverseEdge::Terminate()
{
// wyģącz zachowania kierownicze
m_pOwner->GetSteering()->SeekOff();
m_pOwner->GetSteering()->ArriveOff();
// przywróciæ maksymalną prędkoķæ do normy
m_pOwner->SetMaxSpeed(script->GetDouble("Bot_MaxSpeed"));
}
Przejdžmy teraz do zbadania kilku zģoŋonych celów
Goal_FollowPath
To kieruje bota wzdģuŋ ķcieŋki poprzez wielokrotne wyskakiwanie krawędzi z przodu ķcieŋki i wypychanie celów typu krawędzi trawersowania na przód listy podrzędnej. Oto jego deklaracja:
class Goal_FollowPath : public Goal_Composite< Raven_Bot >
{
private:
// lokalna kopia ķcieŋki zwrócona przez narzędzie do planowania ķcieŋki
std::list
public:
Goal_FollowPath(Raven_Bot* pBot, std::list
//podejrzani
void Activate();
int Process();
void Terminate(){}
}
Oprócz powiązania z nimi okreķlonych typów terenu, krawędzie wykresów mogą równieŋ wymagaæ od bota uŋycia okreķlonej akcji do poruszania się wzdģuŋ nich. Na przykģad krawędž moŋe wymagaæ od agenta latania, skakania, a nawet uŋywania haka do chwytania, aby poruszaæ się wzdģuŋ niej. Tego rodzaju ograniczenia ruchu nie moŋna rozwiązaæ, po prostu dostosowując maksymalną prędkoķæ i cykl animacji agenta. Zamiast tego dla kaŋdej akcji naleŋy utworzyæ unikalny cel typu krawędzi poprzecznych. Cel podąŋania ķcieŋką moŋe następnie sprawdzaæ flagi krawędzi w ramach metody Aktywuj i dodawaæ poprawny typ celu krawędzi trawersu do swojej listy podrzędnej, gdy wyskakuje z ķcieŋki. Aby to wyjaķniæ, oto lista metod aktywacji:
void Goal_FollowPath::Activate()
{
m_iStatus = active;
// uzyskaæ odniesienie do następnej krawędzi
PathEdge edge = m_Path.front();
// usuņ krawędž ze ķcieŋki
m_Path.pop_front();
// niektóre krawędzie okreķlają, ŋe bot powinien uŋywaæ okreķlonego zachowania, gdy
//podąŋaæ za nimi. Ta instrukcja switch pyta o flagę zachowania krawędzi i
// dodaje odpowiednie cele do listy celów cząstkowych.
switch(edge.GetBehaviorFlags())
{
case NavGraphEdge::normal:
{
AddSubgoal(new Goal_TraverseEdge(m_pOwner, edge, m_Path.empty()));
}
break;
case NavGraphEdge::goes_through_door:
{
// also add a goal that is able to handle opening the door
AddSubgoal(new Goal_NegotiateDoor(m_pOwner, edge, m_Path.empty()));
}
break;
case NavGraphEdge::jump:
{
// dodaj subcel, aby przeskoczyæ wzdģuŋ krawędzi
}
break;
case NavGraphEdge::grapple:
{
// dodaj subgoal, aby chwyciæ się wzdģuŋ krawędzi
}
break;
default:
throw
std::runtime_error("
Aby zwiększyæ wydajnoķæ, zauwaŋ, jak tylko jedna krawędž jest usuwana na raz ze ķcieŋki. Aby to uģatwiæ, metoda Process wywoģuje Aktywuj za kaŋdym razem, gdy wykryje, ŋe jej podzadania są zakoņczone, a ķcieŋka nie jest pusta. Oto jak:
int Goal_FollowPath::Process()
{
// jeķli status jest nieaktywny, wywoģaj Activate ()
ActivateIfInactive();
// jeķli nie ma podzadaņ i nadal istnieje krawędž do przejķcia, dodaj
// krawędž jako subgoal
m_Status = ProcessSubgoals();
// jeķli nie ma ŋadnych podzadaņ, sprawdž, czy ķcieŋka nadal ma krawędzie.
// jeķli wywoģa Aktywację, aby zģapaæ następną krawędž.
if (m_Status == completed && !m_Path.empty())
{
Activate();
}
return m_Status;
}
Metoda Goal_FollowPath :: Terminate nie zawiera logiki, poniewaŋ nie ma nic do uporządkowania.
PORADA. Po uruchomieniu pliku wykonywalnego Raven istnieje moŋliwoķæ wyķwietlenia listy celów wybranego agenta w menu.
Rysunek jest w skali szaroķci, ale po uruchomieniu demonstracji aktywne cele zostaną narysowane na niebiesko, zakoņczone na zielono, nieaktywne na czarno i nieudane na czerwono. Wcięcie pokazuje, w jaki sposób cele są zagnieŋdŋone.
Goal_MoveToPosition
Ten zģoŋony cel sģuŋy do przeniesienia bota w dowolne miejsce na mapie. Oto jego deklaracja:
bool Goal_MoveToPosition::HandleMessage(const Telegram& msg)
{
//first, pass the message down the goal hierarchy
bool bHandled = ForwardMessageToFrontMostSubgoal(msg);
// jeķli msg nie zostaģ obsģuŋony, sprawdž, czy ten cel sobie z tym poradzi
if (bHandled == false)
{
switch(msg.Msg)
{
case Msg_PathReady:
// wyczyķæ wszystkie istniejące cele
RemoveAllSubgoals();
AddSubgoal(new Goal_FollowPath(m_pOwner,
m_pOwner->GetPathPlanner()->GetPath()));
return true; // msg obsģugiwane
case Msg_NoPathAvailable:
m_Status = failed;
return true; // msg obsģugiwane
default: return false;
}
}
// obsģugiwane przez subgoals
return true;
}
Subgoale Goal_MoveToPosition są przetwarzane i stale monitorowane pod kątem awarii. Jeķli jeden z podzadaņ nie powiedzie się, cel ten reaktywuje się w celu przeplanowania.
int Goal_MoveToPosition::Process()
{
// jeķli status jest nieaktywny, wywoģaj Activate () i ustaw status na active
ActivateIfInactive();
// przetwarzaæ podzadania
m_Status = ProcessSubgoals();
// jeķli którykolwiek z podzadaņ nie powiódģ się, cel ten zostanie ponownie ustawiony
ReactivateIfFailed();
return m_Status;
}
Przejdžmy teraz do sprawdzenia, jak dziaģa jeden z pozostaģych celów na poziomie strategii: Goal_AttackTarget.
Goal_AttackTarget
Bot wybiera tę strategię, gdy czuje się zdrowy i wystarczająco uzbrojony, aby zaatakowaæ swój obecny cel. Goal_AttackTarget jest celem zģoŋonym, a jego deklaracja jest prosta.
class Goal_AttackTarget : public Goal_Composite
{
public:
Goal_AttackTarget(Raven_Bot* pOwner);
void Activate();
int Process();
void Terminate(){m_iStatus = completed;}
};
Caģa akcja dzieje się w metodzie Aktywuj. Przede wszystkim wszelkie istniejące podzadania są usuwane, a następnie sprawdzane, czy cel bota jest nadal aktualny. Jest to niezbędne, poniewaŋ cel moŋe zginąæ lub wyjķæ poza horyzont sensoryczny bota, gdy ten cel jest nadal aktywny. W takim przypadku cel musi zakoņczyæ się.
void Goal_AttackTarget::Activate()
{
m_iStatus = active;
// jeķli ten cel zostanie ponownie aktywowany, mogą istnieæ pewne podzadania, które
// naleŋy usunąæ
RemoveAllSubgoals();
// cel bota moŋe umrzeæ, gdy ten cel jest aktywny, więc my
// naleŋy przetestowaæ, aby upewniæ się, ŋe bot zawsze ma aktywny cel
if (!m_pOwner->GetTargetSys()->isTargetPresent())
{
m_iStatus = completed;
return;
}
Następnie bot sprawdza swój system celowania, aby dowiedzieæ się, czy ma bezpoķredni strzaģ w cel. Jeķli strzaģ jest moŋliwy, wybiera taktykę ruchu, którą naleŋy zastosowaæ. Pamiętaj, ŋe system broni jest caģkowicie oddzielnym skģadnikiem sztucznej inteligencji i zawsze automatycznie wybiera najlepszą broņ, celuje i strzela do bieŋącego celu, bez względu na cel, do którego dąŋy bot. Oznacza to, ŋe ten cel musi jedynie dyktowaæ ruch bota podczas ataku. Udostępniģem botom Raven tylko dwie moŋliwoķci: jeķli po lewej lub prawej stronie bota jest miejsce, będzie on toczyģ się z boku na bok, dodając Goal_DodgeSideToSide do swojej listy podrzędnej. Jeķli nie ma miejsca na unik, bot po prostu szuka aktualnej pozycji celu.
// jeķli bot jest w stanie strzeliæ do celu (między botem a LOS jest LOS)
// cel), a następnie wybierz taktykę, którą chcesz zastosowaæ podczas strzelania
if (m_pOwner->GetTargetSys()->isTargetShootable())
{
// jeķli bot ma miejsce na atak, zrób to
Vector2D dummy;
if (m_pOwner->canStepLeft(dummy) || m_pOwner->canStepRight(dummy))
{
AddSubgoal(new Goal_DodgeSideToSide(m_pOwner));
}
// jeķli nie jest w stanie atakowaæ, skieruj się bezpoķrednio na pozycję celu
else
{
AddSubgoal(new Goal_SeekToPosition(m_pOwner,
m_pOwner->GetTargetBot()->Pos()));
}
}
W zaleŋnoķci od wymagaņ twojej gry prawdopodobnie będziesz chciaģ daæ botowi znacznie szerszy wybór taktyk agresywnego ruchu do wyboru. Na przykģad, moŋesz chcieæ dodaæ taktykę, która przenosi bota do idealnego zasięgu do strzelania jego prądem (lub ulubiona) broņ lub taka, która wybiera dobrą pozycję snajperską lub osģonową (nie zapominaj, ŋe węzģom nawigacyjnym moŋna przypisaæ takie informacje). Jeķli nie ma bezpoķredniego strzaģu w cel - poniewaŋ mógģ on wģaķnie biegaæ za rogiem - bot dodaje Goal_HuntTarget do swojej listy podrzędnej. Metoda Process dla Goal_AttackTarget jest trywialna. Po prostu upewnia się, ŋe podzadania są przetwarzane, a cel zostanie ponownie zainstalowany w przypadku wykrycia problemu
int Goal_AttackTarget::Process()
{
// jeķli status jest nieaktywny, wywoģaj Activate()
ActivateIfInactive();
// przetwarzaæ podzadania
m_iStatus = ProcessSubgoals();
ReactivateIfFailed();
return m_iStatus;
}
Nie będę wchodziģ w szczegóģy Goal_HuntTarget i Goal_Dodge-SideToSide. To oczywiste, co robią i zawsze moŋesz sprawdziæ kod žródģowy, jeķli chcesz spojrzeæ na drobiazgi.
Arbitraŋ celi
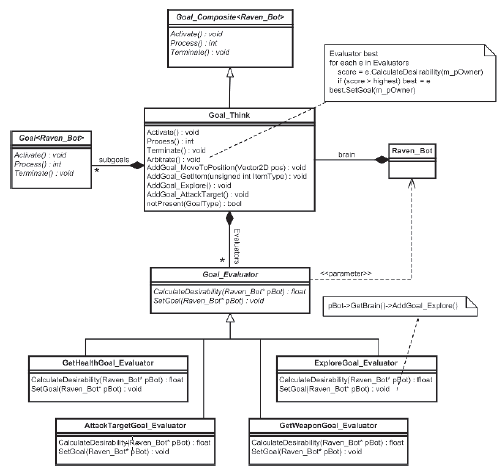
Teraz rozumiesz, jak dziaģają cele i widziaģeķ kilka konkretnych przykģadów, ale prawdopodobnie nadal zastanawiasz się, w jaki sposób boty wybierają cele na poziomie strategii. Osiąga się to dzięki zģoŋonemu celowi Goal_Think, którego kaŋdy bot posiada trwaģą instancję, stanowiącą podstawę jego hierarchii celów. Funkcja Goal_Think polega na arbitraŋu między dostępnymi strategiami, wybierając najbardziej odpowiednie do realizacji. Jest szeķæ strategicznych celów:
• Explore : Agent wybiera dowolny punkt w swoim ķrodowisku i planuje i podąŋa ķcieŋką do tego punktu.
• Get Health: Agent znajduje ķcieŋkę o najniŋszym koszcie do wystąpienia przedmiotu zdrowia i podąŋa ķcieŋką do tego przedmiotu.
• Get Weapon (Rocket Launcher): Agent znajduje ķcieŋkę o najniŋszym koszcie do instancji wyrzutni rakiet i podąŋa za nią.
• Get Weapon (Shotgun): Agent znajduje ķcieŋkę o najniŋszym koszcie do wystąpienia strzelby i podąŋa za nią.
• Get Weapon (Railgun): Agent znajduje ķcieŋkę o najniŋszym koszcie do instancji Railguna i podąŋa za nią.
• Attack Target: Agent okreķla strategię ataku na swój obecny cel.
Kaŋda aktualizacja myķli kaŋda z tych strategii jest oceniana i otrzymuje wynik reprezentujący celowoķæ jej realizacji. Strategia o najwyŋszym wyniku jest przypisywana do strategii, którą agent będzie próbowaģ speģniæ. Aby uģatwiæ ten proces, kaŋdy Goal_Think agreguje kilka instancji Goal_Evaluator, po jednej dla kaŋdej strategii. Obiekty te mają metody obliczania poŋądanej strategii, którą reprezentują, oraz dodawania tego celu do listy podrzędnych celów. R
Kaŋda metoda CalculateDesirability to ręcznie wykonany algorytm, który zwraca wartoķæ wskazującą na celowoķæ bota realizującego odpowiednią strategię. Algorytmy te mogą byæ trudne do utworzenia, dlatego często przydatne jest najpierw skonstruowanie niektórych funkcji pomocniczych, które odwzorowują okreķlone informacje z gry na wartoķci liczbowe w zakresie od 0 do 1. Są one następnie wykorzystywane w formuģowaniu algorytmów poŋądalnoķci. Nie jest szczególnie waŋne, jaki zakres wartoķci zwracają metody wyodrębniania obiektów - od 0 do 1, od 0 do 100 lub od -10000 do 1000 są w porządku - ale pomaga, jeķli są one znormalizowane we wszystkich metodach. Uģatwi to mózg, gdy zaczniesz tworzyæ algorytmy poŋądania. Aby zdecydowaæ, jakie informacje naleŋy pobraæ ze ķwiata gry, rozwaŋ kolejno kaŋdy cel strategii i jakie cechy gry mają wpģyw na celowoķæ jego realizacji. Na przykģad ocena GetHealth będzie wymagaģa informacji o stanie zdrowia bota i lokalizacji przedmiotu zdrowia. Podobnie ewaluator AttackTarget będzie wymagaģ informacji o broni i amunicji, którą nosi bot, oprócz jego poziomów zdrowia (bot o niskim poziomie zdrowia znacznie rzadziej zaatakuje przeciwnika niŋ bot, który czuje się sprawny jako skrzypce). Ewaluator ExploreGoal to szczególny przypadek, jak się wkrótce okaŋe, ale ewaluator GetWeapon będzie wymagaģ dodatkowej wiedzy na temat odlegģoķci do okreķlonej broni i aktualnej amunicji, którą ma przy sobie bot. Raven uŋywa czterech takich funkcji ekstrakcji funkcji, zaimplementowanych jako metody statyczne klasy Raven_Feature. Oto lista deklaracji klasy, która zawiera opis kaŋdej metody w komentarzach:
class Raven_Feature
{
public:
// zwraca wartoķæ od 0 do 1 w oparciu o zdrowie bota. Im lepsze
// zdrowie, tym wyŋsza ocena
static double Health(Raven_Bot* pBot);
// zwraca wartoķæ od 0 do 1 na podstawie odlegģoķci bota do
// dany element. Im dalej przedmiot, tym wyŋsza ocena. Jeķli nie ma
// przedmiot danego typu obecny w ķwiecie gry w czasie tej metody
// nazywa się zwracana wartoķæ to 1
static double DistanceToItem(Raven_Bot* pBot, int ItemType);
// zwraca wartoķæ od 0 do 1 w oparciu o iloķæ amunicji dla bota
// dana broņ i maksymalna iloķæ amunicji, którą bot moŋe nosiæ.
// im bliŋej przenoszonej kwoty do kwoty maksymalnej, tym wyŋszy wynik
static double IndividualWeaponStrength(Raven_Bot* pBot, int WeaponType);
// zwraca wartoķæ od 0 do 1 w oparciu o caģkowitą iloķæ amunicji
// bot przenosi kaŋdą broņ. Kaŋda z trzech broni to bot
// moŋe podnieķæ moŋe przyczyniæ się do uzyskania trzeciej częķci wyniku. Innymi sģowy, jeķli bot
// nosi RL i RG i ma maksymalną amunicję do RG, ale tylko poģowę max
// dla RL ocena będzie wynosiæ 1/3 + 1/6 + 0 = 0,5
static double TotalWeaponStrength(Raven_Bot* pBot);
};
Teraz, gdy mamy kilka funkcji pomocniczych, przyjrzyjmy się, jak moŋna ich uŋyæ do obliczenia wyników poŋądalnoķci dla kaŋdej strategii, które są równieŋ standaryzowane w zakresie od 0 do 1.
Obliczanie celowoķci zlokalizowania przedmiotu zdrowia
Ogólnie rzecz biorąc, celowoķæ zlokalizowania przedmiotu zdrowia jest proporcjonalna do obecnego poziomu zdrowia bota i odwrotnie proporcjonalna do odlegģoķci od najbliŋszej instancji. Poniewaŋ kaŋda z tych funkcji jest wyodrębniana metodami omówionymi wczeķniej i reprezentowana jako liczba z zakresu od 0 do 1, moŋna to zapisaæ jako:
Celowoķæhealth = (1 - Health / DistToHealth)
gdzie k jest staģą uŋywaną do poprawiania wyniku. Ta relacja ma sens, poniewaŋ im dalej musisz podróŋowaæ, aby znaležæ przedmiot, tym mniej go pragniesz, a im niŋszy poziom zdrowia, tym większe twoje pragnienie. (Zauwaŋ, ŋe nie musimy się martwiæ bģędem dzielenia przez zero, poniewaŋ agent nie moŋe zbliŋyæ się do promienia poza jego promieņ ograniczający, zanim element zostanie wyzwolony.) Oto kod žródģowy z Raven, który implementuje to algorytm.
double GetHealthGoal_Evaluator::CalculateDesirability(Raven_Bot* pBot)
{
// najpierw zģap odlegģoķæ do najbliŋszego wystąpienia przedmiotu zdrowia
double Distance = Raven_Feature::DistanceToItem(pBot, type_health);
// jeķli funkcja odlegģoķci ma wartoķæ 1, oznacza to, ŋe
// element nie znajduje się na mapie lub jest zbyt daleko, aby byģ wart
// biorąc pod uwagę, dlatego poŋądana jest wartoķæ zero
if (Distance == 1)
{
return 0;
}
else
{
// wartoķæ uŋyta do ulepszenia poŋądalnoķci
const double Tweaker = 0.2;
// celowoķæ znalezienia przedmiotu zdrowia jest proporcjonalna do kwoty
// zdrowie pozostające i odwrotnie proporcjonalne do odlegģoķci od zdjęcia
// najbliŋsza instancja elementu zdrowia.
double Desirability = Tweaker * (1-Raven_Feature::Health(pBot)) /
(Raven_Feature::DistanceToItem(pBot, type_health));
// upewnij się, ŋe wartoķæ mieķci się w zakresie od 0 do 1
Clamp(Desirability, 0, 1);
return Desirability;
}
}
Obliczanie celowoķci zlokalizowania okreķlonej broni
Jest to bardzo podobne do poprzedniego algorytmu. Celowoķæ zlokalizowania okreķlonej broni moŋna podaæ jako:
Celowoķæweapons = k x ( Health x (1-WeaponStrength) / DistToWeapon)
Zwróæ uwagę, w jaki sposób zarówno siģa broni, jak i funkcje zdrowotne przyczyniają się do potrzeby odzyskania broni. Jest to rozsądne, poniewaŋ w miarę jak bot zostaje powaŋnie uszkodzony lub iloķæ amunicji, którą nosi dla tej konkretnej broni, jego chęæ odzyskania powinna się zmniejszyæ. Oto jak algorytm wygląda w kodzie:
double GetWeaponGoal_Evaluator::CalculateDesirability(Raven_Bot* pBot)
{
// zģap odlegģoķæ do najbliŋszego wystąpienia typu broni
double Distance = Raven_Feature::DistanceToItem(pBot, m_iWeaponType);
// jeķli funkcja odlegģoķci ma wartoķæ 1, oznacza to, ŋe
// element nie znajduje się na mapie lub jest zbyt daleko, aby byģ wart
// biorąc pod uwagę, dlatego poŋądana jest wartoķæ zero
if (Distance == 1)
{
return 0;
}
else
{
// wartoķæ uŋyta do ulepszenia poŋądalnoķci
const double Tweaker = 0.15f;
double Health, WeaponStrength;
Health = Raven_Feature::Health(pBot);
WeaponStrength = Raven_Feature::IndividualWeaponStrength(pBot, m_iWeaponType);
double Desirability = (Tweaker * Health * (1-WeaponStrength)) / Distance;
// wartoķæ uŋyta do ulepszenia poŋądalnoķci br>
Clamp(Desirability, 0, 1);
return Desirability;
}
}
Dodatkową zaletą wykorzystania odlegģoķci jako czynnika do obliczenia celowoķci przy podnoszeniu broni i przedmiotów zdrowotnych jest to, ŋe w odpowiednich okolicznoķciach boty tymczasowo zmieniają strategię i zmieniają kurs, aby podnieķæ przedmioty w pobliŋu
WSKAZÓWKA. Wpģyw odlegģoķci w analizowanych do tej pory algorytmach poŋądania jest liniowy. Innymi sģowy, poŋądalnoķæ jest wprost proporcjonalna do odlegģoķci od przedmiotu. Moŋesz jednak chcieæ, aby "przyciąganie" przedmiotu na bocie stawaģo się silniejsze w miarę zbliŋania się bota (jak siģa, którą odczuwasz, gdy przesuwasz dwa magnesy ku sobie), zamiast ze staģą szybkoķcią (np. Siģa czujesz, kiedy naciągasz spręŋynę). Najlepiej to wyjaķniæ za pomocą wykresu.
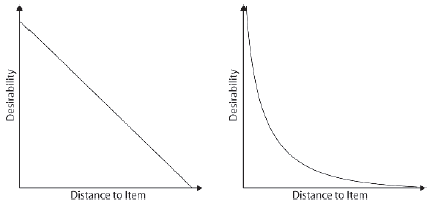
Aby utworzyæ algorytm, który tworzy krzywą poŋądania-odlegģoķci podobną do wykresu po prawej, musisz podzieliæ przez kwadrat (lub nawet szeķcian) odlegģoķci. Innymi sģowy, równanie zmienia się na:
Celowoķæweapons = k x ( Health x (1-WeaponStrength) /DistToWeapon2)
Nie zapominaj, ŋe będziesz musiaģ równieŋ dostosowaæ k, aby uzyskaæ poŋądane wyniki.
Obliczanie celowoķci ataku na cel
Celowoķæ zaatakowania przeciwnika jest proporcjonalna do tego, jak zdrowy i silny jest bot. "Potęŋna" funkcja, w kontekķcie Kruka, wskazuje liczbę broni i amunicji, którą nosi bot, i jest oceniana za pomocą metody Raven_Feature :: TotalWeaponStrength. (Polecam zajrzeæ do tej metody następnym razem, gdy będziesz siedzieæ przy komputerze). Korzystając z tych dwóch funkcji, moŋemy obliczyæ celowoķæ realizacji celu AttackTarget:
Celowoķæattack = k x TotalWeaponStrength x Health
Oto jak wygląda napisane w kodzie:
double AttackTargetGoal_Evaluator::CalculateDesirability(Raven_Bot* pBot)
{
double Desirability = 0.0;
// wykonuj obliczenia tylko wtedy, gdy istnieje cel
if (pBot->GetTargetSys()->isTargetPresent())
{
const double Tweaker = 1.0;
Desirability = Tweaker *
Raven_Feature::Health(pBot) *
Raven_Feature::TotalWeaponStrength(pBot);
}
return Desirability;
WSKAZÓWKA. W zaleŋnoķci od tego, jak bardzo potrzebujesz agenta, moŋesz dodawaæ i usuwaæ strategie z arbitra. (Pamiętaj, ŋe Goal_Think jest arbitrem celów strategicznych bota Raven.) Rzeczywiķcie, moŋesz nawet wģączaæ i wyģączaæ caģe zestawy celów strategicznych, aby zapewniæ agentowi zupeģnie nowy zestaw zachowaņ do wyboru. Far Cry na przykģad uŋywa tego rodzaju techniki z dobrym skutkiem.
Obliczanie celowoķci eksploracji mapy
To jest ģatwe. Wyobraž sobie, ŋe grasz w tę grę. Moŋesz eksplorowaæ mapę tylko wtedy, gdy nie ma innych rzeczy wymagających Twojej natychmiastowej uwagi, takich jak atakowanie przeciwnika lub poszukiwanie amunicji lub zdrowia. W konsekwencji celowoķæ eksploracji mapy jest ustalona jako niska staģa wartoķæ, dzięki czemu opcja eksploracji jest wybrana tylko wtedy, gdy wszystkie alternatywy mają niŋsze oceny celowoķci. Oto kod:
double ExploreGoal_Evaluator::CalculateDesirability(Raven_Bot* pBot)
{
const double Desirability = 0.05;
return Desirability;
}
Ģącząc wszystko razem
Po zdefiniowaniu funkcji celowoķci dla kaŋdego obiektu ewaluatora, pozostaje tylko to, aby Goal_Think przeprowadzaģ iterację przy kaŋdej aktualizacji myķli i wybieraģ najwyŋszą strategię, którą będzie realizowaģ bot. Oto kod wyjaķniający:
void Goal_Think::Arbitrate()
{
double best = 0;
Goal_Evaluator* MostDesirable = NULL;
// teruj przez wszystkich oceniających, aby zobaczyæ, który daje najwyŋszy wynik
GoalEvaluators::iterator curDes = m_Evaluators.begin();
for (curDes; curDes != m_Evaluators.end(); ++curDes)
{
double desirabilty = (*curDes)->CalculateDesirability(m_pOwner);
if (desirabilty >= best)
{
best = desirabilty;
MostDesirable = *curDes;
}
}
MostDesirable->SetGoal(m_pOwner);
}
WSKAZÓWKA. Gracze będący ludžmi mogą przewidywaæ, co zrobi inny gracz, i odpowiednio postępowaæ. Moŋemy to zrobiæ, poniewaŋ jesteķmy w stanie krótko zmieniæ punkt widzenia na innych graczy i zastanowiæ się, jakie mogą byæ ich pragnienia, jeķli rozumiemy ich stan i ķwiat gry. Oto przykģad: z dystansu obserwujesz dwóch graczy, Sid i Erica, walczących z wyrzutniami rakiet, gdy nagle, po dwukrotnym trafieniu z rzędu, Eric odrywa się i zaczyna biec korytarzem. Zmieniasz punkt widzenia na Erica, a poniewaŋ wiesz, ŋe ma maģo zdrowia, przewidujesz, ŋe bardzo prawdopodobne jest, ŋe zmierza w kierunku pakietu zdrowia, o którym wiesz, ŋe znajduje się w pokoju na koņcu korytarza. Zdajesz sobie równieŋ sprawę, ŋe jesteķ umieszczony bliŋej zdrowia niŋ Eric, więc decydujesz się go "ukraķæ" i odczekaæ, aŋ dotrze na miejsce, po czym wysmarujesz jego jelita wzdģuŋ ķciany karabinem plazmowym. Umiejętnoķæ przewidywania dziaģaņ innych w ten sposób jest wrodzoną cechą ludzkich zachowaņ - robimy to caģy czas - ale moŋliwe jest nadanie agentowi podobnej, choæ nieco osģabionej zdolnoķci. Poniewaŋ pragnienia agentów arbitraŋowych bramek są ustalane algorytmicznie, moŋesz sprawiæ, by bot uruchomiģ odpowiednie atrybuty (zdrowie, amunicję itp.) Gracza poprzez wģasny (lub niestandardowy) arbiter, aby zgadywaæ, jakie mogą byæ pragnienia gracza byæ w tym czasie. Oczywiķcie dokģadnoķæ tego przypuszczenia zaleŋy w duŋej mierze od tego, jak ķciķle pragnienia bota odpowiadają graczowi - i to zaleŋy od twoich umiejętnoķci modelowania behawioralnego - ale zwykle nie jest zbyt trudne wykonanie od czasu do czasu dokģadnej prognozy, która pozwala botowi daæ graczowi przykra niespodzianka, nawet w przypadku bardzo podstawowego modelu.
Podziaģy
Jedną wielką zaletą hierarchicznego projektu arbitraŋu opartego na celach jest to, ŋe dodatkowe funkcje są dostarczane przy niewielkim dodatkowym wysiģku ze strony programisty. Spędzimy resztę rozdziaģu, przyglądając się im.
Osobowoķci
Poniewaŋ oceny celowoķci są ograniczone do tego samego zakresu, ģatwo jest stworzyæ agentów o róŋnych cechach osobowoķci, mnoŋąc kaŋdy wynik przez staģą, która przesuwa go w wymaganym kierunku. Na przykģad, aby stworzyæ bota Ravena, który gra agresywnie, nie dbając o wģasne bezpieczeņstwo, moŋesz zmniejszyæ jego chęæ uzyskania zdrowia o 0,6 i chęæ zaatakowania celów o 1,5. Aby stworzyæ grę, która gra ostroŋnie, moŋesz zaspokoiæ pragnienia bota, aby byģ bardziej podatny na zbieranie broni i zdrowia niŋ atak. Jeķli miaģbyķ zaprojektowaæ agentów ukierunkowanych na cel dla gry RTS, moŋesz stworzyæ jednego przeciwnika, który faworyzuje eksplorację i badania technologii, drugiego, który woli tworzyæ ogromne armie tak szybko, jak to moŋliwe, a drugiego, który ma obsesję na punkcie obrony miasta. Aby uģatwiæ takie cechy osobowoķci, klasa podstawowa Goal_Evaluator zawiera zmienną skģadową m_dCharacterBias, której klient w konstruktorze przypisuje wartoķæ:
class Goal_Evaluator
{
protected:
// gdy oceniono celowoķæ dla bramki, jest ona mnoŋona
// wedģug tej wartoķci. Moŋna go uŋywaæ do tworzenia botów z preferencjami opartymi na
// ich osobowoķci
double m_dCharacterBias;
public:
Goal_Evaluator(double CharacterBias):m_dCharacterBias(CharacterBias){}
/* DODATKOWE SZCZEGÓĢY POMINIĘTO */
};
m_dCharacterBias jest wykorzystywany w metodzie CalculateDesirability kaŋdej podklasy do dostosowania obliczania wyniku oceny poŋądalnoķci. Oto jak jest dodawany do obliczania celowoķci AttackTarget:
double AttackTargetGoal_Evaluator::CalculateDesirability(Raven_Bot* pBot)
{
double Desirability = 0.0;
// wykonuj obliczenia tylko wtedy, gdy istnieje cel
if (pBot->GetTargetSys()->isTargetPresent())
{
const double Tweaker = 1.0;
Desirability = Tweaker *
Raven_Feature::Health(pBot) *
Raven_Feature::TotalWeaponStrength(pBot);
//odchylenie wartoķci zgodnie z osobowoķcią bota
Desirability *= m_dCharacterBias;
}
return Desirability;
}
Jeķli twój projekt gry wymaga, aby osobowoķci botów pozostawaģy między grami, powinieneķ utworzyæ osobny plik skryptu dla kaŋdego bota zawierający uprzedzenia (plus wszelkie inne dane charakterystyczne dla bota, takie jak dokģadnoķæ celowania broni, preferencje wyboru broni itp.) . Jednak w Raven nie ma takich botów; za kaŋdym razem, gdy uruchamiasz program, tendencyjnoķci boty są przypisywane losowe wartoķci w konstruktorze Goal_Think, tak jak:
// te uprzedzenia mogą zostaæ zaģadowane ze skryptu dla poszczególnych botów
// ale na razie podamy im losowe wartoķci
const double LowRangeOfBias = 0.5;
const double HighRangeOfBias = 1.5;
double HealthBias = RandInRange(LowRangeOfBias, HighRangeOfBias);
double ShotgunBias = RandInRange(LowRangeOfBias, HighRangeOfBias);
double RocketLauncherBias = RandInRange(LowRangeOfBias, HighRangeOfBias);
double RailgunBias = RandInRange(LowRangeOfBias, HighRangeOfBias);
double ExploreBias = RandInRange(LowRangeOfBias, HighRangeOfBias);
double AttackBias = RandInRange(LowRangeOfBias, HighRangeOfBias);
// utwórz obiekty oceniające
m_Evaluators.push_back(new GetHealthGoal_Evaluator(HealthBias));
m_Evaluators.push_back(new ExploreGoal_Evaluator(ExploreBias));
m_Evaluators.push_back(new AttackTargetGoal_Evaluator(AttackBias));
m_Evaluators.push_back(new GetWeaponGoal_Evaluator(ShotgunBias,
type_shotgun));
m_Evaluators.push_back(new GetWeaponGoal_Evaluator(RailgunBias,
type_rail_gun));
m_Evaluators.push_back(new GetWeaponGoal_Evaluator(RocketLauncherBias,
type_rocket_launcher));
PORADA. Arbitraŋ celowy jest zasadniczo procesem algorytmicznym zdefiniowanym przez kilka liczb. W rezultacie nie jest sterowany przez logikę (jak FSM), ale przez dane. Jest to niezwykle korzystne, poniewaŋ wszystko, co musisz zrobiæ, aby zmieniæ zachowanie, to poprawienie liczb, które wolisz przechowywaæ w pliku skryptu, aby inni czģonkowie Twojego zespoģu mogli z nimi z ģatwoķcią eksperymentowaæ.
Pamięæ stanu
Charakter zģoŋonych celów (LIFO) automatycznie nadaje się do agentów z pamięcią, umoŋliwiając im tymczasową zmianę zachowania poprzez wypchnięcie nowego celu (lub celów) na przód listy podrzędnych celów. Gdy tylko nowy cel zostanie osiągnięty, pojawi się na liķcie, a agent wznowi wszystko, co wczeķniej robiģ. Jest to bardzo potęŋna funkcja, którą moŋna wykorzystaæ na wiele róŋnych sposobów. Oto kilka przykģadów.
Przykģad pierwszy - automatyczne wznawianie przerwanych czynnoķci
Wyobraž sobie, ŋe Eric, który jest w drodze do kužni ze zģotem w kieszeni, zostaje zģapany przez zģodzieja z noŋem Rambo. Dzieje się to tuŋ przed osiągnięciem trzeciego punktu na drodze, którą podąŋa. Lista subgoal jego mózgu przypomina w tym miejscu
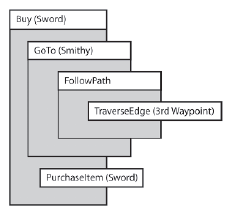
Eric nie spodziewaģ się, ŋe tak się stanie, ale na szczęķcie programista AI stworzyģ cel, aby poradziæ sobie z tego rodzaju sprawą, zwaną DefendAgainst-Attacker. Cel ten zostaje przesunięty na przód jego listy podrzędnej i pozostaje aktywny, dopóki zģodziej nie ucieknie lub nie zostanie zabity przez Erica.
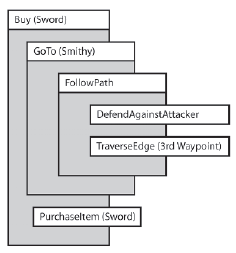
Wspaniaģą rzeczą w tym projekcie jest to, ŋe gdy DefendAgainstAttacker jest usatysfakcjonowany i usunięty z listy, Eric automatycznie wznawia ķledzenie krawędzi do punktu trzeciego. Niektórzy z was zapewne będą myķleæ: "Ach, ale co, jeķli ķcigając zģodzieja, Eric straci wzrok z punktu trzeciego?" To fantastyczna cecha tego projektu. Poniewaŋ cele mają wbudowaną logikę do wykrywania awarii i ponownego tworzenia planu, jeķli cel nie powiedzie się, projekt przesuwa się w górę hierarchii do momentu znalezienia elementu nadrzędnego, który jest w stanie ponownie zaplanowaæ cel.
Przykģad drugi - negocjowanie przeszkód na specjalnej ķcieŋce
Wiele projektów gier wymaga od agentów pokonywania jednego lub więcej rodzajów przeszkód na drodze, takich jak drzwi, windy, mosty zwodzone i ruchome platformy. Często wymaga to od agenta wykonania krótkiej sekwencji dziaģaņ. Na przykģad, aby skorzystaæ z windy, agent musi znaležæ przycisk, który go wywoģuje, podejdž do przycisku, naciķnij go, a następnie cofnij się i staņ przed drzwiami, aŋ winda się pojawi. Korzystanie z ruchomej platformy jest podobnym procesem: agent musi podejķæ do mechanizmu, który dziaģa na platformie, naciķnij / pociągnij ją, podejdž do miejsca wsiadania, poczekaj na platformę, a na koniec wejdž na platformę i poczekaj, aŋ dojdzie do celu.
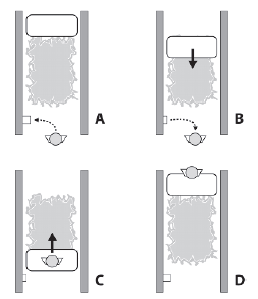
Te "przeszkody" powinny byæ przejrzyste dla planisty ķcieŋki, poniewaŋ nie stanowią one przeszkód dla ruchu agenta. Oczywiķcie negocjowanie ich wymaga czasu, ale moŋe to znaležæ odzwierciedlenie w kosztach nawigacyjnych. Aby agenci mogli poradziæ sobie z takimi przeszkodami, przechodząca przez nie krawędž wykresu musi byæ opatrzona adnotacjami odzwierciedlającymi ich rodzaj. Cel FollowPath moŋe następnie sprawdziæ te informacje i upewniæ się, ŋe wģaķciwy typ celu jest wypychany na początek listy celów agenta, gdy taka krawędž zostanie napotkana. Tak jak w poprzednim przykģadzie, agent będzie realizowaģ ten nowy cel cząstkowy, dopóki nie zostanie ukoņczony, a następnie wznowi wszystko, co robiģ wczeķniej. Aby zilustrowaæ tę zasadę, dodaģem wsparcie przy negocjowaniu przesuwnych drzwi do repertuaru botów Raven. Drzwi przesuwne są otwierane poprzez dotknięcie "przycisku" znajdującego się w pobliŋu drzwi (po jednym z kaŋdej strony). Kiedy drzwi są dodawane w edytorze map, wszelkie krawędzie wykresu przekraczające granicę drzwi są oznaczane flagą idzie_through_door. Jeķli bot napotka krawędž oznaczoną w ten sposób (poniewaŋ są one ķciągane ze ķcieŋki w Goal_FollowPath :: Activate), cel NegotiateDoor jest dodawany do listy podrzędnej w taki sposób:
void Goal_FollowPath::Activate()
{
// uzyskaæ odniesienie do następnej krawędzi
const PathEdge& edge = m_Path.front();
switch(edge.GetBehaviorFlags())
{
case NavGraphEdge::goes_through_door:
{
//dodaj cel, który jest w stanie obsģuŋyæ otwieranie drzwir
AddSubgoal(new Goal_NegotiateDoor(m_pOwner, edge));
}
break;
//etc
Cel NegotiateDoor kieruje bota poprzez sekwencję dziaģaņ wymaganych, aby otworzyæ i przejķæ przez drzwi. Jako przykģad rozwaŋmy przypadek bota pokazanego na rysunku, którego ķcieŋka wiedzie wzdģuŋ krawędzi AB, która jest zasģonięta przesuwanymi drzwiami
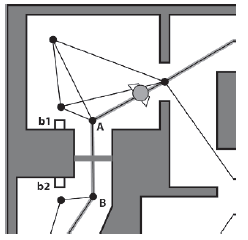
Aby przejķæ przez przesuwane drzwi, bot musi wykonaæ następujące kroki
1. Uzyskaj listę przycisków otwierających drzwi (b1 i b2).
2. Z listy wybierz najbliŋszy przycisk nawigacyjny (b1).
3. Zaplanuj i podąŋaj ķcieŋką do przycisku b1 (przycisk uruchomi się, otwierają się drzwi).
4. Zaplanuj i podąŋaj ķcieŋką do węzģa A.
5. Przejdž przez krawędž AB.
Goal_NegotiateDoor rozwiązuje kaŋdy z tych kroków w metodzie Activate, dodając podzakresy niezbędne do wykonania zadania. Listing pomoŋe to wyjaķniæ
void Goal_NegotiateDoor::Activate()
{
m_iStatus = active;
// jeķli ten cel zostanie ponownie aktywowany, mogą istnieæ pewne podzadania, które
// naleŋy usunąæ
RemoveAllSubgoals();
// uzyskaæ pozycję najbliŋszego przeģączalnego przeģącznika
Vector2D posSw = m_pOwner->GetWorld()->GetPosOfClosestSwitch(m_pOwner->Pos(),
m_PathEdge.GetDoorID());
// poniewaŋ cele są * wypychane * na przód listy podrzędnych celów, które muszą
// byæ dodany w odwrotnej kolejnoķci.
// po pierwsze, cel przejķcia przez krawędž, która przechodzi przez drzwi
AddSubgoal(new Goal_TraverseEdge(m_pOwner, m_PathEdge));
// następnie cel, który przeniesie bota na początek krawędzi, ŋe
// przechodzi przez drzwi
AddSubgoal(new Goal_MoveToPosition(m_pOwner, m_PathEdge.GetSource()));
// wreszcie cel, który skieruje bota do poģoŋenia przeģącznika
AddSubgoal(new Goal_MoveToPosition(m_pOwner, posSw));
}
Moŋesz zobaczyæ roboty Ravena poruszające się po drzwiach, uruchamiając Raven i ģadując mapę Raven_DM1_With_Doors.map. Uŋywa rzadkiego wykresu nawigacyjnego, dzięki czemu moŋesz wyražnie zobaczyæ, jak dziaģa cel NegotiateDoor.
Kolejkowanie poleceņ
Gry strategiczne w czasie rzeczywistym ogromnie się skomplikowaģy w ciągu ostatnich kilku lat. Zwiększono nie tylko liczbę NPC, którą gracz jest w stanie kontrolowaæ, ale takŋe liczbę poleceņ, które moŋe poinstruowaæ NPC. Wymagaģo to kilku ulepszeņ interfejsu uŋytkownika, jednym z nich jest zdolnoķæ gracza do kolejkowania rozkazów NPC - coķ, co staģo się znane jako kolejkowanie poleceņ (lub budowanie w kolejce). Jednym z pierwszych zastosowaņ kolejkowania byģo ustawienie punktów trasy, którymi NPC podąŋaģby ķcieŋką. Aby to zrobiæ, gracz przytrzymuje klawisz, klikając mapę, aby utworzyæ serię punktów trasy. NPC przechowuje punkty w strukturze danych FIFO (pierwsze wejķcie, pierwsze wyjķcie) i podąŋa za nimi w kolejnoķci, zatrzymując się, gdy kolejka jest pusta.
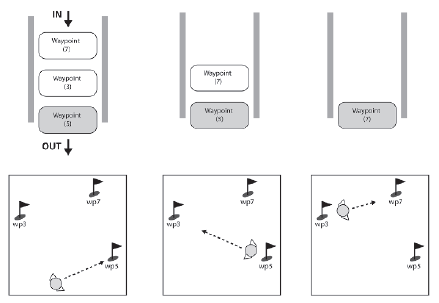
Projektanci szybko zdali sobie sprawę, ŋe przy niewielkich modyfikacjach uŋytkownik moŋe równieŋ przypisaæ punkty patrolowe NPC. Jeķli punkty drogi zostaną przypisane przez gracza jako punkty patrolowania (przytrzymując inny klawisz podczas klikania), są one zwracane na tyģ kolejki, gdy dotrze do nich NPC. W ten sposób NPC będzie nieskoņczenie krąŋyģ przez punkty patrolowania, dopóki nie otrzyma instrukcji.
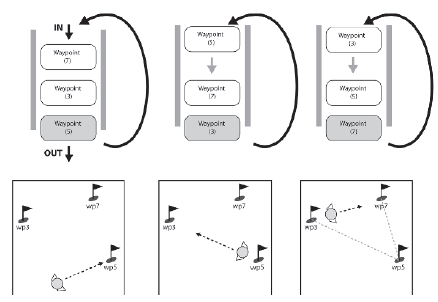
Bardzo krótko po tej innowacji zdano sobie sprawę, ŋe wektory pozycjonujące mogą nie tylko staæ w kolejce, ale takŋe kaŋdy rodzaj polecenia. Następnie, zamiast wydawaæ tylko jedno rozkaz na raz, po prostu przytrzymując klawisz podczas wybierania rozkazów, gracz moŋe kolejkowaæ wiele poleceņ. Na przykģad NPC moŋe zostaæ poinstruowany, aby zebraģ trochę zģota, a następnie zbudowaģ koszary, a następnie zaatakowaģ wrogą jednostkę. Po wydaniu rozkazów gracz moŋe skoncentrowaæ się na innym miejscu, mając pewnoķæ, ŋe NPC wykona rozkazy. Kolejkowanie poleceņ znacznie skraca czas, jaki gracz musi poķwięciæ na mikrozarządzanie i zwiększa czas dostępny na przyjemniejsze aspekty gry. Dlatego staģ się nieodzowną cechą gatunku RTS. Na szczęķcie dzięki zģoŋonej architekturze celów ta funkcja jest niezwykle ģatwa do wdroŋenia. Wszystko, co musisz zrobiæ, to pozwoliæ klientom dodawaæ cele z tyģu listy podrzędnej oprócz frontu. Otóŋ to! Pięæ minut pracy i kolejka poleceņ. Moŋesz obserwowaæ kolejkowanie poleceņ w akcji w Raven. Niestety, w przeciwieņstwie do RTS, Raven nie ma wielu interesujących poleceņ, ale moŋesz ustawiæ w kolejce wiele celów MoveToPosition, przytrzymując klawisz "Q" podczas klikania mapy. Zaimplementowaģem to, dodając metodę QueueGoal_ MoveToPosition do Goal_Think i trochę dodatkowego kodu do wywoģania tej metody, jeķli gracz kliknie mapę, przytrzymując odpowiedni klawisz. Jeķli zwolnisz klawisz "Q" i ponownie klikniesz mapę prawym przyciskiem myszy, kolejka zostanie wyczyszczona i zastąpiona jednym nowym celem. Byģoby to jednak równie ģatwe do wdroŋenia z dowolnym wybranym przez ciebie celem, poniewaŋ kolejkowanie samo się zajmuje.
Korzystanie z zachowania kolejki do skryptu
Kolejną zaletą przeksztaģcenia listy podrzędnej w kolejkę jest to, ŋe umoŋliwia ona pisanie scenariuszy akcji liniowych bez większych trudnoķci. Na przykģad moŋesz utworzyæ takie zachowanie:
• Gracz wchodzi do pokoju i pojawia się widmowa postaæ, która unosi się do skrzyni ustawionej w rogu, otwiera skrzynię, wyjmuje zwój, pģynie z powrotem do gracza i wręcza mu zwój.
• Gracz wchodzi do holu hotelowego ze szklanym sufitem. Po krótkim czasie spędzonym w pokoju sģychaæ helikopter. Kilka sekund póžniej sufit rozbija się na milion odģamków i widaæ, jak kilku uzbrojonych męŋczyzn w czerni zjeŋdŋa z helikoptera. Kiedy uderzą o podģogę, rozpraszają się, kaŋdy znajduje osģonę w osobnym miejscu i zaczynają strzelaæ do gracza.
• Gracz znajduje starą mosięŋną lampę. Pociera ją i pojawia się dŋin. Dŋin mówi "Pójdž za mną" i prowadzi gracza do wejķcia do tajnego tunelu, gdzie natychmiast znika w kģębach dymu.
Aby to zrobiæ, musisz upewniæ się, ŋe zdefiniowaģeķ cel dla kaŋdego kroku sekwencji oraz wyzwalacze wymagane do aktywacji skryptu. Ponadto musisz udostępniæ odpowiedni kod C ++ w swoim języku skryptowym. Na przykģad, aby napisaæ trzeci przykģad z poprzedniej listy w Lua, musisz wykonaæ te zadania.
1. Utwórz trzy cele:
* Cel SayPhrase, który spowoduje wyķwietlenie tekstu na ekranie okreķlony czas.
* Cel LeadPlayerToPosition. Jest to podobne do celu MoveTo-Position widocznego w Raven, z tym ŋe ma dodatkową logikę, aby upewniæ się, ŋe dŋin nie traci z oczu gracza podczas prowadzenia go do tajnego tunelu.
* Cel VanishInPuffOfSmoke, który usunie instancję dŋina ze ķwiata gry i pozostawi po sobie kģębek dymu.
2. Utwórz wyzwalacz, który jest aktywowany, gdy gracz wykonuje akcję "pocieraæ" na konkretnym obiekcie "lampy". Po aktywacji spust powinien wywoģaæ odpowiednią funkcję Lua.
3. Odsģoņ Luę odpowiednie częķci architektury gry. Idealnie byģoby napisaæ skrypt, który wygląda trochę tak:
function AddGenieTourGuide(LampPos, TunnelPos, Player)
--create an instance of a genie at the position of the lamp
genie = CreateGenie(LampPos)
--first welcome the player, text stays on screen for 2 seconds
genie:SayPhrase("Welcome oh great "..Player:GetName().. "!", 2)
--order the player to follow the genie. text stays on screen for
--3 seconds
genie:SayPhrase("Follow me for your three wishes", 3)
--lead the player to the tunnel entrance
genie:LeadPlayerToPosition(Player, TunnelPos)
--vanish
genie:VanishInPuffOfSmoke
end
Dlatego musisz ujawniæ metodę C ++, która tworzy dŋina, dodaje go do ķwiata gry i zwraca wskažnik do niego, a takŋe metody dodawania odpowiednich celów do kolejki bramek dŋina.
Podsumowując
Przedstawiono elastyczną i wydajną architekturę agentów zorientowanych na cele. Nauczyģeķ się, jak zachowanie agenta moŋe byæ modelowane jako zestaw strategii wysokiego poziomu, z których kaŋda skģada się z zagnieŋdŋonej hierarchii celów zģoŋonych i atomowych. Dowiedziaģeķ się takŋe, jak agenci mogą rozstrzygaæ między tymi strategiami, aby wybraæ najbardziej odpowiednią do realizacji w danym stanie gry. Chociaŋ ģączy wiele podobieņstw, ten typ architektury jest znacznie bardziej wyrafinowany niŋ projekt oparty na stanie i wymaga pewnej wprawy, zanim będzie moŋna go bezpiecznie uŋywaæ. Jak zwykle zakoņczę ten rozdziaģ kilkoma pomysģami, z którymi moŋesz się pobawiæ, aby pomóc Ci lepiej zrozumieæ.
Praktyka czyni mistrza
1. Przyzwoici ludzcy gracze FPS odczuwają "wyczucie", kiedy dany przedmiot zaraz się odrodzi. Rzeczywiķcie, niektórzy gracze w deathmatch nie mogą bawiæ się budzikiem z boku swojego monitora! Jednak roboty Raven obecnie nie mają pojęcia, kiedy przedmiot się zbliŋa odrodziæ się. Utwórz warunek zakoņczenia wyszukiwania Dijkstry algorytm, który oblicza, czy nieaktywny (niewidoczny) typ przedmiotu odrodzi się w czasie potrzebnym do jego osiągnięcia, umoŋliwiając w ten sposób botowi go wyprzedziæ.
2. Boty Raven nie mają strategii obronnej. W tej chwili próbują po prostu wytropiæ typ przedmiotu, jeķli nie czują się wystarczająco silni, aby zaatakowaæ i mają nadzieję, ŋe to wyprowadzi ich z drogi. Gdy zobaczysz wersję demonstracyjną, zauwaŋysz, ŋe takie zachowanie często wpędza ich w kģopoty, poniewaŋ nie próbują unikaæ strzaģów podczas ķcigania przedmiotu. Napisz logikę i wszelkie dodatkowe cele wymagane, aby umoŋliwiæ botom wykrywanie takich sytuacji i unikanie ich z boku na bok, wciąŋ ķcigając typ przedmiotu.
3. Dodaj skrypt Raven do postaci i stwórz jedną lub dwie sekwencje skryptowe. To ķwietne æwiczenie, które wzmocni wiele rzeczy, których nauczyģeķ się do tej pory. Nie musisz pisaæ scenariuszy w ŋaden skomplikowany sposób. Na przykģad, moŋesz zrobiæ coķ podobnego do opisanego wczeķniej przykģadu dŋina. Utwórz skrypt z punktu widzenia gracza: natura Kruka, ale wiesz, co mam na myķli), zatrzymuje się przed graczem, mówi "Follow Me", a następnie prowadzi gracza w losowe miejsce.