Logika Rozmyta
Ludzie mają niesamowitą zdolnoķæ do komunikowania umiejętnoķci w prosty i dokģadny sposób, stosując niejasne reguģy językowe. Na przykģad kucharz telewizyjny moŋe pouczyæ Cię, jak zrobiæ idealny ser na toķcie:
1. Wytnij dwie kromki chleba ķredniej gruboķci.
2. Wģącz ciepģo na patelni na wysokim poziomie.
3. Grilluj plastry z jednej strony, aŋ będą zģotobrązowe.
4. Odwróæ plastry i dodaj obficie porcję sera.
5. Wymieņ i grilluj, aŋ wierzch sera będzie lekko brązowy.
6. Usuņ, posyp niewielką iloķcią czarnego pieprzu i jedz.
Wszyscy bylibyķmy pewni, ŋe postępując zgodnie z tymi instrukcjami, przygotujesz pyszną przekąskę. Ludzie robią takie rzeczy przez caģy czas. Jest to dla nas przejrzysty i naturalny proces interpretowania takich instrukcji w sensowny i dokģadny sposób. Czy przy projektowaniu sztucznej inteligencji do gier komputerowych nie byģoby wspaniale móc komunikowaæ się z komputerem w podobny sposób - w celu szybkiego i prostego mapowania wiedzy eksperckiej z dziedziny ludzkiej na cyfrową? Gdyby komputery byģy w stanie zrozumieæ niejasne terminy lingwistyczne, moglibyķmy usiąķæ z ekspertem w dziedzinie zainteresowaņ (częķciej to nie Ty), zadawaæ pytania dotyczące umiejętnoķci niezbędnych do odniesienia sukcesu w tej dziedzinie oraz z odpowiedzi szybko tworzą reguģy językowe do interpretacji przez komputer - tak jak te pokazane przy robieniu tostów. Konwencjonalna logika jest nieodpowiednia do przetwarzania takich reguģ. Na przykģad wyobraž sobie, ŋe programujesz grę w golfa i masz zadanie spędzenia dnia z Tigerem Woodsem w celu ustalenia podstawowych zasad gry w golfa. Pod koniec dnia twój notatnik jest peģen mądroķci, takiej jak te:
Podczas kģadzenia: jeķli piģka jest daleko od doģka, a zieleņ delikatnie pochyla się w dóģ od lewej do prawej, następnie mocno uderz piģkę pod kątem lekko na lewo od flagi.
Podczas stawiania: Jeķli piģka jest bardzo blisko doģka, a zieleņ między piģką a doģkiem jest pozioma, uderz piģkę delikatnie i bezpoķrednio w doģek. Podczas jazdy z tee: jeķli wiatr ma duŋą siģę i wieje od prawej do lewej, a dziura jest daleko, uderz piģkę mocno i pod kątem z prawej strony flagi.
Reguģy te są bardzo opisowe i mają sens dla czģowieka, ale trudno je przetģumaczyæ na język, który komputer moŋe zrozumieæ. Sģowa takie jak "daleko", "bardzo blisko" i "delikatnie" nie mają ostrych, dobrze zdefiniowanych granic, a kiedy próbujemy opisaæ je w kodzie, wynik często wygląda na niezdarny i sztuczny. Na przykģad moŋemy zakodowaæ opisowy termin "Odlegģoķæ" jako zbiór przedziaģów:
Zamknij = piģka znajduje się między 0 a 2 metry od doģka.
Ķredni = piģka znajduje się w odlegģoķci od 2 do 5 metrów od doģka.
Daleko = piģka jest dalej niŋ 5 metrów od doģka.
Ale co jeķli piģka jest 4,99 metra od doģka? Wykorzystując te interwaģy do przedstawienia odlegģoķci, komputer mocno umieķci piģkę w szczelinie "Ķredniej", mimo ŋe dodanie kilku centymetrów sprawi, ŋe będzie daleko! Nietrudno zauwaŋyæ, ŋe podczas manipulowania danymi przedstawionymi w taki sposób rozumowanie AI dotyczące domeny będzie zasadniczo bģędne. Oczywiķcie moŋliwe jest zmniejszenie efektu tego problemu poprzez tworzenie coraz mniejszych przedziaģów, ale podstawowy problem pozostaje, poniewaŋ skģadniki odlegģoķci są nadal reprezentowane przez odrębne przedziaģy. Porównaj to z ludzkimi powodami. Rozwaŋając terminy lingwistyczne, takie jak "daleko" i "blisko" lub "delikatnie" i "stanowczo", czģowiek jest w stanie ustaliæ niejasne granice i pozwoliæ na powiązanie wartoķci z terminem w pewnym stopniu. Gdy piģka znajduje się 4,99 metra od doģka, czģowiek uzna, ŋe jest ona częķciowo związana z terminem "ķredni dystans", ale gģównie z terminem "daleki dystans". W ten sposób ludzie postrzegają jakoķæ odlegģoķci piģki stopniowo przesuwając się między terminami językowymi zamiast gwaģtownie się zmieniając, co pozwala nam dokģadnie rozumowaæ zasady językowe, takie jak te podane podczas gry w golfa lub robienia tostów. Rozmyta logika, wynaleziona przez czģowieka o imieniu Lotfi Zadeh w poģowie lat szeķædziesiątych, umoŋliwia komputerowi rozumowanie terminów i zasad językowych w sposób podobny do ludzi. Pojęcia takie jak "daleko" lub "nieznacznie" nie są reprezentowane przez dyskretne przedziaģy, lecz przez zbiory rozmyte, co umoŋliwia przypisanie wartoķci do zbiorów w pewnym stopniu - proces zwany fuzyfikacją. Uŋywając zakģopotanych wartoķci, komputery są w stanie interpretowaæ reguģy językowe i generowaæ wyniki, które mogą pozostaæ rozmyte lub - częķciej, zwģaszcza w grach wideo - mogą byæ rozmroŋone, aby zapewniæ wyražną wartoķæ. Jest to znane jako wnioskowanie oparte na reguģach rozmytych i jest jednym z najpopularniejszych zastosowaņ logiki rozmytej.
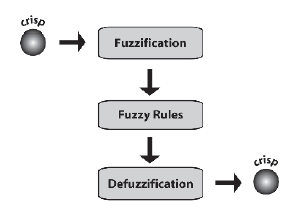
Wkrótce zajmiemy się bardziej szczegóģowo procesem rozmytym, ale zanim zaczniesz rozumieæ zestawy rozmyte, pomaga zrozumieæ matematykę zestawów wyražnych, więc nasza podróŋ do rozmytych rozpocznie się tam.
UWAGA. Interpretacja reguģ językowych jest tylko jednym z wielu zastosowaņ logiki rozmytej. Skoncentrowaģem się na tej aplikacji, poniewaŋ jest to jedna z najbardziej przydatnych funkcji dla programistów AI. Logikę rozmytą z powodzeniem zastosowano w wielu innych obszarach, w tym w inŋynierii sterowania, rozpoznawaniu wzorców, relacyjnych bazach danych i analizie danych. Prawdopodobnie masz w domu kilka póģprzewodnikowych sterowników logiki rozmytej. Mogą regulowaæ system centralnego ogrzewania lub stabilizowaæ obraz w kamerze wideo.
Zestawy Crisp
Zestawy Crisp to matematyczne pojęcia nauczane w szkole. Mają one jasno okreķlone granice: Obiekt (czasem nazywany elementem) albo caģkowicie naleŋy do zbioru, albo nie. Jest to przydatne w przypadku wielu problemów, poniewaŋ wiele obiektów moŋna precyzyjnie sklasyfikowaæ. W koņcu pik to szpadel; to nie jest częķciowo szpadel, a częķciowo para noŋyc ogrodowych. Domena wszystkich elementów, do których naleŋy zbiór, nazywana jest wszechķwiatem dyskursu. Biaģy prostokąt na rycinie 10.2 przedstawia wszechķwiat dyskursu liczb caģkowitych z zakresu od 1 do 15. Koģa wewnątrz UOD oznaczają zbiór liczb caģkowitych parzystych i zbiór liczb nieparzystych.
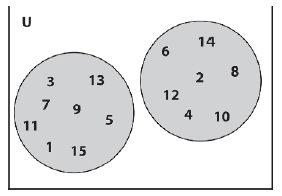
Za pomocą notacji matematycznej zestawy te moŋna zapisaæ jako:
Nieparzyste = {1, 3, 5, 7, 9, 11, 13, 15}
Parzyste = {2, 4, 6, 8, 10, 12, 14}
Jak widaæ, stopieņ przynaleŋnoķci liczby do wyražnego zbioru wynosi albo prawda, albo faģsz, 1 lub 0. Liczba 5 to 100 procent nieparzystych i 0 procent parzystych. W klasycznej teorii zbiorów wszystkie liczby caģkowite są w ten sposób czarno-biaģe - naleŋą one do jednego zbioru do stopnia 1, a drugiego do stopnia 0. Warto równieŋ podkreķliæ, ŋe element moŋe byæ zawarty w więcej niŋ jednym ostry zestaw. Na przykģad liczba caģkowita 3 jest czģonkiem zbioru liczb nieparzystych, zbioru liczb pierwszych i zbioru wszystkich liczb mniejszych niŋ 5. Ale we wszystkich tych zbiorach jego stopieņ czģonkostwa wynosi 1.
Ustaw operatory
Istnieje wiele operacji, które moŋna wykonaæ na zestawach. Najczęstsze to zjednoczenie, przecięcie i uzupeģnienie. Poģączenie dwóch zbiorów jest zbiorem zawierającym wszystkie elementy z obu zbiorów. Operator związku jest zwykle zapisywany za pomocą symbolu ∪. Biorąc pod uwagę dwa zbiory A = {1, 2, 3, 4} i B = {3, 5, 7}, poģączenie A i B moŋna zapisaæ jako:
A ∪ B = 1,2,3,4,3,5,7 } (10.1)
Poģączenie dwóch zbiorów jest równowaŋne ORingowaniu zbiorów razem - dany element znajduje się w jednym LUB drugim. Przecięcie dwóch zbiorów, napisanych za pomocą symbolu ∩, jest zbiorem zawierającym wszystkie elementy obecne w obu zestawach. Uŋywając zestawów A i B z góry, ich przecięcie jest zapisane jako:
A ∩ B = {3} (10.2)
Przecięcie dwóch zbiorów jest równowaŋne ANDowaniu zbiorów razem. Uŋywając naszych dwóch zestawów powyŋej, jest tylko jeden element, który znajduje się w zestawie A ORAZ w zestawie B, tworząc przecięcie zbiorów A i B {3}. Dopeģnieniem zbioru jest zbiór zawierający wszystkie elementy wszechķwiata dyskursu nieobecnego w zbiorze. Innymi sģowy, jest odwrotnoķcią zbioru. Powiedzmy, ŋe wszechķwiat dyskursu A i B to A ∪ B, jak podano w równaniu (10.1), to dopeģniacz A jest B, a dopeģniacz B jest A. Operator dopeģniacza jest zwykle zapisywany za pomocą symbolu ", chociaŋ czasami jest oznaczony przez pasek w górnej częķci nazwy zestawu. Obie opcje pokazano w równaniu

Operator dopeģniania jest równowaŋny NOT
Zestawy rozmyte
Zestawy Crisp są przydatne, ale problematyczne w wielu sytuacjach. Na przykģad zbadajmy wszechķwiat dyskursu wszystkich IQ i zdefiniujmy zestawy dla Gģupiego, Ķredniego i Sprytnego w następujący sposób:
Gģupi = {70, 71, 72,
89}
Ķrednia = {90, 91, 92,
109}
Sprytne = {110, 111, 112,
129}
Graficzny sposób pokazania tych wyražnych zestawów pokazano na rysunku. Zauwaŋ, ŋe stopieņ przynaleŋnoķci elementu do dowolnego zestawu moŋe wynosiæ 1 lub 0.
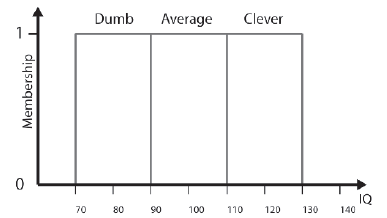
Inteligencję ludzi moŋna teraz podzieliæ na kategorie, przypisując ich do jednego z tych zestawów na podstawie ich wyniku IQ. Najwyražniej jednak osoba o ilorazie inteligencji 109 jest znacznie powyŋej ķredniej inteligencji i prawdopodobnie większoķæ jego rówieķników uznaģaby go za sprytnego. Z pewnoķcią jest znacznie bardziej inteligentny niŋ osoba, która ma wynik 92, mimo ŋe obie naleŋą do tej samej kategorii. Ķmieszne jest teŋ porównywanie osoby z IQ 79 i osoby z IQ 80 i dochodzenie do wniosku, ŋe jedno jest gģupie, a drugie nie! To tutaj spadają ostre zestawy. Zestawy rozmyte pozwalają w pewnym stopniu przypisywaæ do nich elementy.
Definiowanie rozmytych granic za pomocą funkcji czģonkostwa
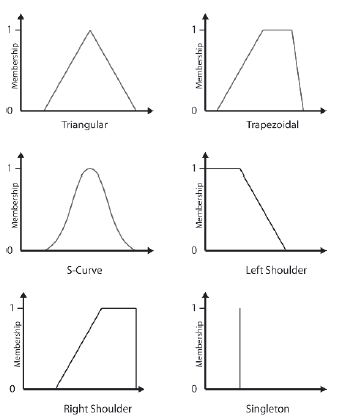
Zestaw rozmyte jest definiowany przez funkcję czģonkostwa. Funkcje te mogą mieæ dowolny ksztaģt, ale zazwyczaj są trójkątne lub trapezowe. Rysunek 10.4 pokazuje kilka przykģadów funkcji czģonkostwa. Zwróæ uwagę, w jaki sposób definiują stopniowe przejķcie z regionów caģkowicie spoza zestawu do regionów caģkowicie w zestawie, umoŋliwiając w ten sposób częķciowe czģonkostwo w zestawie. To jest istota logiki rozmytej.
Rysunek poniŋszy pokazuje, w jaki sposób pojęcia językowe Dumb, Average i Clever moŋna przedstawiæ jako zbiory rozmyte skģadające się z trójkątnych funkcji czģonkostwa. Linia przerywana pokazuje, w jaki sposób Brian, który ma iloraz inteligencji równy 115, jest czģonkiem dwóch zestawów. Jego stopieņ czģonkostwa w Clever wynosi 0,75, a ķrednio 0,25. Jest to zgodne z tym, w jaki sposób czģowiek rozumowaģby inteligencję Briana. Czģowiek uzna go za przebiegģego, ponadprzeciętnego, co wģaķnie moŋna wywnioskowaæ z jego rozmytych ustalonych wartoķci czģonkostwa.
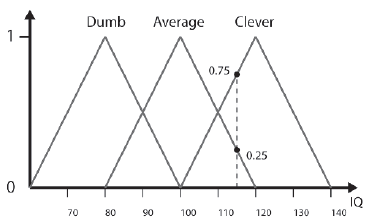
UWAGA Warto zauwaŋyæ, ŋe terminy lingwistyczne powiązane z rozmytymi zbiorami mogą zmieniaæ swoje znaczenie, gdy są uŋywane w róŋnych ramach odniesienia. Na przykģad znaczenie zbiorów rozmytych Wysoki, Ķredni i Krótki będzie inne dla Europejczyków niŋ dla pigmejów Ameryki Poģudniowej. Dlatego wszystkie zbiory rozmyte są zdefiniowane i uŋywane w kontekķcie. Funkcję czģonkostwa moŋna zapisaæ w notacji matematycznej w następujący sposób:
FName_of_set(x) (10.4)
Za pomocą tej notacji moŋemy napisaæ stopieņ czģonkostwa Briana, lub w skrócie DOM, w rozmytym zestawie Clever jako:
CleverBrian = FClever(115) = 0.75 (10.5)
Operatory zbiorów rozmytych
Moŋliwe są przecięcia, związki i uzupeģnienia zbiorów rozmytych, podobnie jak w przypadku zestawów wyražnych. Rozmyta operacja przecięcia jest matematycznie równowaŋna operatorowi AND. Wynikiem ANDing dwóch lub więcej zbiorów rozmytych razem jest inny zestaw rozmytych. Zamazany zestaw ludzi, którzy są przeciętni ORAZ sprytni, pokazano graficznie na tu.
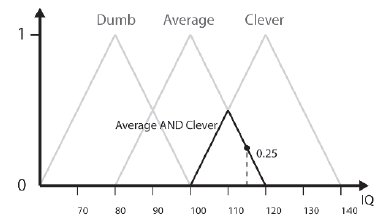
Przykģad graficzny dobrze ilustruje, w jaki sposób operator AND jest równowaŋny z przyjęciem minimalnej wartoķci DOM (stopnia czģonkostwa) dla kaŋdego zestawu, którego czģonkiem jest wartoķæ. Jest to zapisane matematycznie jako:
FAverage∩Clever(x) = min{FAverage(x), FClever(x)} (10.6)
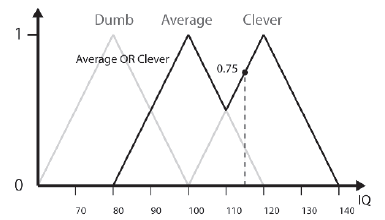
Stopieņ czģonkostwa Briana w grupie osób przeciętnych ORAZ Sprytnych wynosi 0,25. Poģączenie zbiorów rozmytych jest równowaŋne operatorowi OR. Zestaw zģoŋony, który jest wynikiem ORing dwóch lub więcej zestawów razem, wykorzystuje maksimum DOM zestawów komponentów. Dla zbiorów Ķrednia i Sprytna jest to zapisane jako:
FAverage∪Clever(x) = max{FAverage(x), FClever(x)} (10.7)
Rysunek pokazuje grupę ludzi, którzy są przeciętni lub sprytni. Czģonkostwo Briana w tym zestawie wynosi 0,75.
Uzupeģnienie wartoķci DOM o wartoķci m wynosi 1 - m. Rysunek 10.8 opisuje grupę ludzi, którzy NIE są Mądrzy. Widzieliķmy wczeķniej, jak stopieņ czģonkostwa Briana w Clever wynosi 0,75, więc jego DOM dla NOT Clever powinien wynosiæ 1 - 0,75 = 0,25, i dokģadnie to widzimy na rysunku.
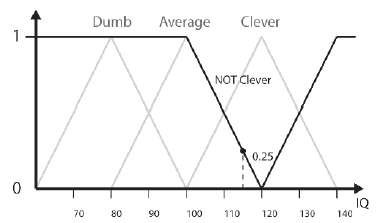
NOT Clever moŋna zapisaæ matematycznie jako:
FClever (x)′ = 1 - FClever (x) (10.8)
Ŋywopģoty
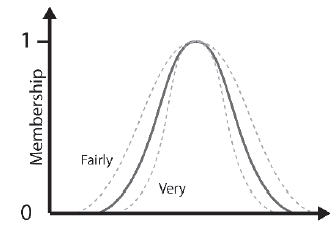
Ŋywopģoty to jednoargumentowe operatory, które moŋna wykorzystaæ do modyfikacji znaczenia zbioru rozmytego. Dwa powszechnie stosowane ŋywopģoty są BARDZO i FAIRY. Dla rozmytego zestawu A, BARDZO modyfikuje go w następujący sposób:
FVERY(A) = FA(x))2 (10.9)
Innymi sģowy, skutkuje kwadratem stopnia czģonkostwa. FAIRLY modyfikuje rozmyty zbiór, biorąc pierwiastek kwadratowy ze stopnia czģonkostwa, w ten sposób:
FVERY(A) =√ FA(x) (10.10)
Efekt tych ŋywopģotów najlepiej widaæ graficznie. Rycina 10.9 pokazuje, w jaki sposób BARDZO zawęŋa funkcję czģonkostwa i jak FAIRLY ją poszerza. Jest to intuicyjne, poniewaŋ kryteria czģonkostwa w zestawie zmodyfikowanym przez FAIRLY powinny byæ bardziej rozlužnione niŋ w przypadku samego zestawu. I odwrotnie, BARDZO - kryterium jest zaostrzone.
Rozmyte zmienne językowe
Rozmyta zmienna językowa (lub FLV) to kompozycja jednego lub więcej zbiorów rozmytych reprezentujących jakoķciowo pojęcie lub domenę. Biorąc pod uwagę nasz wczeķniejszy przykģad, zbiory Dumb, Average i Clever są czģonkami rozmytej zmiennej językowej IQ. Moŋna to zapisaæ w zestawie notacji jako:
IQ = {Gģupi, ķredni, sprytny}
Oto kilka innych przykģadów rozmytych zmiennych językowych i ich skģadowych zbiorów rozmytych:
Prędkoķæ = {Wolny, Ķredni, Szybki}
Wysokoķæ = {karzeģ, krótki, ķredni, wysoki, gigant}
Wiernoķæ = {przyjaciel, neutralny, wróg}
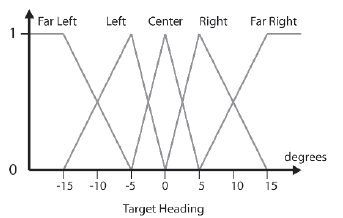
Kierowanie na cel = {skrajnie lewy, lewy, ķrodkowy, prawy, skrajny prawy}
Rysunek pokazuje nagģówek celu FLV w formie graficznej. Zwróæ uwagę, jak funkcje czģonkostwa w zestawach elementów mogą byæ zróŋnicowane pod względem ksztaģtu i asymetryczne, jeķli wymaga tego problem. Zbiór ksztaģtów (funkcje czģonkostwa), które skģadają się na FLV, jest znany jako rozmyta rozmaitoķæ lub rozmyta powierzchnia
UWAGA. Praktycy logiki rozmytej wydają się nie byæ w stanie uzgodniæ spójnej terminologii opisującej elementy językowe, które skģadają się na system rozmyty (o ironio). Często wyraŋenie "rozmyta zmienna językowa" (lub po prostu "zmienna językowa") znajduje zastosowanie do zbioru zbiorów rozmytych i do samych zestawów. Moŋe to byæ mylące podczas czytania dostępnej literatury.
Reguģy rozmyte
Tutaj wszystko zaczyna się ģączyæ. Zdaję sobie sprawę, ŋe moŋesz byæ w tej chwili zdezorientowany, ale trzymaj się tam; oķwiecenie będzie wkrótce wasze! Reguģy rozmyte skģadają się z poprzednika i konsekwencji w postaci:
JEĶLI poprzednia WTEDY konsekwencja
Poprzednik reprezentuje warunek, a konsekwencja opisuje konsekwencję, jeķli warunek ten jest speģniony. Ten typ reguģy jest znany wszystkim programistom. Wszyscy napisaliķmy kod taki jak:
JEŊELI Wizard.Health () <= 0 NASTĘPNIE Wizard.isDead ()
Róŋnica w stosunku do reguģ rozmytych polega na tym, ŋe w przeciwieņstwie do konwencjonalnych reguģ, w których konsekwencja strzela albo nie, w systemach rozmytych konsekwencja moŋe strzelaæ do pewnego stopnia. Oto kilka przykģadów rozmytych reguģ:
JEĶLI Target_isFarRight NASTĘPNIE Turn_QuicklyToRight
JEĶLI BARDZO (Enemy_BadlyInjured) NASTĘPNIE Behavior_Aggressive
JEĶLI Target_isFarAway I Allegiance_isEnemy THEN
Shields_OnLowPower
JEŊELI Ball_isCloseToHole ORAZ Green_isLevel NASTĘPNIE HitBall_Gently
AND HitBall_DirectlyAtHole
JEŊELI (Bend_HairpinLeft LUB Bend_HairpinRight) ORAZ Track_SlightlyWet
NASTĘPNIE Speed_VerySlow
Poprzednikiem moŋe zatem byæ pojedynczy termin rozmyty lub zbiór, który jest wynikiem kombinacji kilku terminów rozmytych. Stopieņ przynaleŋnoķci poprzednika okreķla stopieņ, w jakim konsekwentnie strzela. System wnioskowania rozmytego skģada się zazwyczaj z wielu takich reguģ, których liczba jest proporcjonalna do liczby plików FLV wymaganych dla domeny problemowej i liczby zestawów czģonkostwa w tych plikach FLV. Za kaŋdym razem, gdy zamazany system przechodzi przez zestaw reguģ, ģączy konsekwencje, które zostaģy wystrzelone, i defragmentuje wynik, aby daæ wyražną wartoķæ. Więcej informacji na ten temat za chwilę, ale najpierw, zanim zagģębimy się gģębiej, zaprojektujmy kilka FLV, których moŋemy uŋyæ, aby rozwiązaæ rzeczywisty problem. Biorąc pod uwagę praktyczny przykģad, w który moŋna zatopiæ zęby, jestem pewien, ŋe ģatwiej będzie ci zobaczyæ, jak wszystkie te rzeczy dziaģają razem.
Projektowanie FLV do selekcji broni
Poniewaŋ zasady, którymi gracz decyduje się na zmianę broni, moŋna ģatwo opisaæ przy uŋyciu terminów językowych, dobór broni jest dobrym kandydatem do zastosowania logiki rozmytej. Zobaczmy, jak ten pomysģ moŋna zastosowaæ do Ravena. Aby uproķciæ ten przykģad, powiemy, ŋe celowoķæ wyboru konkretnej broni z ekwipunku zaleŋy od dwóch czynników: odlegģoķci do celu i iloķci amunicji. Kaŋda klasa broni posiada instancję rozmytego moduģu, a kaŋdy moduģ jest inicjalizowany za pomocą plików FLV reprezentujących terminy lingwistyczne Odlegģoķæ do celu, Status amunicji (poprzednicy) i Celowoķæ (konsekwencja), a takŋe zasady dotyczące tej broni. Reguģy okreķlają, jak poŋądana jest ta broņ w danym scenariuszu, umoŋliwiając botowi wybranie broni o najwyŋszej wartoķci poŋądanej jako bieŋącej broni. Odlegģoķæ FLV do celu i celowoķæ są definiowane identycznie dla kaŋdego rodzaju broni. Status amunicji i zestaw reguģ są tworzone na zamówienie. Przykģady podane w tym rozdziale skupią się na projektowaniu FLV i zestawu reguģ dla wyrzutni rakiet.
Projektowanie wymgalnoķci FLV
Zaczniemy od zaprojektowania rozmytej zmiennej językowej wymaganej do oznaczenia następującego zbioru: Celowoķæ. Istnieje kilka waŋnych wskazówek, których naleŋy przestrzegaæ przy projektowaniu FLV. Są to:
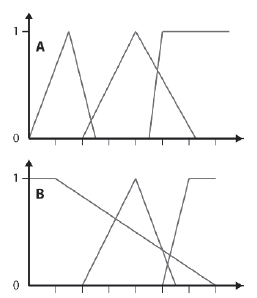
• Dla kaŋdej linii pionowej (reprezentującej wartoķæ wejķciową) przeciągniętej przez FLV, suma DOM w kaŋdym z rozmytych zbiorów, z którymi się przecina, powinna wynosiæ okoģo 1. Zapewnia to pģynne przejķcie między wartoķciami przez rozmytą rozmaitoķæ FLV (poģączone ksztaģt wszystkich zestawów czģonkowskich).
• Dla kaŋdej linii pionowej poprowadzonej przez FLV powinna przecinaæ się tylko z dwoma lub mniej rozmytymi zestawami.
FLV, który ģamie pierwszą wytyczną, pokazano na rysunku A, a FLV, który ģamie drugą wytyczną, pokazano na rysunku B.
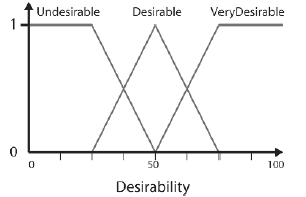
Wymagalnoķæ FLV jest wymagana do reprezentowania dziedziny wszystkich wyników od 0 do 100. Dlatego zestawy elementów muszą odpowiednio obejmowaæ ten zakres (przy jednoczesnym przestrzeganiu wytycznych). Wybraģem uŋycie trzech zestawów elementów: zestawu z lewym ramieniem, zestawu z trójkątem i zestawu z prawym ramieniem, reprezentujących terminy lingwistyczne Niepoŋądane, poŋądane i bardzo poŋądane, jak pokazano tu
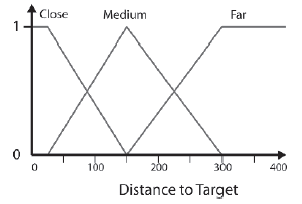
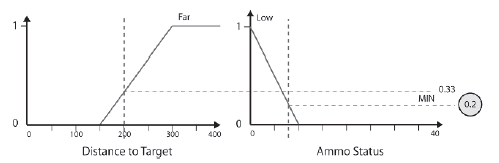
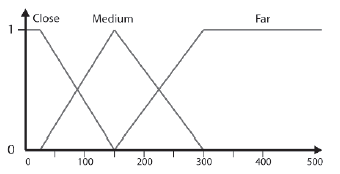
Projektowanie odlegģoķci do docelowego FLV
Następnie rozwaŋymy poprzednik: Odlegģoķæ do celu. Po raz kolejny FLV skģada się z trzech zestawów o nazwach Target_Close, Target_Medium i Target_Far. Te trzy warunki są caģkowicie odpowiednie, aby umoŋliwiæ ekspertowi (czyli nam, ludziom) okreķlenie zasad wyboru broni. Kiedy gram w grę, myķlę, ŋe termin "bliski" oznacza prawie obok mnie - w takim zakresie, w którym moŋesz rozwaŋyæ walkę wręcz. Dlatego ustawiģem pik rozmytego zestawu Target_Close w odlegģoķci 25 pikseli, co wydaje mi się wģaķciwe, biorąc pod uwagę skalę typowej mapy Ravena (bot ma promieņ ograniczający okoģo 10 pikseli). Wybraģem uŋycie 150 pikseli jako piku dla Target_Medium, poniewaŋ wydaje mi się to sģuszne, i postanowiģem uczyniæ z Target_Far ksztaģt ramienia, który osiąga wartoķæ szczytową przy 300, a następnie pģaskowyŋ do 400. Zauwaŋ, ŋe nie martwię się zbytnio o konkretne wartoķci; Po prostu uŋywam wartoķci, które "wydają się" prawidģowe. Odlegģoķæ do celu pokazano na rysunku
.
Projektowanie stanu amunicji FLV
Na koniec zajmiemy się statusem amunicji, który będzie wykorzystywaģ zestawy rozmyte Ammo_Low, Ammo_Okay i Ammo_Loads. Poniewaŋ terminy lingwistyczne są zdefiniowane w kontekķcie (poniewaŋ to, co moŋesz uznaæ za dobrą iloķæ amunicji, powiedzmy, granatnika, raczej nie będzie odpowiednią iloķcią dla karabinu maszynowego), ten FLV róŋni się w zaleŋnoķci od broni. Wyrzutnia rakiet jest w stanie wystrzeliæ dwie rakiety na sekundę, więc powiedziaģbym, ŋe dobra iloķæ amunicji to okoģo 10 rakiet. Niosąc okoģo 30 rakiet, uwaŋam, ŋe mam mnóstwo amunicji, a wszystko poniŋej 10 jest niskie. Mając to na uwadze, zaprojektowaģem Stan amunicji, jak pokazano na rysunku
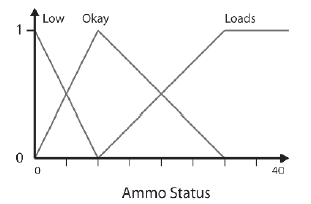
Jak widaæ, projektowanie FLV jest gģównie zdrowym rozsądkiem: po prostu zbadaj i przetģumacz swoją wiedzę, a nawet lepiej, wiedzę eksperta o domenie.
Projektowanie zestawu reguģ do wyboru broni
Teraz, gdy mamy do czynienia z rozmytymi terminami, przejdžmy do zasad. Aby uwzględniæ wszystkie moŋliwoķci, naleŋy utworzyæ reguģę dla kaŋdej moŋliwej kombinacji zbiorów poprzedników. Kaŋdy z rodzajów amunicji FLV i dystansu do celu zawiera trzy zestawy elementów, więc aby uwzględniæ kaŋdą kombinację, naleŋy zdefiniowaæ dziewięæ zasad. Po raz kolejny wcielę się w rolę eksperta. W mojej opinii "eksperta" wyrzutnia rakiet jest ķwietną bronią na ķrednim dystansie, ale uŋywanie jej z bliska jest niebezpieczne, poniewaŋ grozi jej uszkodzenie przez wybuch. Ponadto, poniewaŋ rakiety poruszają się powoli, jest to zģy wybór broni, gdy cel jest daleko, poniewaŋ rakiety moŋna ģatwo uniknąæ. Mając na uwadze te fakty, oto dziewięæ zasad, które stworzyģem w celu okreķlenia celowoķæ uŋycia wyrzutni rakiet:
Zasada 1. JEĶLI Target_Far ORAZ ĢADUNKI amunicji NIŊ Poŋądane
Zasada 2. JEĶLI Target_DALNIE ORAZ Amunicja jest OK TO Niepoŋądane
Zasada 3. JEĶLI Target_Dalej I Amunicja_NISKIE TO Niepoŋądane
Zasada 4. JEĶLI Target_Medium ORAZ ĢADUNKI amunicji WTEDY Bardzo poŋądane
Zasada 5. JEĶLI Target_Medium ORAZ amunicja jest OK, to bardzo poŋądane
Zasada 6. JEĶLI Target_Medium I Ammo_LOW THEN Poŋądane
Zasada 7. JEĶLI Target_Close AND Ammo_Loads THEN Niepoŋądane
Reguģa 8. JEĶLI Target_Close AND Ammo_Okay THEN Niepoŋądane
Zasada 9. JEĶLI Target_Close AND Ammo_LOW THEN Niepoŋądane
Pamiętaj, ŋe te zasady są tylko moją opinią i odzwierciedlają mój poziom doķwiadczenia w grze. Podczas projektowania reguģ dla wģasnej gry skonsultuj się z najlepszym graczem w zespole programistów, poniewaŋ im bardziej ekspert, z którego wywodzisz reguģy, tym lepsza będzie Twoja sztuczna inteligencja. Ma to sens w ten sam sposób, w jaki Michael Schumacher będzie w stanie opisaæ znacznie lepszy zestaw zasad prowadzenia samochodu wyķcigowego Formuģy 1 niŋ ty lub ja.
Wnioskowanie rozmyte
Nadszedģ czas, aby przestudiowaæ procedurę wnioskowania rozmytego. To tam przedstawimy systemowi niektóre wartoķci, aby zobaczyæ, które reguģy odpalają i do jakiego stopnia. Wnioskowanie rozmyte przebiega następująco:
1. Dla kaŋdej reguģy
1a. Dla kaŋdego poprzednika obliczyæ stopieņ czģonkostwa w danej wejķciowej.
1b. Oblicz wywnioskowaną reguģę na podstawie wartoķci okreķlone w 1a.
2. Poģącz wszystkie wywnioskowane wnioski w jeden wniosek (zbiór rozmytych).
3. Aby uzyskaæ wyražne wartoķci, wnioski z 2 muszą byæ zszokowane.
Przeanalizujmy teraz te kroki, wykorzystując niektóre z zasad, które stworzyliķmy dla wyboru broni, i kilka wyražnych wartoķci wejķciowych. Zaģóŋmy, ŋe cel znajduje się w odlegģoķci 200 pikseli, a pozostaģa iloķæ amunicji to 8 rakiet. Jedna reguģa narz
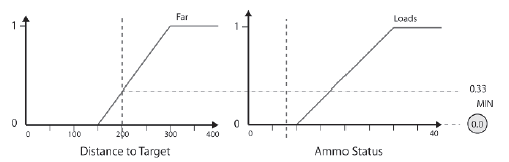
Zasada pierwsza
JEĶLI Target_Far AND Ammo_Loads THEN Poŋądane
Stopieņ przynaleŋnoķci wartoķci 200 do zestawu Target_Far wynosi 0,33. Stopieņ przynaleŋnoķci do wartoķci 8 w zestawie Ammo_Loads wynosi 0. Operator AND powoduje uzyskanie minimum tych wartoķci, więc poŋądany wniosek dla reguģy 1 jest poŋądany = 0. Innymi sģowy, reguģa nie jest uruchamiana. Rysunek 10.15 pokazuje tę reguģę graficznie.
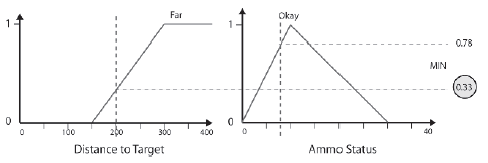
Zasada druga
IF Target_Far AND Ammo_Okay THEN Niepoŋądane
Dla drugiej reguģy stopieņ przynaleŋnoķci wartoķci 200 do zestawu Target_Far wynosi 0,33. Stopieņ czģonkostwa o wartoķci 8 w zestawie Ammo_Okay wynosi 0,78. Wnioskowany wniosek dla reguģy 2 jest zatem niepoŋądany = 0,33.
Zasada trzecia
IF Target_Far AND Ammo_Low THEN Niepoŋądane
Stosując te same wartoķci do trzeciej reguģy, stopieņ przynaleŋnoķci wartoķci 200 do zestawu Target_Far wynosi 0,33. Stopieņ czģonkostwa o wartoķci 8 w zestawie Ammo_Low wynosi 0,2. Wnioskowany wniosek dla reguģy 3 jest zatem niepoŋądany = 0,2.
Jestem pewien, ŋe masz juŋ sedno tego, więc aby zaoszczędziæ wiele powtórzeņ, uzyskane wyniki dla wszystkich reguģ są podsumowane przez macierz pokazaną na rysunku. (Ten typ macierzy jest znany jako rozmyta macierz asocjacyjna lub w skrócie FAM).
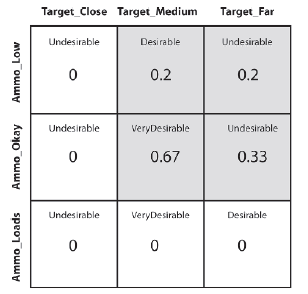
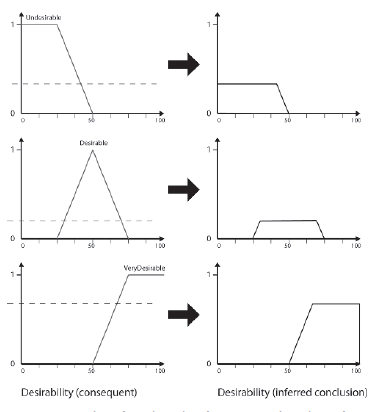
Zauwaŋ, ŋe VeryDesiable wystrzeliģ raz do stopnia 0,67. Poŋądany strzeliģ raz do stopnia 0,2, a Niepoŋądany strzeliģ dwa razy ze stopniem 0,2 i 0,33. Jednym ze sposobów myķlenia o tych wartoķciach jest poziom zaufania. Biorąc pod uwagę dane wejķciowe, reguģy rozmyte wywnioskowaģy wynik Bardzo poŋądany z pewnoķcią 0,67, a wynik Poŋądany z pewnoķcią 0,2. Ale jakie wnioski moŋna wyciągnąæ z Niepoŋądanego, który strzeliģ dwa razy? Istnieje kilka sposobów postępowania z wieloma zwierzeniami. Dwie najpopularniejsze to suma ograniczona (suma i wartoķæ 1) oraz wartoķæ maksymalna (odpowiednik ORing razem ufnoķci). Nie ma wielkiego znaczenia, którą metodę wybierzesz. Wolę OR wartoķci razem, co w tym przykģadzie daje pewnoķæ niepoŋądanemu z 0,33. Podsumowując, w Tabeli wymieniono wnioski wynikające z zastosowania wartoķci odlegģoķci do celu = 200 i stanu amunicji = 8 do wszystkich reguģ.

Te wyniki pokazano graficznie na rysunku. Zwróæ uwagę, w jaki sposób funkcja czģonkostwa kaŋdego następcy jest przycinana do poziomu pewnoķci.
Następnym krokiem jest poģączenie uzyskanych wyników w jeden rozmyty kolektor.
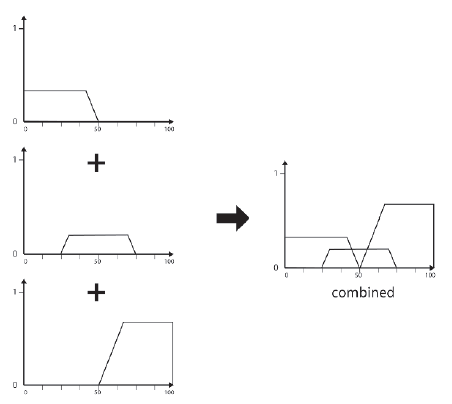
Teraz, gdy mamy zģoŋony zestaw rozmytych reprezentujących wnioskowanie wszystkich reguģ w bazie reguģ, nadszedģ czas, aby odwróciæ proces i przeksztaģciæ ten zestaw danych wyjķciowych w jedną wyražną wartoķæ. Osiąga się to poprzez proces zwany defuzzification.
Defuzzification
Defuzzification jest odwrotnoķcią fuzzification: proces odwracania rozmycia ustawiony na wyražną wartoķæ. Moŋna to zrobiæ na wiele sposobów, a następne kilka stron zostanie poķwięconych na sprawdzenie najczęķciej uŋywanych.
Mean of Maximum (MOM) Ķrednia maksimum - MOM w skrócie - metoda defuzzification oblicza ķrednią z tych wartoķci wyjķciowych, które mają najwyŋszy stopieņ ufnoķci. Rysunek pokazuje, jak moŋna zastosowaæ tę technikę do okreķlenia wyražnej wartoķci z rozkģadu wyjķciowego dla obliczonej wczeķniej celowoķci.
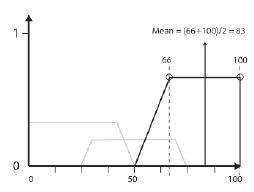
Jednym z problemów związanych z tą metodą jest to, ŋe nie bierze pod uwagę tych zbiorów wyjķciowych, które nie mają ufnoķci równej najwyŋszej (jak te pokazane na rysunku kolorem szarym), które mogą przesunąæ wynikową wyražną wartoķæ na jeden koniec domena. Dokģadniejsze metody fuzyfikacji, takie jak te wymienione poniŋej, rozwiązują ten problem.
Centroid
Metoda centroid jest najdokģadniejsza, ale jest równieŋ najbardziej zģoŋona do obliczenia. Dziaģa poprzez okreķlenie ķrodka masy zbiorów wyjķciowych. Jeķli wyobraŋasz sobie kaŋdy zestaw elementów zestawu wyjķciowego wycięty z kartonu, a następnie sklejony ze sobą, tworząc ksztaģt rozmytego kolektora, ķrodek masy jest pozycją, w której wynikowy ksztaģt byģby zrównowaŋony, gdyby zostaģ umieszczony na linijce.
Ķrodek cięŋkoķci rozmytego kolektora oblicza się, dzieląc kolektor na punkty próbkowania i obliczając sumę udziaģu DOM w kaŋdym punkcie próbki w sumie, podzieloną przez sumę DOMs próbek. Wzór podano w (10.11).
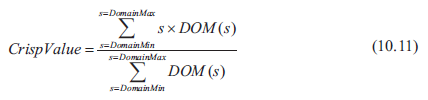
gdzie s jest wartoķcią w kaŋdym punkcie próbki, a DOM (s) to stopieņ czģonkostwo w FLV o tej wartoķci. Im więcej punktów próbki zostanie wybranych do wykonania obliczeņ, tym dokģadniejszy będzie wynik, chociaŋ w praktyce zwykle wystarcza 10 do 20 próbek. Teraz zdaję sobie sprawę, ŋe niektórzy z was mogą mieæ koģatanie serca w tym momencie, więc prawdopodobnie najlepiej będzie, jeķli wyjaķnię na przykģadzie. Rozmyķlimy rozmytą rozmaitoķæ wynikającą z uruchomienia zasad wyboru broni przy uŋyciu 10 przykģadowych punktów pokazanych na rysunku
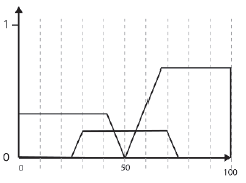
Dla kaŋdego punktu próbki obliczany jest DOM w kaŋdym zestawie elementów. Tabela podsumowuje wyniki. (Uwaga: Wartoķci podane dla próbek w 30 i 70 są nieprecyzyjne, poniewaŋ są po prostu oszacowane na powyŋszym rysunku, ale są wystarczająco dokģadne dla tego pokazu.)
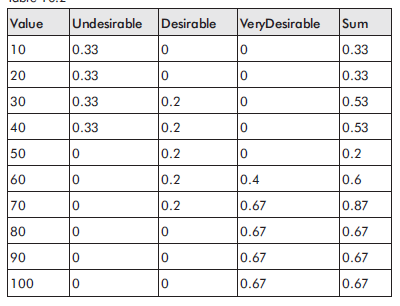
Teraz podģącz liczby do równania (10.11). Najpierw obliczmy licznik (częķæ równania powyŋej linii).

A teraz mianownik (częķæ poniŋej linii):
0,33 + 0,33 + 0,53 + 0,53 + 0,2 + 0,6 + 0,87 + 0,67 + 0,67 + 0,67 = 5,4 (10,13)
Dzielenie licznika przez mianownik daje wyražną wartoķæ:
Celowoķæ = 334,8 / 5,4 = 62 (10,14)
Average of Maxima (MaxAv)
Maksymalna lub reprezentatywna wartoķæ rozmytego zbioru to wartoķæ, w której czģonkostwo w tym zestawie wynosi 1. W przypadku zbiorów trójkątnych jest to po prostu wartoķæ w punkcie ķrodkowym; dla zestawów zawierających pģaskowyŋe - takich jak prawe ramię, lewe ramię i zestawy trapezowe - ta wartoķæ jest ķrednią wartoķci na początku i na koņcu pģaskowyŋu. Ķrednia z maksimów (w skrócie MaxAv) metoda defuzzyfikacji skaluje reprezentatywną wartoķæ kaŋdego następstwa wedģug jego pewnoķci i przyjmuje ķrednią, jak poniŋej:
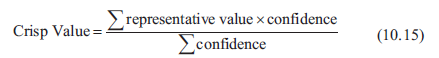
Reprezentatywne wartoķci zbiorów zawierających kolektor wyjķciowy zestawiono w tabeli 10.3.
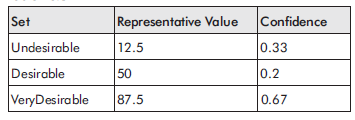
Podģączenie tych wartoķci do równania daje celowoķæ jako wyražną wartoķæ:
Celowoķæ = 12,5 x 0,33 x 50 x 0,2 x 87,5 x 0,67 / 0,33 + 0,2 + 0,67 =
72,75 / 1,2 = 60,625 (10,16)
Jak widaæ, metoda ta wygenerowaģa wartoķæ bardzo zbliŋoną do obliczonej przez dokģadniejszą, ale bardziej kosztowną metodę obliczania centroidów (i byģby bliŋej, gdybym nie oszacowaģ niektórych wartoķci w obliczeniach centroidów), a zatem to ten, który radzę uŋywaæ w swoich grach i aplikacjach. Cóŋ, to wszystko! Przeszliķmy z wyražnych wartoķci (odlegģoķæ do celu = 200, stan amunicji = 8) do rozmytych zestawów, wnioskowania i z powrotem do wyražnej wartoķci reprezentującej celowoķæ korzystania z wyrzutni rakiet (83, 62 lub 60.625 w zaleŋnoķci od metody defuzzyfikacji). Jeķli ten proces powtarza się dla kaŋdego rodzaju broni, którą nosi bot, ģatwo jest wybraæ tę, która ma najwyŋszy wynik poŋądania, jako broņ, której bot powinien uŋyæ w obecnej sytuacji.
Od teorii do zastosowania: kodowanie moduģu logiki rozmytej
Nadszedģ czas, aby dokģadnie zobaczyæ, jak zostaģy zaprojektowane klasy wymagane do implementacji logiki rozmytej i jak są one zintegrowane z Raven.
Klasa FuzzyModule
Klasa FuzzyModule jest sercem systemu rozmytego. Zawiera std :: mapa rozmytych zmiennych językowych i wektor std :: zawierający podstawę reguģy. Ponadto ma metody dodawania plików FLV i reguģ do moduģu oraz przeprowadzania moduģu przez proces fuzzification, wnioskowania i defuzzification.
class FuzzyModule
{
private:
typedef std::map
public:
// klient musi przekazaæ jedną z tych wartoķci do metody defuzzify.
// Ten moduģ obsģuguje tylko metody MaxAv i centroid.
enum DefuzzifyType{max_av, centroid};
// przy obliczaniu ķrodka masy rozmytego kolektora ta wartoķæ jest uŋywana
// aby okreķliæ, ile przekrojów naleŋy próbkowaæ
enum {NumSamplesToUseForCentroid = 15};
private:
// mapa wszystkich rozmytych zmiennych uŋywanych przez ten moduģ
VarMap m_Variables;
// wektor zawierający wszystkie reguģy rozmyte
std::vector
// zeruje DOM z konsekwencji kaŋdej reguģy. Uŋywany przez Defuzzify()
inline void SetConfidencesOfConsequentsToZero();
public:
˜FuzzyModule();
// tworzy nową "pustą" zmienną rozmytą i zwraca do niej odwoģanie.
FuzzyVariable& CreateFLV(const std::string& VarName);
// dodaje reguģę do moduģu
void AddRule(FuzzyTerm& antecedent, FuzzyTerm& consequence);
// ta metoda wywoģuje metodę Fuzzify o nazwie FLV
inline void Fuzzify(const std::string& NameOfFLV, double val);
// podana zmienna rozmyta i metoda defuzzyfikacji zwraca wartoķæ
// wyražna wartoķæ
inline double DeFuzzify(const std::string& key, DefuzzifyType method);
};
Klient zazwyczaj tworzy wystąpienie tej klasy dla kaŋdej AI, która wymaga unikalnego zestawu reguģ rozmytych. Pliki FLV moŋna następnie dodaæ do moduģu za pomocą metody CreateFLV. Ta metoda zwraca odwoģanie do nowo utworzonego pliku FLV. Oto przykģad wykorzystania moduģu do utworzenia rozmytych zmiennych językowych wymaganych w przykģadzie wyboru broni
FuzzyModule fm;
FuzzyVariable & DistToTarget = fm.CreateFLV ("DistToTarget");
FuzzyVariable & Desirability = fm.CreateFLV ("Desirability");
FuzzyVariable & AmmoStatus = fm.CreateFLV ("AmmoStatus");
W tym momencie jednak kaŋdy z tych plików FLV jest "pusty". Aby byģ uŋyteczny, plik FLV musi zostaæ zainicjowany przy uŋyciu niektórych zestawów elementów. Rzuæmy okiem na to, jak róŋne typy zbiorów rozmytych są enkapsulowane.
Klasa podstawowa FuzzySet
Poniewaŋ konieczne jest manipulowanie zestawami rozmytymi przy uŋyciu wspólnego interfejsu, wszystkie typy zestawów rozmytych pochodzą z abstrakcyjnej klasy FuzzySet. Kaŋda klasa zawiera czģonka danych do przechowywania stopnia czģonkostwa wartoķci, która ma byæ zszokowana. Konkretne FuzzySets posiadają dodatkowe dane opisujące ksztaģt ich funkcji czģonkostwa.
class FuzzySet
{
protected:
//utrzyma to stopieņ czģonkostwa w tym zestawie danej wartoķci
double m_dDOM;
// to maksimum funkcji czģonkostwa w zestawie. Na przykģad, jeķli
// zestaw jest trójkątny, to będzie punkt szczytowy trójkąta.
// Jeķli zestaw ma pģaskowyŋ, wówczas ta wartoķæ będzie punktem ķrodkowym
//Pģaskowyŋ. Ta wartoķæ jest ustawiana w konstruktorze, aby uniknąæ czasu wykonywania
// obliczenie wartoķci punktu ķrodkowego.
double m_dRepresentativeValue;
public:
FuzzySet(double RepVal):m_dDOM(0.0), m_dRepresentativeValue(RepVal){}
// zwraca stopieņ czģonkostwa w tym zestawie podanej wartoķci. UWAGA:
// to nie ustawia m_dDOM na DOM wartoķci przekazanej jako parametr.
// Wynika to z faktu, ŋe metoda defuzzyfikacji centroidów równieŋ korzysta z tej metody
// w celu okreķlenia DOM wartoķci, których uŋywa jako punktów próbnych.
virtual double CalculateDOM(double val)const = 0;
// jeķli ten rozmyty zestaw jest częķcią wynikowego pliku FLV i jest uruchamiany przez reguģę,
// następnie ta metoda ustawia DOM (w tym kontekķcie DOM reprezentuje
// poziom ufnoķci) do maksymalnej wartoķci parametru lub zbioru
// istniejąca wartoķæ m_dDOM
void ORwithDOM(double val);
// metody akcesora
double GetRepresentativeVal()const;
void ClearDOM(){m_dDOM = 0.0;}
double GetDOM()const{return m_dDOM;}
void SetDOM(double val);
};
Przyjrzyjmy się teraz kilku konkretnym rozmytym klasom zbiorów.
Klasa trójkątnego zestawu rozmytego
Trójkątny zbiór rozmytych jest definiowany przez trzy wartoķci: punkt szczytowy, lewe przesunięcie i prawe przesunięcie.
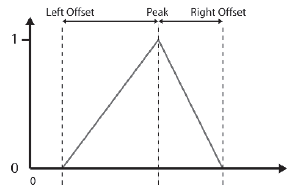
Deklaracja klasy enkapsulującej te dane jest następująca:
class FuzzySet_Triangle : public FuzzySet
{
private:
// wartoķci, które okreķlają ksztaģt tego pliku FLV
double m_dPeakPoint;
double m_dLeftOffset;
double m_dRightOffset;
public:
FuzzySet_Triangle(double mid,
double lft,
double rgt):FuzzySet(mid),
m_dPeakPoint(mid),
m_dLeftOffset(lft),
m_dRightOffset(rgt)
{}
// ta metoda oblicza stopieņ czģonkostwa dla okreķlonej wartoķci
double CalculateDOM(double val)const;
};
Jak widaæ, jest to bardzo proste. Zwróæ uwagę, w jaki sposób punkt ķrodkowy trójkąta jest przekazywany do konstruktora klasy podstawowej jako wartoķæ reprezentatywna dla tego ksztaģtu. Interfejs FuzzySet definiuje tylko jedną metodę, która musi zostaæ zaimplementowana: CalculateDOM, metoda okreķlająca stopieņ przynaleŋnoķci wartoķci do zestawu. Oto kod tej implementacji:
double FuzzySet_Triangle::CalculateDOM(double val)const
{
// test dla przypadku, gdy lewe lub prawe odsunięcie trójkąta ma wartoķæ zero
// (aby zapobiec podzieleniu przez zero bģędów poniŋej)
if ( (isEqual(m_dRightOffset, 0.0) && (isEqual(m_dPeakPoint, val))) ||
(isEqual(m_dLeftOffset, 0.0) && (isEqual(m_dPeakPoint, val))) )
{
return 1.0;
}
// znajdž DOM, jeķli pozostanie po ķrodku
if ( (val <= m_dPeakPoint) && (val >= (m_dPeakPoint - m_dLeftOffset)) )
{
double grad = 1.0 / m_dLeftOffset;
return grad * (val - (m_dPeakPoint - m_dLeftOffset));
}
// znajdž DOM, jeķli jest na prawo od ķrodka
else if ( (val > m_dPeakPoint) && (val < (m_dPeakPoint + m_dRightOffset)) )
{
double grad = 1.0 / -m_dRightOffset;
return grad * (val - m_dPeakPoint) + 1.0;
}
// poza zakresem tego FLV, zwróæ zero
else
{
return 0.0;
}
}
Klasa zestawu rozmytego prawego ramienia
Zestaw rozmytych prawych ramion jest równieŋ parametryzowany przez trzy wartoķci: punkt szczytowy, lewe przesunięcie i prawe przesunięcie.
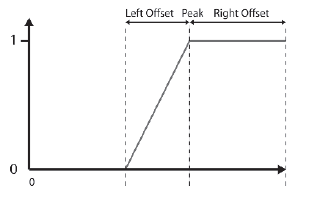
Po raz kolejny definicja klasy jest prosta:
class FuzzySet_RightShoulder : public FuzzySet
{
private:
// wartoķci, które okreķlają ksztaģt tego pliku FLV
double m_dPeakPoint;
double m_dLeftOffset;
double m_dRightOffset;
public:
FuzzySet_RightShoulder(double peak,
double LeftOffset,
double RightOffset):
FuzzySet( ((peak + RightOffset) + peak) / 2),
m_dPeakPoint(peak),
m_dLeftOffset(LeftOffset),
m_dRightOffset(RightOffset)
{}
// ta metoda oblicza stopieņ czģonkostwa dla okreķlonej wartoķci
double CalculateDOM(double val)const;
};
Tym razem reprezentatywną wartoķcią jest punkt ķrodkowy pģaskowyŋu ģopatki. Metoda CalculateDOM jest równieŋ nieco inna
double FuzzySet_RightShoulder::CalculateDOM(double val)const
{
// sprawdž, czy przesunięcie moŋe wynosiæ zero
if (isEqual(0, m_dLeftOffset) && isEqual(val,m_dMidPoint))
{
return 1.0;
}
//znajdž DOM, jeķli pozostanie po ķrodkur
if ( (val <= m_dMidPoint) && (val > (m_dMidPoint - m_dLeftOffset)) )
{
double grad = 1.0 / m_dLeftOffset;
return grad * (val - (m_dMidPoint - m_dLeftOffset));
}
//znajdž DOM, jeķli jest na prawo od ķrodka
else if (val > m_dMidPoint)
{
return 1.0;
}
// poza zakresem tego FLV, zwróæ zero
else
{
return 0.0;
}
}
Znowu wszystko jest bardzo proste. Nie chcę marnowaæ papieru, wymieniając kod dla innych zbiorów rozmytych; są równie jasne i ģatwe do zrozumienia. Przejdžmy do rozmytej klasy zmiennych językowych.
Tworzenie rozmytej klasy zmiennej językowej
Klasa rozmytej zmiennej językowej FuzzyVariable zawiera std :: mapę wskažników do instancji FuzzySets - zestawów, które skģadają się na jej róŋnorodnoķæ. Ponadto ma metody dodawania rozmytych zestawów oraz zamazywania i rozmraŋania wartoķci. Za kaŋdym razem, gdy zestaw elementów jest tworzony i dodawany do FLV, zakresy min / maks FLV są ponownie obliczane i przypisywane do wartoķci m_dMinRange i m_dMaxRange. Prowadzenie rejestru zakresu domeny FLV w ten sposób pozwala logice ustaliæ, czy wartoķæ przedstawiona dla fuzyfikacji jest poza zakresem, i w razie potrzeby wyjķæ z twierdzeniem. Oto deklaracja klasy:
class FuzzyVariable
{
private:
typedef std::map
private:
// nie zezwalaj na kopie
FuzzyVariable(const FuzzyVariable&);
FuzzyVariable& operator=(const FuzzyVariable&);
private:
//mapa zbiorów rozmytych zawierających tę zmiennąe
MemberSets m_MemberSets;
// minimalna i maksymalna wartoķæ zakresu tej zmiennej
double m_dMinRange;
double m_dMaxRange;
// ta metoda jest wywoģywana z górną i dolną granicą zestawu za kaŋdym razem, gdy
// dodano nowy zestaw w celu odpowiedniego dostosowania górnego i dolnego zakresu wartoķci
void AdjustRangeToFit(double min, double max);
// klient pobiera odwoģanie do zmiennej rozmytej, gdy instancja jest
// stworzony za pomocą FuzzyModule :: CreateFLV (). Aby uniemoŋliwiæ klientowi usunięcie
// instancja FuzzyVariable destruktor jest prywatny i
// Klasa FuzzyModule zaprzyjažniģa się.
˜FuzzyVariable();
friend class FuzzyModule;
public:
FuzzyVariable():m_dMinRange(0.0),m_dMaxRange(0.0){}
// następujące metody tworzą instancje zestawów nazwanych w metodzie
// nazwa i dodaje je do mapy zestawu czģonków. Za kaŋdym razem, gdy zestaw dowolnego typu jest
// dodano m_dMinRange i m_dMaxRange są odpowiednio dostosowane. Wszystkie zdjęcia
// metody zwracają klasę proxy reprezentującą nowo utworzoną instancję. To
// zestaw proxy moŋe byæ uŋywany jako operand podczas tworzenia podstawy reguģy.
FzSet AddLeftShoulderSet(std::string name,
double minBound,
double peak,
double maxBound);
FzSet AddRightShoulderSet(std::string name,
double minBound,
double peak,
double maxBound);
FzSet AddTriangularSet(std::string name,
double minBound,
double peak,
double maxBound);
FzSet AddSingletonSet(std::string name,
double minBound,
double peak,
double maxBound);
// fuzzify wartoķæ, obliczając jej DOM w kaŋdym podzbiorze tej zmiennej
void Fuzzify(double val);
// defuzzify zmiennej przy uŋyciu metody MaxAv
double DeFuzzifyMaxAv()const;
// defuzzify zmiennej przy uŋyciu metody centroid
double DeFuzzifyCentroid(int NumSamples)const;
};
Zauwaŋ, ŋe metody tworzenia i dodawania zestawów nie uŋywają tych samych parametrów, które same wykorzystują same klasy zbiorów rozmytych. Na przykģad, oprócz ģaņcucha reprezentującego nazwę, metoda AddLeftShoulderSet przyjmuje jako parametry minimalną granicę, punkt szczytowy i maksymalną granicę, podczas gdy klasa FuzzySet_Triangle wykorzystuje wartoķci okreķlające punkt ķrodkowy, lewe przesunięcie i prawe przesunięcie. Ma to na celu uczynienie metod bardziej instynktownymi dla klientów. Zazwyczaj podczas tworzenia plików FLV szkicujesz ich zestawy elementów na papierze (lub wyobraŋasz je sobie w gģowie), co znacznie uģatwia odczytywanie wartoķci od lewej do prawej zamiast obliczania wszystkich przesunięæ. Oprzyjmy się na naszym przykģadzie i dodajmy niektóre zestawy czģonków do DistToTarget
FuzzyModule fm;
FuzzyVariable& DistToTarget = fm.CreateFLV("DistToTarget");
FzSet Target_Close = DistToTarget.AddLeftShoulderSet("Target_Close", 0, 25, 150);
FzSet Target_Medium = DistToTarget.AddTriangularSet("Target_Medium", 25, 50, 300);
FzSet Target_Far = DistToTarget.AddRightShoulderSet("Target_Far", 150, 300, 500);
Te kilka wierszy kodu tworzy plik FLV pokazany na rysunku
Zauwaŋ, w jaki sposób instancja FzSet jest zwracana przez kaŋdą z metod dodawania zestawu. Jest to klasa proxy, która naķladuje funkcjonalnoķæ konkretnego FuzzySet. Konkretne same instancje są zawarte w FuzzyVariable :: m_MemberSets. Te proxy są uŋywane jako operandy podczas konstruowania rozmytej bazy reguģ.
Projektowanie klas do budowania reguģ rozmytych
Jest to niewątpliwie najbardziej upiorna częķæ kodowania rozmytego systemu. Jak się dowiedziaģeķ, kaŋda rozmyta reguģa ma postaæ:
JEĶLI poprzednia WTEDY konsekwencja
gdzie poprzednikiem i następcą mogą byæ pojedyncze zbiory rozmyte lub zbiory zģoŋone, które są wynikiem operacji. Aby byæ elastycznym, moduģ rozmyty musi byæ w stanie obsģugiwaæ reguģy przy uŋyciu nie tylko operatora AND, ale takŋe operatorów OR i NOT oraz rozmytych ŋywopģotów, takich jak BARDZO i FAIRY. Innymi sģowy, moduģ powinien byæ w stanie poradziæ sobie z następującymi reguģami:
JEŊELI a1 i a2 NASTĘPNIE c1
JEĶLI BARDZO (a1) I (a2 LUB a3) NASTĘPNIE c1
JEŊELI [(a1 ORAZ a2) LUB (NIE (a3) ORAZ BARDZO (a4))] NASTĘPNIE [c1 AND c2]
W ramach ostatecznej reguģy obserwuj, jak operator OR dziaģa na podstawie wyniku (a1 ORAZ a2) i wyniku (NIE (a3) ORAZ BARDZO (a4)). Z kolei AND w drugim okresie dziaģa na wynikach NOT (a3) i VERY (a4). Jeķli to nie jest wystarczająco skomplikowane, reguģa ma dwa konsekwencje AND razem. Oczywiķcie ten przykģad jest zdecydowanie przesadzony i jest bardzo maģo prawdopodobne, ŋe programiķci zajmujący się sztuczną inteligencją gry będą wymagaæ takiej reguģy (chociaŋ nie byģoby to niczym niezwykģym w wielu rozmytych systemach eksperckich), ale dobrze ilustruje to, co mam na myķli - kaŋdy klasa operatora warta swojej soli musi byæ w stanie obsģugiwaæ poszczególne operandy oraz ich kompozycje i operatory w identyczny sposób. To wyražnie kolejny obszar, w którym na ratunek przychodzi zģoŋony wzór. Powtórzmy: Ideą zģoŋonego wzoru jest zaprojektowanie wspólnego interfejsu zarówno dla obiektów zģoŋonych, jak i atomowych; kiedy zostanie zģoŋony wniosek o kompozyt, przekaŋe go jednemu lub większej liczbie swoich dzieci (patrz rozdziaģ 9, jeķli potrzebujesz bardziej szczegóģowego wyjaķnienia zģoŋonego wzoru). W reguģach rozmytych operandy (zbiory rozmyte) są obiektami atomowymi, a operatory (AND, OR, BARDZO itd.) Są kompozytami. Dlatego wymagana jest klasa, która definiuje wspólny interfejs dla obu tych typów obiektów aby wprowadziæ w ŋycie. Ta klasa nazywa się FuzzyTerm i wygląda następująco:
class FuzzyTerm
{
public:
virtual ~FuzzyTerm(){}
// wszystkie warunki muszą implementowaæ wirtualnego konstruktora
virtual FuzzyTerm* Clone()const = 0;
// pobiera stopieņ czģonkostwa tego terminu
virtual double GetDOM()const=0;
// wyjaķnia stopieņ czģonkostwa w tym terminie
virtual void ClearDOM()=0;
// metoda aktualizacji DOM konsekwenta po uruchomieniu reguģy
virtual void ORwithDOM(double val)=0;
};
Poniewaŋ jakakolwiek operacja rozmyta na jednym lub kilku zestawach powoduje powstanie zģoŋonego zbioru rozmytego, ten maģy interfejs jest wystarczający do zdefiniowania obiektów do uŋycia w konstrukcji reguģ rozmytych. Rysunek 10.27 pokazuje związek między klasą FuzzyTerm, rozmytą klasą operatorską AND FzAND (kompozyt), a obiektem proxy FzSet z zestawem rozmytym (atomowym).
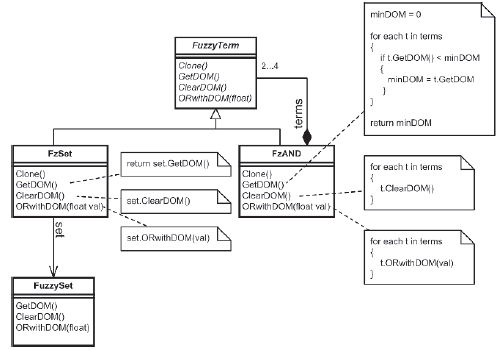
Zauwaŋ, jak obiekt FzAND moŋe zawieraæ od dwóch do czterech FuzzyTerms, a gdy jedna z jego metod zostanie wywoģana, iteruje się przez kaŋdą z nich i przekazuje wywoģanie odpowiedniej metodzie kaŋdego dziecka lub uŋywa interfejsu do obliczenia wyniku. Zauwaŋ teŋ, jak FzSet dziaģa jako proxy dla obiektu FuzzySet. Klasa proxy sģuŋy do ukrywania prawdziwej klasy przed klientem; dziaģa jako surogat prawdziwej klasy, aby kontrolowaæ dostęp do niej. Klasy proxy przechowują odwoģanie do klasy, dla której są surogatem, a gdy klient wywoģuje metodę klasy proxy, przekazuje wywoģanie do równowaŋnej metody odwoģania. Za kaŋdym razem, gdy FuzzySet jest dodawany do FuzzyVariable, klient otrzymuje do niego serwer proxy w postaci FzSet. Ten serwer proxy moŋe zostaæ skopiowany i uŋyty wiele razy przy tworzeniu bazy reguģ. Bez względu na to, ile razy jest kopiowany, zawsze zastępuje ten sam obiekt, co znacznie upraszcza projekt, poniewaŋ nie musimy się martwiæ ķledzeniem kopii FuzzySets podczas tworzenia reguģ. Korzystając z tego projektu dla wszystkich operatorów i operandów, moŋna stworzyæ bardzo przyjazny interfejs do tworzenia rozmytych reguģ. Klienci uŋywają skģadni w następujący sposób, aby dodaæ reguģy:
fm.AddRule (FzAND (Target_Far, Ammo_Low), niepoŋądane);
Nawet zģoŋony termin pokazany wczeķniej jest ģatwy do zbudowania:
fm.AddRule (FzOR (FzAND (a1, a2), FzAND (FzNOT (a3), FzVery (a4))), FzAND (c1, c2));
Aby to lepiej zrozumieæ, zagģębimy się w treķæ metody AddRule. Oto implementacja:
void FuzzyModule :: AddRule (FuzzyTerm i poprzednik, FuzzyTerm i konsekwencja)
{
m_Rules.push_back (nowy FuzzyRule (poprzednik, konsekwencja));
}
Jak widaæ, caģa ta metoda polega na utworzeniu lokalnej kopii klasy FuzzyRule. Reguģa FuzzyRule zawiera instancję FuzzyTerm oznaczającą poprzednika i kolejną oznaczającą konsekwencję. Te instancje są kopiami FuzzyTerms uŋywanych do konstruowania FuzzyRule. Jest to jeden z powodów, dla których kaŋda podklasa FuzzyTerm musi implementowaæ metodę klonowania wirtualnego konstruktora. Oto lista, dzięki czemu moŋesz dokģadnie zobaczyæ, co się dzieje.
class FuzzyRule
{
private:
// poprzednik (zwykle zģoŋony z kilku rozmytych zbiorów i operatorów)
const FuzzyTerm* m_pAntecedent;
// konsekwencja (zwykle pojedynczy zestaw rozmytych, ale moŋe byæ kilka AND razem)
FuzzyTerm* m_pConsequence;
// nie ma sensu zezwalaæ klientom na kopiowanie reguģ
FuzzyRule(const FuzzyRule&);
FuzzyRule& operator=(const FuzzyRule&);
public:
FuzzyRule(FuzzyTerm& ant,
FuzzyTerm& con):m_pAntecedent(ant.Clone()),
m_pConsequence(con.Clone())
{}
˜FuzzyRule(){delete m_pAntecedent; delete m_pConsequence;}
void SetConfidenceOfConsequentToZero(){m_pConsequence->ClearDOM();}
// ta metoda aktualizuje DOM (zaufanie) następującego terminu o
// DOM poprzedzającego terminu.
void Calculate()
{
m_pConsequence->ORwithDOM(m_pAntecedent->GetDOM());
}
};
Okay, myķlę, ŋe to wystarczający komentarz do projektu klas uŋywanych do tworzenia i wykonywania rozmytych reguģ. Jeķli chcesz zagģębiæ się w trzewia, radzę sprawdziæ implementację klas FzAND, FzOR, FzVery i FzFairly, które moŋna znaležæ w folderze common / fuzzy. Diagram UML na rysunku 10.28 pomoŋe ci równieŋ zrozumieæ, w jaki sposób wszystkie obiekty uŋywane przez moduģ rozmytych są ze sobą powiązane. Kontynuując kod pokazany wczeķniej w tej sekcji, oto jak moŋna dodaæ zasadę dla wyrzutni rakiet do moduģu rozmytego:
/ * najpierw zainicjuj rozmyty moduģ za pomocą plików FLV * /
/ * teraz dodaj zestaw reguģ * /
fm.AddRule(FzAND(Target_Close, Ammo_Loads), Undesirable);
fm.AddRule(FzAND(Target_Close, Ammo_Okay), Undesirable);
fm.AddRule(FzAND(Target_Close, Ammo_Low), Undesirable);
fm.AddRule(FzAND(Target_Medium, Ammo_Loads), VeryDesirable);
fm.AddRule(FzAND(Target_Medium, Ammo_Okay), VeryDesirable);
fm.AddRule(FzAND(Target_Medium, Ammo_Low), Desirable);
fm.AddRule(FzAND(Target_Far, Ammo_Loads), Desirable);
fm.AddRule(FzAND(Target_Far, Ammo_Okay), Desirable);
fm.AddRule(FzAND(Target_Far, Ammo_Low), Undesirable);
Po zainicjowaniu moduģu FuzzyModule wprowadzanie wartoķci i obliczenie wyražnych wniosków jest bezbolesne. Oto metoda, która wģaķnie to robi:
double CalculateDesirability(FuzzyModule& fm, double dist, double ammo)
{
// fuzzify wejķcia
fm.Fuzzify("DistToTarget", dist);
fm.Fuzzify("AmmoStatus", ammo);
// ta metoda automatycznie przetwarza reguģy i odblokowuje
// wywnioskowany wniosek
return fm.DeFuzzify("Desirability", FuzzyModule::max_av);
}
Po wywoģaniu metody DeFuzzify reguģy są przetwarzane i wywnioskowany wniosek rozbity na wyražną wartoķæ. Oto metoda twojego przejrzenia:
inline double
FuzzyModule::DeFuzzify(const std::string& NameOfFLV, DefuzzifyMethod method)
{
// najpierw upewnij się, ŋe nazwa FLV istnieje w tym module
assert ( (m_Variables.find(NameOfFLV) != m_Variables.end()) &&
"
// wyczyķæ DOM ze wszystkich następstw
SetConfidencesOfConsequentsToZero();
// przetwarza zasady
std::vector
for (curRule; curRule != m_Rules.end(); ++curRule)
{
(*curRule)->Calculate();
}
// teraz odtajmy wynikowy wniosek przy uŋyciu okreķlonej metody
switch (method)
{
case centroid:
return m_Variables[NameOfFLV]->DeFuzzifyCentroid(NumSamples);
case max_av:
return m_Variables[NameOfFLV]->DeFuzzifyMaxAv();
}
return 0;
}
Jak Raven uŋywa klas logiki rozmytej
Kaŋda broņ Kruka posiada instancję rozmytego moduģu, który jest inicjowany FLV i reguģami specyficznymi dla broni. Wszystkie bronie pochodzą z abstrakcyjnej klasy bazowej Raven_Weapon i implementują metodę GetDesirability, która aktualizuje moduģ rozmytych i zwraca wyražny wynik poŋądania. Oto odpowiednie częķci Raven_Weapon:
class Raven_Weapon
{
protected:
FuzzyModule m_FuzzyModule;
/* DODATKOWE SZCZEGÓĢY POMINIĘTE */
public:
virtual double GetDesirability(double DistToTarget)=0;
/* DODATKOWE SZCZEGÓĢY POMINIĘTE */
};
Co kilka cykli aktualizacji (domyķlnie dwa razy na sekundę) boty sprawdzają kaŋdą z broni w ekwipunku, aby ustaliæ, która z nich jest najbardziej poŋądana, biorąc pod uwagę odlegģoķæ do celu bota i pozostaģej amunicji, i wybiera tę o najwyŋszej celowoķci wynik. Kod implementujący tę logikę wymieniono poniŋej.
void Raven_Bot::SelectWeapon()
{
// wystarczy uruchomiæ ten kod, tylko jeķli obecny jest cel
if (m_pTargSys->isTargetPresent())
{
// obliczyæ odlegģoķæ do celu
double DistToTarget = Vec2DDistance(Pos(), m_pTargSys->GetTarget()->Pos());
// dla kaŋdej broni w ekwipunku oblicz jej celowoķæ biorąc pod uwagę
//obecna sytuacja. Wybrano najbardziej poŋądaną broņ
double BestSoFar = MinDouble;
std::vector
for (curWeap = m_Weapons.begin(); curWeap != m_Weapons.end(); ++curWeap)
{
// chwyciæ celowoķæ tej broni (celowoķæ opiera się na
// odlegģoķæ do celu i pozostaģa amunicja)
double score = (*curWeap)->GetDesirability(DistToTarget);
// jeķli jest to jak dotąd najbardziej poŋądane, wybierz go
if (score > BestSoFar)
{
BestSoFar = score;
// umieķæ broņ w ręce bota.
m_pCurrentWeapon = *curWeap;
}
}
}
}
Metoda grzebienia
Jednym z gģównych problemów z rozmytymi systemami wnioskowania jest to, ŋe wraz ze wzrostem zģoŋonoķci problemu liczba wymaganych reguģ roķnie w zastraszającym tempie. Na przykģad prosty moduģ stworzony do rozwiązania problemu wyboru broni wymagaģ tylko dziewięciu reguģ - po jednej dla kaŋdej moŋliwej kombinacji poprzednich zestawów - ale jeķli dodamy jeszcze jeden FLV, ponownie skģadający się z trzech zestawów elementów, wówczas 27 reguģ jest niezbędnych. Jest znacznie gorzej, jeķli liczba zestawów elementów w kaŋdym pliku FLV musi zostaæ zwiększona, aby uzyskaæ większą precyzję. Na przykģad 125 reguģ jest wymaganych dla systemu z trzema plikami FLV, z których kaŋdy zawiera pięæ zestawów elementów. Dodaj kolejny plik FLV z pięciu zestawów czģonków i liczba gwaģtownie wzrasta do 625 zasad! Ten efekt jest znany jako eksplozja kombinatoryczna i stanowi ogromny problem przy projektowaniu rozmytych systemów do krytycznych aplikacji, którymi są oczywiķcie gry komputerowe. Na szczęķcie dla nas mamy rycerza w lķniącej zbroi w postaci Williama Combsa, inŋyniera z Boeingiem. W 1997 roku Combs zaproponowaģ system, który umoŋliwia liniowy wzrost liczby reguģ z liczbą zestawów elementów zamiast wykģadniczo. Tabela 10.4 pokazuje liczbę reguģ wymaganych przy uŋyciu metody tradycyjnej w porównaniu z metodą grzebieniową (zakģadając, ŋe kaŋdy plik FLV zawiera pięæ zestawów elementów).

Duŋa róŋnica, jestem pewien, ŋe się zgodzisz! Teoria leŋąca u podstaw metody Combs dziaģa na zasadzie, ŋe:
JEĶLI Target_Far AND Ammo_Loads THEN Poŋądane
jest logicznie równowaŋne z:
JEĶLI Target_Far THEN Poŋądany
LUB
JEŊELI Ammo_Load się THEB Poŋądany
Korzystając z tej zasady, moŋna zdefiniowaæ podstawę reguģy, która zawiera tylko jedną reguģę na kolejny zestaw elementów. Na przykģad dziewięæ podanych wczeķniej zasad dotyczących wyrzutni rakiet:
Zasada 1. JEĶLI Target_Far ORAZ ĢADUNKI amunicji NIŊ Poŋądane
Zasada 2. JEĶLI Target_DALNIE ORAZ Amunicja jest OK TO Niepoŋądane
Zasada 3. JEĶLI Target_Dalej I Amunicja_NISKIE TO Niepoŋądane
Zasada 4. JEĶLI Target_Medium ORAZ ĢADUNKI amunicji WTEDY Bardzo poŋądane
Zasada 5. JEĶLI Target_Medium ORAZ amunicja jest OK, to bardzo poŋądane
Zasada 6. JEĶLI Target_Medium I Ammo_LOW THEN Poŋądane
Zasada 7. JEĶLI Target_Close AND Ammo_Loads THEN Niepoŋądane
Reguģa 8. JEĶLI Target_Close AND Ammo_Okay THEN Niepoŋądane
Zasada 9. JEĶLI Target_Close AND Ammo_LOW THEN Niepoŋądane
Moŋna sprowadziæ do szeķciu zasad:
Zasada 1. JEĶLI Target_Close THEN Niepoŋądane
Zasada 2. JEĶLI Target_MEDIUM NASTĘPNIE Bardzo poŋądane
Zasada 3. JEĶLI Target_DALNIE TO Niepoŋądane
Zasada 4. JEĶLI Amunicja_NISKIE TO Niepoŋądana
Zasada 5. JEĶLI Amunicja jest OK POTEM
Zasada 6. JEĶLI Amunicja ģaduje się wtedy bardzo poŋądane
To nie jest duŋa redukcja kursu, ale jak zauwaŋyģeķ w Tabeli 10.4, metoda Combs staje się coraz bardziej atrakcyjną alternatywą wraz ze wzrostem liczby zestawów elementów uŋywanych przez zmienne lingwistyczne. Jedną z wad tej metody jest to, ŋe zmiany w regule to podstawa wymagana do przyjęcia logiki nie jest intuicyjna. Combs podaje dobry przykģad w swoim artykule "Metoda grzebienia do szybkiego wnioskowania": Kiedy dostaģem moje pierwsze prawo jazdy, mój agent ubezpieczeniowy przypomniaģ mi, ŋe skoro miaģem szesnaķcie lat ORAZ singla ORAZ singla, moja skģadka ubezpieczeniowa byģaby wysoka. Póžniej, po studiach, powiedziaģ, ŋe poniewaŋ miaģem okoģo dwudziestki i byģam męŋczyzną ORAZ ŋonaty, moja skģadka ubezpieczeniowa byģaby umiarkowanie niska. To ostatnie stwierdzenie wydaje się mieæ bardziej intuicyjny sens niŋ nasz alternatywny format: poniewaŋ miaģem okoģo dwudziestki, moja skģadka ubezpieczeniowa byģaby umiarkowanie niska, LUB poniewaŋ byģem męŋczyzną, moja skģadka ubezpieczeniowa byģaby umiarkowanie wysoka, LUB odkąd byģem ŋonaty, moja skģadka ubezpieczeniowa byģaby niska. Ŋaden agent, który nie chce zamknąæ sprzedaŋy, nie wypowie tak pozornie sprzecznego oķwiadczenia. Jednym z problemów związanych z [tą metodą] jest to, ŋe transformacja z [(p i q) następnie r] do [(p następnie r) lub (q następnie r)] przesuwa nasze skupienie z jednej reguģy na coķ, co wydaje się byæ unią dwóch (lub więcej) zasad. Ponadto, poniewaŋ kaŋda z tych alternatywnych reguģ moŋe zawieraæ róŋne konsekwencje, wydaje się, ŋe są ze sobą sprzeczne: albo moja premia jest wysoka LUB moja premia jest niska. Jak to moŋe byæ jedno i drugie? Dla wielu z was przeciwdziaģanie tej metodzie moŋe byæ przeszkodą, ale jeķli tak, to wytrwaj - zdecydowanie warto spróbowaæ, jeķli pracujesz z duŋymi zasadami.