Praktyczne planowanie ķcieŋki
W częķci 5 zobaczyģeķ, jak agenci mogą wykorzystywaæ wykresy nawigacyjne do planowania ķcieŋek między lokalizacjami w ķrodowisku. Jednak jeķli chodzi o wdroŋenie tej teorii w praktyce, przekonasz się, ŋe istnieje wiele róŋnych problemów do rozwiązania, zanim agenci zaczną się przemieszczaæ tak, jak chcesz. Tu omówimu=y wiele praktycznych problemów napotkanych podczas projektowania moduģów planowania ķcieŋek agentów gier. Chociaŋ wersje demonstracyjne w tym rozdziale są oparte na frameworku Raven, większoķæ technik ma zastosowanie w wielu róŋnych gatunkach gier.
Budowa wykresu nawigacyjnego
Aby wyznaczyæ ķcieŋkę od A do B za pomocą algorytmu wyszukiwania, ķrodowisko gry musi zostaæ podzielone na struktury danych, które algorytmy mogą eksplorowaæ: wykres nawigacyjny. Poniewaŋ istnieje wiele sposobów reprezentowania geometrii, która skģada się na ķwiat gry - na przykģad na podstawie kafelków, wektorów lub wielokątów - trudno się dziwiæ, ŋe istnieje wiele metod przeksztaģcania istotnych informacji przestrzennych w strukturę danych podobną do wykresu. Przeanalizujmy kilka popularnych metod stosowanych we wspóģczesnych grach.
Na podstawie kafelków
Gry oparte na kafelkach lub komórkach, takie jak gry obficie występujące w gatunkach RTS i gier wojennych, mają duŋe, a czasem zģoŋone ķrodowisko oparte na kwadratach lub heksach. Dlatego sensowne jest zaprojektowanie wykresu nawigacyjnego gry wokóģ tych komórek: kaŋdy węzeģ wykresu reprezentuje ķrodek komórki, a krawędzie wykresu oznaczają poģączenia między sąsiednimi komórkami. W grach tego typu od czasu do czasu manewrowanie jednostką gry - jak czoģg lub ŋoģnierz - będzie się wiązaæ z róŋnymi rodzajami terenu. Woda i bģoto są przecieŋ o wiele trudniejsze do pokonania przez zbiornik Shermana niŋ asfalt lub ubita ziemia. Poniewaŋ kaŋda komórka zwykle przypisuje okreķlony typ terenu przez projektanta mapy, uŋywanie tej informacji do waŋenia krawędzi wykresu nawigacyjnego jest trywialne. Algorytmy zastosowane do przeszukiwania wykresu mogą wykorzystaæ te dodatkowe informacje do ustalenia odpowiednich ķcieŋek przez teren, takich, które unikają wody i bģota lub omijają wzgórza, a nie ich wierzchoģki. Wadą uŋywania komórek jako szkieletu dla grafu nawigacyjnego jest to, ŋe przestrzenie wyszukiwania mogą szybko staæ się bardzo duŋe. Nawet skromna mapa komórkowa 100 x 100 będzie wymagaģa wykresu zģoŋonego z maksymalnie 10 000 węzģów i 78 000 (lub więcej) krawędzi. Biorąc pod uwagę, ŋe gry RTS zwykle mają jednoczeķnie kilkadziesiąt, a nawet setki jednostek AI, przy czym wiele z nich ŋąda przeszukiwania wykresów na kaŋdym etapie aktualizacji, to cholernie duŋo do zrobienia, nie wspominając o związanych z tym kosztach pamięci . Na szczęķcie dostępnych jest wiele metod zmniejszania obciąŋenia, które omówimy w dalszej częķci
Punkty widocznoķci
Wykres nawigacyjny punktów widocznoķci (POV) jest tworzony przez umieszczenie węzģów wykresu, zwykle ręcznie, w waŋnych punktach ķrodowiska, tak aby kaŋdy węzeģ wykresu miaģ linię widzenia co najmniej jednego innego. Umieszczone ostroŋnie węzģy wykresu utworzą wykres ģączący wszystkie waŋne obszary w geometrii ķwiata. Rysunek poniŋszt pokazuje prosty wykres POV utworzony dla mapy Raven (Raven_DM1).
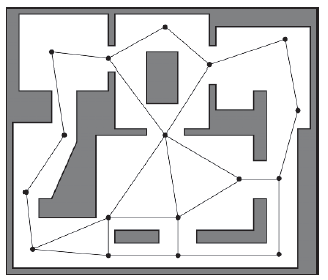
Jedną z cech wykresów POV jest to, ŋe moŋna je ģatwo rozszerzyæ, aby zawieraģy węzģy, które podają informacje ponad danymi dotyczącymi ģącznoķci. Na przykģad, węzģy moŋna ģatwo dodaæ do wykresu POV, aby reprezentowaæ dobre pozycje snajperskie, osģonowe lub zasadzkowe. Minusem jest to, ŋe jeķli mapa gry jest duŋa i zģoŋona, projektant mapy moŋe poķwięciæ bardzo duŋo cennego czasu na opracowanie pozycji i ulepszenie wykresu. Wykres POV moŋe byæ równieŋ problematyczny, jeķli planujesz doģączyæ dowolny rodzaj funkcji generowania mapy, poniewaŋ musisz takŋe opracowaæ zautomatyzowaną metodę generowania struktury wykresu POV, aby nowe mapy byģy przydatne. (Dlatego niektóre gry nie mają funkcji losowego generowania map.) Jednym z rozwiązaņ tego problemu jest jednak stosowanie technik rozszerzonej geometrii.
Rozszerzona geometria
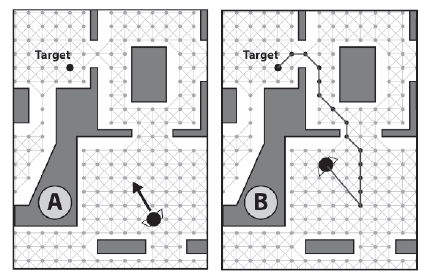
Jeķli ķrodowisko gry jest zbudowane z wielokątów, moŋna wykorzystaæ informacje zawarte w tych ksztaģtach, aby automatycznie utworzyæ wykres POV, który w przypadku duŋych map moŋe byæ oszczędnoķcią czasu. Osiąga się to najpierw poprzez rozszerzenie wielokątów o wielkoķæ proporcjonalną do promienia ograniczającego agentów gry. Patrz rysunki A i B.
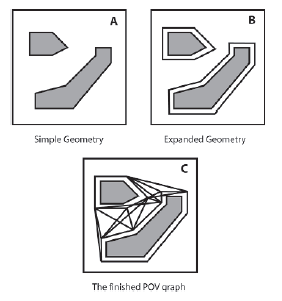
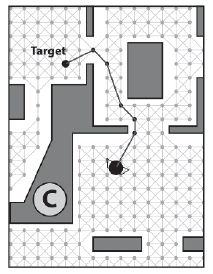
Wierzchoģki definiujące tę rozszerzoną geometrię są następnie dodawane jako węzģy do wykresu nawigacyjnego. Na koniec uruchamiany jest algorytm w celu sprawdzenia linii wzroku między wierzchoģkami, a krawędzie są odpowiednio dodawane do wykresu. Rysunek C pokazuje gotowy wykres nawigacyjny. Poniewaŋ wielokąty są powiększane o kwotę nie mniejszą niŋ agent w promieniu ograniczającym agent moŋe przeszukiwaæ wynikowy wykres nawigacyjny, aby tworzyæ ķcieŋki, które bezpiecznie negocjują otoczenie bez wpadania na ķciany.
NavMesh
Jednym z podejķæ, które zyskuje na popularnoķci wķród twórców gier, jest wykorzystanie sieci wypukģych wielokątów, zwanych navmesh, w celu opisania dostępnych obszarów gry. Wypukģy wielokąt ma tę cenną wģaķciwoķæ, ŋe umoŋliwia swobodne przemieszczanie się z dowolnego punktu wielokąta do dowolnego innego. Jest to przydatne, poniewaŋ umoŋliwia reprezentację ķrodowiska za pomocą wykresu, na którym kaŋdy węzeģ reprezentuje przestrzeņ wypukģą (zamiast punktu). Rysunek pokazuje mapę z rysunku pierwszego *podzieloną na partycje w taki sposób.
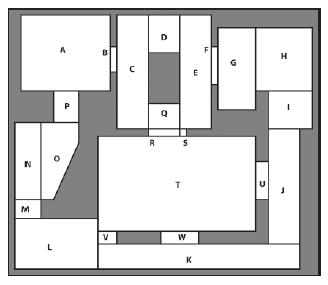
Dlaczego to dobra rzecz? Cóŋ, navmeshes są wydajne. Struktura danych wymagana do przechowywania jednej jest zwarta i moŋna ją bardzo szybko przeszukaæ. Ponadto tam, gdzie ķrodowiska zbudowane są w caģoķci z wielokątów - podobnie jak większoķæ gier typu 3D FPS - moŋliwe jest uŋycie algorytmów do automatycznego podziaģu obszarów dostępnych na mapach.
Wykres nawigacyjny Raven
Poniewaŋ dają mi największą moŋliwoķæ wykazania róŋnorodnego zakresu technik, wykresy nawigacyjne dla map Raven są tworzone przy uŋyciu metody POV. Widziaģeķ wczeķniej, w jaki sposób nawigator pokazany na rysunku pierwszym zostaģ utworzony przez ręczne pozycjonowanie węzģów w edytorze map. W tym przykģadzie niewielka liczba węzģów zostaģa umieszczona na waŋnych skrzyŋowaniach. Poniewaŋ kaŋdy węzeģ skutecznie reprezentuje duŋy obszar przestrzenny, moŋna powiedzieæ, ŋe ten typ wykresu jest gruboziarnisty (lub ziarnisty). Gruboziarniste wykresy są bardzo zwartymi strukturami danych. Uŋywają bardzo maģo pamięci i są szybkie do wyszukiwania i stosunkowo ģatwe do utworzenia, chociaŋ mają kilka ograniczeņ. Rzuæmy okiem na niektóre z ich wad.
Gruboziarniste wykresy
Jeķli gra ogranicza tylko agentów do poruszania się wzdģuŋ krawędzi wykresu nawigacyjnego, takich jak ruch postaci w gamie gier Pac-Man, wówczas gruboziarnisty navgraph to ķwietny wybór. Jeķli jednak projektujesz grafik dla gry, w której postacie mają większą swobodę, zgrubne wykresy mogą byæ zwiastunem róŋnego rodzaju problemów. Na przykģad większoķæ gier RTS / RPG korzysta z systemu sterowania, w którym uŋytkownik moŋe rozkazywaæ postaciom, aby przejķæ do dowolnego nawigowanego obszaru mapy. Zwykle odbywa się to za pomocą kilku kliknięæ myszką, jednego, aby wybraæ NPC, a drugiego, aby wybraæ pozycję, w której powinien się przenieķæ. Aby przenieķæ NPC do pozycji AI musi wykonaæ następujące kroki:
1. Znajdž najbliŋszy widoczny węzeģ wykresu do bieŋącej lokalizacji NPC, powiedzmy, węzeģ A.
2. Znajdž najbliŋszy widoczny węzeģ wykresu do docelowej lokalizacji, powiedzmy, węzeģ B.
3. Uŋyj algorytmu wyszukiwania, aby znaležæ ķcieŋkę o najniŋszych kosztach od A do B.
4. Przenieķ NPC do węzģa A.
5. Przesuņ NPC wzdģuŋ ķcieŋki obliczonej w kroku 3.
6. Przenieķ NPC z B do miejsca docelowego.
Jeķli po tych krokach pojawi się gruboziarnisty wykres, taki jak pokazany wczeķniej, nieestetyczne ķcieŋki będą się regularnie pojawiaæ. Niektóre z tych zaģamaņ moŋna usunąæ za pomocą algorytmu wygģadzania ķcieŋki, takiego jak ten omówiony w dalszej częķci tego rozdziaģu, ale ze względu na zgrubnoķæ wykresu nawigacyjnego nadal będzie wiele sytuacji, w których agent zygzakuje nienaturalnie na początku i na koņcu punkty ķcieŋki. Co gorsza, w przypadku korzystania z gruboziarnistych wykresów prawie zawsze istnieje kilka pozycji na mapie, do których nie ma linii wzroku z ŋadnego z węzģów wykresu, co skutecznie czyni te obszary niewidocznymi dla dowolnego planisty ķcieŋki. Rysunek ilustruje dwie pozycje na mapie Raven_DM1, które są niedostępne dla narzędzia planowania ķcieŋki.
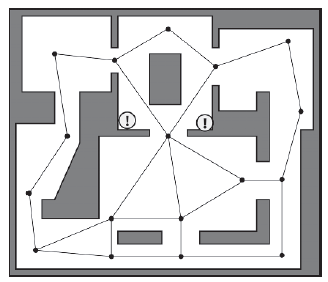
Te "niewidoczne" obszary są doķæ ģatwe do wykrycia podczas testowania maģej mapy, ale są znacznie trudniejsze do znalezienia wraz ze wzrostem zģoŋonoķci mapy. Znajduje to odzwierciedlenie w wielu grach, które zostaģy wydane z takimi problemami. Moŋesz zaobserwowaæ te problemy z pierwszej ręki, uruchamiając plik wykonywalny Raven_CoarseGraph. Po uruchomieniu demonstracji bot zbada ķrodowisko, tworząc ķcieŋki do losowo wybranych węzģów graficznych. Kliknij bota prawym przyciskiem myszy, aby go wybraæ, a zobaczysz ķcieŋkę, którą podąŋa, pokazaną jako serię czerwonych kropek. Zwróæ uwagę, jak ruch bota wygląda dobrze, o ile utrzymuje się na pozycjach na wykresie nawigacyjnym. Teraz ponownie kliknij prawym przyciskiem myszy bota, aby go "posiąķæ". Po zdobyciu moŋesz kliknąæ prawym przyciskiem myszy w dowolnym miejscu w ķrodowisku, a bot spróbuje obliczyæ ķcieŋkę do tego punktu (o ile punkt znajduje się w obszarze ŋeglownym mapy). Obserwuj, jak bot musi cofaæ się, aby podąŋaæ pewnymi ķcieŋkami.
Drobnoziarniste wykresy
Zģe ķcieŋki i niedostępne pozycje moŋna poprawiæ, zwiększając ziarnistoķæ wykresu nawigacyjnego. Rysunek poniŋej to przykģad bardzo drobno granulowanego wykresu utworzonego dla mapy Raven_DM1.
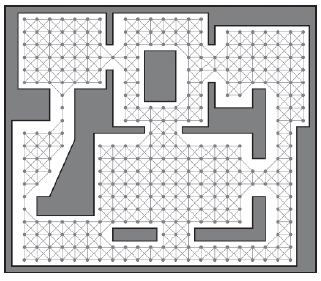
Ręczne tworzenie takiego wykresu jest niezwykle ŋmudne, więc do wykonania większoķci zadaņ edytor map wykorzystuje algorytm wypeģniania zalania. Więcej informacji znajduje się na poniŋszym pasku bocznym. Poniewaŋ drobnoziarniste wykresy są podobne w topologii do grafik nawigacyjnych opartych na kafelkach - i dlatego stanowią podobne wyzwania dla programisty AI - wykorzystam je jako podstawę do zademonstrowania technik opisanych w pozostaģej częķci. W ten sposób mam nadzieję zabiæ kilka ptaków jednym kamieniem, a pod koniec zrozumiesz, jak stworzyæ agenta zdolnego do planowania ķcieŋek w dowolnym ķrodowisku gry, czy to FPS, RTS, czy RPG.
Uŋywanie algorytmu Flood Fill do stworzenia wykresu nawigacyjnego
Aby uŋyæ algorytmu wypeģniania zalania do utworzenia wykresu nawigacyjnego, najpierw gdzieķ na mapie umieszczany jest pojedynczy węzeģ "zarodkowy". Patrz rysunek poniŋej, u góry w lewo. Algorytm "powiększa" wykres, rozszerzając węzģy i krawędzie na zewnątrz z nasion w kaŋdym dostępnym kierunku, a następnie z węzģów na skraju wykresu, aŋ do wypeģnienia caģego obszaru ŋeglownego. Rysunek pokazuje pierwsze szeķæ iteracji takiego procesu.
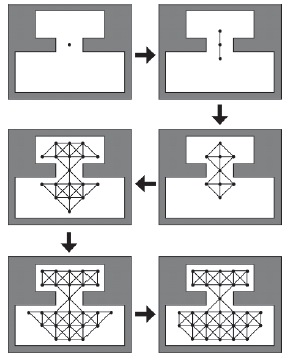
Jest to podobny rodzaj techniki malowania uŋywanej przez programy do wypeģniania nieregularnych ksztaģtów, z wyjątkiem tego, ŋe zamiast zalewaæ ksztaģt kolorem, edytor wykorzystuje algorytm do zalania mapy węzģami graficznymi i krawędziami. Poszczególne węzģy mogą byæ następnie przenoszone, usuwane lub dodawane przez projektanta w celu uzyskania poŋądanego rezultatu. Aby zapewniæ nieograniczony ruch agenta, podczas procesu algorytm zapewnia, ŋe wszystkie węzģy i krawędzie są ustawione w minimalnej odlegģoķci równej promieniu ograniczającemu agenta od ķcian.
Dodawanie przedmiotów do wykresu nawigacji Raven
Większoķæ gier zawiera przedmioty, które agent moŋe w jakiķ sposób odebraæ i wykorzystaæ. Te elementy moŋna dodawaæ jako węzģy do wykresu nawigacyjnego, umoŋliwiając sztucznej inteligencji planowania ķcieŋki ģatwe wyszukiwanie elementów i planowanie ķcieŋek do nich. Tam, gdzie jest wiele instancji tego samego przedmiotu, sztuczna inteligencja moŋe uŋyæ nawigatora, aby szybko ustaliæ, który jest najmniej kosztowny do osiągnięcia. Pamiętacie, jak w rozdziale 5 pokazaģem wam przykģad klasy węzģów grafowych zaprojektowanej specjalnie do uŋytku z grafami nawigacyjnymi? Na wypadek gdyby twoja pamięæ byģa tak sģaba jak moja, oto znowu lista:
template < class extra_info = void* >
class NavGraphNode : public GraphNode
{
protected:
// pozycja węzģa
Vector2D m_vPosition;
// często chcesz, aby węzeģ navgraph zawieraģ dodatkowe informacje.
// (na przykģad węzeģ moŋe reprezentowaæ pozycję typu elementu
// takie jak zdrowie, umoŋliwiając w ten sposób algorytmowi wyszukiwania przeszukanie wykresu
// dla tego typu elementu)
extra_info m_ExtraInfo;
public:
//ctors
NavGraphNode():m_ExtraInfo(extra_info()){}
NavGraphNode(int idx,
Vector2D pos):GraphNode(idx),
m_vPosition(pos),
m_ExtraInfo(extra_info())
{}
virtual ~NavGraphNode(){}
Vector2D Pos()const;
void SetPos(Vector2D NewPosition);
extra_info ExtraInfo()const;
void SetExtraInfo(extra_info info);
/* DODATKOWE SZCZEGÓĢY POMINIĘTE */
};
Jest to klasa węzģów uŋywana przez wykres nawigacyjny Raven. Jak wspomniano wczeķniej , typy przedmiotów w Raven pochodzą z klasy Trigger. Po dodaniu wyzwalacza do mapy za pomocą edytora map dodawany jest równieŋ węzeģ wykresu. Czģonek m_ExtraInfo tego węzģa ma przypisany wskažnik do elementu, z którym jest poģączony, umoŋliwiając w ten sposób zmodyfikowanemu algorytmowi wyszukiwania zapytanie o wykres nawigacji dla okreķlonych typów elementów, a takŋe dla okreķlonych indeksów węzģów.
WSKAZÓWKA. Projektując mapy niektórych gier, dobrze jest umieķciæ często uŋywane przedmioty, takie jak amunicja i zbroja, bezpoķrednio na najczęķciej uŋywanych ķcieŋkach agentów gry. Pomaga to agentom, poniewaŋ skupiają się na waŋniejszych celach gry, zamiast biegaæ w poszukiwaniu broni i amunicji.
Korzystanie z partycjonowania przestrzennego w celu przyspieszenia zapytaņ o bliskoķæ
Jedną z najczęķciej uŋywanych metod klasy planowania ķcieŋki jest funkcja, która okreķla najbliŋszy widoczny węzeģ dla danej pozycji. Jeķli to wyszukiwanie zostanie przeprowadzone przez iterację przez wszystkie węzģy w celu znalezienia najbliŋszego, wydajnoķæ nastąpi w czasie O (n2): Za kaŋdym razem, gdy liczba węzģów się podwoi, czas potrzebny na ich przeszukanie zwiększa się czterokrotnie. Jak widzieliķmy w rozdziale 3, skutecznoķæ takich wyszukiwaņ moŋna poprawiæ, stosując technikę podziaģu przestrzennego, taką jak podziaģ na komórki, drzewa BSP, drzewa quad lub dowolną z wielu dostępnych metod. W przypadku wykresów nawigacyjnych z kilkuset węzģów podziaģ przestrzenny daje radykalny wzrost prędkoķci, poniewaŋ czas wyszukiwania staje się funkcją gęstoķci węzģów, O (d), a nie liczbę węzģów; i od gęstoķci węzģów na caģym obrazie nawigacyjnym wydaje się byæ doķæ spójny, czas potrzebny na wykonanie zapytania o bliskoķæ węzģa będzie staģy. W związku z tym klasa Raven_Game dzieli na partycje węzģy navgraph przy uŋyciu metody przestrzeni komórkowej po zaģadowaniu mapy.
UWAGA. Nie ma napisanego kodu dla tej częķci jako takiej. Wszystkie demonstracje zostaģy utworzone przez kompilację plików projektu Raven z wģączonymi lub wyģączonymi niektórymi opcjami, aby zademonstrowaæ kaŋdą omawianą technikę. Z tego powodu dema uŋywają skompilowanych plików skryptowych Lua, aby zapobiec manipulowaniu przy opcjach, które mogą spowodowaæ awarię demonstracji. Aby uzyskaæ peģne prawa do kręcenia się, skompiluj wģaķciwy projekt Raven!
Tworzenie klasy PathPlanner
Większoķæ pozostaģej częķci tekstu zostanie wydana po opracowaniu klasy planowania ķcieŋki zdolnej do wykonywania i zarządzania licznymi ŋądaniami wyszukiwania grafów wymaganych przez bota Raven. Ta klasa nazywa się Raven_PathPlanner i kaŋdy bot będzie miaģ jej instancję. Klasa zacznie się w prosty sposób, ale w miarę postępów jej moŋliwoķci będą stopniowo rozszerzane, dając moŋliwoķæ zademonstrowania, jak rozwiązaæ wiele typowych problemów napotkanych podczas opracowywania sztucznej inteligencji planowania ķcieŋki. Najpierw rozwaŋmy minimalną funkcjonalnoķæ, jaką musi zapewniæ obiekt planowania ķcieŋki. Bot Raven przynajmniej powinien byæ w stanie zaplanowaæ ķcieŋkę z aktualnej pozycji do dowolnej innej lokalizacji, biorąc pod uwagę, ŋe obie pozycje są prawidģowe i moŋliwe do nawigacji, a ķcieŋka jest moŋliwa. Bot Raven powinien takŋe byæ w stanie zaplanowaæ ķcieŋkę o najniŋszym koszcie między swoją obecną pozycją a okreķlonym typem przedmiotu, takim jak pakiet zdrowia. W rezultacie klasa planowania ķcieŋki musi mieæ metody przeszukiwania navgraph w poszukiwaniu takich ķcieŋek i uzyskiwania dostępu do wynikowych danych ķcieŋki. Mając na uwadze te funkcje, spróbujmy najpierw w klasie planowania ķcieŋki.
class Raven_PathPlanner
{
private:
// dla czytelnoķci
enum {no_closest_node_found = -1};
private:
// Wskažnik do wģaķciciela tej klasy
Raven_Bot* m_pOwner;
// lokalne odniesienie do navgraph
const Raven_Map::NavGraph& m_NavGraph;
//to jest pozycja, którą bot chce zaplanowaæ ķcieŋkę do osiągnięcia
Vector2D m_vDestinationPos;
// zwraca indeks najbliŋszego widocznego i niezakģóconego węzģa graficznego do
// podana pozycja. Jeķli nie zostanie znaleziony, zwraca wyliczoną wartoķæ
// "no_closest_node_found"
int GetClosestNodeToPosition(Vector2D pos)const;
public:
Raven_PathPlanner(Raven_Bot* owner);
// znajduje ķcieŋkę o najniŋszym koszcie między pozycją agenta a celem
//pozycja. Wypeģnia ķcieŋkę listą punktów, jeķli wyszukiwanie zakoņczy się powodzeniem
// i zwraca true. Zwraca false, jeķli nie powiedzie się
bool CreatePathToPosition(Vector2D TargetPos, std::list
// znajduje ķcieŋkę o najniŋszym koszcie do wystąpienia klasy ItemType. Wypeģnia ķcieŋkę znakiem
// lista punktów, jeķli wyszukiwanie zakoņczy się powodzeniem i zwróci wartoķæ true. Zwraca
// false, jeķli się nie powiedzie
bool CreatePathToItem(unsigned int ItemType, std::list
};
Ta klasa zapewnia minimalną funkcjonalnoķæ wymaganą przez agenta gry. Przyjrzyjmy się bliŋej metodom tworzącym ķcieŋki.
Planowanie ķcieŋki do pozycji
Planowanie ķcieŋki z bieŋącej lokalizacji bota do miejsca docelowego jest proste. Planista ķcieŋki musi:
1. Znajdž najbliŋszy widoczny niezakģócony węzeģ grafowy do bieŋącej lokalizacji bota.
2. Znajdž najbliŋszy widoczny niezakģócony węzeģ wykresu do lokalizacji docelowej.
3. Uŋyj algorytmu wyszukiwania, aby znaležæ ķcieŋkę najmniejszych kosztów między nimi.
Poniŋszy kod uŋywa tych kroków. Komentarze powinny byæ odpowiednim wyjaķnieniem.
bool Raven_PathPlanner::CreatePathToPosition(Vector2D TargetPos,
std::list
{
// zanotuj pozycję docelową
m_vDestinationPos = TargetPos;
// jeķli cel nie jest zasģonięty od pozycji bota, ķcieŋka nie potrzebuje
// do obliczenia, a bot moŋe PRZYBYÆ bezpoķrednio w miejscu docelowym.
// isPathObstructed to metoda, która zaczyna się od początku
// pozycja, pozycja docelowa i promieņ encji i okreķla, czy
// agent tego rozmiaru jest w stanie poruszaæ się bez przeszkód między dwiema pozycjami.
// Sģuŋy tutaj do ustalenia, czy bot moŋe przejķæ bezpoķrednio do celu
// lokalizacja bez potrzeby planowania ķcieŋki.
if (!m_pOwner()->GetWorld()->isPathObstructed(m_pOwner->Pos(),
TargetPos,
m_pOwner->BRadius()))
{
path.push_back(TargetPos);
return true;
}
// znajdž najbliŋszy niezakģócony węzeģ w pozycji bota.
// GetClosestNodeToPosition to metoda odpytująca wykres nawigacyjny
// węzģy (przez partycję przestrzeņ komórkowa), aby okreķliæ najbliŋszą niezakģóconą
// węzeģ do podanego wektora pozycji. Sģuŋy tutaj do znalezienia najbliŋszego zdjęcia
// niezakģócony węzeģ do bieŋącej lokalizacji bota.
int ClosestNodeToBot = GetClosestNodeToPosition(m_pOwner->Pos());
// jeķli nie znaleziono widocznego węzģa, zwróæ bģąd. Nastąpi to, jeķli
// navgraph jest žle zaprojektowany lub jeķli botowi udaģo się zdobyæ
// * wewnątrz * geometrii (otoczonej ķcianami) lub przeszkody.
if (ClosestNodeToBot == no_closest_node_found)
{
return false;
}
// znajdž najbliŋszy widoczny niezakģócony węzeģ do pozycji docelowej
int ClosestNodeToTarget = GetClosestNodeToPosition(TargetPos);
// zwrócenie bģędu, jeķli występuje problem ze zlokalizowaniem widocznego węzģa z poziomu
//cel.
// Tego rodzaju rzeczy występują znacznie częķciej niŋ powyŋsze. Dla
// przykģad, jeķli uŋytkownik kliknie wewnątrz obszaru ograniczonego ķcianami lub wewnątrz zdjęcia
//obiekt.
if (ClosestNodeToTarget == no_closest_node_found)
{
return false;
}
// utwórz instancję klasy wyszukiwania A *, aby wyszukaæ ķcieŋkę między
// najbliŋszy węzeģ do bota i najbliŋszy węzeģ do pozycji docelowej. To
// Wyszukiwanie * będzie wykorzystywaæ heurystyczną linię euklidesową
typedef Graph_SearchAStar< Raven_Map::NavGraph, Heuristic_Euclid> AStar;
AStar search(m_NavGraph,
ClosestNodeToBot,
ClosestNodeToTarget);
// zģap ķcieŋkę
std::list
// jeķli wyszukiwanie się powiedzie, zamieņ indeksy węzģów na wektory pozycji
if (!PathOfNodeIndices.empty())
{
ConvertIndicesToVectors(PathOfNodeIndices, path);
// pamiętaj, aby dodaæ pozycję docelową na koņcu ķcieŋki
path.push_back(TargetPos);
return true;
}
else
{
// nie znaleziono ķcieŋki podczas wyszukiwania
return false;
}
}
Planowanie ķcieŋki do typu elementu
Jest lepszym algorytmem do wyszukiwania ķcieŋki o najniŋszym koszcie od aktualnej pozycji bota do konkretnej pozycji docelowej, ale co z tym, kiedy wymagana jest ķcieŋka o najniŋszych kosztach do typu przedmiotu - takiego jak wyrzutnia rakiet - gdzie moŋe byæ wiele wystąpienia w ķrodowisku okreķlonego typu? Aby obliczyæ koszt heurystyczny podczas wyszukiwania A*, algorytm musi mieæ zarówno pozycję žródģową, jak i docelową. W związku z tym, uŋywając A* do wyszukiwania najbliŋszej instancji typu przedmiotu, wyszukiwanie musi zostaæ zakoņczone dla kaŋdej instancji obecnej w ķwiecie gry, zanim ta o najniŋszej cenie będzie mogģa zostaæ wybrana jako najlepsza pozycja do przejķcia. Jest to w porządku, jeķli twoja mapa zawiera tylko garķæ instancji przedmiotu, ale co, jeķli zawiera wiele? W koņcu ķrodowiska gier RTS często zawierają dziesiątki, a nawet setki instancji zasobów, takich jak drzewa lub zģoto. Oznacza to, ŋe konieczne będzie przeprowadzenie wielu wyszukiwaņ A* w celu zlokalizowania tylko jednego elementu. To nie jest dobre. Gdy występuje wiele podobnych typów przedmiotów, algorytm Dijkstry jest lepszym wyborem. Jak się dowiedziaģeķ, algorytm Dijkstry "wyrasta" najkrótszą ķcieŋką na zewnątrz od węzģa gģównego do momentu osiągnięcia celu lub zbadania caģego wykresu. Gdy tylko szukany element zostanie znaleziony, algorytm zakoņczy się, a SPT będzie zawieraæ ķcieŋkę od katalogu gģównego do najbliŋszego elementu poŋądanego typu. Innymi sģowy, bez względu na to, ile wystąpieņ typu przedmiotu występuje w ķwiecie gry, algorytm Dijkstry musi zostaæ uruchomiony tylko raz, aby znaležæ ķcieŋkę najmniejszego kosztu do jednego z nich. W obecnej postaci klasa algorytmów Dijkstry uŋywana do tej pory w ta ksiąŋka zakoņczy się dopiero po znalezieniu okreķlonego indeksu węzģów. W rezultacie kod musi zostaæ zmieniony, aby wyszukiwanie zakoņczyģo się po lokalizacji aktywnego typu elementu (wyzwalacza). Moŋna to ģatwo osiągnąæ, okreķlając jako parametr szablonu polityka stanowi warunek zakoņczenia. Na przykģad:
template < class graph_type, class termination_condition >
class Graph_SearchDijkstra
{
/* POMINIĘTE */
};
Polityka warunków zakoņczenia jest klasą zawierającą pojedynczą metodę statyczną isSatisfied, która zwraca wartoķæ true, jeķli warunki wymagane do zakoņczenia są speģnione. Podpis isSatisfied wygląda następująco:
static bool isSatisfied (const graph_type & G, int target, int CurrentNodeIdx);
Zmodyfikowany algorytm Dijkstry moŋe korzystaæ z takich zasad, aby okreķliæ, kiedy naleŋy zakoņczyæ wyszukiwanie. Aby to uģatwiæ, linia:
// jeķli cel zostaģ znaleziony, wyjdž
if (NextClosestNode == m_iTarget) return;
found in Graph_SearchDijkstra::Search is replaced with:
// jeķli cel zostaģ znaleziony, wyjdž
if (termination_condition::isSatisfied(m_Graph,
m_iTarget,
NextClosestNode))
{
// zanotuj indeks węzģa, który speģniģ warunek. To
// jest tak, ŋe moŋemy pracowaæ wstecz od indeksu, aby wyodrębniæ ķcieŋkę z
// najkrótsza ķcieŋka.
m_iTarget = NextClosestNode;
return;
}
Jednak zanim ten dostosowany algorytm będzie mógģ byæ uŋyty, naleŋy stworzyæ odpowiednią politykę warunków zakoņczenia. W Raven typy przedmiotów są reprezentowane przez wyzwalacze dawców. Dlatego podczas wyszukiwania typu elementu wyszukiwanie powinno zakoņczyæ się, gdy zostanie zlokalizowany węzeģ wykresu, którego pole m_ExtraInfo wskazuje na aktywny wyzwalacz odpowiedniego typu. Oto klasa zasad warunku zakoņczenia, która koņczy wyszukiwanie na podstawie tych kryteriów:
template < class trigger_type >
class FindActiveTrigger
{
public:
template
static bool isSatisfied(const graph_type& G, int target, int CurrentNodeIdx)
{
bool bSatisfied = false;
// uzyskaæ odwoģanie do węzģa o podanym indeksie węzģów
const graph_type::NodeType& node = G.GetNode(CurrentNodeIdx);
// jeķli dodatkowe pole informacyjne wskazuje na wyzwalacz dawcy, sprawdž, aby się upewniæ, ŋe
// jest aktywny i ŋe jest poprawnego typu.
if ((node.ExtraInfo() != NULL) &&
node.ExtraInfo()->isActive() &&
(node.ExtraInfo()->EntityType() == target) )
{
bSatisfied = true;
}
return bSatisfied;
}
};
Uzbrojeni w ten warunek zakoņczenia i dostosowany algorytm wyszukiwania Dijkstra ģatwo jest znaležæ ķcieŋkę o najniŋszym koszcie do aktywnego elementu okreķlonego typu. Powiedzmy, ŋe chcesz znaležæ najbliŋszą paczkę zdrowia dla węzģa grafu z indeksem 6. Oto jak:
typedef FindActiveTrigger
typedef Graph_SearchDijkstra_TS
// utworzyæ wyszukiwanie
SearchDij dij(G,
//wykres6,
//węzeģ žródģowy
type_health);
// typ przedmiotu, którego szukamy
// zģap ķcieŋkę
std::list
gdzie type_health jest wartoķcią wyliczoną
UWAGA 3D. Mam nadzieję, ŋe rozumiesz, ŋe nie ma róŋnicy między wyszukiwaniem ķcieŋek w 3D a wyszukiwaniem ķcieŋek w 2D. Oczywiķcie, aby agent mógģ poruszaæ się w większoķci ķrodowisk 3D, musiaģby wykonywaæ takie czynnoķci jak skakanie wąwozami i korzystanie z wind, ale te rozwaŋania powinny byæ przejrzyste dla planisty ķcieŋki. Po prostu manifestują się jako korekty kosztów brzegowych, dzięki czemu algorytm wyszukiwania moŋe uwzględniæ koszt wykonania skoku, przejķcia przez póģkę, uŋycia windy lub zrobienia czegokolwiek, gdy szuka ķcieŋki o najniŋszym koszcie do pozycji docelowej. Jeķli nadal nie jest to oczywiste, zdecydowanie zalecamy cofnięcie się i ponowne przeczytanie częķci 5, pamiętając, ŋe wykres moŋe istnieæ w dowolnej liczbie wymiarów.
Ķcieŋki jako węzģy czy ķcieŋki jako krawędzie?
Do tej pory myķleliķmy o ķcieŋkach jako serii wektorów pozycji lub punktów trasy. Często ķcieŋki skģadające się z krawędzi wykresu zapewniają programistom AI dodatkową elastycznoķæ. Jako przykģad wežmy grę z postaciami niezaleŋnymi, w których ruch między punktami w otoczeniu musi byæ ograniczony do okreķlonego typu, np. "Palcami tutaj", "czoģgaæ się tutaj" lub "biegaæ szybko tutaj". Moŋesz pomyķleæ, ŋe odpowiednie węzģy navgraph gry mogą byæ opatrzone adnotacjami z flagami wskazującymi poŋądane zachowanie (na przykģad, węzeģ moŋe byæ oznaczony zachowaniem "palców", aby agent zacząģ palcami, jak tylko dotrze do tego węzģa), ale w æwiczyæ, istnieją problemy z tym podejķciem. Na przykģad ryc. 8.10 pokazuje częķæ wykresu nawigacyjnego, w którym jedna z krawędzi A - B przecina rzekę.
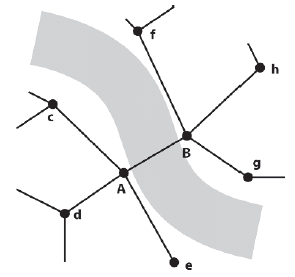
Projekt gry wymaga, aby agenci zmienili się na zachowanie "pģywania" podczas podróŋy z A do B (lub odwrotnie), więc węzģy A i B są opatrzone adnotacjami, aby to odzwierciedliæ. Powiedzmy, ŋe agent podąŋa ķcieŋką e - A - B - h. Gdy agent dotrze do węzģa A, jego zachowanie zmieni się na pģywanie i moŋe bezpiecznie przekroczyæ krawędž do B. Jak dotąd tak dobrze, ale niestety w tym momencie ma problemy. Kiedy osiągnie węzeģ B, który równieŋ jest opatrzony adnotacją o zachowaniu podczas pģywania, będzie kontynuowaģ pģywanie wzdģuŋ krawędzi B - h. Niedobrze. Jeķli to nie wystarczy, powiedzmy, ŋe agent chce podąŋaæ ķcieŋką e - A - c. Jak tylko osiągnie A, zacznie pģywaæ, mimo ŋe nie zamierza przekraczaæ rzeki!
Problem ten moŋna jednak ģatwo rozwiązaæ, jeķli krawędzie wykresu są opatrzone adnotacjami zamiast węzģów. W ten sposób agent moŋe ģatwo zapytaæ o informacje brzegowe, podąŋając ķcieŋką i odpowiednio zmieniæ zachowanie. Biorąc pod uwagę poprzedni przykģad, oznacza to, ŋe krawędž A - B jest opatrzona instrukcją pģywania, a wszystkie pozostaģe krawędzie instrukcją chodzenia (lub cokolwiek innego, co moŋe byæ odpowiednie). Teraz, gdy agent podąŋy ķcieŋką e - A - B - h, jego ruch będzie prawidģowy.
v
WSKAZÓWKA. Za pomocą adnotacji moŋna ģatwo okreķliæ zachowanie krawędzi, które jest modyfikowane podczas gry. Na przykģad, moŋesz zaprojektowaæ mapę, która ma prowizoryczny most - jak spadający kģód - przechodzący przez strumieņ, który agenci przechodzą normalnie, dopóki most nie zostanie zniszczony lub przeniesiony. Po zdjęciu mostu adnotacja na krawędzi zmienia się na "pģywanie", a jej koszt wzrasta, aby odzwierciedliæ dodatkową iloķæ czasu potrzebną do poruszania się wzdģuŋ niej. W ten sposób agenci nadal biorą pod uwagę krawędž podczas planowania ķcieŋek i odpowiednio zmodyfikują swoją animację, gdy ją przechodzą. (Moŋna nawet usunąæ / wyģączyæ krawędž, aby przedstawiæ warunki uniemoŋliwiające przepģyw strumienia, takie jak powódž).
Adnotowany przykģad klasy krawędzi
Adnotowaną krawędž moŋna ģatwo utworzyæ, wywodząc z GraphEdge i dodając dodatkowy element danych do reprezentowania flagi (lub flag, w zaleŋnoķci od tego, jakie informacje chcesz reprezentowaæ krawędž). Oto przykģad:
class NavGraphEdge : public GraphEdge
{
public:
// wyliczyæ niektóre flagi zachowania
enum BehaviorType
{
normal = 1 << 0,
tippy_toe = 1 << 1,
swim = 1 << 2,
crawl = 1 << 3,
creep = 1 << 4
};
protected:
// zachowanie związane z przechodzeniem przez tę krawędž
BehaviorType m_iBehavior;
/* DODATKOWE SZCZEGÓĢY POMINIĘTE */
};
WSKAZÓWKA. Jeķli twój projekt gry wymaga adnotacji krawędzi i / lub węzģa, często okaŋe się, ŋe dodatkowe pola w klasach węzģów / krawędzi są nieuŋywane (lub ustawione na "normalne") w większoķci przypadków w grafie nawigacyjnym. Moŋe to byæ znaczne marnotrawstwo pamięci, jeķli wykres jest duŋy. W takich przypadkach zalecam uŋycie tabeli odnoķników typu mapy skrótów lub, w przypadku duŋej iloķci adnotacji na instancję, utworzenie specjalnej struktury danych, do której kaŋda krawędž lub węzeģ moŋe przechowywaæ wskažnik.
Modyfikowanie klasy Planowanie ķcieŋki w celu dostosowania krawędzi z adnotacjami
Aby uwzględniæ adnotacje na krawędziach, naleŋy zmodyfikowaæ klasy planera ķcieŋki i algorytmu wyszukiwania, aby zwracaģy ķcieŋki zawierające dodatkowe informacje. Aby to uģatwiæ, Raven korzysta z klasy PathEdge - prostej struktury danych, która przechowuje informacje o poģoŋeniu węzģa i adnotacjach na krawędzi. Oto jego listing:
class PathEdge
{
private:
// pozycje węzģów žródģowego i docelowego, które ģączy ta krawędž
Vector2D m_vSource;
Vector2D m_vDestination;
// zachowanie związane z przechodzeniem przez tę krawędž
int m_iBehavior;
public:
PathEdge(Vector2D Source,
Vector2D Destination,
int Behavior):m_vSource(Source),
m_vDestination(Destination),
m_iBehavior(Behavior)
{}
Vector2D Destination()const;
void SetDestination(Vector2D NewDest);
Vector2D Source()const;
void SetSource(Vector2D NewSource);
int Behavior()const;
};
Metody Raven_PathPlanner :: CreatePath i odpowiadające im algorytmy wyszukiwania zostaģy nieznacznie zmienione, aby utworzyæ std :: list PathEdges. Oto lista zmodyfikowanej metody CreatePathToPosition
bool Raven_PathPlanner::CreatePathToPosition(Vector2D TargetPos,
std::list
{
// jeķli cel nie jest zasģonięty od pozycji bota, ķcieŋka nie potrzebuje
// do obliczenia, a bot moŋe PRZYBYÆ bezpoķrednio w miejscu docelowym.
if (!m_pOwner()->GetWorld()->isPathObstructed(m_pOwner->Pos(),
TargetPos,
m_pOwner->BRadius()))
{
// stwórz krawędž ģączącą aktualną pozycję bota i
// pozycja docelowa i wciķnij ją na listę ķcieŋek (oflagowany, aby uŋyæ
// "normalne" zachowanie)
path.push_back(PathEdge(m_pOwner->Pos(), TargetPos, NavGraphEdge::normal));
return true;
}
// znajdž najbliŋszy niezakģócony węzeģ w pozycji bota.
int ClosestNodeToBot = GetClosestNodeToPosition(m_pOwner->Pos());
if (ClosestNodeToBot == no_closest_node_found)
{
// ŋadna ķcieŋka nie jest moŋliwa
return false;
}
// znajdž najbliŋszy widoczny niezakģócony węzeģ do pozycji docelowej
int ClosestNodeToTarget = GetClosestNodeToPosition(TargetPos);
if (ClosestNodeToTarget == no_closest_node_found)
{
// ŋadna ķcieŋka nie jest moŋliwa
return false;
}
// utwórz instancję klasy wyszukiwania A*.
typedef Graph_SearchAStar
AStar search(m_NavGraph, ClosestNodeToBot, ClosestNodeToTarget);
// chwyæ ķcieŋkę jako listę PathEdges
path = search.GetPathAsPathEdges();
// jeķli wyszukiwanie zakoņczyģo się pomyķlnie, dodaj pierwszą i ostatnią krawędž ręcznie do
// ķcieŋka
if (!path.empty())
{
path.push_front(PathEdge(m_pOwner->Pos(),
path.front().GetSource(),
NavGraphEdge::normal));
path.push_back(PathEdge(path.back().GetDestination(),
TargetPos,
NavGraphEdge::normal));
return true;
}
else
{
// nie znaleziono ķcieŋki podczas wyszukiwania
return false;
}
}
Bot moŋe teraz ģatwo sprawdzaæ adnotacje na krawędziach ķcieŋek i wprowadzaæ odpowiednie zmiany w zachowaniu. W pseudokodzie za kaŋdym razem, gdy bot wysuwa nową krawędž listy, robi coķ takiego:
if (Bot.PathPlanner.CreatePathToPosition(destination, path))
{
PathEdge next = GetNextEdgeFromPath(path)
switch(next.Behavior)
{
case behavior_stealth:
set stealth mode
break
case behavior_swim
set swim mode
break
etc
}
Bot.MoveTo(NavGraph.GetNodePosition(next.To))
}
Od tego momentu moŋesz zaģoŋyæ, ŋe wszelkie wersje demonstracyjne korzystające ze struktury Raven będą uŋywaæ ķcieŋek krawędzi zamiast ķcieŋek punktów drogi.
WSKAZÓWKA . Niektóre ķwiaty gry zawierają teleportery lub "portale", których agenci mogą uŋywaæ do magicznego i natychmiastowego przemieszczania się między lokalizacjami. Jeķli Twoja gra korzysta z takich urządzeņ, nie będziesz w stanie uŋyæ algorytmu wyszukiwania A * do dokģadnego planowania ķcieŋek, poniewaŋ nie jest moŋliwe dostosowanie ich do heurystyki. Zamiast tego musisz uŋyæ alternatywnego algorytmu wyszukiwania, takiego jak Dijkstra.
Wygģadzanie ķcieŋki
Doķæ często, a zwģaszcza jeķli wykres nawigacyjny gry ma ksztaģt siatki, ķcieŋki utworzone przez planer ķcieŋek zawierają zwykle niepotrzebne krawędzie, powodując zaģamania, takie jak te pokazane na rysunku 8.11. Wyglądają nienaturalnie dla ludzkiego oka - w koņcu czģowiek nie robiģby tak niepotrzebnie takiego zygzaka, więc žle wygląda, gdy robi to agent gry. (Oczywiķcie jest to caģkowicie do przyjęcia, jeķli modelujesz koty domowe, które wydają się mieæ swój wģasny tajny program podczas przejķcia z A do B.)
Korzystając z A* i nawigatora opartego na siatce, moŋna tworzyæ lepiej wyglądające ķcieŋki za pomocą heurystycznej odlegģoķci na Manhattanie w poģączeniu z funkcją, która karze kaŋdą zmianę kierunku. (Pamiętaj, ŋe odlegģoķæ na Manhattanie to suma liczby kafelków przesuniętych poziomo i pionowo między rozwaŋanymi węzģami.) Jednak wytworzone ķcieŋki wciąŋ są dalekie od ideaģu ze względu na topologię wykresu ograniczającą skręty do przyrostów 45 stopni. Ta metoda równieŋ nie dziaģa z innym powszechnym problemem. Jak widzieliķmy, zanim planista ķcieŋki będzie mógģ wyszukaæ ķcieŋkę, musi znaležæ węzģy wykresu najbliŋsze pozycjom początkowym i docelowym, i nie zawsze będą to te, które dają naturalnie wyglądającą ķcieŋkę. Rozwiązanie dla obu tych problemów to przetwarzanie ķcieŋek koņcowych w celu "wygģadzenia" niepoŋądanych zaģamaņ. Jest na to kilka metod - jedna zgrubna i jedna precyzyjna.
Wygģadzanie ķcieŋki Szorstkie, ale szybkie
Stosunkowo szybka metoda wygģadzania ķcieŋki polega na sprawdzeniu "przejezdnoķci" między sąsiednimi krawędziami. Jeķli jedna z krawędzi jest zbyteczna, dwie krawędzie są zastępowane jedną.
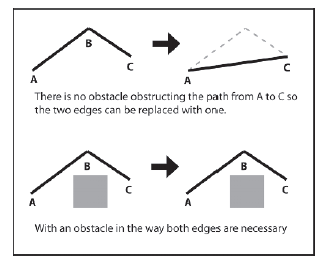
Algorytm dziaģa w następujący sposób: po pierwsze, dwa iteratory, E1 i E2, są umieszczone odpowiednio na pierwszej i drugiej krawędzi ķcieŋki. Następnie wykonuje się następujące kroki:
1. Chwyæ pozycję žródģową E1.
2. Chwyæ pozycję docelową E2.
3. Jeķli agent moŋe poruszaæ się między tymi dwoma pozycjami bez przeszkód przez geometrię ķwiata, przypisz miejsce docelowe E1 do miejsca docelowego E2 i usuņ E2 ze ķcieŋki. Ponownie przypisz E2 do nowej krawędzi po E1. (Naleŋy pamiętaæ, ŋe nie jest to prosty test pola widzenia, poniewaŋ naleŋy wziąæ pod uwagę rozmiar bytu - musi on byæ w stanie poruszaæ się między dwiema pozycjami bez uderzania w ķciany).
4. Jeķli agent nie moŋe poruszaæ się bez przeszkód między dwiema pozycjami, przypisz E2 do E1 i przejdž do E2.
5. Powtarzaj kroki, aŋ miejsce docelowe E2 będzie równe miejscu docelowemu ķcieŋki.
Zobaczmy, jak dziaģa ten algorytm i wygģadzamy ķcieŋkę pokazaną na rysunku 8.13. Najpierw E1 jest skierowany na pierwszą krawędž ķcieŋki, a E2 na drugą.
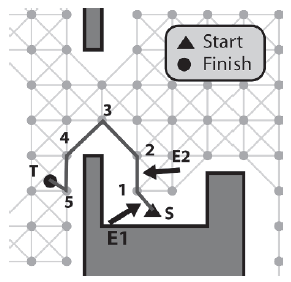
E1 jest krawędzią S - 1, a E2 krawędzią 1 - 2. Widzimy, ŋe agent moŋe poruszaæ się bez przeszkód między E1-> Žródģo (S) i E2-> Miejsce docelowe (2), więc pozycja indeksu węzģa 2 wynosi przypisany do E1-> Miejsce docelowe, krawędž 1-2 jest usuwana ze ķcieŋki, a E2 jest wysuwany, aby wskazywaæ na krawędž 2-3. (Zwróæ uwagę, ŋe krawędž wskazywana przez E1 ģączy teraz S - 2.)
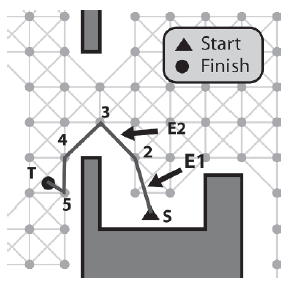
Po raz kolejny widzimy, ŋe agent jest w stanie poruszaæ się bez przeszkód między E1-> Žródģo (S) i E2-> Miejsce docelowe (3), więc ponownie ķcieŋka i iteratory są aktualizowane, dając sytuację pokazaną na rysunku
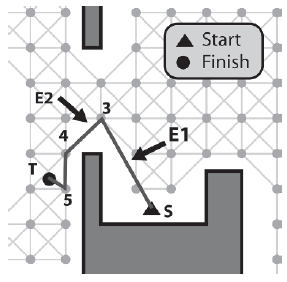
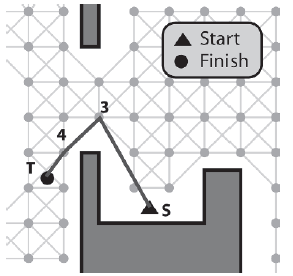
Tym razem jednak pozycje E1-> Žródģo (S) i E2-> Miejsce docelowe (4) są zablokowane. Dlatego oba E1 i E2 są zaawansowane o jedną krawędž.
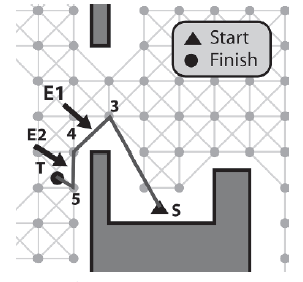
Ponownie, ķcieŋka między węzģami 3 i 5 jest zablokowana, więc E1 i E2 są zaawansowane. Tym razem, poniewaŋ ķcieŋka między 4 a T jest przejezdna, krawędzie są aktualizowane, aby to odzwierciedliæ, dając ostateczną wygģadzoną ķcieŋkę pokazaną na rysunku.
Kod žródģowy do wygģadzenia ķcieŋki przy uŋyciu tego algorytmu wygląda następująco:
void Raven_PathPlanner::SmoothPathEdgesQuick(std::list< PathEdge >& path)
{
// utwórz kilka iteratorów i skieruj je na przód ķcieŋki
std::list
// przyrost e2, tak aby wskazywaģ na krawędž po e1.
++e2;
// podczas gdy e2 nie jest ostatnią krawędzią na ķcieŋce, przejdž przez krawędzie, sprawdzając
// aby sprawdziæ, czy agent moŋe poruszaæ się bez przeszkód z węzģa žródģowego
// e1 do węzģa docelowego e2. Jeķli agent moŋe poruszaæ się między nimi
// pozycje, wówczas dwie krawędzie są zastępowane jedną krawędzią.
while (e2 != path.end())
{
// sprawdž, czy nie ma przeszkód, odpowiednio wyreguluj i usuņ krawędzie
if ( m_pOwner->canWalkBetween(e1->Source(), e2->Destination()) )
{
e1->SetDestination(e2->Destination());
e2 = path.erase(e2);
}
else
{
e1 = e2;
++e2;
}
}
}
Wygģadzanie ķcieŋki Precyzyjne, ale powolne
Niestety, poprzedni algorytm nie jest idealny. Jeķli przyjrzysz się powyŋszemu rysunkowi , znowu widaæ, ŋe dwie ostatnie krawędzie moŋna ģatwo zastąpiæ jedną, jak pokazano na rysunku
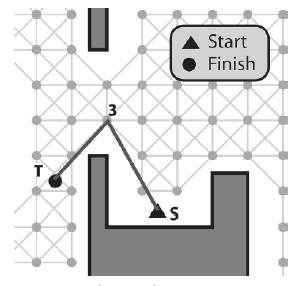
Algorytm tego nie zauwaŋyģ, poniewaŋ sprawdzaģ tylko przejezdnoķæ między sąsiadującymi krawędziami. Bardziej precyzyjny algorytm wygģadzania musi iterowaæ wszystkie krawędzie od E1 do krawędzi koņcowej za kaŋdym razem, gdy E1 jest przesuwany. Jednak, choæ precyzyjna, metoda ta jest znacznie wolniejsza, poniewaŋ naleŋy wykonaæ wiele dodatkowych testów skrzyŋowaņ. Oczywiķcie, jakiego algorytmu wygģadzania uŋywasz lub czy w ogóle decydujesz się na wygģadzanie, zaleŋy od iloķci dostępnego czasu procesora i wymagaņ twojej gry. Kod bardziej precyzyjnie wygģadzający ķcieŋkę wygląda następująco:
void Raven_PathPlanner::SmoothPathEdgesPrecise(std::list
{
// utwórz kilka iteratorów
std::list
// wskaŋ e1 na początek ķcieŋki
e1 = path.begin();
while (e1 != path.end())
{
// punkt e2 na krawędzi bezpoķrednio po e1
e2 = e1;
++e2;
// podczas gdy e2 nie jest ostatnią krawędzią na ķcieŋce, przejdž przez krawędzie,
// sprawdzanie, czy agent moŋe się poruszaæ bez przeszkód z poziomu
// węzeģ žródģowy e1 do węzģa docelowego e2. Jeķli agent moŋe się przenieķæ
// między tymi pozycjami, wówczas wszelkie krawędzie między e1 i e2 są
// zastąpiony jedną krawędzią.
while (e2 != path.end())
{
// sprawdž, czy nie ma przeszkód, odpowiednio wyreguluj i usuņ krawędzie
if ( m_pOwner->canWalkBetween(e1->Source(), e2->Destination()) )
{
e1->SetDestination(e2->Destination());
e2 = path.erase(++e1, ++e2);
e1 = e2;
--e1;
}
else
{
++e2;
}
}
++e1;
}
}
Moŋesz zobaczyæ oba te algorytmy w akcji, uruchamiając demo Raven_PathSmoothing.
UWAGA. Jeķli mapa korzysta z krawędzi wykresu opatrzonych specjalnymi zachowaniami lub jeķli agenci mają inne ograniczenia, takie jak ograniczony promieņ skrętu, algorytmy wygģadzania naleŋy zmodyfikowaæ, aby zapobiec usunięciu waŋnych krawędzi. Zobacz žródģo projektu Raven jako przykģad.
Metody zmniejszania obciąŋenia procesora
Skoki obciąŋenia mają miejsce, gdy liczba cykli procesora wymaganych przez silnik gry przekracza liczbę dostępnych cykli. Jeķli w grze biegnie mnóstwo agentów kontrolowanych przez AI, wszyscy są w stanie ŋądaæ ķcieŋek w dowolnym momencie, wówczas mogą wystąpiæ gwaģtowne obciąŋenia, gdy zbyt wielu z nich jednoczeķnie zaŋąda wyszukiwania. Gdy tak się stanie, przepģyw pģynu w grze zostanie przerwany, gdy procesor spróbuje nadąŋyæ za stawianymi mu wymaganiami, tworząc w ten sposób gwaģtowny, jąkający się ruch. Oczywiķcie jest to zģa rzecz i naleŋy jej unikaæ, gdy tylko jest to moŋliwe. Kolejne strony poķwięcone będą metodom, które zmniejszają prawdopodobieņstwo skoków obciąŋenia poprzez zmniejszenie narzutu związanego z aktualizacją ŋądaņ planowania ķcieŋki.
Wstępnie obliczone ķcieŋki
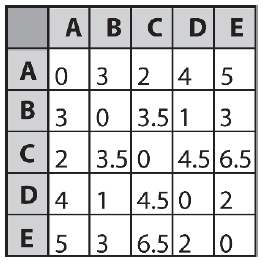
Jeķli twoje ķrodowisko gry jest statyczne i masz do dyspozycji pamięæ, dobrą opcją dla zmniejszenia obciąŋenia procesora jest uŋycie wstępnie obliczonych tabel odnoķników, umoŋliwiających bardzo szybkie okreķlenie ķcieŋek. Moŋna je obliczyæ w dowolnym dogodnym czasie, na przykģad gdy mapa jest odczytywana z pliku lub tworzona przez edytor map i przechowywana wraz z danymi mapy. Tabela przeglądowa musi zawieraæ trasy z kaŋdego węzģa na wykresie nawigacyjnym do kaŋdego innego węzģa na wykresie nawigacyjnym. Moŋna to obliczyæ za pomocą algorytmu Dijkstry, aby utworzyæ drzewo najkrótszych ķcieŋek (SPT) dla kaŋdego węzģa na wykresie. (Pamiętaj, ŋe SPT jest poddrzewem navgraph zakorzenionym w węžle docelowym, który zawiera najkrótszą ķcieŋkę do kaŋdego innego węzģa.) Informacje są następnie wyodrębniane i przechowywane w dwuwymiarowej tablicy liczb caģkowitych. Na przykģad, biorąc pod uwagę wykres pokazany na rysunku 8.19, odpowiednia tabela odnoķników jest taka, jak pokazano na rysunku
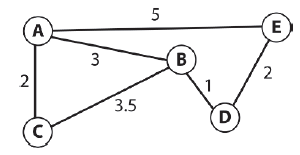

Wpisy w tabeli pokazują następny węzeģ, do którego agent powinien przejķæ na ķcieŋce od początku do miejsca docelowego. Na przykģad, aby okreķliæ ķcieŋkę najmniejszego kosztu od C do E, odsyģamy C do E, dając węzeģ B. Węzeģ B jest następnie odsyģany do miejsca docelowego, aby daæ D, i tak dalej, aŋ pozycja tabeli będzie równowaŋna węzeģ docelowy. W tym przypadku otrzymujemy ķcieŋkę C - B - D - E, która jest najkrótszą ķcieŋką od C do E. Stworzy tabelę wyszukiwania wszystkich par dla dowolnego typu wykresu z interfejsem podobnym do SparseGraph. To wygląda tak
template < class graph_type >
std::vector
{
enum {no_path = -1};
// utwórz tabelę 2D elementów ustawionych na wyliczoną wartoķæ no_path
std::vector
std::vector
for (int source=0; source
// obliczyæ SPT dla tego węzģa
Graph_SearchDijkstra
std::vector
// teraz, gdy mamy SPT, ģatwo jest przeszukaæ go wstecz, aby znaležæ
// najkrótsze ķcieŋki z kaŋdego węzģa do tego węzģa žródģowego
for (int target = 0; target
if (source == target)
{
shortest_paths[source][target] = target;
}
else
{
int nd = target;
while ((nd != source) && (spt[nd] != 0))
{
shortest_paths[spt[nd]->From][target]= nd;
nd = spt[nd]->From;
}
}
}// następny węzeģ docelowy
}// następny węzeģ žródģowy
return shortest_paths;
}
Wstępnie obliczone koszty
Czasami agent gry musi obliczyæ koszt podróŋy z jednego miejsca do drugiego. Na przykģad, wraz z innymi funkcjami, agent moŋe wziąæ pod uwagę koszt przedmiotu gry, decydując, czy chce odebraæ ten przedmiot. Wyszukiwanie w celu ustalenia tych kosztów dla kaŋdego typu elementu na kaŋdym etapie aktualizacji AI będzie bardzo kosztowne, jeķli wykres nawigacyjny jest duŋy i / lub istnieje wiele elementów tego samego rodzaju. W takich sytuacjach tabela wstępnie obliczonych kosztów moŋe okazaæ się nieoceniona. Jest to skonstruowane w podobny sposób jak tabela tras dla wszystkich par omówiona w ostatniej sekcji, z tym wyjątkiem, ŋe elementy tabeli reprezentują caģkowity koszt przejķcia najkrótszą drogą z jednego węzģa do drugiego. Zobacz rysunek
Kod do utworzenia takiej tabeli jest następujący:
template < class graph_type >
std::vector
{
std::vector
std::vector
for (int source=0; source
// przeszukaj
Graph_SearchDijkstra
// iteruj przez kaŋdy węzeģ na wykresie i oblicz koszty podróŋy do
// ten węzeģ
for (int target = 0; target
if (source != target)
{
PathCosts[source][target]= search.GetCostToNode(target);
}
}// następny węzeģ docelowy
}// następny węzeģ žródģowy
return PathCosts;
}
Planowanie ķcieŋki w okreķlonym czasie
Alternatywą dla wstępnego obliczania tabel odnoķników w celu zmniejszenia obciąŋenia procesora jest przydzielenie staģej iloķci zasobów procesora na krok aktualizacji dla wszystkich ŋądaņ wyszukiwania i równomierne rozdzielenie tych zasobów pomiędzy wyszukiwania. Osiąga się to poprzez podzielenie wyszukiwania na wiele etapów czasowych, technikę znaną jako dzielenie czasu. Aby ten pomysģ zadziaģaģ, wymagana jest dodatkowa praca, ale w przypadku niektórych gier warto poķwięciæ ten wysiģek, poniewaŋ obciąŋenie procesora związane z wyszukiwaniem wykresów jest staģe, bez względu na to, ilu agentów wysyģa ŋądania.
UWAGA . Chciaģbym wyjaķniæ, ŋe wyszukiwanie ķcieŋek czasowych jest przesadą w przypadku gry z garstką agentów, takich jak Raven, ale to ķwietna technika do rozwaŋenia, czy Twoja gra ma dziesiątki lub setki agentów, a zwģaszcza jeķli tworzysz platformę konsolową, poniewaŋ pomaga ci ŋyæ w ograniczeniach sprzętowych.
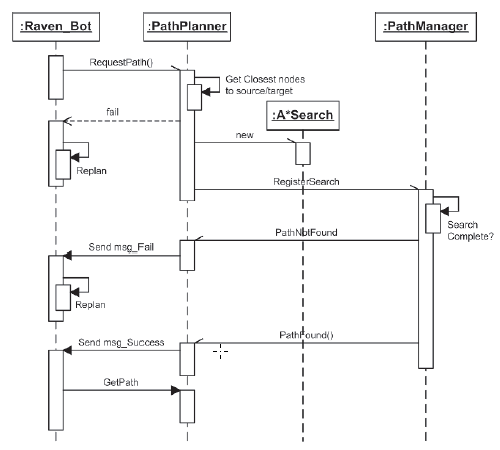
Przede wszystkim wyszukiwania Dijkstra i A* muszą zostaæ zmodyfikowane w taki sposób, aby mogģy przeszukiwaæ wykres na wielu etapach aktualizacji. Następnie, gdy agenci ŋądają wyszukiwania, ich planiķci ķcieŋek tworzą wystąpienia odpowiednich wyszukiwaņ (A * lub Dijkstra) i rejestrują się w klasie menedŋera ķcieŋek. Menedŋer ķcieŋek prowadzi listę wskažników do wszystkich aktywnych planistów ķcieŋek, które iteruje przez kaŋdy krok, równomiernie dzieląc między nimi dostępne zasoby procesora. Gdy wyszukiwanie zakoņczy się pomyķlnie lub ķcieŋka nie zostanie znaleziona, planista ķcieŋki powiadomi wģaķciciela, wysyģając mu wiadomoķæ. Rysunek pokazuje schemat sekwencji typu UML procesu.
Czas przyjrzeæ się szczegóģowym modyfikacjom wymaganym do przeprowadzenia tego procesu. Zacznijmy od zbadania, w jaki sposób adaptowane są klasy algorytmów wyszukiwania A* i Dijkstry.
Modyfikowanie algorytmów wyszukiwania w celu dostosowania do podziaģu czasu
Algorytmy wyszukiwania A* i Dijkstra zawierają pętlę, która powtarza następujące kroki:
1. Zģap następny węzeģ z kolejki priorytetowej.
2. Dodaj węzeģ do drzewa najkrótszych ķcieŋek.
3. Sprawdž, czy węzeģ jest celem.
4. Jeķli węzeģ nie jest celem, sprawdž węzģy, z którymi jest poģączony, umieszczając je w kolejce priorytetowej, gdy jest to wģaķciwe. Jeķli węzģem jest cel, zwrot sukcesu.
Będziemy odnosiæ się do pojedynczej iteracji tych kroków jako cyklu wyszukiwania. Poniewaŋ powtarzane iteracje ostatecznie zakoņczą wyszukiwanie, moŋna uŋyæ cykli wyszukiwania, aby podzieliæ wyszukiwanie na wiele etapów czasowych. W konsekwencji klasy algorytmów wyszukiwania A * i Dijkstry są modyfikowane, aby zawieraģy metodę o nazwie CycleOnce, która zawiera kod wymagany do podjęcia pojedynczego cyklu wyszukiwania. Jest to stosunkowo ģatwe, tworząc instancję kolejki priorytetowej jako czģonka klasy i inicjując ją za pomocą indeksu węzģa žródģowego w konstruktorze. Ponadto algorytm musi zostaæ nieznacznie zmodyfikowany, aby CycleOnce zwróciģ wyliczoną wartoķæ wskazującą status wyszukiwania. Moŋe to byæ jeden z następujących stanów: docelowy_found, docelowy_found lub search_incomplete. Klient moŋe wtedy wywoģywaæ CycleOnce wielokrotnie, dopóki zwracana wartoķæ nie wskaŋe zakoņczenia wyszukiwania. Oto lista metody CycleOnce algorytmu A* z ustalonym przedziaģem czasowym.
template < class graph_type, class heuristic >
int Graph_SearchAStar_TS
{
// jeķli PQ jest pusty, cel nie zostaģ znaleziony
if (m_pPQ->empty())
{
return target_not_found;
}
// pobierz węzeģ o najniŋszym koszcie z kolejki
int NextClosestNode = m_pPQ->Pop();
// umieķæ węzeģ w SPT
m_ShortestPathTree[NextClosestNode] = m_SearchFrontier[NextClosestNode];
// jeķli cel zostaģ znaleziony, wyjdž
if (NextClosestNode == m_iTarget)
{
return target_found;
}
// teraz, aby przetestowaæ wszystkie krawędzie doģączone do tego węzģa
Graph::ConstEdgeIterator EdgeItr(m_Graph, NextClosestNode);
for (const GraphEdge* pE=EdgeItr.beg(); !EdgeItr.end(); pE=EdgeItr.nxt())
{
/* TEN SAM, JAK W POPRZEDNIM ALGORYTMIE */
}
// są jeszcze węzģy do zbadania
return search_incomplete;
}
WSKAZÓWKA. Jeķli gra wykorzystuje agentów rozmieszczonych w oddziaģach lub plutonach, nie musisz planowaæ ķcieŋki dla kaŋdego czģonka plutonu za kaŋdym razem, gdy pluton musi przejķæ z punktu A do B; wystarczy zaplanowaæ pojedynczą ķcieŋkę dla lidera plutonu i sprawiæ, aby wszyscy inni czģonkowie plutonu podąŋali za tym liderem (stosując odpowiednie zachowanie sterujące).
Tworzenie wspólnego interfejsu dla algorytmów wyszukiwania
Biorąc pod uwagę, ŋe planista ķcieŋki moŋe wykorzystywaæ wyszukiwania A * i Dijkstry (odpowiednio do wyszukiwania pozycji lub pozycji), wygodnie jest im udostępniæ wspólny interfejs. W rezultacie zarówno pokrojona w czasie klasa A *, jak i pokrojona w czasie klasa Dijkstry wywodzą się z wirtualnej klasy o nazwie Graph_SearchTimeSliced. Oto deklaracja interfejsu:
template < class edge_type >
class Graph_SearchTimeSliced
{
public:
enum SearchType{AStar, Dijkstra};
private:
SearchType m_SearchType;
public:
Graph_SearchTimeSliced(SearchType type):m_SearchType(type){}
virtual ˜Graph_SearchTimeSliced(){}
// Po wywoģaniu ta metoda uruchamia algorytm przez jeden cykl wyszukiwania.
// metoda zwraca wyliczoną wartoķæ (target_found, target_not_found,
// search_incomplete) wskazujący status wyszukiwania
virtual int CycleOnce()=0;
// zwraca wektor krawędzi zbadanych przez algorytm
virtual std::vector
// zwraca caģkowity koszt do celu
virtual double GetCostToTarget()const=0;
// zwraca ķcieŋkę jako listę PathEdges
virtual std::list
SearchType GetType()const{return m_SearchType;}
};
Klasa planowania ķcieŋki moŋe teraz tworzyæ instancję dowolnego rodzaju wyszukiwania i przypisywaæ ją do pojedynczego wskažnika. Poniŋsza lista jest zaktualizowaną wersją klasy Raven_PathPlanner i ilustruje dodatkowe dane i metody wymagane do uģatwienia tworzenia ŋądaņ ķcieŋki podzielonej na przedziaģy czasowe.
class Raven_PathPlanner
{
private:
// wskažnik do wystąpienia bieŋącego algorytmu wyszukiwania wykresów.
Graph_SearchTimeSliced* m_pCurrentSearch;
/* DODATKOWE SZCZEGÓĢY POMINIĘTE */
public:
// tworzy instancję wyszukiwania wedģug przedziaģu czasu A * i rejestruje ją w
// menedŋer ķcieŋek
bool RequestPathToItem(unsigned int ItemType);
// tworzy instancję czasowego wyszukiwania i rejestrów Dijkstry
// z menedŋerem ķcieŋki
bool RequestPathToTarget(Vector2D TargetPos);
// menedŋer ķcieŋek wywoģuje to w celu wykonania iteracji raz przez cykl wyszukiwania
// aktualnie przypisanego algorytmu wyszukiwania. Po zakoņczeniu wyszukiwania
// metoda wysyģa wģaķcicielowi wiadomoķæ z msg_NoPathAvailable lub
// msg_PathReady wiadomoķci.
int CycleOnce()const;
// wywoģywany przez agenta po otrzymaniu powiadomienia o zakoņczeniu wyszukiwania
//z powodzeniem. Metoda wyodrębnia ķcieŋkę z m_pCurrentSearch, dodaje
// dodatkowe krawędzie odpowiednie do typu wyszukiwania i zwraca je jako listę
// PathEdges.
Path GetPath();
};
Metoda Raven_PathPlanner :: CycleOnce wywoģuje metodę CycleOnce aktualnie utworzonego wystąpienia wyszukiwania i sprawdza wynik. Jeķli wynik wskazuje na sukces lub niepowodzenie, do wģaķciciela klasy wysyģany jest komunikat, aby umoŋliwiæ podjęcie odpowiednich dziaģaņ. Aby to wyjaķniæ, oto wykaz tej metody:
int Raven_PathPlanner::CycleOnce()const
{
assert (m_pCurrentSearch &&
"
int result = m_pCurrentSearch->CycleOnce();
// powiadom bota o niepowodzeniu znalezienia ķcieŋki
if (result == target_not_found)
{
Dispatcher->DispatchMsg(SEND_MSG_IMMEDIATELY,
SENDER_ID_IRRELEVANT,
m_pOwner->ID(),
Msg_NoPathAvailable,
NO_ADDITIONAL_INFO);
}
// powiadom bota o znalezieniu ķcieŋki
else if (result == target_found)
{
// jeķli szukano typu elementu, to ostatni węzeģ na ķcieŋce będzie
// reprezentują wyzwalacza. W związku z tym warto przekazaæ wskažnik
// do wyzwalacza w dodatkowym polu informacyjnym wiadomoķci. (Wskažnik
// będzie po prostu NULL, jeķli nie ma wyzwalacza)
void* pTrigger =
m_NavGraph.GetNode(m_pCurrentSearch->GetPathToTarget().back()).ExtraInfo();
Dispatcher->DispatchMsg(SEND_MSG_IMMEDIATELY,
SENDER_ID_IRRELEVANT,
m_pOwner->ID(),
Msg_PathReady,
pTrigger);
}
return result;
}
Przyjrzyjmy się teraz klasie, która zarządza wszystkimi ŋądaniami wyszukiwania.
Menedŋer ķcieŋek
Menedŋer ķcieŋek to szablon klasy o nazwie, co nie dziwi, PathManager. Kiedy bot wysyģa ŋądanie trasy za pomocą swojego narzędzia do planowania ķcieŋki, planista tworzy instancję odpowiedniego typu wyszukiwania (A * dla pozycji, Dijkstra dla typów) i rejestruje się w menedŋerze ķcieŋek. Menedŋer ķcieŋek prowadzi listę wszystkich aktywnych ŋądaņ wyszukiwania, które aktualizuje za kaŋdym razem. Oto jego definicja:
template < class path_planner >
class PathManager
{
private:
// kontener wszystkich aktywnych ŋądaņ wyszukiwania
std::list
// to caģkowita liczba cykli wyszukiwania przydzielonych menedŋerowi.
// Kaŋdy krok aktualizacji są równo podzielone między wszystkie zarejestrowane ķcieŋki
// wnioski
unsigned int m_iNumSearchCyclesPerUpdate;
public:
PathManager(unsigned int NumCyclesPerUpdate);
// za kaŋdym razem, gdy jest to wywoģywane, caģkowita liczba dostępnych cykli wyszukiwania
// byæ równo podzielone między wszystkie aktywne ŋądania ķcieŋki. Jeķli wyszukiwanie
// zakoņczy się pomyķlnie lub zakoņczy się niepowodzeniem, metoda powiadomi odpowiedniego bota
void UpdateSearches();
// planista ķcieŋki powinien wywoģaæ tę metodę, aby zarejestrowaæ wyszukiwanie w
//menedŋer. (Metoda sprawdza, czy planer ķcieŋki jest zarejestrowany tylko
// raz)
void Register(path_planner* pPathPlanner);
// agent moŋe uŋyæ tej metody do usunięcia ŋądania wyszukiwania.
void UnRegister(path_planner* pPathPlanner);
};
Menedŋer ķcieŋek ma przydzieloną liczbę cykli wyszukiwania, których moŋe uŋyæ do aktualizacji wszystkich aktywnych wyszukiwaņ na kaŋdym etapie aktualizacji. Po wywoģaniu UpdateSearches przydzielone cykle są równo dzielone między zarejestrowanymi planistami ķcieŋek, a metoda CycleOnce kaŋdego aktywnego wyszukiwania jest nazywana odpowiednią liczbę razy. Gdy wyszukiwanie zakoņczy się powodzeniem lub niepowodzeniem, menedŋer ķcieŋek usuwa ŋądanie wyszukiwania z listy. Oto lista metod twojego przeszukiwania.
template < class path_planner >
inline void PathManager
{
int NumCyclesRemaining = m_iNumSearchCyclesPerUpdate;
// iteruj po ŋądaniach wyszukiwania, dopóki wszystkie ŋądania nie zostaną wykonane
// speģnione lub w tym kroku aktualizacji nie ma ŋadnych cykli wyszukiwania.
std::list
while (NumCyclesRemaining-- && !m_SearchRequests.empty())
{
// wykonaj jeden cykl wyszukiwania dla tego ŋądania ķcieŋki
int result = (*curPath)->CycleOnce();
// jeķli wyszukiwanie zostaģo zakoņczone, usuņ z listy
if ( (result == target_found) || (result == target_not_found) )
{
// usuņ tę ķcieŋkę z listy ķcieŋek
curPath = m_SearchRequests.erase(curPath);
}
//przejdž do następnego
else
{
++curPath;
}
// iterator moŋe teraz wskazywaæ na koniec listy. Jeķli tak jest,
// naleŋy go zresetowaæ do początku.
if (curPath == m_SearchRequests.end())
{
curPath = m_SearchRequests.begin();
}
}//end while
}
UWAGA. Zamiast ograniczaæ menedŋera ķcieŋek do kilku cykli wyszukiwania, moŋesz preferowaæ przydzielenie okreķlonej iloķci czasu na uŋycie kaŋdej aktualizacji do przeszukiwania ķcieŋki. Moŋna to ģatwo osiągnąæ, dodając kod, aby wyjķæ z metody PathPlanner :: UpdateSearches po przekroczeniu przydzielonego czasu.
Tworzenie i rejestrowanie wyszukiwania
Jak widzieliķmy, kaŋdy bot Raven posiada instancję klasy Raven_Path- Planner. Aby umoŋliwiæ tworzenie ŋądaņ ķcieŋki podzielonej czasowo, klasa ta zostaģa zmodyfikowana tak, aby byģa wģaķcicielem wskažnika do instancji algorytmu wyszukiwania podzielonego czasowo (instancja klasy Graph_SearchDijkstra_TS, gdy bot ŋąda ķcieŋki do typu elementu i instancji klasy Graph_SearchAStar_TS, jeķli bot ŋąda ķcieŋki do pozycji docelowej). Te instancje są tworzone i rejestrowane w menedŋerze wyszukiwania w metodach Request-PathToTarget lub RequestPathToItem. Oto, w jaki sposób wysyģane jest zapytanie o wyszukiwanie przedmiotów:
bool Raven_PathPlanner:: RequestPathToItem(unsigned int ItemType)
{
//wyczyķæ listę punktów i usuņ wszelkie aktywne wyszukiwanie
GetReadyForNewSearch();
// znajdž najbliŋszy widoczny węzeģ od pozycji bota
int ClosestNodeToBot = GetClosestNodeToPosition(m_pOwner->Pos());
// usuņ węzeģ docelowy z listy i zwróæ false, jeķli nie jest widoczny
// znaleziono węzeģ. Nastąpi to, jeķli nawigator jest žle zaprojektowany lub jeķli bot
// udaģo się dostaæ * do * geometrii (otoczonej ķcianami)
// lub przeszkoda
if (ClosestNodeToBot == no_closest_node_found)
{
return false;
}
// utwórz instancję klasy wyszukiwania Dijkstra
typedef FindActiveTrigger< Trigger
typedef Graph_SearchDijkstra_TS< Raven_Map::NavGraph, term_con> DijSearch;
m_pCurrentSearch = new DijSearch(m_pWorld->GetNavigationGraph(),
ClosestNodeToBot,
ItemType);
// i zarejestruj wyszukiwanie w menedŋerze ķcieŋek
m_pWorld->GetPathManager()->Register(this);
return true;
}
Po zarejestrowaniu menedŋer ķcieŋki będzie wywoģywaģ metodę CycleOnce odpowiedniego algorytmu na kaŋdym etapie aktualizacji, aŋ wyszukiwanie zakoņczy się powodzeniem lub niepowodzeniem. Gdy agent zostanie powiadomiony o znalezieniu ķcieŋki, pobiera ją z narzędzia do planowania ķcieŋki, wywoģując metodę Raven_PathPlanner :: GetPath.
Zapobieganie kręceniu kciukami
Jedną z konsekwencji planowania ķcieŋki podzielonej na czas jest opóžnienie od momentu, gdy agent zaŋąda ķcieŋki, do momentu otrzymania powiadomienia o pomyķlnym lub nieudanym wyszukiwaniu. To opóžnienie jest proporcjonalne do wielkoķci wykresu nawigacyjnego, liczby cykli wyszukiwania na aktualizację przypisanych do menedŋera wyszukiwania oraz liczby aktywnych ŋądaņ wyszukiwania. Opóžnienie moŋe byæ bardzo maģe, zaledwie kilka kroków aktualizacji lub moŋe byæ duŋe, nawet o kilka sekund. W przypadku niektórych gier moŋe byæ w porządku, aby agent siedziaģ i kręciģ kciukami w tym okresie, ale dla wielu waŋne jest, aby agent zareagowaģ natychmiast w jakiķ sposób. W koņcu, gdy gracz gry kliknie NPC, a następnie kliknie lokalizację, do której ten NPC ma się przenieķæ, oczekuje, ŋe zareaguje on bezzwģocznie i gra nie będzie pod wraŋeniem, jeķli tak się nie stanie. Co zatem robi nasz biedny maģy agent gier w tej sytuacji? Musi zacząæ się poruszaæ, zanim zostanie sformuģowana ķcieŋka, ale dokąd? Prostą opcją, której uŋyģem dla Ravena, jest szukanie przez agenta celu, dopóki nie otrzyma powiadomienia od menedŋera wyszukiwania ŋe ķcieŋka jest gotowa, w tym czasie podąŋa ķcieŋką. Jeķli jednak bot poprosi o wyszukiwanie do typu elementu, lokalizacja celu jest nieznana do czasu zakoņczenia wyszukiwania (poniewaŋ moŋe istnieæ wiele takich przypadków). W tej sytuacji bot po prostu bģąka się, dopóki nie otrzyma powiadomienia. Dziaģa to dobrze w większoķci przypadków, ale stanowi kolejny problem: do czasu sformuģowania ķcieŋki agent mógģ przesunąæ się doķæ daleko od pozycji, w której początkowo ŋądano wyszukiwania. W związku z tym pierwsze kilka węzģów ķcieŋki zwróconych z planisty zostanie zlokalizowanych w taki sposób, ŋe agent będzie musiaģ cofnąæ się, aby je ķledziæ. Przykģadem tego jest rysunek poniŋszy. W A bot poprosiģ o ķcieŋkę od planisty ķcieŋki i podczas opóžnienia szuka w kierunku celu. Rysunek B pokazuje pozycję w momencie, gdy bot otrzymuje powiadomienie o sformuģowaniu ķcieŋki. Jak widaæ, pozostawiony wģasnym urządzeniom bot odwróci się i cofnie, aby podąŋaæ punktami trasy. Zģy bot! Niegrzeczny bot!
Na szczęķcie mamy juŋ rozwiązanie tego problemu. Gdy na ķcieŋce zastosowany zostanie algorytm wygģadzania, wszystkie nadmiarowe punkty trasy są automatycznie usuwane, co daje bardziej naturalnie wyglądającą ķcieŋkę pokazaną na rysunku. Dlatego planowanie ķcieŋki o okreķlonym czasie powinno byæ zawsze stosowane w poģączeniu z pewnego rodzaju wygģadzaniem ķcieŋki.
Moŋesz obserwowaæ te efekty z pierwszej ręki, uruchamiając demo Raven_TimeSlicing i obserwując boty poruszające się po ķrodowisku z wģączonym lub wyģączonym wygģadzaniem. (Liczba cykli wyszukiwania dostępnych dla menedŋera wyszukiwania na aktualizację jest bardzo maģa, aby podkreķliæ efekt.)
WSKAZÓWKA.Jeķli zauwaŋysz, ŋe twoi agenci często ķledzą się nawzajem w jednym pliku, aby dotrzeæ do lokalizacji lub elementu, i uŋywasz A* do generowania ķcieŋek, moŋesz zmieniaæ ķcieŋkę wygenerowaną przez algorytm wyszukiwania, dodając trochę szumu do heurystyczny. Spowoduje to nieco inne ķcieŋki dla tego samego wyszukiwania.
Hierarchiczne wyszukiwanie ķcieŋek
Inna dostępna technika zmniejszania obciąŋenia procesora grafem wyszukiwania nosi nazwę hierarchicznego wyszukiwania ķcieŋek. Dziaģa w podobny sposób, jak ludzie poruszają się po swoim otoczeniu. (Cóŋ, niezupeģnie, ale to stanowi dobry przykģad.) Zaģóŋmy na przykģad, ŋe budzisz się w ķrodku nocy i decydujesz się na szklankę mleka. Na jednym poziomie ķwiadomoķci prawdopodobnie będziesz podąŋaģ ķcieŋką przechodzącą przez szereg pokoi (np. Sypialnia do szczytu schodów na dóģ schodów do korytarza do jadalni do kuchni), ale na innym planujesz ķcieŋki między pokojami jako dotrzesz do nich. Na przykģad, gdy dotrzesz do jadalni, twój mózg automatycznie obliczy ķcieŋkę do kuchni, która moŋe wymagaæ obejķcia stoģu, unikania komody peģnej talerzy, otwierania drzwi i próbowania nie kopnięcia miski z wodą dla psa. Jako taki, twój umysģ planuje ķcieŋki na kilku róŋnych poziomach - przy róŋnych szczegóģowoķciach. Innym sposobem spojrzenia na to jest to, ŋe na jednym poziomie ķcieŋka jest planowana przy uŋyciu szeregu obszarów (jadalnia, kuchnia itp.), A na niŋszym poziomie jest planowana przy uŋyciu szeregu punktów przez te obszary. Tę koncepcję moŋna powtórzyæ w komputerze, projektując planer ķcieŋki, który wykorzystuje dwa naģoŋone na siebie wykresy o róŋnych ziarnistoķciach - jeden gruby, drugi drobny. Na przykģad wyobraž sobie grę strategiczną opartą na wojnie secesyjnej w Ameryce. Hierarchiczny planista ķcieŋki dla tej gry moŋe wykorzystywaæ gruboziarnisty wykres do reprezentowania informacji o ģącznoķci na poziomie stanu oraz drobno granulowany na poziomie miast i dróg. Gdy jednostka wojskowa prosi o trasę z Atlanty do Richmond, planista ķcieŋki okreķla, w których stanach leŋą te miasta - Georgia i Wirginia - i oblicza drogę między nimi za pomocą stanowego nawigatora: Georgia do Poģudniowej Karoliny, Karolina Póģnocna i Wirginia. Ķcieŋkę tę moŋna obliczyæ niezwykle szybko, poniewaŋ wykres zawiera tylko kilkadziesiąt węzģów, po jednym dla kaŋdego stanu reprezentowanego w grze. Następnie planista uŋywa drobnoziarnistego nawigatora do obliczania ķcieŋek między stanami, gdy i kiedy jednostka ich potrzebuje. W ten sposób wyszukiwanie drobnoziarnistego wykresu jest utrzymywane na niskim poziomie, a zatem szybkie.
UWAGA. Chociaŋ uŋycie dwóch warstw graficznych jest najbardziej typową implementacją hierarchicznego wyszukiwania ķcieŋek, nic nie stoi na przeszkodzie, abyķ uŋywaģ większej liczby warstw, jeķli ķrodowisko gry jest wystarczająco zģoŋone, aby to uzasadniæ.
Stosując ten sam pomysģ do mapy Raven_DM1, planista ķcieŋki mógģby uŋyæ wykresów pokazanych na rysunku . Wykres po lewej stronie moŋe sģuŋyæ do szybkiego okreķlania ķcieŋek na poziomie "pokoju", a wykres po prawej stronie do okreķlania ķcieŋek między pokojami na poziomie "punktu".
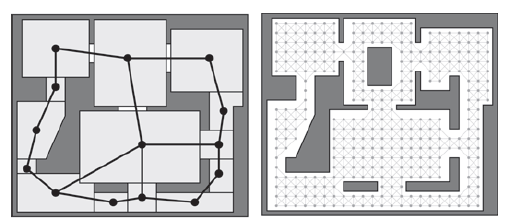
Oczywiķcie jest to trywialny przykģad; hierarchiczne wyszukiwanie ķcieŋek powinno się rozwaŋaæ tylko wtedy, gdy gra wymaga planowania ķcieŋek w duŋych i / lub zģoŋonych ķrodowiskach.
Wyjķcie z lepkich sytuacji
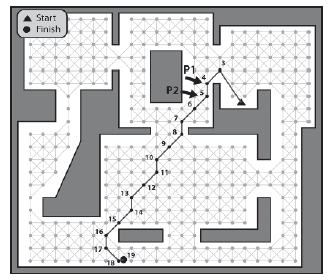
Problem, który gracze w grach komputerowych obserwują zbyt często, to utknięcie NPC. Moŋe się to zdarzyæ z róŋnych powodów. W szczególnoķci występuje często, gdy ķrodowisko zawiera wiele czynników, a geometria ma wąskie gardģa. Wąskim gardģem moŋe byæ maģa przestrzeņ między dwiema przeszkodami, wąskie drzwi lub wąski korytarz. Jeķli zbyt wielu agentów jednoczeķnie próbuje pokonaæ wąskie gardģo, to niektórzy z nich mogą zostaæ zepchnięci do tyģu i zaklinowaæ się na ķcianie lub przeszkodzie. Przyjrzyjmy się temu z prostym przykģadem. Rysunek pokazuje bota - nazwiemy go Eric - podąŋając ķcieŋką od A do B do C. Pokazuje takŋe liczbę innych botów podróŋujących w przeciwnym kierunku. Eric czeka na paskudną niespodziankę.
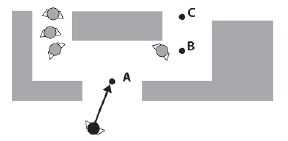
Na rysunku Eric osiągnąģ punkt A, więc zostaģ usunięty z listy i B przypisany jako następny punkt. Niestety, gdy tak się dzieje, przybywają inne boty i zaczynają przepychaæ Erica przez drzwi.
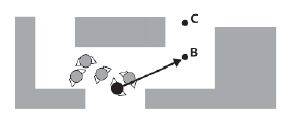
Na tym rysunku8 Eric zostaģ wypchnięty z powrotem przez drzwi, ale wciąŋ szuka drogi do punktu B. Gģupi stary Eric.
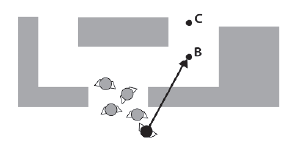
W koņcu Eric zostaje przyciķnięty do ķciany, wciąŋ walcząc wķciekle i beznadziejnie próbuje dotrzeæ do następnego punktu, jak pokazano na rysunku
TSK TSK.

Oczywiķcie nie chcemy, aby coķ takiego się wydarzyģo, więc kaŋda sztuczna inteligencja warta swojej soli powinna regularnie testowaæ takie sytuacje i odpowiednio planowaæ. Ale jak to zrobiæ? Jednym ze sposobów jest obliczenie przez agenta odlegģoķci do bieŋącego punktu na kaŋdym kroku aktualizacji. Jeķli ta wartoķæ pozostaje mniej więcej taka sama lub stale roķnie, oznacza to uczciwy zakģad, ŋe agent utknąģ lub zostaģ popchnięty do tyģu przez siģę oddzielającą od sąsiednich agentów. Innym sposobem jest obliczenie oczekiwanego czasu przybycia dla kaŋdego punktu trasy i ponowne zaplanowanie, jeķli aktualny czas przekroczy oczekiwany czas. Takie jest podejķcie przyjęte w Raven. Jest bardzo prosty do wdroŋenia. Za kaŋdym razem, gdy nowa krawędž jest wyciągana ze ķcieŋki, oczekiwany czas na przejķcie jest obliczany w następujący sposób (w pseudokodzie):
Edge next = GetNextEdgeFromPath (ķcieŋka)
// w prostym grafiku kosztem krawędzi jest dģugoķæ krawędzi
ExpectedTimeToReachPos = next.cost / Bot.MaxSpeed
// uwzględniæ margines bģędu
MarginOfError = 2.0;
ExpectedTimeToReachPos + = MarginOfError;
Margines bģędu sģuŋy do uwzględnienia wszelkich reaktywnych zachowaņ bota podczas podróŋy, takich jak skręcanie w bok w celu uniknięcia kolejnego bota lub przepychanie się w drzwiach i wąskich przejķciach. Margines ten powinien byæ wystarczająco maģy, aby uniemoŋliwiæ agentom wyglądanie na gģupie, a jednoczeķnie wystarczająco duŋy, aby uniemoŋliwiæ agentom częste ŋądanie nowych ķcieŋek od narzędzia do planowania ķcieŋek.
UWAGA Moŋesz zaobserwowaæ, ŋe boty blokują się, jeķli uruchomisz demo Raven_BotsGetting- Stuck. W wersji demo kilka botów bada mapę. Z ich aktualnej pozycji rysowana jest strzaģka do ich bieŋącego miejsca docelowego. Kiedy przepychają się przez drzwi, niektóre z nich utkną, a niektóre na staģe.
Podsumowanie
Przedstawiono wiele metod i technik związanych z planowaniem ķcieŋki. Większoķæ pomysģów zostaģa wģączona do frameworka gry Raven, dzięki czemu moŋesz zobaczyæ, jak dziaģają na miejscu i zbadaæ kod, aby zobaczyæ, jak wszystko dziaģa razem. Pamiętaj, ŋe jest to tylko przykģad. Zwykle nie uŋywaģbyķ wszystkich tych technik jednoczeķnie. Po prostu uŋywaj tego, czego wymaga Twoja gra, i nic więcej.
Praktyka czyni mistrza
Po przejķciu do pozycji docelowej boty Raven wypeģniają lukę utworzoną przez czas potrzebny na przeszukiwanie wykresu, szukając tej pozycji. Jest to tanie i ģatwe do wdroŋenia, ale w grach z setkami agentów lub duŋymi nawigatorami opóžnienie moŋe byæ zbyt dģugie, aby takie podejķcie byģo skuteczne. Biorąc pod uwagę zbyt dģugie opóžnienie, agenci zaczną gģupio chodziæ po ķcianach i innych przeszkodach. Są teŋ chwile, w których najlepsza ķcieŋka do pozycji polega na oddaleniu się od celu lub odchyleniu go od niego przed pochyleniem się, aby stawiæ mu czoģa.
Szukanie w takich sytuacjach przez dģuŋszy czas jest zdecydowanie nie-nie. Zamiast tego agenci muszą okreķliæ częķciową ķcieŋkę do pozycji docelowej. Oznacza to, ŋe algorytm A* musi zostaæ zmodyfikowany, aby zwracaģ ķcieŋkę do węzģa najbliŋszego celowi po osiągnięciu zdefiniowanej przez uŋytkownika liczby cykli wyszukiwania lub gģębokoķci wyszukiwania. Agent moŋe następnie podąŋaæ tą ķcieŋką, dopóki nie zostanie utworzona peģna ķcieŋka. Spowoduje to znacznie lepsze zachowanie i zmniejszy szanse, ŋe agent będzie wyglądaģ gģupio. Twoim zadaniem, jeķli zdecydujesz się to zaakceptowaæ, jest zmodyfikowanie projektu PathPlanner w celu utworzenia częķciowych ķcieŋek między węzģami žródģowym i docelowym.