Skrypt, czy Nie-Skrypt
Ta częķæ koncentruje się na zadziwiająco uŋytecznej matematycznej abstrakcji zwanej grafem. Będziesz często uŋywaæ wykresów w sztucznej inteligencji gry. W rzeczywistoķci juŋ je widziaģeķ: diagramy bąbelkowe przejķcia stanu z częķci są rodzajem wykresu. Grafiki i ich mģodsi bracia, drzewa, są stale uŋywane przez programistów AI. Moŋna ich uŋywaæ do wielu róŋnych rzeczy - od umoŋliwienia agentom gry efektywnego podróŋowania między dwoma punktami, do decydowania, co zbudowaæ w grze strategicznej i rozwiązywania zagadek. Pierwsza częķæ zostanie poķwięcona wprowadzeniu cię do róŋnych rodzajów wykresów i związanej z nimi terminologii. Dowiesz się, czym są wykresy, jak moŋna ich uŋywaæ i jak je efektywnie kodowaæ. W pozostaģej częķci rozdziaģu opisano szczegóģowo wiele algorytmów wyszukiwania dostępnych w celu wykorzystania peģnej mocy grafów.
Wykresy
Podczas opracowywania sztucznej inteligencji do gier jednym z najczęstszych zastosowaņ grafów jest reprezentowanie sieci ķcieŋek, którymi agent moŋe się poruszaæ po swoim ķrodowisku. Kiedy się tego nauczyģem, byģem zdezorientowany, poniewaŋ przez caģe ŋycie znaģem wykres, który wygląda jak wykresy, których nauczyģem się rysowaæ w szkole
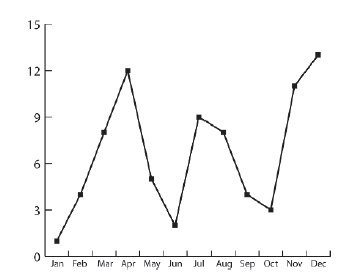
Zawsze uwaŋaģem, ŋe wykresy są przydatne do wizualizacji wzlotów i upadków niektórych wģąķciwoķci, takich jak wykresy temperatur pokazane w telewizyjnych prognozach pogody lub danych o sprzedaŋy, i tym podobne, więc zastanawiaģem się, jak taki wykres mógģby ewentualnie moŋe byæ uŋywany do reprezentowania ķcieŋek tnących wokóģ ķcian i przeszkód w ķrodowisku gry. Jeķli nigdy nie studiowaģeķ teorii grafów, to prawdopodobnie tak myķlisz o grafach. Myķlę, ŋe tak wģaķnie jeste
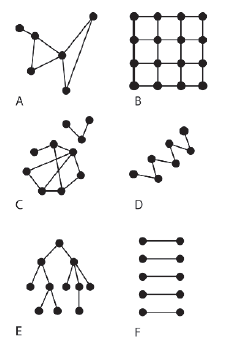
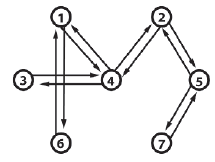
To ten sam wykres, ale zmieniģem etykietowanie osi, aby reprezentowaæ wspóģrzędne x i y przestrzeni kartezjaņskiej, dodając kilka kosmetycznych ozdób, dzięki czemu teraz reprezentuje ķcieŋkę wijącą się w pobliŋu rzeki. W rzeczywistoķci wygląda na coķ, co przeciętny czģowiek na ulicy nazwaģby mapą. Rzeczywiķcie, caģy obraz jest mapą, ale szereg punktów poķrednich i ģącząca je ķcieŋka są reprezentowane przez bardzo prosty wykres. Teraz zdaję sobie sprawę, ŋe niektórzy z was będą myķleæ, ŋe to nie jest wielka sprawa, ale wierzę, ŋe dla wielu ta subtelna zmiana perspektywy moŋe byæ objawieniem. To z pewnoķcią byģo dla mnie. W terminologii graficznej punkty drogi nazywane są węzģami (lub czasami wektorami), a ķcieŋki ģączące je nazywane są krawędziami (lub czasami ģukami). Rysunek poniŋszy pokazuje kilka innych przykģadów wykresów. Jak widaæ, mogą one przyjmowaæ szeroki zakres konfiguracji.
W szerszym kontekķcie wykres jest symboliczną reprezentacją sieci i chociaŋ węzģy i krawędzie mogą reprezentowaæ relację przestrzenną, taką jak w omawianym wczeķniej przykģadzie, nie musi tak byæ. Wykresy mogą sģuŋyæ do reprezentowania wszelkiego rodzaju sieci, od sieci telefonicznych i sieci WWW po obwody elektroniczne i sztuczne sieci neuronowe.
UWAG.A Wykresy mogą byæ podģączone lub niepoģączone. Wykres uwaŋa się za poģączony, gdy moŋliwe jest przeķledzenie ķcieŋki między poszczególnymi węzģami. Wykresy A, B, D i E na powyŋszym rysunku są przykģadami poģączonych wykresów. Wykresy C i F są przykģadami niepowiązanych wykresów.
Bardziej formalny opis
Wykres G moŋna formalnie zdefiniowaæ jako zbiór węzģów lub wierzchoģków, N, ģączący się z zestawem krawędzi, E. Często moŋna to znaležæ jako:
G = {N, E} (5.1)
Jeķli kaŋdy węzeģ na wykresie jest oznaczony liczbą caģkowitą z zakresu od 0 do (N-1), krawędž moŋe byæ teraz okreķlana przez węzģy, które ģączy, na przykģad 3-5 lub 19-7. wszelkie wykresy mają wywaŋone krawędzie - zawierają informacje o koszcie przejķcia z jednego węzģa do drugiego. Na przykģad na wykresie pokazanym wczeķniej na rysunku koszt przejķcia krawędzi to odlegģoķæ między dwoma poģączonymi węzģami. Na wykresie przedstawiającym drzewo technologiczne gry RTS przypominającej Warcraft krawędzie mogą wskazywaæ zasoby potrzebne do ulepszenia kaŋdej jednostki.
UWAGA. Chociaŋ wykres moŋe mieæ wiele poģączeņ z tym samym węzģem lub nawet poģączenia zapętlone ģączące węzeģ z samym sobą, funkcje te rzadko są niezbędne do sztucznej inteligencji w grze i nie będą omawiane na następnych stronach.
Drzewa
Większoķæ programistów zna strukturę danych drzewa. Drzewa są szeroko stosowane we wszystkich dyscyplinach programowania. Jednak moŋesz nie zdawaæ sobie sprawy, ŋe drzewa są podzbiorem wykresów obejmujących wszystkie wykresy acykliczne (nie zawierające ķcieŋek cyklicznych). Wykres E na rysunku powyŋej jest drzewem i prawdopodobnie jest to ksztaģt, który znasz, ale wykres D jest równieŋ drzewem. Wykres F to las drzew.
Gęstoķæ wykresu
Stosunek krawędzi do węzģów wskazuje, czy wykres jest rzadki czy gęsty. Rzadkie wykresy mają kilka poģączeņ na węzeģ, a wykresy gęste wiele.
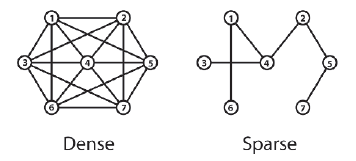
pokazuje przykģad obu typów. Aby zmniejszyæ zģoŋonoķæ i ograniczyæ zuŋycie procesora i pamięci do minimum, powinieneķ preferowaæ rzadkie wykresy, gdy tylko jest to moŋliwe, na przykģad podczas projektowania wykresu do wykorzystania w planowaniu ķcieŋki. Wiedza, czy wykres jest gęsty, czy rzadki, jest pomocna przy wyborze odpowiedniej struktury danych do kodowania struktury wykresu, poniewaŋ implementacja, która jest wydajna dla gęstego wykresu, prawdopodobnie nie będzie wydajna dla tego, który jest rzadki
Dwugraf
Do tej pory zakģadaliķmy, ŋe jeķli moŋliwe jest przejazd z węzģa A do węzģa B, moŋliwe jest równieŋ wykonanie czynnoķci odwrotnej. Nie zawsze tak moŋe byæ. Czasami moŋe byæ konieczne zaimplementowanie wykresu, w którym poģączenia są kierunkowe. Na przykģad, twoja gra moŋe mieæ "poķlizg ķmierci" umieszczony nad rzeką. Agent powinien byæ w stanie przejķæ tylko w jedną stronę - od góry do doģu - dlatego musimy znaležæ sposób na reprezentację tego rodzaju poģączenia. Alternatywnie moŋe byæ moŋliwe podróŋowanie między dwoma węzģami w dowolnym kierunku, ale koszt kaŋdego przejķcia moŋe byæ inny. Dobrym przykģadem jest to, jeķli chcesz, aby Twoi agenci brali pod uwagę pochyģoķci terenu. W koņcu pojazd ģatwo i sprawnie i szybko zjeŋdŋa w dóģ, ale zuŋywa o wiele więcej paliwa, aby pojazd poruszaģ się pod górę, a jego maksymalna prędkoķæ będzie znacznie mniejsza. Moŋemy odzwierciedliæ te informacje za pomocą wykresu zwanego digraph lub w skrócie DAG. Digraf ma krawędzie skierowane lub w jedną stronę. Węzģy, które definiują skierowaną krawędž są znane jako para uporządkowana i okreķla kierunek krawędzi. Na przykģad, uporządkowana para 16-6 wskazuje, ŋe moŋliwe jest przejķcie z węzģa 16 do węzģa 6, ale nie z węzģa 6 do 16. W tym przykģadzie węzeģ 16 jest znany jako węzeģ žródģowy, a węzeģ docelowy 6.
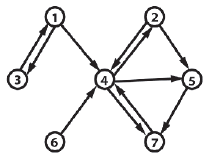
Krawędzie są rysowane za pomocą strzaģek wskazujących ich kierunek. Podczas projektowania struktury danych dla wykresów często pomocne jest myķlenie o grafach bezkierunkowych jako o wykrojach z dwiema krawędziami ģączącymi kaŋdą poģączoną parę węzģów. Jest to wygodne, poniewaŋ oba typy wykresów (skierowane i nieukierowane) mogą byæ następnie reprezentowane przez tę samą strukturę danych. Na przykģad rzadki, nieukierowany wykres pokazany na rycinie 5.4 moŋe byæ reprezentowany przez wykrój pokazany poniŋej
Wykresy nawigacyjne
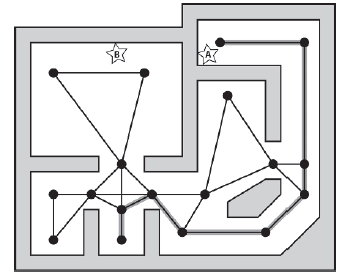
Chciaģbym wyjaķniæ, ŋe agent gry nie ogranicza się do poruszania się wzdģuŋ krawędzi wykresu, jakby to byģ pociąg jadący po szynach. Agent moŋe przejķæ do dowolnej niezakģóconej pozycji w ķrodowisku gry, ale uŋywa wykresu nawigacyjnego do negocjowania swojego ķrodowiska - do planowania ķcieŋek między dwoma lub więcej punktami i przechodzenia przez nie. Na przykģad, jeķli agent umieszczony w punkcie A uzna, ŋe konieczne jest przejķcie do poģoŋenia B, moŋe uŋyæ nawigatora, aby obliczyæ najlepszą trasę między węzģami znajdującymi się najbliŋej tych punktów. Rysunek powyŋszy jest typowy dla wykresu nawigacyjnego utworzonego dla strzelanki FPS. Inne typy gier mogą uznaæ inny ukģad węzģów za bardziej skuteczny. Na przykģad gry typu RTS / RPG często oparte są na siatce kafelków lub komórek, przy czym kaŋda pģytka reprezentuje inny rodzaj terenu, np. Trawę, drogę, bģoto itp. Dlatego wygodnie jest utworzyæ wykres za pomocą ķrodka punkty kaŋdej pģytki i przypisywanie kosztów krawędzi na podstawie odlegģoķci między komórkami waŋonymi dla typu terenu, po którym przesuwa się krawędž. Takie podejķcie pozwala agentom gry ģatwo obliczyæ ķcieŋki, które omijają wodę, wolą podróŋowaæ po drogach od bģota i wędrowaæ po górach. Rysunek pokazuje rodzaj ukģadu komórek, którego moŋna się spodziewaæ w RTS / RPG.
Poniewaŋ niektóre gry RTS / RPG mogą wykorzystywaæ dosģownie setki tysięcy komórek, wadą tego podejķcia jest to, ŋe wykresy mogą byæ bardzo duŋe, kosztowne do przeszukania i zajmują duŋe iloķci pamięci. Na szczęķcie dla twórców AI, niektórych z tych problemów moŋna uniknąæ, stosując techniki, których nauczysz się w dalszej częķci
WSKAZÓWKA. Jeķli tworzysz "ukryte", takie jak gry Thief and Thief 2 firmy Looking Glass Studios / Eidos Interactive, moŋesz uŋyæ nawigatora, którego krawędzie są wywaŋone przez to, ile džwięku postaæ przemieķci wzdģuŋ krawędzi. Krawędzie, które moŋna pokonywaæ cicho, takie jak te wzdģuŋ dywanu, miaģyby niskie cięŋary wartoķci, a gģoķne krawędzie wysokie wartoķci. Projektowanie wykresów w ten sposób pozwala postaciom w grze znaležæ najcichszą ķcieŋkę między dwoma pokojami.
Wykresy zaleŋnoķci
Wykresy zaleŋnoķci są uŋywane w grach typu zarządzanie zasobami w celu opisania zaleŋnoķci między róŋnymi budynkami, materiaģami, jednostkami i technologiami dostępnymi dla gracza. Rysunek pokazuje częķæ wykresu zaleŋnoķci utworzonego dla takiej gry. Ten rodzaj wykresu uģatwia sprawdzenie, jakie są wymagania wstępne do utworzenia kaŋdego rodzaju zasobu.
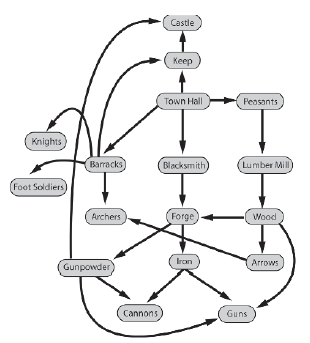
Wykresy zaleŋnoķci są nieocenione przy projektowaniu sztucznej inteligencji dla tego rodzaju gatunku, poniewaŋ AI moŋe ich uŋywaæ do decydowania o strategiach, przewidywania przyszģego statusu przeciwnika i skutecznego przydzielania zasobów. Oto kilka przykģadów opartych na wykresie pokazanym na rysunku.
1. Jeķli AI przygotowuje się do bitwy i stwierdzi, ŋe ģucznicy będą korzystni, moŋe zbadaæ wykres zaleŋnoķci, aby stwierdziæ, ŋe zanim będzie w stanie wyprodukowaæ ģuczników, musi najpierw upewniæ się, ŋe ma koszary i technologię strzaģ. Wie równieŋ, ŋe aby produkowaæ strzaģy, musi mieæ tartak produkujący drewno. Dlatego jeķli AI ma juŋ tartak, moŋe przeznaczyæ zasoby na budowę koszar lub odwrotnie. Jeķli sztuczna inteligencja nie ma koszar ani tartaku, moŋe dodatkowo sprawdziæ wykres technologii, aby ustaliæ, ŋe prawdopodobnie korzystne jest zbudowanie koszar przed tartakiem. Dlaczego? Poniewaŋ koszary są warunkiem wstępnym dla trzech róŋnych rodzajów jednostek bojowych, podczas gdy tartak jest warunkiem koniecznym do produkcji drewna. Sztuczna inteligencja stwierdziģa juŋ, ŋe bitwa jest nieuchronna, więc powinna zdaæ sobie sprawę (oczywiķcie jeķli poprawnie ją zaprojektowaģeķ), ŋe powinna jak najszybciej wkģadaæ zasoby w tworzenie jednostek bojowych, poniewaŋ, jak wszyscy wiemy, rycerze i piechota ŋoģnierze robią lepszych wojowników niŋ drewniane deski!
2. Jeķli wrogi pieszy ŋoģnierz niosący broņ dotrze na terytorium AI, AI moŋe przejechaæ przez wykres do tyģu, aby stwierdziæ, ŋe:
• Wróg musiaģ juŋ zbudowaæ kužnię i tartak.
• Wróg musiaģ opracowaæ technologię prochu.
• Wróg musi produkowaæ zasoby drewna i ŋelaza.
Dalsze badanie wykresu wskazaģoby, ŋe wróg prawdopodobnie ma armaty lub je obecnie buduje. Paskudny! AI moŋe wykorzystaæ te informacje do wyboru najlepszego planu ataku. Na przykģad sztuczna inteligencja wiedziaģaby, ŋe aby nie dopuķciæ do dotarcia na jej terytorium kolejnych wrogów z bronią, powinna celowaæ w kužnię i tartak wroga. Moŋe równieŋ wywnioskowaæ, ŋe wysģanie zabójcy w celu uderzenia wroga kowala znacznie osģabiģoby jego wroga i byæ moŋe poķwięciģby ķrodki na stworzenie zabójcy na ten cel.
3. Często technologia lub okreķlona jednostka jest kluczem do zwycięstwa druŋyny. Jeķli koszty budowy kaŋdego zasobu są przypisane do krawędzi wykresu zaleŋnoķci, wtedy AI moŋe wykorzystaæ te informacje do obliczenia najbardziej wydajnej trasy do wytworzenia tego zasobu
Wykresy stanu
Wykres stanu reprezentuje kaŋdy moŋliwy stan, w którym moŋe znajdowaæ się system, oraz przejķcia między tymi stanami. Ta kolekcja potencjalnych stanów systemu jest znana jako przestrzeņ stanów. Wykres tego typu moŋna przeszukaæ, aby sprawdziæ, czy dany stan jest moŋliwy, lub znaležæ najbardziej efektywną trasę do okreķlonego stanu. Spójrzmy na prosty przykģad z ukģadanką "Towers of Hanoi"
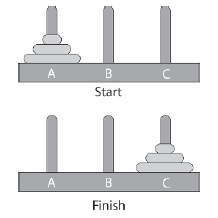
W tej prostej wersji ukģadanki znajdują się trzy koģki - A, B i C - i trzy pierķcienie o róŋnych rozmiarach, które pasują na koģki. Pierķcienie zaczynają się ustawiaæ w porządku wielkoķci nad koģkiem A. Celem ukģadanki jest przesuwanie pierķcieni, aŋ wszystkie zostaną ustawione na koģku C, równieŋ w kolejnoķci wielkoķci. Jednoczeķnie moŋna przenosiæ tylko jeden pierķcieņ. Pierķcieņ moŋna umieķciæ na pustym koģku lub na pierķcieniu większym od niego. Moŋemy przedstawiæ przestrzeņ stanu tej ukģadanki za pomocą wykresu, na którym kaŋdy węzeģ reprezentuje jeden z moŋliwych stanów, w których moŋe znajdowaæ się ukģadanka. Krawędzie wykresu przedstawiają przejķcia między stanami: Jeķli moŋliwe jest przejķcie bezpoķrednio z jednego stanu do drugiego, będzie krawędž ģącząca oba stany; w przeciwnym razie nie będzie poģączenia. Wykres jest tworzony przez utworzenie najpierw węzģa, który zawiera stan początkowy ukģadanki. Jest to znane jako węzeģ gģówny. Węzeģ gģówny jest następnie rozwijany przez dodanie do wykresu wszystkich stanów moŋliwych do uzyskania z tego węzģa, a następnie kaŋdy z tych stanów jest rozszerzany i tak dalej, aŋ wszystkie moŋliwe stany i przejķcia zostaną dodane do wykresu. Poprzedni stan kaŋdego stanu nazywany jest stanem nadrzędnym, a nowy stan nazywany jest dzieckiem stanu nadrzędnego. Rysunek pokazuje ten proces. Strzaģka ģącząca dwa stany oznacza, ŋe jeden stan moŋna osiągnąæ z drugiego, przesuwając jeden z dysków. Wykres szybko się komplikuje, więc pominąģem wiele moŋliwych stanów, aby uģatwiæ dostrzeŋenie jednej ze ķcieŋek prowadzących do rozwiązania.
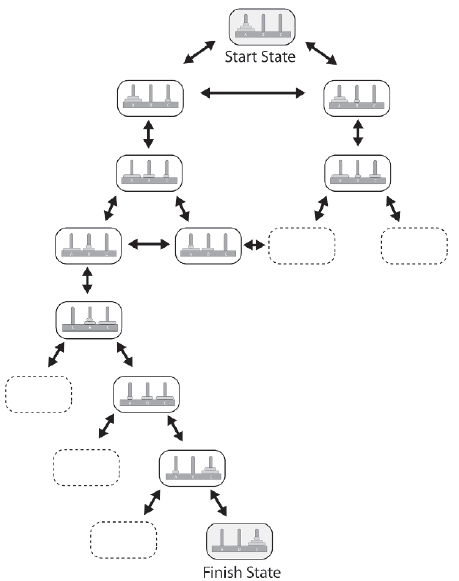
Wykres stanu moŋna ģatwo przeszukaæ, aby znaležæ stan celu. W tym przykģadzie stanem bramki jest taki, w którym wszystkie elementy są umieszczone na koģku C we wģaķciwej kolejnoķci. Przeszukując przestrzeņ stanów moŋna nie tylko znaležæ jedno rozwiązanie, ale takŋe znaležæ kaŋde moŋliwe rozwiązanie lub rozwiązanie wymagające najmniejszej liczby ruchów (lub największej liczby ruchów, jeķli tego wģaķnie szukasz). Ķrednia liczba węzģów podrzędnych promieniujących z kaŋdego węzģa nadrzędnego jest znana jako czynnik rozgaģęziający wykresu. W przypadku niektórych problemów, takich jak omawiany tutaj przykģad ģamigģówki, wspóģczynnik rozgaģęzienia jest niski - rzędu od jednej do trzech gaģęzi na węzeģ - co umoŋliwia przedstawienie za pomocą wykresu caģej przestrzeni stanu w pamięci komputera. Jednak w wielu domenach wspóģczynnik rozgaģęzienia jest znacznie wyŋszy, a liczba potencjalnych stanów ogromnie roķnie wraz ze wzrostem odlegģoķci od węzģa gģównego (gģębokoķæ wykresu). W tego typu systemach niemoŋliwe jest przedstawienie caģej przestrzeni stanów, poniewaŋ szybko przekroczy moŋliwoķci pamięci nawet najbardziej wydajnego komputera. Nawet jeķli taki wykres mógģby zostaæ zapisany, wyszukiwanie zajmie jeszcze eony. W rezultacie tego rodzaju wykresy są tworzone i przeszukiwane poprzez rozwinięcie kilku węzģów naraz, zwykle (ale nie zawsze) przy uŋyciu algorytmów, które kierują wyszukiwanie w kierunku celu.
Implementowanie klasy grafu
Dwie popularne struktury danych uŋywane do reprezentowania wykresów to macierze przylegģoķci i listy przylegģoķci. Wykresy macierzy adiakencji wykorzystują dwuwymiarową macierz booleanów lub liczb zmiennoprzecinkowych do przechowywania informacji o poģączeniu wykresu. Wartoķci logiczne są uŋywane, jeķli nie ma kosztu związanego z przemierzaniem krawędzi, a zmiennoprzecinkowe są uŋywane, gdy istnieje powiązany koszt, na przykģad w przypadku wykresu nawigacyjnego, w którym kaŋda krawędž reprezentuje odlegģoķæ między dwoma węzģami. Dokģadne wdroŋenie zaleŋy oczywiķcie od projektanta i jego potrzeb problem. Rycina. pokazuje, jak wygląda macierz przylegania dla wykreķlnika na rycinie wczeķniej
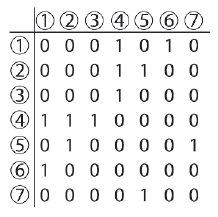
Kaŋde "1" oznacza poģączenie między dwoma węzģami, a kaŋde "0" oznacza brak poģączenia. Po odczytaniu wartoķci bezpoķrednio z macierzy z rysunku 5.12 wiemy, ŋe nie ma poģączenia od węzģa 2 do 6, ale istnieje krawędž ģącząca 4 do 2. Macierze adiacyencji są intuicyjne, ale dla duŋych rzadkich grafów ten typ reprezentacji jest nieefektywna, poniewaŋ większoķæ matrycy jest uŋywana do przechowywania niepotrzebnych wartoķci zerowych. Znacznie lepsza struktura danych dla rzadkich wykresów (najczęķciej występujących wykresów w grze AI) to lista sąsiedztwa. Dla kaŋdego obecnego węzģa wykres listy przylegģoķci przechowuje poģączoną listę wszystkich sąsiednich krawędzi. Rysunek pokazuje, jak to dziaģa w poprzednim przykģadzie.
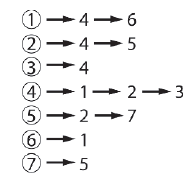
Listy adiakencji są skuteczne do przechowywania rzadkich wykresów, poniewaŋ nie marnują miejsca na przechowywanie zerowych poģączeņ. Iloķæ miejsca wymagana do przechowywania wykresu przy uŋyciu tego typu struktury danych jest proporcjonalna do N + E (liczba węzģów + liczba krawędzi), podczas gdy dla macierzy sąsiedniej jest proporcjonalna do N2 (liczba węzģów do kwadratu). Poniewaŋ większoķæ wykresów, które moŋna napotkaæ podczas tworzenia gier AI, jest niewielka, lista zgodnoķci będzie często twoją wybraną strukturą danych. Mając to na uwadze, spójrzmy na kod žródģowy wymagany do zaimplementowania takiego wykresu.
Klasa GraphNode
GraphNode zawiera minimalną iloķæ informacji wymaganych przez węzeģ do reprezentacji wykresu listy przylegģoķci: unikalny numer identyfikacyjny lub indeks. Oto lista deklaracji węzģa wykresu:
class GraphNode
{
protected:
// kaŋdy węzeģ ma indeks. Prawidģowy indeks to> = 0
int m_iIndex;
public:
GraphNode (): m_iIndex (invalid_node_index) {}
GraphNode (int idx): m_iIndex (idx) {}
virtual ~ GraphNode () {}
int Index () const;
void SetIndex (int NewIndex);
};
Poniewaŋ często konieczne jest, aby węzeģ zawieraģ dodatkowe informacje, GraphNode jest zwykle uŋywany jako klasa bazowa, z której moŋna uzyskaæ niestandardowe węzģy. Na przykģad węzģy wykresu nawigacyjnego muszą przechowywaæ informacje przestrzenne, a węzģy wykresu zaleŋnoķci muszą zawieraæ informacje o reprezentowanych przez nich zasobach. Klasa węzģa zaprojektowana do uŋycia w grafie nawigacyjnym moŋe wyglądaæ mniej więcej tak:
template
klasa NavGraphNode: public GraphNode
{
protected:
// pozycja węzģa
Vector2D m_vPosition;
// często będziesz potrzebowaæ węzģa navgraph, aby zawieraģ dodatkowe informacje.
// Na przykģad węzeģ moŋe reprezentowaæ odbiór, taki jak zbroja, w której
// case m_ExtraInfo moŋe byæ wyliczoną wartoķcią oznaczającą typ odbioru,
// umoŋliwiając w ten sposób algorytmowi wyszukiwania przeszukanie wykresu dla okreķlonych elementów.
// Idąc o krok dalej, m_ExtraInfo moŋe byæ wskažnikiem do wystąpienia
// typ elementu, z którym węzeģ jest powiązany. Pozwoliģoby to na algorytm wyszukiwania
// aby sprawdziæ status odbioru podczas wyszukiwania.
extra_info m_ExtraInfo;
public:
/ * POMINIĘTY INTERFEJS * /
};
Pamiętaj, ŋe chociaŋ wymieniona tutaj klasa węzģów uŋywa wektora 2D do przedstawienia pozycji węzģa, wykres moŋe istnieæ w dowolnej liczbie wymiarów, które ci się podobają. Jeķli tworzysz wykres nawigacyjny dla gry 3D, po prostu uŋyj wektorów 3D. Wszystko będzie dziaģaæ tak samo.
Klasa GraphEdge
Klasa GraphEdge zawiera podstawowe informacje wymagane do oznaczenia poģączenia między dwoma węzģami grafowymi. Oto kod:
class GraphEdge
{
protected:
// Krawędž ģączy dwa węzģy. Prawidģowe wskažniki węzģów są zawsze dodatnie.
int m_iFrom;
int m_iTo;
// koszt przejķcia krawędzi
double m_dCost;
public:
GraphEdge (int from, int to, double cost): m_dCost (cost),
m_iFrom (od),
m_iTo (do)
{}
GraphEdge (int from, int to): m_dCost (1.0),
m_iFrom (od),
m_iTo (do)
{}
GraphEdge (): m_dCost (1.0),
m_iFrom (invalid_node_index),
m_iTo (invaid_node_index)
{}
Czasami przydaje się moŋliwoķæ utworzenia GraphEdge z jednym lub obydwoma wskažnikami ustawionymi na "nieprawidģową" (ujemną) wartoķæ. Wyliczona wartoķæ invaid_node_index w pliku NodeTypeEnumerations.h jest tutaj uŋywana , aby zainicjowaæ From i To w domyķlnym konstruktorze.
virtual ~ GraphEdge () {}
int From () const;
void SetFrom (int NewIndex);
int To () const;
void SetTo (int NewIndex);
double Cost () const;
void SetCost (double NewCost);
};
Jeķli pracujesz na platformie, na której wykorzystanie pamięci jest znacznie większym problemem niŋ szybkoķæ wyszukiwania wykresu, moŋesz uzyskaæ dobre oszczędnoķci na wykresach opartych na komórkach (lub wykresach o równej lub większej gęstoķci), nie zapisując jawnie kosztu kaŋdego krawędž. Zamiast tego moŋna zaoszczędziæ pamięæ, pomijając pole kosztu z klasy GraphEdge i obliczyæ koszt "w locie" za pomocą funkcji atrybutów jego dwóch sąsiednich węzģów. Na przykģad, jeķli koszt krawędzi jest równy odlegģoķci między dwoma węzģami, funkcją będzie odlegģoķæ euklidesowa. Coķ jak:
//cost from A to B
cost = Distance(NodeA.Position, NodeB.Position)
Poniewaŋ na tym wykresie jest zwykle osiem razy więcej krawędzi niŋ wierzchoģków, oszczędnoķæ pamięci moŋe byæ znaczna, gdy zaangaŋowana jest duŋa liczba węzģów
Klasa SparseGraph
Węzģy i krawędzie wykresu są zgrupowane razem w klasie SparseGraph. Jest to zaimplementowane jako szablon klasy, dzięki czemu ten typ wykresu moŋe wykorzystywaæ dowolne odpowiednie typy węzģów i krawędzi. Algorytmy dziaģające na wykresach powinny mieæ szybki dostęp do węzģa i danych brzegowych. Mając to na uwadze, klasa SparseGraph zostaģa zaprojektowana w taki sposób, aby klucze numeryczne indeksu kaŋdego węzģa bezpoķrednio w wektorze węzģów grafowych (m_Nodes) i wektorze list krawędzi przylegģoķci (m_Edges), co daje czas wyszukiwania O (1). Stwarza to jednak problem, gdy węzeģ jest usuwany z wykresu, poniewaŋ gdyby miaģ zostaæ równieŋ usunięty z m_Nodes, caģe indeksowanie dla węzģów o wyŋszym indeksowaniu byģoby uniewaŋnione. Dlatego zamiast usuwaæ węzeģ z wektora, jego indeks jest ustawiony na wyliczoną wartoķæ invalid_node_index i wszystkie metody SparseGraph traktują tę wartoķæ tak, jakby nie byģo węzģa. Oto lista deklaracji SparseGraph.
template
class SparseGraph
{
public:
// moŋliwia ģatwy dostęp klienta do typów krawędzi i węzģów uŋywanych na wykresie
typedef edge_type EdgeType;
typedef node_type NodeType;
// kilka innych przydatnych typedefs
typedef std::vector
typedef std::list
typedef std::vector
private:
// węzģy, które skģadają się na ten wykres
NodeVector m_Nodes;
// wektor list krawędzi przylegģoķci. (kaŋdy klucz indeksu węzģa do
// listy krawędzi powiązanych z tym węzģem)
EdgeListVector m_Edges;
// czy to jest ukierunkowany wykres?
bool m_bDigraph;
// indeks następnego węzģa, który ma zostaæ dodany
int m_iNextNodeIndex;
/ * DODATKOWE SZCZEGÓĢY POMINOWANE * /
public:
//ctor
SparseGraph(bool digraph): m_iNextNodeIndex(0), m_bDigraph(digraph){}
// zwraca węzeģ o podanym indeksie
const NodeType& GetNode(int idx)const;
// wersja non-const
NodeType& GetNode(int idx);
// metoda const uzyskiwania odniesienia do krawędzi
const EdgeType& GetEdge(int from, int to)const;
// wersja non const
EdgeType& GetEdge(int from, int to);
// pobiera następny wolny indeks węzģa
int GetNextFreeNodeIndex()const;
// dodaje węzeģ do wykresu i zwraca jego indeks
int AddNode(NodeType node);
// usuwa węzeģ, ustawiając jego indeks na invalid_node_index
void RemoveNode(int node);
// metody dodawania i usuwania krawędzi
void AddEdge(EdgeType edge);
void RemoveEdge(int from, int to);
Zwróæ uwagę, w jaki sposób klasa ma metody usuwania węzģów i krawędzi. Jest to niezbędna funkcja, jeķli wykres jest dynamiczny i moŋe się zmieniaæ w miarę postępu gry. Na przykģad ģatwo jest przedstawiæ zakģócenie wywoģane trzęsieniem ziemi, usuwając (a czasem dodając) krawędzie z wykresu nawigacyjnego. Alternatywnie, rozgrywka podobna do tej z Command & Conquer moŋe dodawaæ i usuwaæ krawędzie, gdy gracze budują lub niszczą mosty i ķciany.
// zwraca liczbę aktywnych + nieaktywnych węzģów obecnych na wykresie
int NumNodes () const;
// zwraca liczbę aktywnych węzģów obecnych na wykresie
int NumActiveNodes () const;
// zwraca liczbę krawędzi obecnych na wykresie
int NumEdges () const;
// zwraca true, jeķli wykres jest skierowany
bool isDigraph () const;
// zwraca true, jeķli wykres nie zawiera ŋadnych węzģów
bool isEmpty () const;
// zwraca true, jeķli węzeģ z danym indeksem jest obecny na wykresie
bool isPresent (int nd) const;
// metody ģadowania i zapisywania wykresów z otwartego strumienia plików lub z
// nazwa pliku
bool Save (const char * FileName) const;
bool Save (std :: ofstream & stream) const;
bool Load (const char * nazwa_pliku);
bool Load (std :: ifstream & stream);
// czyķci wykres gotowy do wstawienia nowego węzģa
void Clear ();
// klienci iteratorów mogą uzyskiwaæ dostęp do węzģów i krawędzi
class ConstEdgeIterator;
class EdgeIterator;
class NodeIterator;
class ConstNodeIterator;
};
Z informacji w tej sekcji dowiedziaģeķ się, ŋe wykresy to potęŋne narzędzie, które masz do dyspozycji. Jednak sama struktura danych wykresu ma niewiele zastosowaņ. Duŋa częķæ mocy grafów jest realizowana tylko wtedy, gdy są one obsģugiwane przez algorytmy zaprojektowane do ich eksploracji, albo w celu znalezienia okreķlonego węzģa lub znalezienia ķcieŋki między węzģami. Pozostaģa częķæ jest poķwięcona jest badaniu kilku z tych algorytmów.
Algorytmy wyszukiwania wykresów
Teoria grafów jest popularnym obszarem badaņ matematyków i opracowano wiele algorytmów do wyszukiwania i eksploracji topologii wykresu. Korzystając z algorytmów wyszukiwania, moŋna między innymi:
• Odwiedž kaŋdy węzeģ na wykresie, skutecznie mapując topologiaę wykresu
• Znajdž dowolną ķcieŋkę między dwoma węzģami. Jest to przydatne, jeķli chcesz znaležæ węzeģ, ale tak naprawdę nie zaleŋy ci na tym, jak tam dotrzeæ. Na przykģad tego rodzaju wyszukiwania moŋna uŋyæ do znalezienia jednego (lub więcej) rozwiązania puzzli Wieŋe Hanoi.
• Znajdž najlepszą ķcieŋkę między dwoma węzģami. To, co jest "najlepsze", zaleŋy od problemu. Jeķli przeszukiwany wykres jest grafem nawigacyjnym, najlepszą ķcieŋką moŋe byæ najkrótsza ķcieŋka między dwoma węzģami, ķcieŋka, która zabiera agenta między dwoma punktami w najszybszym czasie, ķcieŋka omijająca linię wzroku wroga lub najcichsza ķcieŋka (? la Thief). Jeķli wykres jest wykresem stanu, takim jak ukģadanka z Wieŋ Hanoi, to najlepsza ķcieŋka będzie tą, która dojdzie do rozwiązania w jak najmniejszej liczbie kroków
Zanim przejdę do drobiazgów, chciaģbym wyjaķniæ, ŋe wielu z was na początku będzie miaģo trudnoķci z zrozumieniem niektórych z tych algorytmów. W rzeczywistoķci uwaŋam, ŋe algorytmy wyszukiwania grafów powinny zawieraæ ostrzeŋenie zdrowotne. Wģaķciwe byģoby coķ takiego:
OSTRZEŊENIE!
Strzeŋ się! Algorytmy wyszukiwania mają zdolnoķæ tworzenia w przeciętnym ludzkim mózgu strasznych frustracji i dezorientacji, co prowadzi do bólów gģowy, nudnoķci i braku snu. Spontaniczne i nadmierne wycie nie jest niczym niezwykģym. Naleŋy pamiętaæ, ŋe te objawy są powszechne na wczesnych etapach krzywej uczenia się i nie są generalnie powodem do niepokoju. Zwykģa usģuga jest zwykle wznawiana w rozsądnym czasie. (Jeķli objawy utrzymują się, trzymaj się z dala od ruchliwych dróg, ŋyletek i zaģadowanej broni. Zasięgnij porady medycznej przy najbliŋszej okazji.)
Powaŋnie, jednak dla wielu osób te rzeczy mogą byæ trudne do zrozumienia. Z tego powodu poķwięcę czas na wyjaķnienie kaŋdego algorytmu. Bardzo waŋne jest, aby zrozumieæ teorię i nie uŋywaæ tych technik w sposób "wycinaj i wklej", poniewaŋ często moŋesz chcieæ zmodyfikowaæ algorytm zgodnie z wģasnymi wymaganiami. Bez zrozumienia, jak dziaģają te wyszukiwania, wszelkie modyfikacje będą prawie niemoŋliwe, a ty będziesz drapaģ się po gģowie z frustracją.
Niedoinformowane wyszukiwania grafów
Niedoinformowane wyszukiwania grafów lub ķlepe wyszukiwania, jak to czasem bywa znane, przeszukuje wykres bez względu na związane z nim koszty krawędzi. Mogą jednak rozróŋniaæ poszczególne węzģy i krawędzie, umoŋliwiając im identyfikację węzģa docelowego lub rozpoznanie wczeķniej odwiedzonych węzģów lub krawędzi. Jest to jedyna informacja wymagana do peģnego zbadania wykresu (do odwiedzenia kaŋdego węzģa) lub znalezienia ķcieŋki między dwoma węzģami.
Gģębokie pierwsze wyszukiwanie
Poznaj maģego Billy′ego. Billy stoi przy wejķciu do typowego parku rozrywki: zlepek przejaŋdŋek i innych atrakcji oraz ķcieŋki wijące się przez park, który je ģączy. Billy nie ma mapy, ale chętnie odkrywa, jakie przejaŋdŋki i inną rozrywkę ma do zaoferowania park. Na szczęķcie Billy wie o teorii grafów i szybko dostrzega podobieņstwo między ukģadem parku rozrywki a wykresem. Widzi, ŋe kaŋdą atrakcję moŋna przedstawiæ za pomocą węzģa, a ķcieŋki między nimi za pomocą krawędzi. Wiedząc o tym, Billy moŋe zapewniæ, ŋe odwiedzi kaŋdą atrakcję i zejdzie kaŋdą ķcieŋką, uŋywając algorytmu wyszukiwania zwanego pierwszym wyszukiwaniem gģębokim lub w skrócie DFS. Pierwsze wyszukiwanie gģębokie jest tak nazwane, poniewaŋ wyszukuje, przesuwając jak najgģębiej na wykresie. Kiedy uderza w ķlepy zauģek, wraca do pģytszego węzģa, gdzie moŋe kontynuowaæ eksplorację. Na przykģadzie parku tematycznego dziaģa ten algorytm:
Od wejķcia do parku (węzeģ žródģowy) Billy odnotowuje opis i ķcieŋki, które rozciągają się na zewnątrz (krawędzie) na kartce papieru. Następnie wybiera jedną ze ķcieŋek do zejķcia. Nie ma znaczenia, moŋe wybraæ jeden losowo, pod warunkiem, ŋe jest to ķcieŋka, której nie zbadaģ. Za kaŋdym razem, gdy ķcieŋka prowadzi Billy′ego do nowej atrakcji, notuje jej nazwę i ķcieŋki z nią związane. Ilustracje oznaczone od A do D na rycinie przedstawiają kilka pierwszych kroków tego procesu.
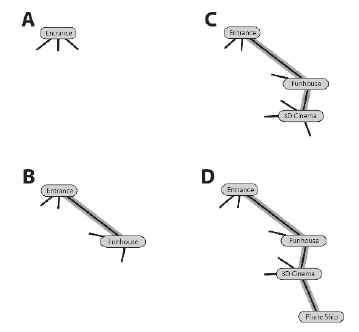
Cienkie czarne linie reprezentują niezbadane ķcieŋki a podķwietlone linie pokazują ķcieŋki, które Billy postanowiģ zejķæ. Kiedy osiąga pozycję pokazaną w D, Billy zauwaŋa, ŋe ze statku pirackiego nie prowadzą ŋadne nowe ķcieŋki (w mowie graficznej ten węzeģ jest znany jako węzeģ koņcowy). Dlatego, aby kontynuowaæ wyszukiwanie, cofa się do kina 3D, gdzie istnieją dalsze niezbadane ķcieŋki do przejķcia. Patrz rysunek E.
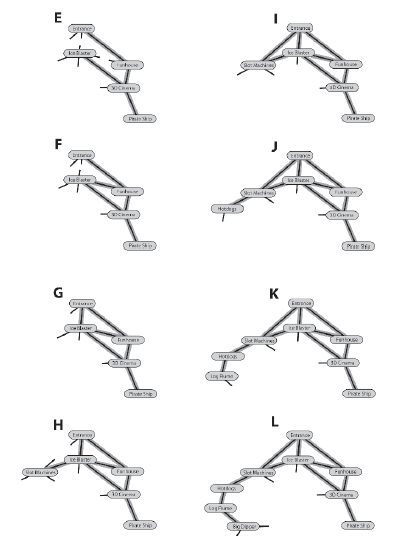
Kiedy dotrze do Lodowego Blastera, są cztery niezbadane ķcieŋki do wypróbowania. Pierwsze dwie, po których nawiguje, prowadzą z powrotem do wczeķniej odwiedzonych miejsc - Wejķcia i Funhouse - więc kaŋdą ķcieŋkę oznaczy jako zbadaną przed powrotem do Ice Blaster, aby wypróbowaæ inną trasę. W koņcu znajduje ķcieŋkę prowadzącą do automatów. Patrz rysunek F, G i H. Ten proces przesuwania się do przodu przez wykres tak daleko, jak to moŋliwe, zanim nastąpi powrót do wczeķniej niezbadanych ķcieŋek, trwa do momentu zmapowania caģego parku rozrywki. Kroki od I do L na rysunku przedstawiają kilka kolejnych etapów procesu. Rycina poniŋszy pokazuje gotowy wykres po tym, jak
UWAGA Przy danym węžle žródģowym pierwsze wyszukiwanie gģębokoķci moŋe jedynie zagwarantowaæ, ŋe wszystkie węzģy i krawędzie zostaną odwiedzone na poģączonym wykresie. Pamiętaj, ŋe poģączony wykres to taki, na którym moŋna dotrzeæ do dowolnego węzģa z dowolnego innego. Jeķli przeszukujesz niepowiązany wykres, taki jak C na rysunku wczeķniej, algorytm naleŋy rozwinąæ, aby zawieraģ węzeģ žródģowy dla kaŋdego pod-wykresu.
Implementacja algorytmu
DFS jest zaimplementowany jako szablon klasy i moŋe byæ uŋywany z dowolną implementacją grafu (np. Gęsty wykres) przy uŋyciu tego samego interfejsu, co pokazana wczeķniej klasa SparseGraph. Najpierw przejrzyjmy deklarację klasy, a następnie opiszę sam algorytm wyszukiwania.
template
class Graph_SearchDFS
{
private:
// w celu zwiększenia czytelnoķci
enum {visited, unvisited, no_parent_assigned};
// utwórz typy typef dla typów krawędzi i węzģów uŋywanych przez wykres
typedef typename graph_type::EdgeType Edge;
typedef typename graph_type::NodeType Node;
private:
// odniesienie do wykresu do przeszukania
const graph_type & m_Graph;
// rejestruje indeksy wszystkich odwiedzanych węzģów jeķli
// wyszukiwanie trwa
std::vector
m_Visited zawiera tę samą liczbę elementów, co węzģy na wykresie. Kaŋdy element jest początkowo ustawiony jako niezwiedzony. W miarę postępu wyszukiwania za kaŋdym razem, gdy odwiedzany jest węzeģ, odpowiadający mu element w m_Visited zostanie ustawiony na odwiedzony.
// to utrzymuje trasę wybraną do celu
std::vector
m_Route zawiera równieŋ tę samą liczbę elementów, co na węžle na wykresie. Kaŋdy element jest początkowo ustawiony na no_parent_assigned. W miarę przeszukiwania wykresu ten wektor przechowuje trasę do węzģa docelowego, rejestrując elementy nadrzędne kaŋdego węzģa pod odpowiednim indeksem. Na przykģad, jeķli ķcieŋka do celu podąŋa za węzģami 3 - 8 - 27, to m_Route [8] będzie zawieraæ 3, a m_Route będzie zawieraæ 8.
/ indeksy węzģa žródģowego i docelowego
int m_iSource,
m_iTarget;
Podczas eksploracji wykresu najczęķciej szukasz okreķlonego celu (lub celów). Aby ponownie uŋyæ analogii do parku rozrywki, wygląda to tak, jakbyķ szukaģ konkretnej jazdy, na przykģad kolejki górskiej. Mając to na uwadze, algorytmy wyszukiwania zwykle wykorzystują warunek zakoņczenia, zwykle w postaci indeksu węzģa docelowego.
//true, jeķli ķcieŋka do celu zostaģa znaleziona
bool m_bFound;
//ta metoda wykonuje wyszukiwanie w DFS
bool Search();
Ta metoda jest kodem, który implementuje algorytm pierwszego wyszukiwania gģębokoķci. Za chwilę zanurzymy się w jej wnętrznoķci.
Graph_SearchDFS(const graph_type& graph,
int source,
int target = -1 ):
m_Graph(graph),
m_iSource(source),
m_iTarget(target),
m_bFound(false),
m_Visited(m_Graph.NumNodes(), unvisited),
m_Route(m_Graph.NumNodes(), no_parent_assigned)
{
m_bFound = Search();
}
//zwraca wartoķæ true, jeķli węzeģ docelowy zostaģ zlokalizowany
bool Found()const{return m_bFound;}
//zwraca wektor indeksów węzģów, które zawierają najkrótszą ķcieŋkę
//od žródģa do celu
std::list
};
Algorytm wyszukiwania DFS jest implementowany przy uŋyciu wskažniki do krawędzi std :: stack const zawierających wykres, który wyszukuje. Stos jest strukturą danych ostatnia, pierwsza wyszģa (zwykle w skrócie LIFO). Stos jest uŋywany w podobny sposób, jak arkusz papieru, którego nasz przyjaciel Billy uŋywaģ do eksploracji parku tematycznego: Krawędzie są popychane na nim w trakcie wyszukiwania, tak jak Billy zapisywaģ ķcieŋki podczas eksploracji. Rzuæ okiem na kod metody wyszukiwania, a następnie przedstawię ci przykģad, aby upewniæ się, ŋe rozumiesz, jak dziaģa jego magia.
template
bool Graph_SearchDFS
{
//utwórz standardowy stos wskažników do krawędzi
std::stack
// stwórz atrapę i umieķæ na stosie
Edge Dummy(m_iSource, m_iSource, 0);
stack.push(&Dummy);
// gdy na stosie są krawędzie, szukaj dalej
while (!stack.empty())
{
//zģap następną krawędž
const Edge* Next = stack.top();
//usuņ krawędž ze stosu
stack.pop();
//zanotuj element nadrzędny węzģa, na który wskazuje ta krawędž
m_Route[Next->To] = Next->From();
//i oznacz jako odwiedzone
m_Visited[Next->To()] = visited;
//jeķli cel zostaģ znaleziony, metoda moŋe zwróciæ sukces
if (Next->To() == m_iTarget)
{
return true;
}
// popchnij krawędzie prowadzące od węzģa, na który wskazuje ta krawędž
// stos (pod warunkiem, ŋe krawędž nie wskazuje wczeķniej
// odwiedzony węzeģ)
graph_type::ConstEdgeIterator ConstEdgeItr(m_Graph, Next->To());
for (const Edge* pE=ConstEdgeItr.begin();
!ConstEdgeItr.end();
pE=ConstEdgeItr.next())
{
if (m_Visited[pE->To()] == unvisited)
{
stack.push(pE);
}
}
}//podczas
// braku ķcieŋki do celu>
return false;
}
Aby pomóc Ci zrozumieæ, przeanalizujmy prosty przykģad. Uŋywając niekierowanego wykresu pokazany na poniŋszym rysunku, powiedzmy, ŋe chcemy wyszukaæ węzeģ 3 (węzeģ docelowy), rozpoczynając wyszukiwanie od węzģa 5 (węzeģ žródģowy).
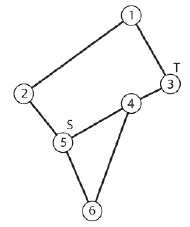
Wyszukiwanie rozpoczyna się od utworzenia sztucznej krawędzi - prowadzącej od węzģa žródģowego z powrotem do węzģa žródģowego - i umieszczenia go na stosie.
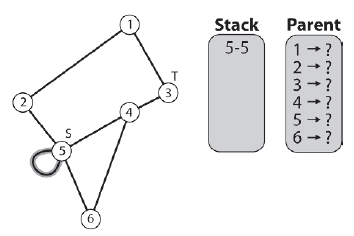
Podķwietlenie wskazuje, ŋe krawędž znajduje się na stosie. Wyszukiwanie odbywa się po wprowadzeniu pętli while. Podczas gdy są jeszcze niezbadane krawędzie stosu, algorytm iteruje następujące kroki. Komentarze w nawiasach opisują sytuację dla pierwszej iteracji w pętli.
1. Usuņ najwyŋszą krawędž ze stosu. (Atrapa krawędzi [5-5].)
2. Zanotuj element nadrzędny węzģa docelowego krawędzi, wstawiając indeks elementu nadrzędnego do wektora m_Routes, w elemencie, do którego odwoģuje się indeks węzģa docelowego. (Poniewaŋ krawędž fikcyjna jest uŋywana do uruchomienia algorytmu, rodzicem węzģa 5 jest równieŋ węzeģ 5. Dlatego m_Routes [5] jest ustawiony na 5.)
3. Zaznacz węzeģ docelowy krawędzi jako odwiedzony, przypisując odwiedzone wyliczenie do odpowiedniego indeksu w wektorze m_Visited
(m_Visited [5] = visited).
4. Test na zakoņczenie. Jeķli węzeģ docelowy krawędzi jest węzģem docelowym, wyszukiwanie moŋe zwróciæ sukces. (5 nie jest węzģem docelowym, więc wyszukiwanie jest kontynuowane).
5. Jeķli węzeģ docelowy krawędzi nie jest celem, to pod warunkiem, ŋe węzeģ, na który wskazuje bieŋąca krawędž, nie zostaģ jeszcze odwiedzony, wszystkie sąsiednie krawędzie zostaną wypchnięte na stos. (Krawędzie [5-2], [5-4] i [5-6] są wpychane w stos.)
Rysunek poniŋszy pokazuje stan gry algorytmu po jednej iteracji pętli while. Szary kolor węzģa žródģowego wskazuje, ŋe zostaģ on oznaczony jako odwiedzony.
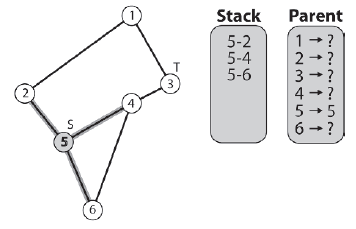
W tym momencie algorytm rozgaģęzia się z powrotem na początek pętli while, zsuwa następną krawędž ze szczytu stosu (krawędž [5-2]), zaznacza węzeģ docelowy jako odwiedzony (węzeģ 2) i notuje elementu nadrzędnego węzģa docelowego (węzeģ 5 jest elementem nadrzędnym węzģa 2). Następnie algorytm bierze pod uwagę, które krawędzie powinny zostaæ zepchnięte na stos. Węzeģ 2 (do którego krawędzi [5-2] wskazuje) ma dwie sąsiednie krawędzie: [2-1] i [2-5]. Węzeģ 5 zostaģ oznaczony jako odwiedzony, więc krawędž [2-5] nie zostaje dodana do stosu. Poniewaŋ węzeģ 1 nie zostaģ odwiedzony, prowadząca do niego krawędž [2-1] jest wypychana na stos. Zobacz rysunek 5.20. Gruba czarna linia z [5-2] wskazuje, ŋe konkretna krawędž nie będzie dalej rozpatrywana.
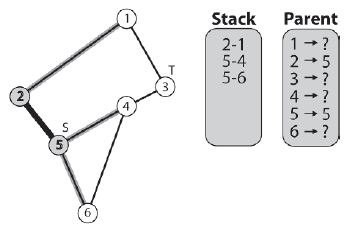
Po raz kolejny algorytm rozgaģęzia się z powrotem na początek pętli while i zrzuca następną krawędž ze stosu (krawędž [2 -1]), zaznacza węzeģ docelowy jako odwiedzony (węzeģ 1) i zapisuje informacje o jego rodzicu (węžle 2 jest rodzicem węzģa 1). Węzeģ 1 ma krawędzie prowadzące do węzģa 3 i węzģa 2. Węzeģ 2 zostaģ juŋ odwiedzony, więc tylko krawędž [1-3] jest wypychana na stos.
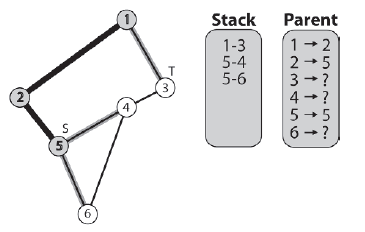
Tym razem, gdy algorytm wyskakuje ze stosu następną krawędzią [1-3], po zwykģej procedurze zaznaczania węzģa docelowego i odnotowywania elementu nadrzędnego, algorytm stwierdza, ŋe zlokalizowaģ cel, w którym to momencie algorytm koņczy dziaģanie. Na tym etapie status jest pokazany na rysunku
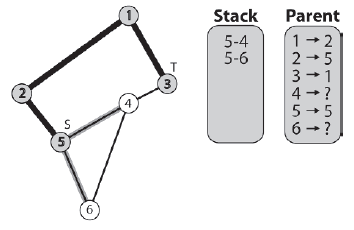
Podczas wyszukiwania ķcieŋka do węzģa docelowego jest przechowywana w wektorze m_Route (przedstawionym na poprzednich rysunkach tabelą uŋywaną do przechowywania rodziców kaŋdego węzģa). Metoda GetPathToTarget wyodrębnia te informacje i zwraca je jako wektor liczb caģkowitych reprezentujących indeksy węzģów, których agent musi przestrzegaæ, aby przejķæ od žródģa do celu. Oto jak wygląda kod žródģowy:
template
std::list
{
std::list
// po prostu zwróæ pustą ķcieŋkę, jeķli nie znaleziono ķcieŋki do celu lub jeķli
// nie okreķlono celu
if (!m_bFound || m_iTarget<0) return path;
int nd = m_iTarget;
path.push_back(nd);
while (nd != m_iSource)
{
nd = m_Route[nd];
path.push_back(nd);
}
return path;
}
To bardzo prosta metoda. Zaczyna się od przetestowania, aby zobaczyæ, jaki jest element nadrzędny węzģa docelowego, a następnie element nadrzędny tego węzģa i tak dalej, aŋ do osiągnięcia węzģa žródģowego. W przykģadzie, który podąŋaģeķ na kilku ostatnich stronach, ķcieŋka, którą zwraca ta metoda, to 5 - 2 - 1 - 3.
UWAGA W celu zapewnienia szybkoķci i wydajnoķci implementacje algorytmów wyszukiwania opisanych w tym rozdziale są zaprojektowane do dziaģania na wykresach utworzonych przed wyszukiwaniem. Jednak w przypadku niektórych problemów nie będzie moŋna tego zrobiæ, poniewaŋ oczekiwany rozmiar wykresu jest albo zbyt duŋy, aby moŋna go byģo zapisaæ w pamięci, albo dlatego, ŋe trzeba oszczędzaæ pamięæ, tworząc tylko te węzģy i krawędzie, które są niezbędne do wyszukiwania. Na przykģad, jeķli chcesz przeszukaæ przestrzeņ stanu gry, takiej jak szachy, nie moŋna zbudowaæ wykresu stanu przed wyszukiwaniem ze względu na ogromną liczbę moŋliwych stanów. Zamiast tego węzģy i krawędzie muszą byæ tworzone w miarę wyszukiwania.
DFS w akcji
Aby przekazaæ uŋyteczne informacje wizualne, stworzyģem program demonstracyjny, który pokazuje róŋne wyszukiwania wykresów na wykresie nawigacyjnym ukģadu siatki. Ten typ ukģadu węzģów jest powszechnie spotykany w grach opartych na kafelkach, w których węzeģ jest umieszczony na ķrodku kaŋdej pģytki, a krawędzie ģączą się z najbliŋszymi oķmioma sąsiadami. Linie pionowe i poziome reprezentują granice kafelków, kropki są węzģami wykresu, a cienkie linie wychodzące z węzģów są krawędziami ģączącymi. Niestety zrzut ekranu jest drukowany w skali szaroķci, więc moŋe nie byæ ģatwo zobaczyæ wszystko wyražnie. Jeķli jesteķ blisko komputera, polecam uruchomiæ plik wykonywalny PathFinder.exe i nacisnąæ klawisz "G", aby wyķwietliæ wykres.
UWAGA. Chociaŋ w prawdziwym ķwiecie poģączenia diagonalne w demonstracji PathFinder są dģuŋsze niŋ poģączenia pionowe i poziome, pierwsze wyszukiwanie gģębokoķci nie ma wiedzy na temat ŋadnego związanego z tym kosztu krawędzi i dlatego traktuje wszystkie krawędzie jako równe.
W wersji demo uŋyģem ukģadu węzģów opartego na siatce, poniewaŋ uģatwia tworzenie eksperymentalnych wykresów poprzez blokowanie kafelków w celu reprezentowania przeszkód lub zróŋnicowanego terenu. Nie oznacza to jednak, ŋe Twoja gra musi korzystaæ z wykresu opartego na siatce. Podkreķlam ten punkt, poniewaŋ często widzę, ŋe nowicjusze mają trudnoķci ze zrozumieniem, w jaki sposób wykres moŋe mieæ dowolny ksztaģt inny niŋ siatka. Mówią na przykģad: "Wiem, jak dziaģa algorytm wyszukiwania XYZ dla opartych na kafelkach gier RTS, ale czy moŋna go uŋyæ w moim FPS?" Często spotykam się z tego rodzaju pytaniami i przypuszczam, ŋe dzieje się tak, poniewaŋ większoķæ prezentacji, samouczków i artykuģów na temat wyszukiwania ķcieŋek pokazuje przykģady przy uŋyciu ukģadu węzģa oparty na siatce (z powodów juŋ wymienionych) i myķlę, ŋe ludzie zakģadają, ŋe tak wģaķnie musi byæ. Proszę … Bģagam, nie popeģniaj tego samego bģędu! Wykresy mogą mieæ dowolny ksztaģt (i dowolną liczbę wymiarów). W kaŋdym razie wróæmy do DFS. Zrzut ekranu pokazuje prostą mapę, którą utworzyģem, blokując niektóre kafelki jako przeszkody.

Poniewaŋ jest wydrukowany w skali szaroķci, sprawiģem, ŋe węzģy žródģowy i docelowy są lepiej widoczne, zaznaczając je odpowiednio kwadratem i krzyŋem. Liczby w prawym dolnym rogu pokazują liczbę węzģów i krawędzi na podstawowym wykresie
Ulepszenia systemu plików DFS
Niektóre wykresy mogą byæ bardzo gģębokie, a DFS moŋna ģatwo opóžniæ, przechodząc zbyt daleko zģą ķcieŋką. W najgorszym scenariuszu system plików DFS moŋe nie byæ w stanie wyprowadziæ się z niewģaķciwego wyboru na początku wyszukiwania, powodując trwaģe zablokowanie. Jako przykģad zaģóŋmy, ŋe chcesz znaležæ rozwiązanie losowo pomieszanego Kostki Rubika. Caģa przestrzeņ stanu dla tego problemu jest ogromna i zabrania generowania peģnego wykresu stanu przed jakimkolwiek wyszukiwaniem, dlatego węzģy są tworzone w locie, poniewaŋ kaŋdy stan jest rozwijany, zaczynając od węzģa gģównego. W pewnym momencie wyszukiwania algorytm DFS moŋe wybraæ krawędž prowadzącą do pod grafu przestrzeni stanu, który nie zawiera stanu rozwiązania, ale jest zbyt duŋy, aby moŋna go byģo w peģni rozwinąæ, biorąc pod uwagę dostępną moc obliczeniową. Powoduje to, ŋe rozwiązanie nigdy nie jest zwracane przez DFS, a komputer skutecznie zawiesiæ. Na szczęķcie moŋna temu zapobiec, ograniczając liczbę gģębokoķci wyszukiwania algorytmu DFS przed rozpoczęciem cofania. Nazywa się to wyszukiwaniem gģębokoķci. Korzystając z wyszukiwania z ograniczoną gģębokoķcią, pod warunkiem, ŋe gģębokoķæ jest tą, którą algorytm moŋe przeszukiwaæ, biorąc pod uwagę dostępną moc obliczeniową, DFS zawsze zwróci rozwiązanie, jeķli takie istnieje na tej gģębokoķci. Jednak wyszukiwanie z ograniczoną gģębokoķcią ma powaŋną wadę. Skąd wiesz, jaki limit ustawiæ dla maksymalnej gģębokoķci wyszukiwania? W przypadku większoķci problematycznych domen nie moŋna oceniæ, jaki powinien byæ ten limit. Korzystając z Kostki Rubika jako przykģadu, rozwiązaniem moŋe byæ trzy kroki do przodu lub piętnaķcie. Jeķli maksymalna gģębokoķæ wyszukiwania jest ustawiona na dziesięæ, moŋe, ale nie musi znaležæ rozwiązania. Jeķli jest ustawiony zbyt wysoko, liczba moŋliwych stanów moŋe spowodowaæ zawieszenie wyszukiwania. Na szczęķcie istnieje sposób na obejķcie tego problemu: iteracyjne pogģębianie DFS. Iteracyjne wyszukiwanie pogģębienia polega na uŋyciu DFS do przeszukiwania wykresu z limitem gģębokoķci równym jeden, następnie gģębokoķæ druga, potem trzy itd., Aŋ do zakoņczenia wyszukiwania. Chociaŋ na pierwszy rzut oka moŋe się to wydawaæ marnotrawstwem zasobów, poniewaŋ węzģy na pģytszych gģębokoķciach są przeszukiwane wiele razy, w rzeczywistoķci większoķæ węzģów zawsze znajduje się na granicy poszukiwaņ. Jest to szczególnie prawdziwe w przypadku przeszukiwania wykresów o wysokim wspóģczynniku rozgaģęzienia. Biorąc pod uwagę wspóģczynnik rozgaģęzienia wynoszący osiem, podobnie jak wykres na demie PathFinder, liczba węzģów na skraju jest pokazana w tabeli
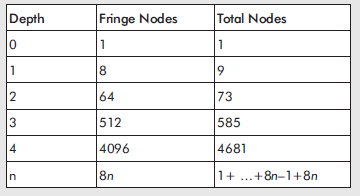
Wyobraŋam sobie, ŋe niektórzy z was mogą myķleæ coķ w stylu "Ale jeķli podczas normalnego wyszukiwania DFS gģębokoķæ n zawieszę komputer, to na pewno, gdy iteracyjne pogģębianie DFS osiągnie tę samą gģębokoķæ, zawiesi takŋe komputer!" Odpowiedž brzmi: tak, jeķli IDDFS moŋe wejķæ tak gģęboko, pojawią się problemy, ale sekretem stosowania iteracyjnego pogģębiania jest narzucenie granicy, zwykle definiowanej jako limit czasowy. Po upģywie czasu przeznaczonego na wyszukiwanie algorytm koņczy się bez względu na osiągnięty poziom. Następstwem tego metodycznego podejķcia jest to, ŋe biorąc pod uwagę wystarczającą iloķæ czasu i prawidģowy cel, iteracyjne pogģębianie DFS nie tylko znajdzie cel, ale znajdzie cel w jak najmniejszej liczbie kroków.
Linia na poniŋszym zrzucie ekranu ilustruje ķcieŋkę, którą podjąģ DFS w poszukiwaniu celu. Jak widaæ, meandruje wokóģ prawie caģego obszaru mapy, zanim natknie się na węzeģ docelowy, wyražnie pokazując, ŋe chociaŋ DFS znajduje cel, nie gwarantuje znalezienia najlepszej trasy do celu.

Naleŋy równieŋ zauwaŋyæ w tym przykģadzie, ŋe DFS nie zbadaģ ŋadnych krawędzi poza ķcieŋką do węzģa docelowego. Gdy węzeģ docelowy moŋna osiągnąæ wieloma ķcieŋkami, jest to wspólna cecha systemu plików DFS, co czyni go szybkim algorytmem do zastosowania, gdy dģugoķæ ķcieŋki jest nieistotna (tj. Przy przeszukiwaniu przestrzeni stanów w celu sprawdzenia, czy istnieje konkretny stan w przeciwieņstwie do okreķlenie najszybszej trasy do tego stanu).
Szerokoķæ Pierwszego Wyszukiwania
Chociaŋ zwykģy system plików DFS gwarantuje znalezienie węzģa docelowego na poģączonym wykresie, nie gwarantuje znalezienia najlepszej ķcieŋki do tego węzģa - ķcieŋki zawierającej najmniej krawędzi. W poprzednim przykģadzie DFS daģo ķcieŋkę obejmującą trzy krawędzie, mimo ŋe najlepsza ķcieŋka obejmuje dwie: 5-4-3. Algorytm BFS wysuwa się z węzģa žródģowego i bada kaŋdy z węzģów, do których prowadzą jego krawędzie, przed rozwinięciem z tych węzģów i sprawdzanie wszystkich krawędzi, z którymi się ģączą itd. Moŋesz myķleæ o wyszukiwaniu jako eksploracji wszystkich węzģów, które są jedną krawędzią od węzģa žródģowego, następnie wszystkie węzģy dwie krawędzie dalej, a następnie trzy krawędzie i tak dalej, aŋ do znalezienia węzģa docelowego. Dlatego teŋ, gdy tylko cel zostanie zlokalizowany, ķcieŋka do niego prowadząca ma gwarancję jak najmniejszej liczby krawędzi. (Mogą istnieæ inne ķcieŋki o równej dģugoķci, ale nie będzie krótszej ķcieŋki).
Implementacja algorytmu
Algorytm dla BFS jest prawie dokģadnie taki sam, jak dla DFS, z tym wyjątkiem, ŋe uŋywa stosu kolejki pierwsze wejķcie, pierwsze wyjķcie (FIFO) zamiast stosu. W związku z tym krawędzie czasu są pobierane z kolejki w tej samej kolejnoķci, w jakiej są umieszczane w kolejce. Spójrz na kod žródģowy metody wyszukiwania BFS.
template
bool Graph_SearchBFS< graph_type>::Search()
{
// stwórz standardową kolejkę krawędzi wskažnika
std::queue
// utwórz atrapę i umieķæ w kolejce
const Edge Dummy(m_iSource, m_iSource, 0);
Q.push(&Dummy);
// zaznacz węzeģ žródģowy jako odwiedzony
m_Visited[m_iSource] = visited;
// gdy w kolejce są krawędzie, szukaj dalej
while (!Q.empty())
{
// zģap następną krawędž
const Edge* Next = Q.front();
Q.pop();
// zaznacz element nadrzędny tego węzģa
m_Route[Next->To()] = Next->From();
// wyjķcie, jeķli cel zostaģ znaleziony
if (Next->To() == m_iTarget)
{
return true;
}
// pchnij krawędzie prowadzące od węzģa na koņcu tej krawędzi
// do kolejki
graph_type::ConstEdgeIterator ConstEdgeItr(m_Graph, Next->To());
for (const Edge* pE=ConstEdgeItr.begin();
!ConstEdgeItr.end();
pE=ConstEdgeItr.next())
{
// jeķli węzeģ jeszcze nie byģ odwiedzany, moŋemy go przesģaæ na
// krawędž do kolejki
if (m_Visited[pE->To()] == unvisited)
{
Q.push(pE);
// węzeģ jest tutaj oznaczony jako odwiedzony, ZANIM zostanie sprawdzony, poniewaŋ
// zapewnia, ŋe w kolejce będzie zawsze umieszczonych maksymalnie N krawędzi,
// zamiast krawędzi E.
m_Visited[pE->To()] = visited;
}
}
}
// brak ķcieŋki do celu
return false;
}
Aby wyjaķniæ ci algorytm, przejdžmy do tego samego przykģadu, co poprzednio. Rysunek ponižszy odķwieŋy twoją pamięæ.
BFS zaczyna się jak DFS. Najpierw tworzona jest sztuczna krawędž [5-5] i wpychana do kolejki. Następnie węzeģ žródģowy jest oznaczony jako odwiedzony.
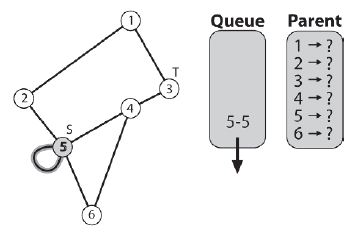
Następnie algorytm odnotowuje rodzica 5. Tak jak poprzednio, poniewaŋ pierwszą krawędzią, którą naleŋy wziąæ pod uwagę, jest krawędž fikcyjna, węzeģ 5 jest ustawiony jako macierzysty. Ta krawędž jest następnie usuwana z przodu kolejki i dodawane są wszystkie sąsiednie krawędzie węzģa 5 (te skierowane do niezapowiedzianych węzģów).
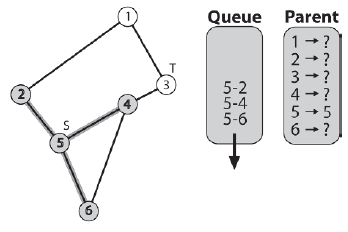
Do tej pory wszystko wyglądaģo bardzo podobnie do DFS, ale tutaj algorytm zaczyna się róŋniæ. Następnie krawędž [5-6] jest usuwana z kolejki. Zauwaŋono, ŋe węzeģ 5 jest rodzicem węzģa 6. Poniewaŋ obie sąsiednie krawędzie węzģa 6 wskazują na wczeķniej odwiedzane węzģy, nie są dodawane do kolejki.
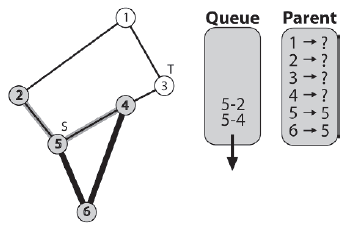
Dalej w kolejce jest krawędž [5-4]. Zauwaŋono, ŋe węzeģ 5 jest rodzicem węzģa 4. Węzeģ 4 ma trzy sąsiednie krawędzie, ale tylko krawędž [4-3] wskazuje na nieoznaczony węzeģ, więc jest to jedyny umieszczony w kolejce.
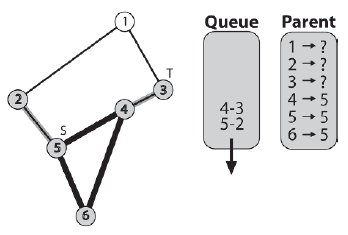
Dalej jest krawędž [5-2]. Zauwaŋono, ŋe węzeģ 5 jest rodzicem węzģa 2, a krawędž [2-1] jest umieszczona w kolejce.
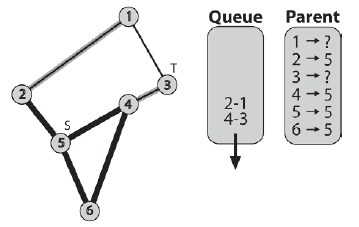
Krawędž [4-3] jest następna. Węzeģ 4 jest uwaŋany za element nadrzędny węzģa 3. Poniewaŋ węzeģ 3 jest równieŋ węzģem docelowym, w tym momencie algorytm wychodzi.
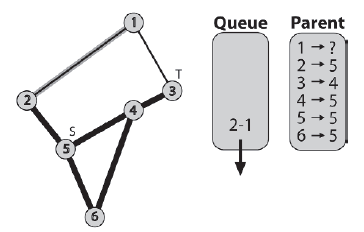
Uŋywając wektora m_Routes do przejķcia przez rodziców z węzģa docelowego do žródģa, otrzymujemy ķcieŋkę 3-4-5. Jest to ķcieŋka między dwoma zawierającymi najmniej krawędzi… najlepsza ķcieŋka.
WSKAZÓWKA. Moŋesz przyspieszyæ BFS (i wiele innych algorytmów wyszukiwania wykresów), uruchamiając jednoczeķnie dwa wyszukiwania, jedno rozpoczęte w węžle žródģowym, a drugie w węžle docelowym i zatrzymując wyszukiwanie, gdy się spotkają. Nazywa się to wyszukiwaniem dwukierunkowym.
BFS w akcji
Uruchommy ponownie program PathFinder, aby zobaczyæ, jak BFS dziaģa w prawdziwym ķwiecie. Przede wszystkim myķlę, ŋe przydaģby ci się prosty przykģad pokazany na zrzucie ekranu 5.4. (Jeķli korzystasz z programu PathFinder, zaģaduj plik no_obstacles_source_target_close.map i kliknij przycisk BF na pasku narzędzi.)
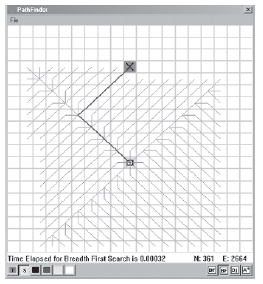
W tym przypadku nie ma ŋadnych przeszkód. Węzeģ žródģowy jest umieszczony blisko węzģa docelowego, a tylko kilka innych węzģów (kafelków) oddziela je. Ponownie gruba linia pokazuje ķcieŋkę znalezioną przez algorytm BFS. Cienkie linie reprezentują wszystkie krawędzie, które algorytm odwiedziģ w drodze do celu. To wyražnie pokazuje, jak wentylatory BFS wychodzą z węzģa žródģowego, aŋ do znalezienia węzģa docelowego. Odwiedzane krawędzie tworzą kwadratowy ksztaģt, poniewaŋ BFS, podobnie jak DFS, traktuje wszystkie krawędzie tak, jakby byģy równej dģugoķci. Ķcieŋka skręca w lewo, a następnie w prawo zamiast z tego samego powodu bezpoķrednio w kierunku węzģa docelowego. Oba wykonują tę samą liczbę kroków, ale ksztaģt ķcieŋki jest caģkowicie zaleŋny od kolejnoķci, w której eksplorowane są krawędzie kaŋdego węzģa. Zrzut ekranu 5.5 pokazuje dziaģanie BFS na tej samej mapie, którą widzieliķmy wczeķniej. Poprawa dģugoķci ķcieŋki jest wyražna, chociaŋ naleŋy się tego spodziewaæ, poniewaŋ zwykģy system plików DFS nie nadaje się do wyszukiwania najkrótszych ķcieŋek. Jeszcze raz zwróæ uwagę, jak kaŋda krawędž znajduje się na tej samej gģębokoķci z dala od węzģa žródģowego, poniewaŋ cel zostaģ odwiedzony.

Niestety, poniewaŋ BFS jest tak systematyczny w swojej eksploracji, moŋe okazaæ się niewygodny w uŋyciu na czymkolwiek innym niŋ maģe przestrzenie wyszukiwania. Jeķli oznaczymy wspóģczynnik rozgaģęzienia jako b, a liczbę krawędzi, na której węzeģ docelowy jest oddalony od žródģa jako d (gģębokoķæ), wówczas liczbę zbadanych węzģów podaje równanie

Jeķli badany wykres jest bardzo duŋy i ma wysoki wspóģczynnik rozgaģęzienia, BFS zaprzepaķci duŋo pamięci i będzie sģabo dziaģaæ. Co gorsza, jeķli przestrzeņ stanu ma tak wysoki wspóģczynnik rozgaģęzienia, ŋe uniemoŋliwia utworzenie peģnego wykresu przed wyszukiwaniem, wymagając od BFS rozszerzenia węzģów podczas eksploracji, wyszukiwanie moŋe potrwaæ dosģownie lata. W swojej ksiąŋce Artificial Intelligence: A Modern Approach Russell i Norvig podają przykģad ukģadanki o wspóģczynniku rozgaģęzienia równym 10; zakģadając, ŋe rozwinięcie kaŋdego węzģa zajmuje jedną milisekundę, BFS zajmie 3500 lat, aby osiągnąæ gģębokoķæ 14! Komputery staģy się znacznie szybszymi bestiami od czasu wydania pierwszego wydania tej ksiąŋki, ale mimo to nadal byģbyķ starszym czģowiekiem w iloķci czasu, jaką BFS zajmuje do tej gģębokoķci.
Wyszukiwania oparte na kosztach
W przypadku wielu domen problemowych powiązany wykres będzie kosztowaģ (czasami okreķlany jako cięŋar) związany z przechodzeniem przez krawędž. Na przykģad wykresy nawigacyjne zwykle mają krawędzie o koszcie proporcjonalnym do odlegģoķci między poģączonymi węzģami. Aby znaležæ najkrótsze ķcieŋki na wykresie, naleŋy wziąæ pod uwagę te koszty. Po prostu nie wystarczy - tak jak poprzednio z BFS - znaležæ ķcieŋkę zawierającą najmniejszą liczbę krawędzi, poniewaŋ przy powiązanym koszcie podróŋowanie w dóģ wielu krótszych krawędzi moŋe byæ znacznie taņsze niŋ dwóch dģugich.
Chociaŋ moŋna uŋyæ BFS lub DFS do wyczerpującego wyszukiwania przez wszystkie trasy do węzģa docelowego, sumując koszty kaŋdej ķcieŋki, a następnie wybierając ķcieŋkę o najniŋszych kosztach, jest to oczywiķcie bardzo nieefektywne rozwiązanie. Na szczęķcie mamy do dyspozycji znacznie lepsze metody.
Edge Relaxation
Algorytmy wyszukiwania omówione w pozostaģej częķci oparte są na technice zwanej relaksacją krawędzi. W trakcie dziaģania algorytm zbiera informacje o najlepszej znalezionej do tej pory ķcieŋce (BPSF) od węzģa žródģowego do dowolnego innego węzģa w drodze do celu. Informacje te są aktualizowane w miarę sprawdzania nowych krawędzi. Jeķli nowo zbadana krawędž wnioskuje, ŋe ķcieŋka do węzģa moŋe zostaæ skrócona poprzez uŋycie jej zamiast istniejącej najlepszej ķcieŋki, wówczas ta krawędž jest dodawana i ķcieŋka jest odpowiednio aktualizowana. Ten proces relaksacji, podobnie jak w przypadku wszystkich operacji graficznych, jest znacznie ģatwiejszy do zrozumienia, obserwując schemat. Spójrz na rysunek
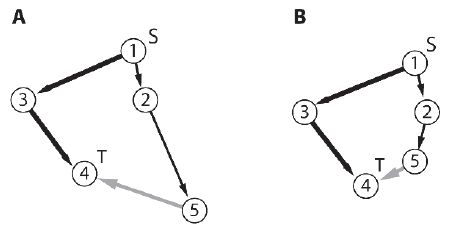
Na wykresie pokazanym w A najlepsza ķcieŋka od 1 do 4 przez 3 nie jest poprawiona przez zbadanie krawędzi [5-4]. Dlatego relaks nie jest konieczny. Jednak w przypadku wykresu B krawędž [5-4] moŋe zostaæ wykorzystana do stworzenia krótszej ķcieŋki do 4; w rezultacie BPSF musi zostaæ odpowiednio zaktualizowany poprzez zmianę elementu nadrzędnego węzģa 4 z 3 na 5 (podając ķcieŋkę 1 - 2 - 5 - 4). Proces ten nazywa się rozlužnieniem krawędzi, poniewaŋ naķladuje sposób, w jaki kawaģek spręŋysty rozciągnięty wzdģuŋ krawędzi BPSF rozlužniģby się (staģby się mniej napięty), gdy zostanie znaleziona krawędž, która uģatwia krótszą ķcieŋkę. Kaŋdy algorytm utrzymuje zmienną std :: wektor liczb zmiennoprzecinkowych (indeksowanych wedģug węzģów) reprezentujących najlepszy caģkowity koszt dla kaŋdego węzģa znaleziony do tej pory przez algorytm. Biorąc pod uwagę ogólny przypadek pokazany na rysunku 5.32, pseudokod do rozlužnienia ķcieŋki wyglądaģby mniej więcej tak:
if (TotalCostToThisNode [t]> TotalCostToThisNode [n] + EdgeCost (n-to-t))
{
TotalCostToThisNode [t] = TotalCostToThisNode [n] + EdgeCost (n-to-t));
Parent (t) = n;
}
Drzewa najkrótszej ķcieŋki
Biorąc pod uwagę wykres, G i węzeģ žródģowy, drzewo najkrótszej ķcieŋki (SPT) jest poddrzewa G, które reprezentuje najkrótszą ķcieŋkę od dowolnego węzģa na SPT do węzģa žródģowego. Ponownie, zdjęcie jest warte tysiąca sģów, więc spójrz na Rysunek 5.33. Pokazuje SPT z korzeniem ustawionym w węžle 1.
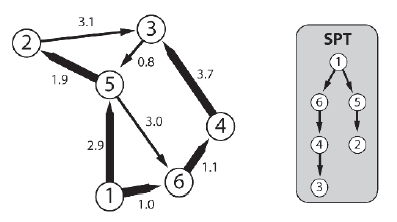
Poniŋsze algorytmy znajdują najkrótsze ķcieŋki na wykresach waŋonych przez "wyhodowanie" najkrótszego drzewa ķcieŋek na zewnątrz od węzģa žródģowego.
Algorytm Dijkstry
Profesor Edsger Wybe Dijkstra wniósģ do informatyki wiele cennych wkģadów, ale jednym z najbardziej znanych jest jego algorytm znajdowania najkrótszych ķcieŋek na wykresach waŋonych. Algorytm Dijkstry buduje najkrótsze drzewo ķcieŋek po jednej krawędzi, najpierw dodając węzeģ žródģowy do SPT, a następnie dodając krawędž, która daje najkrótszą ķcieŋkę od žródģa do węzģa, który nie jest jeszcze w SPT. W wyniku tego procesu SPT zawiera najkrótszą ķcieŋkę od kaŋdego węzģa na wykresie do węzģa žródģowego. Jeķli algorytm zostanie dostarczony z węzģem docelowym, proces zostanie zakoņczony, gdy tylko zostanie znaleziony. W momencie zakoņczenia algorytmu wygenerowany SPT będzie zawieraģ najkrótszą ķcieŋkę do węzģa žródģowego od węzģa docelowego i od kaŋdego węzģa odwiedzonego podczas wyszukiwania.
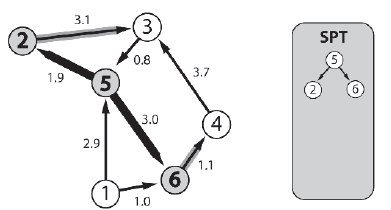
UWAGA HISTORYCZNA, Dijkstra jest równieŋ znany z tego, ŋe zaprojektowaģa i zakodowaģ kompilator Algol 60 oraz ŋarliwie potępia uŋycie instrukcji goto w programowaniu. Lubię teŋ jego powiedzenie, ŋe "pytanie, czy komputery mogą myķleæ, jest jak pytanie, czy ģodzie podwodne potrafią pģywaæ". Niestety Dijkstra zmarģ w 2002 roku na raka. Przejdžmy przez przykģad z wykorzystaniem tego samego wykresu, który widziaģeķ na powyŋszym rysunku, ale w tym przypadku węzģem žródģowym będzie węzeģ 5. Najpierw węzeģ 5 jest dodawany do SPT, a krawędzie, które go opuszczają, są umieszczane na granicy wyszukiwania.
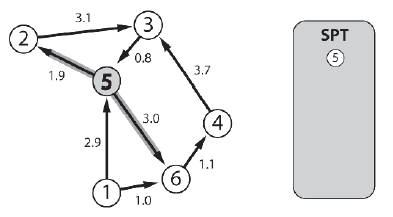
Algorytm następnie sprawdza docelowe węzģy krawędzi na granicy - 6 i 2 - i dodaje ten najbliŋszy žródģu (węzeģ 2 w odlegģoķci 1.9) do SPT. Następnie wszelkie krawędzie opuszczające węzeģ 2 są dodawane do granicy.
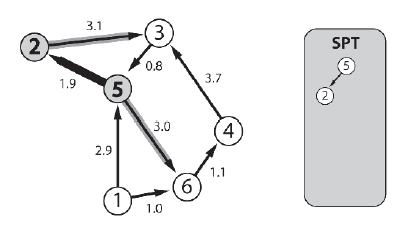
Algorytm ponownie sprawdza docelowe węzģy krawędzi na granicy. Koszt dotarcia do węzģa 3 ze žródģa wynosi 5,0, a koszt dotarcia do węzģa 6 to 3,0. Węzeģ 6 jest zatem następnym węzģem, który zostanie dodany do SPT, a wszystkie krawędzie, które go opuszczą, zostaną dodane do granicy.
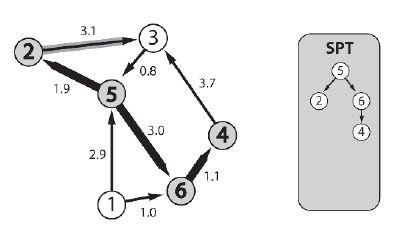
Proces powtarza się jeszcze raz. Poniewaŋ koszt węzģa 4 jest mniejszy niŋ koszt węzģa 3, jest on dodawany do SPT. Tym razem jednak jedyna krawędž z węzģa 4 prowadzi do węzģa 3 - węzģa, który jest juŋ węzģem docelowym krawędzi na granicy. Tutaj zaczyna się relaks krawędzi. Analizując obie moŋliwe ķcieŋki do 3, algorytm widzi, ŋe ķcieŋka 5 - 2 - 3 ma koszt 5,0, a ķcieŋka 5 - 6 - 4 - 3 wyŋszy koszt 7,8. Dlatego krawędž [2-3] pozostaje na SPT, a krawędž [4-3] zostaje usunięta z dalszych rozwaŋaņ.
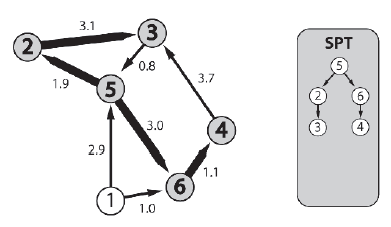
Wreszcie węzeģ 3 jest dodawany do SPT. Zobacz rysunek 5.38. Zwróæ uwagę, ŋe krawędž [3-5] nie zostaģa dodana do granicy. Wynika to z faktu, ŋe węzeģ 5 jest juŋ w SPT i nie wymaga dalszego rozpatrywania. Dodatkowo zauwaŋ, ŋe węzeģ 1 nie zostaģ dodany do SPT. Poniewaŋ istnieją tylko krawędzie prowadzące od węzģa 1, jest on skutecznie izolowany od innych węzģów na wykresie.
Implementowanie algorytmu Dijkstry
Wdroŋenie algorytmu najkrótszej ķcieŋki Dijkstry moŋe byæ początkowo bardzo zrozumiaģe i przyznaję, ŋe nie mogģem się doczekaæ napisania tej częķci, poniewaŋ uwaŋam, ŋe nie będzie to ģatwiejsze do wyjaķnienia! Myķlę, ŋe oboje musimy wziąæ gģęboki oddech, zanim przejdziemy dalej. To jest o wiele lepsze. Dobra, zacznę od pokazania deklaracji klasy. Komentarze w kodzie zawierają wyjaķnienia kaŋdej ze zmiennych skģadowych, z których większoķæ powinna brzmieæ znajomo.
template
class Graph_SearchDijkstra
{
private:
// utwórz typy typef dla typów węzģów i krawędzi uŋywanych przez wykres
typedef typename graph_type::EdgeType Edge;
typedef typename graph_type::NodeType Node;
private:
const graph_type & m_Graph;
// ten wektor zawiera krawędzie, które skģadają się na najkrótsze drzewo ķcieŋek -
// ukierunkowane poddrzewo wykresu, które zawiera najlepsze ķcieŋki
// kaŋdy węzeģ SPT do węzģa žródģowego.
std::vector
// jest to indeksowane wedģug indeksu węzģów i zawiera caģkowity koszt najlepszych
// ķcieŋka znaleziona do danego węzģa. Na przykģad m_CostToThisNode [5]
// utrzyma caģkowity koszt wszystkich krawędzi, które tworzą najlepszą ķcieŋkę
// do węzģa 5 znalezionego do tej pory w wyszukiwaniu (jeķli węzeģ 5 jest obecny i ma
// odwiedzono oczywiķcie).
std::vector
// jest to indeksowany (wedģug węzģów) wektor "macierzystych" krawędzi prowadzących do węzģów
// podģączony do SPT, ale jeszcze go nie dodano.
std::vector
int m_iSource;
int m_iTarget;
void Search();
public:
Graph_SearchDijkstra(const graph_type& graph,
int source,
int target = -1):m_Graph(graph),
m_ShortestPathTree(graph.NumNodes()),
m_SearchFrontier(graph.NumNodes()),
m_CostToThisNode(graph.NumNodes()),
m_iSource(source),
m_iTarget(target)
{
Search();
}
// zwraca wektor krawędzi definiujących SPT. Jeķli podano cel
// w konstruktorze, będzie to SPT zawierający wszystkie węzģy
// sprawdzane przed znalezieniem celu, w przeciwnym razie będzie on zawieraģ wszystkie węzģy
// na wykresie.
std::vector
// zwraca wektor indeksów węzģów obejmujących najkrótszą ķcieŋkę
// od žródģa do celu. Oblicza ķcieŋkę, pracując
// wstecz przez SPT z węzģa docelowego
std::list
//zwraca caģkowity koszt do celu
double GetCostToTarget()const;
};
Ten algorytm wyszukiwania jest implementowany przy uŋyciu indeksowanej kolejki priorytetowej. Kolejka priorytetowa, w skrócie PQ, to kolejka, która porządkuje elementy wedģug priorytetu (wtedy nie ma niespodzianek). Ten typ struktury danych moŋna wykorzystaæ do przechowywania docelowych węzģów krawędzi na granicy wyszukiwania, w kolejnoķci rosnącej odlegģoķci (kosztu) od węzģa žródģowego. Ta metoda gwarantuje, ŋe węzeģ z przodu PQ będzie węzģem, który nie jest jeszcze w SPT, który jest najbliŋej węzģa žródģowego. Czy do tej pory mam sens? Jeķli nie, proszę o zniesģawienie mnie przed ponownym przeczytaniem tego akapitu. PQ musi byæ w stanie utrzymaæ przechowywane w nim elementy w uporządkowanej kolejnoķci. Oznacza to, ŋe kaŋdy węzeģ wykresu musi mieæ dodatkową zmienną skģadową, aby przechowywaæ koszty skumulowane w tym węžle, aby operatorzy "lub" mogli zostaæ przeciąŋeni, aby zapewniæ prawidģowe zachowanie. Chociaŋ uŋycie dodatkowej zmiennej skģadowej jest z pewnoķcią poprawnym rozwiązaniem, wolaģbym nie zmieniaæ istniejącego węzģa grafu, a poza tym moŋe to byæ problematyczne, gdy uruchomionych jest wiele wyszukiwaņ jednoczeķnie, poniewaŋ kaŋde wyszukiwanie będzie wykorzystywaæ ten sam rekord danych . Moŋna temu zaradziæ, tworząc kopie węzģów, ale wówczas cenna pamięæ i szybkoķæ zostają utracone. Alternatywą jest uŋycie indeksowanej kolejki priorytetowej (w skrócie iPQ). Ten typ PQ indeksuje się do wektora kluczy. W tym przykģadzie klucze to skumulowane koszty dla kaŋdego węzģa przechowywane w wektorze m_CostToThisNode. Węzeģ jest dodawany do kolejki przez wstawienie jego indeksu. Podobnie, gdy węzeģ jest pobierany z iPQ, zwracany jest jego indeks, a nie sam węzeģ (lub wskažnik do węzģa). Tego indeksu moŋna następnie uŋyæ do uzyskania dostępu do węzģa i jego danych za poķrednictwem m_Graph :: GetNode. Czas pokazaæ ci kod žródģowy. Upewnij się, ŋe nie spiesz się i rozumiesz kaŋdą linię tego algorytmu; na dģuŋszą metę przyniesie ci dywidendy. Napisaģem obszerne komentarze w žródle, aby pomóc ci zrozumieæ, ale jeķli jesteķ zwykģym ķmiertelnikiem, wątpię, aby same komentarze wystarczyģy, by "kliknąæ" przy pierwszym czytaniu. (Jeķli po kilku odczytach nadal masz problemy z algorytmem, zdecydowanie zalecamy przejrzenie kodu na kartce papieru na prostym przykģadzie).
template
void Graph_SearchDijkstra
{
// utwórz indeksowaną kolejkę priorytetową, która będzie sortowana od najmniejszej do największej
//(od przodu do tyģu). Zauwaŋ, ŋe maksymalna liczba elementów iPQ
// moŋe zawieraæ jest NumNodes (). Wynika to z faktu, ŋe ŋaden węzeģ nie moŋe byæ reprezentowany
// w kolejce więcej niŋ jeden raz.
IndexedPriorityQLow
// umieķæ węzeģ žródģowy w kolejce
pq.insert(m_iSource);
// gdy kolejka nie jest pusta
while(!pq.empty())
{
// pobierz węzeģ o najniŋszym koszcie z kolejki. Nie zapomnij o wartoķci zwracanej
// jest * indeksem węzģa *, a nie samym węzģem. Ten węzeģ nie jest jeszcze węzģem
// w SPT, który jest najbliŋej węzģa žródģowego
int NextClosestNode = pq.Pop();
// przenieķ tę krawędž z granicy wyszukiwania do drzewa najkrótszej ķcieŋki
m_ShortestPathTree[NextClosestNode] = m_SearchFrontier[NextClosestNode];
// jeķli cel zostaģ znaleziony, wyjdž
if (NextClosestNode == m_iTarget) return;
// teraz, aby rozlužniæ krawędzie. Dla kaŋdej krawędzi podģączonej do następnego najbliŋszego węzģa
graph_type::ConstEdgeIterator ConstEdgeItr(m_Graph, NextClosestNode);
for (const Edge* pE=ConstEdgeItr.begin();
!ConstEdgeItr.end();
pE=ConstEdgeItr.next())
{
// caģkowity koszt dla węzģa, na który wskazuje ta krawędž, to koszt dla
// aktualny węzeģ plus koszt poģączenia krawędzi.
double NewCost = m_CostToThisNode[NextClosestNode] + pE->Cost();
// jeķli ta krawędž nigdy nie byģa na granicy, zanotuj koszt
// aby dotrzeæ do węzģa, na który wskazuje, a następnie dodaj krawędž do granicy
// i węzeģ docelowy do PQ.
if (m_SearchFrontier[pE->To()] == 0)
{
m_CostToThisNode[pE->To()] = NewCost;
pq.insert(pE->To());
m_SearchFrontier[pE->To()] = pE;
}
// else przetestuj, czy koszt dotarcia do węzģa docelowego za poķrednictwem
// aktualny węzeģ jest taņszy niŋ najtaņszy dotychczas znaleziony koszt. Gdyby
// ta ķcieŋka jest taņsza, przypisujemy nowy koszt do miejsca docelowego
// węzeģ, zaktualizuj jego wpis w PQ, aby odzwierciedliæ zmianę, i dodaj
// krawędž do granicy
else if ( (NewCost < m_CostToThisNode[pE->To()]) &&
(m_ShortestPathTree[pE->To()] == 0) )
{
m_CostToThisNode[pE->To()] = NewCost;
// poniewaŋ koszt jest mniejszy niŋ poprzednio, PQ musi byæ
// uciekģ się do tego.pq.ChangePriority(pE->To());
m_SearchFrontier[pE->To()] = pE;
}
}
}
}
WSKAZÓWKA. Implementacja indeksowanej kolejki priorytetowej wykorzystuje stertę dwukierunkową do przechowywania elementów. W przypadku rzadkich wykresów, jeķli kaŋda zbadana krawędž powoduje poprawę kosztów (wymaganie, aby IndexedPriorityQLow :: ChangePriority nyģ wywoģany), algorytm podaje najgorszy czas dziaģania Elog2N, chociaŋ w praktyce czas dziaģania będzie znacznie krótszy.
Dalsze ulepszenia prędkoķci moŋna uzyskaæ, stosując stertę d-way, gdzie d jest funkcją gęstoķci wykresu. Tym razem najgorszym czasem dziaģania będzie ElogdN. Gdy wszystko jest juŋ powiedziane i zrobione, algorytm najkrótszej ķcieŋki Dijkstry jest ģadny dobry wykonawca i gwarantuje znalezienie najkrótszej ķcieŋki między dwoma węzģami, jeķli taki istnieje.
Algorytm Dijkstry w dziaģaniu
Uruchommy ponownie program PathFinder i sprawdžmy, jak dziaģa algorytm Dijkstry na przykģadach, które widzieliķmy wczeķniej. Zrzut ekranu ilustruje algorytm dziaģający na prosty problem
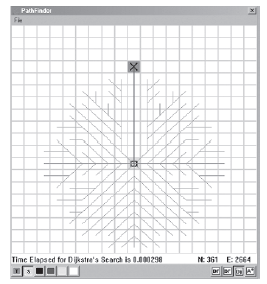
Wynik jest podobny do szerokoķci pierwszego wyszukiwania, chociaŋ teraz drzewo zawierające badane krawędzie ma okrągģy ksztaģt. Wynika to z faktu, ŋe algorytm Dijkstry dziaģa z rzeczywistymi kosztami krawędzi, dlatego tym razem krawędzie ukoķne kosztują więcej, niŋ poziomy lub pionowy. Mając to na uwadze, moŋesz zobaczyæ, jak algorytm szukaģ podobnej odlegģoķci we wszystkich kierunkach przed osiągnięciem celu. Zrzut ekranu pokazuje algorytm Dijkstry dziaģający na bardziej zģoŋonej mapie.
Podobnie jak BFS, algorytm Dijkstry analizuje bardzo duŋo krawędzi. Czy nie byģoby wspaniale, gdyby algorytm mógģ otrzymywaæ wskazówki w miarę przesuwania wyszukiwania we wģaķciwym kierunku? Na szczęķcie dla nas jest to moŋliwe. Panie i panowie! Proszę, zģóŋcie oklaski i powitajcie A *!
Dijkstra z niespodzianką: A*
Algorytm Dijkstry szuka, minimalizując dotychczasowy koszt ķcieŋki. Moŋna go znacznie poprawiæ, biorąc pod uwagę, umieszczając węzģy na granicy, szacowany koszt do celu z kaŋdego rozwaŋanego węzģa. Oszacowanie to jest zwykle okreķlane jako heurystyczne, a nazwa nadana algorytmowi wykorzystującemu tę metodę heurystycznie kierowanego wyszukiwania to A * (wymawiana ay-star). I to jest naprawdę dobre! Jeķli heurystyka stosowana przez algorytm okreķla dolną granicę rzeczywistego kosztu (nie docenia kosztu) z dowolnego węzģa do celu, wówczas A* gwarantuje optymalne ķcieŋki. W przypadku wykresów zawierających informacje przestrzenne, takich jak wykresy nawigacyjne, moŋna uŋyæ kilku funkcji heurystycznych, z których najprostszą jest odlegģoķæ w linii prostej między danymi węzģami. Jest to czasami okreķlane jako odlegģoķæ euklidesowa. A* przebiega prawie identycznie jak algorytm wyszukiwania Dijkstry. Jedyna róŋnica polega na obliczeniu kosztów węzģów na granicy wyszukiwania. Skorygowany koszt F dla węzģa umieszczonego w kolejce priorytetowej (granicy wyszukiwania) oblicza się jako:
F = G + H (5.3)
gdzie G jest ģącznym kosztem dotarcia do węzģa, a H jest heurystycznym oszacowaniem odlegģoķci do celu. W przypadku krawędzi E, która wģaķnie zeszģa z granicy i zostaģa dodana do SPT, pseudokod do obliczenia kosztu do węzģa docelowego wygląda następująco:
Koszt = Koszt skumulowany (E.From) + E.Koszt + KosztTo (docelowy)
Wykorzystując w ten sposób heurystykę, zmodyfikowane koszty kierują wyszukiwanie w kierunku węzģa docelowego zamiast promieniowaæ równo na zewnątrz we wszystkich kierunkach. Powoduje to koniecznoķæ zbadania mniejszej liczby krawędzi, co przyspiesza wyszukiwanie i jest podstawową róŋnicą między algorytmem A * i algorytmem Dijkstry.
UWAGA. Jeķli ustawisz koszt heurystyczny na zero w A *, wynikowe wyszukiwanie zachowa się dokģadnie tak samo jak algorytm Dijkstry. Rzuæmy okiem na to, jak A * dziaģa na wykresach problemów uŋywanych w programie PathFinder
A* w akcji
Zrzut ekranu pokazuje wynik dziaģania A* na prostym przykģadzie przykģadowym žródģo-cel. Jak widaæ, nie uwzględniono ŋadnych obcych krawędzi, a ķcieŋka prowadzi bezpoķrednio do celu. Zastosowaną funkcją heurystyczną jest odlegģoķæ w linii prostej między dwoma węzģami.
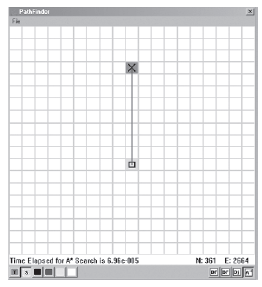
Zrzut ekranu jest równie imponujący. Zauwaŋ, jak maģo krawędzi algorytm A * musiaģ wziąæ pod uwagę przed znalezieniem celu. W rezultacie czas potrzebny na wyszukiwanie jest znacznie krótszy niŋ w przypadku innych wyszukiwaņ (mimo ŋe do obliczenia kosztu heurystycznego wymagany jest zģy pierwiastek kwadratowy).

UWAGA. Wykazano, ŋe A* jest optymalnie wydajny. Innymi sģowy, ŋaden inny algorytm wyszukiwania nie rozszerzy mniejszej liczby węzģów w poszukiwaniu ķcieŋki o najniŋszych kosztach między žródģem a celem.
Wdroŋenie A*
Klasa A* jest bardzo podobna do Graph_SearchDijkstra. Implementacja wyszukiwania wymaga utrzymania dwóch standardowych wektorów kosztów: jeden dla kosztu F dla kaŋdego węzģa, który jest indeksowany przez kolejkę priorytetową, i jeden dla kosztu G dla kaŋdego węzģa. Ponadto podczas tworzenia instancji tej klasy naleŋy okreķliæ jako parametr szablonu heurystykę, która ma zostaæ uŋyta. Ta konstrukcja uģatwia stosowanie niestandardowej heurystyki z klasą, podobnie jak heurystyka na odlegģoķæ na Manhattanie wspomniana pod koniec tego rozdziaģu. Oto deklaracja klasowa, którą moŋesz przeczytaæ:
template
class Graph_SearchAStar
{
private:
// utwórz typedef dla typu krawędzi uŋywanego przez wykres
typedef typename graph_type::EdgeType Edge;
private:
const graph_type& m_Graph;
// indeksowane wedģug węzģa. Zawiera "rzeczywisty" skumulowany koszt dla tego węzģa
std::vector
// indeksowane wedģug węzģa. Zawiera koszt dodania m_GCosts [n] do
// heurystycznego kosztu od n do węzģa docelowego. To jest wektor
// iPQ indeksuje do.
std::vector
std::vector
std::vector
int m_iSource;
int m_iTarget
// algorytm wyszukiwania A*
void Search();
public:
Graph_SearchAStar(graph_type& graph,
int source,
int target):m_Graph(graph),
m_ShortestPathTree(graph.NumNodes()),
m_SearchFrontier(graph.NumNodes()),
m_GCosts(graph.NumNodes(), 0.0),
m_FCosts(graph.NumNodes(), 0.0),
m_iSource(source),
m_iTarget(target)
{
Search();
}
// zwraca wektor krawędzi zbadanych przez algorytm
std::vector
// zwraca wektor indeksów węzģów, które zawierają najkrótszą ķcieŋkę
// od žródģa do celu
std::list
/ zwraca caģkowity koszt do celu
double GetCostToTarget()const;
};
Strategie heurystyczne do uŋytku z tą klasą muszą zapewniaæ statyczną metodę obliczania z następującym podpisem:
//oblicz koszt heurystyczny od węzģa nd1 do węzģa nd2
static double Calculate(const graph_type& G, int nd1, int nd2);
Poniewaŋ wykres uŋywany przez demo PathFinder przedstawia informacje przestrzenne, koszt heurystyczny jest obliczany jako odlegģoķæ w linii prostej (znana równieŋ jako odlegģoķæ euklidesowa) do węzģa docelowego z kaŋdego rozwaŋanego węzģa. Poniŋszy kod pokazuje, w jaki sposób taka heurystyka jest implementowana jako klasa, której moŋna uŋyæ jako parametru szablonu dla Graph_SearchAStar.
class Heuristic_Euclid
{
public:
Heuristic_Euclid(){}
// obliczyæ odlegģoķæ w linii prostej od węzģa nd1 do węzģa nd2
template
static double Calculate(const graph_type& G, int nd1, int nd2)
{
return Vec2DDistance(G.GetNode(nd1).Position, G.GetNode(nd2).Position);
}
}
Typ heurystyczny jest przekazywany jako parametr szablonu podczas tworzenia instancji klasy wyszukiwania A*. Oto jak program demonstracyjny PathFinder tworzy instancję wyszukiwania A * przy uŋyciu heurystyki euklidesowej:
//utwórz kilka czcionek typedef, aby kod wygodnie znajdowaģ się na stronie
typedef SparseGraph
typedef Graph_SearchAStar
AStarSearch AStar(*m_pGraph, m_iSourceCell, m_iTargetCell);
Implementacja metody wyszukiwania A* jest prawie identyczna jak w przypadku algorytmu najkrótszej ķcieŋki Dijkstry. Jedynym wyjątkiem jest to, ŋe koszt dotarcia do okreķlonego węzģa przed umieszczeniem go na granicy jest teraz obliczany jako G + H (zamiast tylko G). Wartoķæ H okreķla się, wywoģując metodę statyczną heurystycznej klasy strategii.
template
void Graph_SearchAStar
{
// utwórz indeksowaną kolejkę priorytetową węzģów. Kolejka da pierwszeņstwo
// do węzģów o niskich kosztach F. (F = G + H)
IndexedPriorityQLow
// umieķæ węzeģ žródģowy w kolejce
pq.insert(m_iSource);
// gdy kolejka nie jest pusta
while(!pq.empty())
{
// pobierz węzeģ o najniŋszym koszcie z kolejki
int NextClosestNode = pq.Pop();
// przenieķ ten węzeģ z granicy do drzewa opinającego
m_ShortestPathTree[NextClosestNode] = m_SearchFrontier[NextClosestNode];
// jeķli cel zostaģ znaleziony, wyjdž
if (NextClosestNode == m_iTarget) return;
// teraz, aby przetestowaæ wszystkie krawędzie doģączone do tego węzģa
graph_type::ConstEdgeIterator ConstEdgeItr(m_Graph, NextClosestNode);
for (const Edge* pE=ConstEdgeItr.begin();
!ConstEdgeItr.end();
pE=ConstEdgeItr.next())
{
// oblicz koszt heurystyczny od tego węzģa do celu (H)
double HCost = heuristic::Calculate(m_Graph, m_iTarget, pE->To());
// obliczyæ "rzeczywisty" koszt dla tego węzģa ze žródģa (G)
double GCost = m_GCosts[NextClosestNode] + pE->Cost();
// jeķli węzeģ nie zostaģ dodany do granicy, dodaj go i zaktualizuj
// koszty G i F.
if (m_SearchFrontier[pE->To()] == NULL)
{
m_FCosts[pE->T()] = GCost + HCost;
m_GCosts[pE->To()] = GCost;
pq.insert(pE->To());
m_SearchFrontier[pE->To()] = pE;
}
// jeķli ten węzeģ znajduje się juŋ na granicy, ale koszt dotarcia tutaj
// droga jest taņsza niŋ wczeķniej znaleziona, zaktualizuj koszty węzģa
// i odpowiednio granica
else if ((GCost < m_GCosts[pE->To()]) &&
(m_ShortestPathTree[pE->To()]==NULL))
{
m_FCosts[pE->To()] = GCost + HCost;
m_GCosts[pE->To()] = GCost;
pq.ChangePriority(pE->To());
m_SearchFrontier[pE->To()] = pE;
}
}
}
}
WSKAZÓWKA. Jeķli pracujesz ze ķcisģymi wymaganiami dotyczącymi pamięci, moŋesz ograniczyæ iloķæ pamięci uŋywanej przez A * lub wyszukiwanie Dijkstry, ograniczając liczbę węzģów umieszczonych w kolejce priorytetowej. Innymi sģowy, tylko n najlepszych węzģów jest przechowywanych w kolejce. To staģo się znane jako wyszukiwanie wiązki.
Heurystyka na dystansie na Manhattanie
Widziaģeķ, jak moŋna uŋyæ klasy algorytmu wyszukiwania A* w heurystyce euklidesowej (odlegģoķæ w linii prostej). Inną funkcją heurystyczną popularną wķród programistów gier, które mają tabele graficzne z topologią podobną do siatki, takich jak gry wojenne oparte na kafelkach, jest odlegģoķæ Manhattanu między dwoma węzģami: suma przesunięcia w kafelkach w pionie i poziomie. Na przykģad odlegģoķæ Manhattanu między węzģami na rysunku wynosi 10 (6 + 4).
Odlegģoķæ Manhattanu daje wzrost prędkoķci w stosunku do heurystyki euklidesowej, poniewaŋ do obliczeņ nie jest wymagany pierwiastek kwadratowy
Podsumowanie<
Powinieneķ teraz dobrze rozumieæ wykresy i algorytmy, których moŋesz uŋyæ do ich przeszukiwania. Podobnie jak w przypadku większoķci technik sztucznej inteligencji, twoje zrozumienie ogromnie wzroķnie dzięki praktycznemu doķwiadczeniu, dlatego zachęcam do podjęcia przynajmniej niektórych z poniŋszych problemów.
Praktyka czyni mistrza
1. Za pomocą oģówka i papieru przeķledž algorytm DFS, BFS i Dijkstry dla poniŋszego wykresu. Dla kaŋdego wyszukiwania uŋyj innego węzģa początkowego i koņcowego. Dodatkowe punkty zostaną przyznane za uŋycie stylu i koloru.
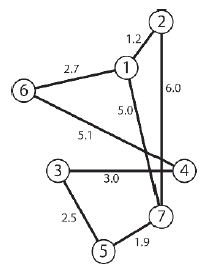
2. Utwórz heurystyczną klasę polityki odlegģoķci Manhattan, aby oszacowaæ odlegģoķæ między węzģem a celem na wykresie nawigacyjnym. Spróbuj heurystyki z róŋnymi wykresami. Czy jest lepsza czy gorsza niŋ heurystyka euklidesowa dla grafów opartych na siatce?
3. Euklidesowa heurystyka oblicza odlegģoķæ w linii prostej między węzģami. Obliczenia te wymagają uŋycia pierwiastka kwadratowego. Utwórz heurystykę, która dziaģa w przestrzeni z kwadratem odlegģoķci i zwróæ uwagę na ksztaģt tworzonych ķcieŋek.
4. Utwórz program, aby znaležæ najlepsze rozwiązanie dla wieŋ typu n-disk. Ukģadanka Hanoi, w której n moŋe byæ dowolną liczbą caģkowitą dodatnią. Aby to zrobiæ, musisz przepisz algorytm BFS, aby węzģy i krawędzie zostaģy dodane do pliku wykres stanu w trakcie wyszukiwania. To doskonaģy sposób na przetestowanie twoje zrozumienie materiaģu przedstawionego w tej częķci
5. Teraz zmodyfikuj algorytm utworzony w 4, aby wyszukaæ najlepsze rozwiązanie za pomocą iteracyjnego pogģębiania DFS. Jak to się porównuje?
6. Uŋyj algorytmu A*, aby rozwiązaæ potasowaną Kostkę Rubika. Duŋo uwagi poķwięæ zaprojektowaniu funkcji heurystycznej. Jest to trudny problem, szukając potencjalnie ogromnej przestrzeni wyszukiwania, więc najpierw wypróbuj swój algorytm na szeķcianie oddalonej tylko o jeden obrót od rozwiązania, a następnie o dwa itd.