Wprowadzenie
KROK 1
Wprowadzenie do Big Data Analytics
CO TO JEST BIG DATA?
Big Data to dowolna duŋa iloķæ danych ustrukturyzowanych, częķciowo ustrukturyzowanych i nieustrukturyzowanych, które mogą zostaæ wydobyte w celu uzyskania informacji, w których indywidualne rekordy przestają mieæ znaczenie i tylko agregują je. Dane stają się Big Data, gdy przetwarzanie ich przy uŋyciu tradycyjnych technik jest trudne.
CHARAKTERYSTYKA BIG DATA:
Istnieje wiele cech Big Data. Omówmy kilka tutaj.
1. Objętoķæ: duŋe zbiory danych oznaczają ogromne iloķci danych generowanych przez czujniki, maszyny poģączone z eksplozją internetu, media spoģecznoķciowe, handel elektroniczny, urządzenia GPS itp.
2. Prędkoķæ: implikuje szybkoķæ, z jaką napģywają dane, tak jak uŋytkownicy Facebooka generują 3 miliony polubieņ dziennie, a uŋytkownicy tworzą okoģo 450 milionów tweetów dziennie.
3. Róŋnorodnoķæ: sugeruje rodzaj formatów i moŋna je podzieliæ na 3 typy:
- Strukturalne - RDBMS, takie jak Oracle, MySQL, starsze systemy, takie jak Excel, Access
- Póģustrukturyzowane - e-maile, tweety, pliki dziennika, opinie uŋytkowników
- Nieustrukturyzowane - zdjęcia, wideo, pliki audio.
4. Wiarygodnoķæ: Odnosi się do stronniczoķci, szumu i nieprawidģowoķci w danych. Jeķli chcemy uzyskaæ znaczący wgląd w te dane, musimy je wstępnie oczyķciæ.
5. Waŋnoķæ: Odnosi się do adekwatnoķci i precyzji danych, poniewaŋ waŋnoķæ danych jest bardzo waŋna przy podejmowaniu decyzji.
6. Zmiennoķæ: Odnosi się do tego, jak dģugo dane są waŋne, poniewaŋ dane, które są obecnie aktualne, mogą nie byæ waŋne zaledwie kilka minut lub dni póžniej.
DLACZEGO BIG DATA JEST WAŊNE?
Sukces organizacji polega nie tylko na tym, jak dobrze radzi sobie w prowadzeniu dziaģalnoķci, ale takŋe na tym, jak dobrze moŋe analizowaæ swoje dane i uzyskiwaæ wgląd w swoją firmę, konkurentów itp. Duŋe zbiory danych mogą pomóc ci w podjęciu wģaķciwej decyzji we wģaķciwej decyzji czas. Dlaczego nie RDBMS? Skalowalnoķæ jest gģównym problemem w RDBMS, bardzo trudno jest zarządzaæ RDBMS, gdy zmieniają się wymagania lub liczba uŋytkowników. Kolejny problem z RDBMS polega na tym, ŋe musimy zdecydowaæ o strukturze bazy danych na początku, a póžniejsze wprowadzanie jakichkolwiek zmian moŋe byæ ogromnym zadaniem. W przypadku duŋych zbiorów danych potrzebujemy elastycznoķci i niestety RDBMS nie moŋe tego zapewniæ.
TERMINOLOGIA ANALITYCZNA
Analityka to jedno z niewielu pól, w którym wiele róŋnych terminów jest rozpowszechnianych przez wszystkich i wiele z nich brzmi podobnie, ale są one uŋywane w róŋnych kontekstach. Niektóre terminy brzmią bardzo odmiennie, ale są podobne i moŋna je stosowaæ zamiennie. Ktoķ, kto nie zna się na Analityce, spodziewaģ się pomyliæ z bogactwem terminologii dostępnej w tej dziedzinie. Analityka to proces dzielenia problemu na prostsze częķci i korzystania z wnioskowania na podstawie danych w celu podejmowania decyzji. Analityka nie jest narzędziem ani technologią, a raczej sposobem myķlenia i dziaģania. Business Analytics okreķla zastosowanie Analityki w sferze biznesu. Obejmuje analizę marketingową, analizę ryzyka, analizę oszustw, analizę CRM, analizę lojalnoķci, analizę operacji, a takŋe analizę HR. W ramach dziaģalnoķci Analityka jest wykorzystywana we wszystkich branŋach, takich jak analityka finansowa, analityka zdrowotna, analityka detaliczna, analityka telekomunikacyjna, analityka internetowa. Analityka predykcyjna zyskaģa na popularnoķci w ostatnich latach vs. retrospektywna natura, taka jak OLAP i BI, Analiza opisowa polega na opisywaniu lub eksploracji dowolnego rodzaju danych. Eksploracja i przygotowanie danych jest niezbędne, aby w duŋym stopniu polegaæ na analizie opisowej. Big Data Analytics to nowy termin uŋywany do analizy nieustrukturyzowanych danych i duŋych danych, takich jak terabajty, a nawet petabajty danych. Big Data to dowolny zestaw danych które nie mogą byæ analizowane za pomocą konwencjonalnych narzędzi.
RODZAJE ANALITYKI
Analitykę moŋna zastosowaæ do tak wielu problemów i w wielu róŋnych branŋach, ŋe waŋne jest, aby poķwięciæ trochę czasu na zrozumienie zakresu analiz w biznesie. Przyjrzymy się bliŋej 3 szerokim klasyfikacjom analitycznym: 1. W oparciu o branŋę. 2. W oparciu o funkcję biznesową. 3. W oparciu o rodzaj oferowanych spostrzeŋeņ. Zacznijmy od spojrzenia na branŋe, w których wykorzystanie analizy jest bardzo powszechne. Istnieją pewne branŋe, które zawsze tworzyģy ogromną iloķæ danych, takie jak karty kredytowe i towary konsumpcyjne. Branŋe te byģy jednymi z pierwszych, które wprowadziģy analizy. Analityka jest często klasyfikowana na podstawie branŋy, do której jest stosowana, dlatego usģyszysz takie terminy, jak analizy ubezpieczeniowe, analizy detaliczne, analityka internetowa i tak dalej. Moŋemy nawet sklasyfikowaæ analitykę na podstawie funkcji biznesowej, w której jest uŋywana. Klasyfikacja analityki na podstawie funkcji biznesowej i wpģywu wygląda następująco:
- Analityka marketingowa
- Analizy sprzedaŋy i HR
- Analizy ģaņcucha dostaw i tak dalej
Moŋe to byæ doķæ dģuga lista, poniewaŋ analiza ma wpģyw na praktycznie kaŋdą dziaģalnoķæ biznesową w duŋej organizacji. Ale najbardziej popularny sposób klasyfikowania analiz opiera się na tym, co pozwala nam to zrobiæ. Wszystkie informacje są gromadzone dla róŋnych branŋ i róŋnych dziaģów. Wszystko, co musimy zrobiæ, to kroiæ i kroiæ dane na róŋne sposoby, byæ moŋe patrząc na nie pod róŋnymi kątami lub wzdģuŋ róŋnych wymiarów itp. Jak widaæ analiza opisowa jest prawdopodobnie najprostszym rodzajem analizy, poniewaŋ wykorzystuje istniejące informacje z przeszģoķci, aby zrozumieæ decyzje w teražniejszoķci i miejmy nadzieję, ŋe pomoŋe zdecydowaæ o skutecznym žródle dziaģania w przyszģoķci. Jednak ze względu na względną ģatwoķæ zrozumienia i opisową analizę analityczną często uwaŋano za stonowanego bližniaka analityki. Ale jest równieŋ niezwykle potęŋna pod względem potencjaģu i w większoķci sytuacji biznesowych, analiza opisowa moŋe pomóc rozwiązaæ większoķæ problemów. Detaliķci są bardzo zainteresowani zrozumieniem relacji między produktami. Chcą wiedzieæ, czy dana osoba kupuje produkt A, czy prawdopodobnie kupuje równieŋ produkt B lub produkt C. Nazywa się to analizą powinowactwa produktu lub analizą skojarzeņ i jest powszechnie stosowane w branŋy detalicznej. Nazywa się to równieŋ analizą koszyka rynkowego i jest uŋywane w odniesieniu do zestawu technik, które moŋna zastosowaæ do analizy koszyka zakupów lub transakcji. Czy zastanawiaģeķ się kiedyķ, dlaczego mleko jest umieszczane z tyģu sklepu, a magazyny i guma do ŋucia znajdują się przy kasie? Wynika to z faktu, ŋe za poķrednictwem detalistów analitycznych zdajesz sobie sprawę, ŋe podczas podróŋy na tyģ sklepu, aby odebraæ niezbędne rzeczy, moŋesz po prostu pokusiæ się o coķ innego, a takŋe dlatego, ŋe czasopisma i guma do ŋucia są tanimi zakupami impulsowymi. Postanawiasz wrzuciæ je do koszyka, poniewaŋ nie są zbyt drogie i prawdopodobnie patrzyģeķ na nie, czekając w kolejce przy kasie. Analiza predykcyjna dziaģa poprzez identyfikację wzorców i danych historycznych, a następnie uŋycie statystyki, aby wyciągaæ wnioski na temat przyszģoķci. Na bardzo uproszczonym poziomie staramy się dopasowaæ dane do okreķlonego wzorca, a jeķli uwaŋamy, ŋe dane są zgodne z okreķlonym wzorcem, moŋemy przewidzieæ, co stanie się w przyszģoķci. Spójrzmy na inny przykģad dotyczący analizy predykcyjnej w branŋy telekomunikacyjnej. Duŋa firma telekomunikacyjna ma dostęp do wszelkiego rodzaju informacji o nawykach telefonicznych klienta:
- Ile czasu spędzają na telefonie?
-Ile poģączeņ międzynarodowych wykonują?
- Czy wolą numery SMS lub poģączenia poza swoim miastem?
Jest to informacja, którą moŋna uzyskaæ wyģącznie poprzez obserwację lub analizę opisową. Ale takie firmy, co waŋniejsze, chciaģyby wiedzieæ, którzy klienci planują odejķæ i nawiązaæ nowe poģączenie ze swoimi konkurentami. Wykorzysta tu informacje historyczne, ale w celu uzyskania wyników wykorzysta modelowanie i analizę predykcyjną. To jest analiza predykcyjna. Chociaŋ analiza opisowa jest bardzo potęŋnym narzędziem nadal daje nam informacje tylko o przeszģoķci, podczas gdy w rzeczywistoķci gģówną troską większoķci uŋytkowników zawsze będzie przyszģoķæ. Wģaķciciel hotelu chciaģby przewidzieæ, ile jego pokoi będzie zajmowanych w przyszģym tygodniu. Dyrektor generalny firmy Pharma będzie chciaģ wiedzieæ, który z jego testowanych leków najprawdopodobniej odniesie sukces. W tym przypadku analizy predykcyjne są o wiele bardziej przydatne. Oprócz tych narzędzi istnieje trzeci rodzaj analiz, który powstaģ bardzo niedawno, byæ moŋe zaledwie dziesięæ lat temu. Nazywa się to analizą nakazową. Analizy preskryptywne wykraczają poza analitykę predykcyjną, mówiąc nie tylko o tym, co się dzieje, ale takŋe o tym, co moŋe się wydarzyæ, a co najwaŋniejsze, co z tym zrobiæ. Moŋe równieŋ informowaæ o wpģywie tych decyzji, co sprawia, ŋe analiza nakazowa jest tak nowoczesna. Domeny biznesowe, które są ķwietnymi przykģadami, w których moŋna zastosowaæ nakazową analizę, to przemysģ lotniczy lub ogólnokrajowe sieci drogowe. Preskryptywne analizy mogą przewidzieæ skutecznie korygujące wąskie gardģa na drogach lub zidentyfikowaæ drogi, na których moŋna wprowadziæ opģaty za przejazd w celu usprawnienia ruchu. Aby zobaczyæ, jak funkcjonuje analiza nakazowa w branŋy lotniczej, spójrzmy na następujący przykģad. Linie lotnicze zawsze szukają sposobów na optymalizację swoich tras w celu uzyskania maksymalnej wydajnoķci. Mogą to byæ miliardy dolarów oszczędnoķci, ale nie jest to takie ģatwe. Przy ponad 50 milionach lotów komercyjnych na ķwiecie co roku, jest to lot co sekundę. Prosta trasa lotu między dwoma miastami, powiedzmy, San Francisco i Bostonem, ma 2000 opcji trasy. Dlatego branŋa lotnicza często polega na nakazowej analizie, która decyduje o tym, co, kto i jak powinien lataæ samolotem, aby obniŋyæ koszty i zyski. Przyjrzeliķmy się zatem doķæ dogģębnej analizie opisowej, predykcyjnej i nakazowej. Celem tego kursu będzie analiza opisowa. Pod koniec poķwięcimy trochę czasu na zrozumienie niektórych bardziej popularnych technik modelowania predykcyjnego.
CYKL ŊYCIA ANALITYKI
Cykl ŋycia Analityki ma róŋne etapy i wiele osób opisuje go na wiele sposobów, ale ogólny pomysģ pozostaje taki sam. Rozwaŋmy następujące etapy cyklu ŋycia projektu Analityki.
- Identyfikacja problemu
- Formuģowanie hipotez
- Zbieranie danych
- Eksploracja danych
- Przygotowanie danych / manipulacja
- Planowanie modelu / budowanie
- Sprawdenie poprawnoķci modelu
- Oceņ / Monitoruj wyniki
1. Identyfikacja problemu: Problem to sytuacja, która jest oceniana jako coķ, co wymaga naprawy. Naszym zadaniem jest upewnienie się, ŋe rozwiązujemy odpowiedni problem, moŋe nie byæ to ten przedstawiony nam przez klienta. Co naprawdę musimy rozwiązaæ? Czasami stwierdzenia problemów, które otrzymujemy od firmy, są bardzo proste.
Na przykģad:
- Jak zidentyfikowaæ najcenniejszych klientów?
- W jaki sposób mogę zminimalizowaæ straty wynikające z braku dostępnoķci produktu na póģce?
- Jak zoptymalizowaæ mój ekwipunek?
- Jak wykryæ klientów, którzy prawdopodobnie nie wykonają pģatnoķci rachunków?
Są to proste stwierdzenia problemów i naprawdę nie ma wątpliwoķci co do tego, co próbujemy osiągnąæ dzięki projektowi analitycznemu. Jednak za kaŋdym razem nasze oķwiadczenie biznesowe moŋe nie prowadziæ do jednoznacznej identyfikacji problemu. Czasami oķwiadczenia biznesowe są na bardzo wysokim poziomie, dlatego będziesz musiaģ spędziæ czas z firmą, aby zrozumieæ potrzeby i uzyskaæ kontekst. Konieczne moŋe byæ podzielenie tego problemu na podproblemy w celu zidentyfikowania krytycznych wymagaņ. Byæ moŋe trzeba pomyķleæ o ograniczeniach, które naleŋy uwzględniæ w rozwiązaniu. Przypuķæmy, ŋe pracujesz dla firmy obsģugującej karty kredytowe, a firma mówi ci, ŋe jest problem, na który chcą spojrzeæ, a mianowicie: "Chcemy otrzymywaæ wnioski o kartę kredytową tylko od dobrych klientów" . Teraz z perspektywy biznesowej, czy jest to prawidģowe oķwiadczenie biznesowe? Z pewnoķcią na bardzo wysokim poziomie jest to waŋny wymóg biznesowy. Czy jednak dla twojego celu, jakim jest zbudowanie rozwiązania mającego na celu rozwiązanie tego pytania, jest to bardzo waŋne stwierdzenie, czy wystarczający punkt wyjķcia do analizy danych? Nie. Poniewaŋ z takim oķwiadczeniem biznesowym jest wiele problemów. Co to znaczy, ŋe chcemy otrzymywaæ wnioski o kartę kredytową tylko od dobrych klientów? Spójrzmy na problem z tym stwierdzeniem problemu. Chcę otrzymywaæ wnioski o kredyt wyģącznie od dobrych klientów. Jednym z najbardziej oczywistych problemów związanych z tym stwierdzeniem jest to, kim są dobrzy klienci? Jeķli masz wiedzę na temat branŋy kart kredytowych, jedną z odpowiedzi dla dobrego klienta mogą byæ ludzie, którzy nie zwlekają z pģatnoķciami. Oznacza to, ŋe wydajesz na kartę kredytową i spģacasz jej kartę kredytową na czas. Jednak inną definicją dobrego klienta mogą byæ ludzie, którzy nie pģacą na czas. Dlaczego? Poniewaŋ jeķli nie zapģacisz na czas, wystawca karty kredytowej moŋe obciąŋyæ Cię wysokimi stopami procentowymi od tego salda na karcie kredytowej. Tego rodzaju klienci nazywani są rewolwerami. Kto naprawdę jest dobrym klientem dla firmy wydającej karty kredytowe? Czy ci klienci pģacą na czas? Czy są to klienci, którzy nie wywiązują się ze zobowiązaņ i nie pģacą na czas. Odpowiedž moŋe byæ taka ,ŋe obaj są dobrymi klientami. Jak to moŋliwe? To zaleŋy od twojej perspektywy. Jeķli chcesz zminimalizowaæ ryzyko, jeķli pracujesz w dziale ryzyka firmy wydającej karty kredytowe, Twoją definicją dobrego klienta są klienci, którzy pģacą na czas, klienci, którzy wywiązują się ze zobowiązaņ. Jeķli natomiast patrzysz na przychody, to dobrym pomysģem na dobrego klienta mogą byæ ludzie, którzy duŋo wydają na kartę kredytową i nie zwracają jej caģej. Mają wysoką równowagę obrotową. Teraz, jako analityk, kto decyduje, kim są dobrzy klienci? Gdy wystawca karty kredytowej wyda Ci wyciąg biznesowy, który mówi, ŋe chcemy przyjąæ wniosek o kartę kredytową tylko od dobrych klientów. Czy wiesz, ŋe szukają ryzyka lub przychodów? To naprawdę zaleŋy od interesów biznesowych; zaleŋy to od celów biznesowych na ten rok. W rzeczywistoķci dobry klient w tym roku moŋe byæ zģym klientem w przyszģym roku. Dlatego waŋne jest, aby uzyskaæ kontekst lub opis problemu przed rozpoczęciem analizy. Ale to nie jedyny problem z tym opisem problemu. Innym problemem jest zastanowienie się nad decyzją: czy naprawdę moŋesz nalegaæ na otrzymywanie dobrych aplikacji lub czy moŋesz nalegaæ na zatwierdzanie dobrych aplikacji. Czy decyzja jest na etapie skģadania wniosku lub zatwierdzania? Czy naprawdę moŋesz kontrolowaæ aplikacje, aby byģy dobre, czy moŋesz kontrolowaæ decyzje, aby umoŋliwiæ dostęp do ciebie tylko dobrym klientom?. Innym problemem związanym z tym opisem problemu jest to, ŋe chcemy otrzymywaæ wnioski o karty kredytowe tylko od dobrych klientów. Czy realistyczne jest zakģadanie, ŋe będziesz mieæ rozwiązanie, które nigdy nie przyjmie zģego klienta?
Ponownie, nie jest to realistyczny wynik. Wracając do naszego stanu definicji problemu, którym jest problem biznesowy, chcę uzyskaæ dobrych klientów jako wystawca kart kredytowych. Jak przeksztaģciæ ten problem w coķ, co moŋe rozwiązaæ podejķcie analityczne? Jednym ze sposobów jest dodanie szczegóģów do opisu problemu. Pomyķl więc o konkretnych, wymiernych, osiągalnych, realistycznych i terminowych wynikach, które moŋesz doģączyæ do tego opisu problemu. Dlatego podkreķlamy, ŋe musisz dokģadnie zrozumieæ kontekst biznesowy i porozmawiaæ czy masz do czynienia z wģaķciwym problemem. Jak mogę dodaæ szczegóģy do tego problemu? Zaģóŋmy, ŋe patrzę na to z perspektywy ryzyka, poniewaŋ w tym roku moje firmy wydające karty kredytowe skupiģy się na zmniejszeniu ryzyka portfela. Mógģbym mieæ róŋne oķwiadczenia o problemach biznesowych. Na przykģad zmniejsz straty z domyķlnej karta kredytowa o co najmniej 30 procent w ciągu pierwszych 12 miesięcy po wdroŋeniu nowej strategii. Opracuj algorytm do sprawdzania aplikacji, które nie speģniają kryteriów okreķlonych przez klienta, co zmniejszy domyķlne wartoķci o 20 procent w ciągu najbliŋszych 3 miesięcy. Zidentyfikuj strategie ograniczenia domyķlnych zobowiązaņ o 20 procent w ciągu najbliŋszych trzech miesięcy, umoŋliwiając zagroŋonym klientom dodatkowe opcje pģatnoķci. Zdecydowaliķmy, ŋe dobrą definicją problemu zajmujemy się z perspektywy ryzyka. Ale w przypadku tego samego oķwiadczenia biznesowego mamy teraz trzy róŋne oķwiadczenia dotyczące problemów, które dotyczą trzech róŋnych rzeczy. Znowu, który z nich powinienem wybraæ jako punkt wyjķcia do mojej analizy? Czy powinienem identyfikowaæ strategie dla moich obecnych klientów, czy powinienem szukaæ potencjalnych nowych klientów? Ponownie jest to coķ, co moŋe wynikaæ z potrzeb biznesowych. Dlatego waŋne jest, aby stale rozmawiaæ z biznesem, aby upewniæ się, ŋe rozpoczynając projekt analityczny, rozwiązujesz wģaķciwe stwierdzenie problemu. Dotarcie do jasno zdefiniowanego problemu jest często oparte na odkryciach - zacznij od definicji pojęciowej, a poprzez analizę (pierwotną przyczynę, analizę wpģywu itp. ksztaģtujesz i redefiniujesz problem pod względem zagadnieņ. Problem staje się znany, gdy dana osoba widzi rozbieŋnoķæ między tym, jakie rzeczy są i tym, jakie powinny byæ. Problemy mogą byæ zidentyfikowane przez:
- Badania porównawcze / porównanie
- Raportowanie wyników - ocena bieŋących wyników w stosunku do celów i zaģoŋeņ
- Analiza SWOT - ocena mocnych stron, sģaboķci, szans i zagroŋeņ
- Skargi / ankiety
Czasami to, co uwaŋamy za problem, nie jest prawdziwym problemem, więc aby dojķæ do prawdziwego problemu, konieczne jest sondowanie. Analiza przyczyn pierwotnych jest skuteczną metodą sondowania - pomaga zidentyfikowaæ, co, jak i dlaczego coķ się wydarzyģo. Rozwaŋmy wzrost rotacji pracowników w naszej organizacji. Musimy dowiedzieæ się czemu Pięæ Razy Dlaczego odnosi się do praktyki pytania pięæ razy, dlaczego problem istnieje, aby dotrzeæ do jego pierwotnej przyczyny:
- Dlaczego pracownicy wyjeŋdŋają do innej pracy?
- Dlaczego pracownicy nie są zadowoleni?
- Dlaczego pracownicy uwaŋają, ŋe są niedopģacani?
- Dlaczego inni pracodawcy pģacą wyŋsze pensje?
- Dlaczego popyt na takich pracowników wzrósģ na rynku?
Podstawowe pytania do zdefiniowania problemu:
- Kto powoduje problem?
- Kogo dotyczy ten problem?
- Co się stanie, jeķli ten problem nie zostanie rozwiązany? Jakie są skutki?
- Gdzie i kiedy występuje ten problem?
- Dlaczego występuje ten problem?
- Jak powinien dziaģaæ proces?
- Jak ludzie obecnie radzą sobie z problemem?
2. Formuģowanie hipotezy: Rozbij problemy i formuģuj hipotezy. Okreķl ramy pytaņ, na które naleŋy odpowiedzieæ, lub tematów, które naleŋy zbadaæ, aby rozwiązaæ problem.
- Opracuj kompleksową listę wszystkich moŋliwych problemów związanych z problemem
- Ogranicz obszerną listę, eliminując duplikaty i ģącząc nakģadające się problemy
- Korzystając z budowania konsensusu, przejdž do listy gģównych problemów.
3. Zbieranie danych: Aby odpowiedzieæ na kluczowe pytania i zweryfikowaæ hipotezy, konieczne jest zebranie realistycznych informacji. W zaleŋnoķci od rodzaju rozwiązywanego problemu moŋna zastosowaæ róŋne techniki gromadzenia danych. Zbieranie danych jest kluczowym etapem rozwiązywania problemów - jeķli jest powierzchowne, stronnicze lub niekompletne, analiza danych będzie trudna.
Techniki zbierania danych:
- Korzystanie z danych, które zostaģy juŋ zebrane przez innych
- Systematycznie wybieraj i obserwuj cechy ludzi, przedmiotów lub wydarzeņ.
- Ustne pytania respondentów, indywidualnie lub w grupie.
- Zbieranie danych na podstawie odpowiedzi udzielonych przez respondentów w formie pisemnej.
- Uģatwienie bezpģatnych dyskusji na wybrane tematy z wybraną grupą uczestników.
4. Eksploracja danych: Przed przeprowadzeniem formalnej analizy danych analityk musi wiedzieæ, ile przypadków znajduje się w zbiorze danych, jakie zmienne są uwzględnione, ile jest brakujących obserwacji i jakie ogólne hipotezy dane mogą wesprzeæ. Wstępna eksploracja zestawu danych pomaga odpowiedzieæ na te pytania, zapoznając analityków z danymi, z którymi pracują. Analitycy często uŋywają wizualizacji do eksploracji danych, poniewaŋ umoŋliwia ona uŋytkownikom szybkie i proste przeglądanie większoķci istotnych funkcji ich zbioru danych. W ten sposób uŋytkownicy mogą zidentyfikowaæ zmienne, które mogą mieæ interesujące obserwacje. Wyķwietlając dane graficznie za pomocą wykresów rozrzutu lub wykresów sģupkowych, uŋytkownicy mogą sprawdziæ, czy dwie lub więcej zmiennych koreluje i ustaliæ, czy są dobrymi kandydatami do dalszej szczegóģowej analizy.
5. Przygotowanie danych: Dane przychodzą do Ciebie w formie, która nie jest ģatwa do analizy. Musimy wyczyķciæ dane i sprawdziæ ich spójnoķæ, konieczna jest obszerna manipulacja danymi w celu ich analizy.
Etapy przygotowania danych mogą obejmowaæ:
- Importowanie danych
- Identyfikacja zmiennych / Tworzenie nowych zmiennych
- Sprawdzanie i podsumowywanie danych
- Wybieranie podzbiorów danych
- Wybieranie zmiennych i zarządzanie nimi.
- Ģączenie danych
- Dzielenie danych na wiele zestawów danych.
- Leczenie brakujących wartoķci
- Leczenie odstępne
Identyfikacja zmiennych: Najpierw zidentyfikuj zmienne predykcyjne (wejķciowe) i docelowe (wyjķciowe). Następnie okreķl typ danych i kategorię zmiennych.
Analiza jednoczynnikowa: Na tym etapie badamy zmienne jeden po drugim. Metoda przeprowadzania analizy jednoczynnikowej będzie zaleŋeæ od tego, czy typ zmiennej jest kategoryczny czy ciągģy. Przyjrzyjmy się tym metodom i miarom statystycznym indywidualnie dla zmiennych jakoķciowych i ciągģych.
Ciągģe zmienne: W przypadku zmiennych ciągģych musimy zrozumieæ centralną tendencję i rozprzestrzenianie się zmiennej. Są one mierzone przy uŋyciu róŋnych metod wizualizacji metryk statystycznych.
Zmienne jakoķciowe: W przypadku zmiennych jakoķciowych uŋywamy tabeli częstotliwoķci, aby zrozumieæ rozkģad kaŋdej kategorii. Moŋemy równieŋ odczytaæ jako procent wartoķci w kaŋdej kategorii. Moŋna to zmierzyæ za pomocą dwóch wskažników, liczby i procentu dla kaŋdej kategorii.
6. Budowanie modelu: To tak naprawdę caģy proces budowania rozwiązania i wdraŋania rozwiązania. Większoķæ czasu poķwięconego na projekt spędza się na etapie wdraŋania rozwiązania. Jedną z interesujących rzeczy, o których naleŋy pamiętaæ przy podejķciu analitycznym, jest to, ŋe podejķcie analityczne podczas budowania modeli, modeli analitycznych, jest procesem bardzo iteracyjnym, poniewaŋ nie ma czegoķ takiego jak ostateczne rozwiązanie lub idealne rozwiązanie. Zazwyczaj poķwięcasz czas na budowanie wielu modeli na wielu rozwiązaniach, zanim znajdziesz najlepsze rozwiązanie, z którym firma będzie wspóģpracowaæ.
7. Istnieje wiele sposobów podejmowania decyzji z perspektywy biznesowej. Analityka to jeden sposób. Istnieją inne sposoby podjęcia decyzji. Moŋe to byæ podejmowanie decyzji opartych na doķwiadczeniu. Moŋe to byæ proces decyzyjny oparty na przeszukaniu. I nie za kaŋdym razem zawsze wybierzesz podejķcie analityczne. Jednak na dģuŋszą metę sensowne jest budowanie zdolnoķci analitycznych, poniewaŋ prowadzi to do bardziej obiektywnego podejmowania decyzji. Ale zasadniczo, jeķli chcesz danych, aby przyspieszyæ podejmowanie decyzji, musisz upewniæ się, ŋe zainwestowaģeķ w gromadzenie odpowiednich danych, aby umoŋliwiæ Ci podejmowanie decyzji na podstawie danych
8. Ocena / monitorowanie modelu: Jest to ciągģy proces mający na celu przede wszystkim sprawdzenie skutecznoķci rozwiązania w czasie. Pamiętaj, ŋe analityczne podejķcie do rozwiązywania problemów róŋni się od standardowego podejķcia do rozwiązywania problemów. Musimy pamiętaæ o tych punktach:
- Dane mają wyražną pewnoķæ co do identyfikacji rozwiązania.
- Uŋywamy technik analitycznych opartych na teoriach numerycznych.
- Musisz dobrze zrozumieæ teoretyczne koncepcje sytuacji biznesowych, aby stworzyæ realne rozwiązanie.
Oznacza to, ŋe potrzebujesz dobrego zrozumienia sytuacji biznesowej i kontekstu biznesowego, a takŋe silnej wiedzy na temat podejķæ analitycznych i umieæ ģączyæ koncepcje, znaležæ praktyczne rozwiązanie. W niektórych branŋach tempo zmian jest bardzo wysokie. Rozwiązania starzeją się więc bardzo szybko. W innych branŋach tempo zmian moŋe nie byæ tak wysokie, a kiedy zbudujesz rozwiązanie, moŋesz mieæ rozwiązanie na 2-3 lata, które będzie dziaģaæ, ale trzeba będzie dostosowaæ, aby zarządzaæ nowymi warunkami biznesowymi. Jednak sposobem oceny, czy Twoje rozwiązanie dziaģa, jest okresowe sprawdzanie skutecznoķci rozwiązania. Konieczne jest ķledzenie niezawodnoķci w czasie i moŋe byæ konieczne wprowadzenie niewielkich zmian, aby przywróciæ rozwiązanie na wģaķciwe tory. Czasami moŋe byæ konieczne zbudowanie caģego rozwiązania od zera, poniewaŋ ķrodowisko zmieniģo się tak drastycznie, ŋe zbudowane rozwiązanie nie ģączy się juŋ w obecnym kontekķcie biznesowym
WSPÓLNE BĢĘDY W ANALITYCZNYM MYĶLENIU
Definicja problemu przez klienta moŋe byæ niepoprawna. Moŋe mu brakowaæ wiedzy i doķwiadczenia, które posiadasz. Poniewaŋ większoķæ problemów nie jest unikalna, moŋemy potwierdziæ problem i moŋliwe rozwiązania w stosunku do innych žródeģ. Najlepsze rozwiązania problemu są często zbyt trudne do wdroŋenia przez klienta. Zachowaj więc ostroŋnoķæ w zalecaniu optymalnego rozwiązania problemu. Większoķæ wyjaķnieņ wymaga pewnego stopnia ugody w celu wykonania.
KROK 2
Rozpoczęcie pracy z R
WPROWADZENIE
R jest językiem programowania do analizy statystycznej i raportowania. R jest prostym językiem programowania, który zawiera wiele funkcji do analizy danych, ma efektywne narzędzie do obsģugi i przechowywania danych. R zapewnia graficzne moŋliwoķci analizy danych i raportowania. Proszę o zainstalowanie R and R studio, które moŋna bezpģatnie pobraæ.
Kiedy po raz pierwszy otworzysz Studio R, zobaczysz cztery okna.
1. Skrypty: Sģuŋy jako obszar do pisania i zapisywania kodu R.
2. Obszar roboczy: Wyķwietla zestaw danych i zmienne w ķrodowisku R.
3. Wykresy: Wyķwietla wykresy wygenerowane przez kod R.
4. Konsola : Zapewnia historię wykonanego kodu R i danych wyjķciowych
OPERACJE ELEMENTARNE W R
1. Wyraŋenia:
Jeķli pracujesz tylko z liczbami R moŋesz uŋyæ jako zaawansowanego kalkulatora, po prostu wpisz
4 + 5
i naciķnij enter, otrzymasz wartoķæ 9.
R moŋe wykonywaæ obliczenia matematyczne bez koniecznoķci przechowywania go w obiekcie. Wynik jest wydrukowany na konsoli. Spróbuj obliczyæ iloczyn 2 lub więcej liczb (* to operator mnoŋenia).
6 * 9 # otrzymasz 54.
Cokolwiek napisane po znaku # będzie uwaŋane za komentarz w R.
R stosuje się do reguģ BODMAS, aby wykonywaæ operacje matematyczne.
Wpisz następujące polecenia i zrozum róŋnicę.
20-15 * 2 # otrzymasz -10
(20-15) * 2 #uzyskasz 10
Uwaŋaj, aby oddzieliæ dowolną wartoķæ od 0, aby uzyskaæ inf (nieskoņczonoķæ).
wpisz to polecenie w konsoli i sprawdž
8/0
Te operacje matematyczne moŋna ģączyæ w dģugie formuģy, aby osiągnąæ okreķlone zadania.
2. Wartoķci logiczne:
Niewiele wyraŋeņ zwraca "wartoķæ logiczną": PRAWDA lub FAĢSZ. (znane jako wartoķci "boolowskie"). Spójrz na wyraŋenie, które daje nam logiczną wartoķæ:
6 < 9 # PRAWDA
3. Zmienne:
Moŋemy przechowywaæ wartoķci w zmiennej, aby uzyskaæ do niej dostęp póžniej.
X <- 48 # do przechowywania wartoķci w x.
Y <- "YL, Prasad" (nie zapomnij cudzysģowów)
Teraz X i Y są obiektami utworzonymi w R, mogą byæ uŋywane w wyraŋeniach w pozycji oryginalnego wyniku. Spróbuj wywoģaæ X i Y, wpisując nazwę obiektu
Y # [1] "YL, Prasad"
musimy pamiętaæ, ŋe R rozróŋnia maģe i wielkie litery.Jeķli przypiszesz wartoķæ do znaku X i wywoģasz maģe X, wyķwietli się bģąd. Spróbuj podzieliæ X przez 2 (/ jest operatorem dzielenia) # dostaniesz 24 jako odpowiedž Moŋemy ponownie przypisaæ dowolną wartoķæ do zmiennej w dowolnym momencie. Przypisz "Lakshmi" do Y.
Y <- "Lakshmi"
Moŋemy wyķwietliæ wartoķæ zmiennej po prostu wpisując jej nazwę w konsoli. Spróbuj wyķwietliæ bieŋącą wartoķæ Y. Jeķli napisaģeķ ten kod, gratulacje! Pierwszy kod napisaģeķ w R i stworzyģeķ obiekt.
4. Funkcje
Moŋemy wywoģaæ funkcję, wpisując jej nazwę, a następnie w nawiasie argumenty tej funkcji. Wypróbuj funkcję sumowania, aby dodaæ kilka liczb. Wchodziæ:
sum(1, 3, 5) # 9
Uŋywamy funkcji sqrt, aby uzyskaæ pierwiastek kwadratowy z 16.
sqrt(16) # 4
16^.5 # równieŋ daje taką samą odpowiedž jak 4
Pierwiastek kwadratowy jest najczęķciej stosowaną transformacją wraz z transformacją logów podczas przygotowywania danych. Wpisz następujące polecenia i sprawdž odpowiedzi
log(1) # 0
log(10) # 2.302585
log10(100) # to zwróci 2, poniewaŋ log 100 o podstawie 10 wynosi 2. W dowolnym momencie, jeķli chcesz uzyskaæ dostęp do okna pomocy, moŋesz wpisaæ następujące polecenia
help(exp)
? exp
Jeķli chcesz podaæ przykģad funkcji, podaj następujące polecenie:
example (log)
R pozwala zapisaæ ķrodowisko robocze, w tym zmienne i zaģadowane biblioteki, do pliku danych .R za pomocą funkcji save.image (). Istniejący plik danych .R moŋna zaģadowaæ za pomocą funkcji load.image ().
5. Pliki
Polecenia R moŋna zapisywaæ i przechowywaæ w plikach tekstowych (z rozszerzeniem ".R") w celu ich póžniejszego wykonania. Zaģóŋmy, ŋe zachowaliķmy kilka przykģadowych skryptów. Moŋemy wyķwietliæ listę plików w bieŋącym katalogu z poziomu R wywoģując funkcję list.files.
list.files ()
USTAWIANIE KATALOGU ROBOCZEGO
Przed zagģębieniem się w R zawsze lepiej jest skonfigurowaæ katalog roboczy do przechowywania wszystkich naszych plików, skalarów, wektorów, ramek danych itp. Po pierwsze, chcemy wiedzieæ, który katalog domyķlnie uŋywa R. aby to zrozumieæ, wpisz polecenie:
getwd () # [1] "C:/Users/admin/Documents"
Teraz chcę ustawiæ dane folderu R jako mój katalog roboczy, który znajduje się na dysku D. aby to zrobiæ, wydam polecenie:
setwd ("D:/ R Data")
Naciķnij Enter (kliknij przycisk Przeķlij ikonę), aby upewniæ się, ŋe polecenie zostaģo wykonane i katalog roboczy zostaģ ustawiony. Ustawiamy dane folderu R na dysku D jako katalog roboczy. Nie oznacza to, ŋe utworzyliķmy tutaj coķ nowego, ale wģaķnie przypisaliķmy miejsce jako katalog roboczy, tutaj zostaną dodane wszystkie pliki. Aby sprawdziæ, czy katalog roboczy zostaģ poprawnie skonfigurowany, wydaj polecenie:
getwd ()
STRUKTURY DANYCH W R
Struktura danych to interfejs do danych zorganizowanych w pamięci komputera. R zapewnia kilka rodzajów struktury danych, z których kaŋda ma na celu optymalizację niektórych aspektów przechowywania, dostępu lub przetwarzania. Przykģady struktur danych: 1. Wektor 2. Macierz 3. Czynnik 4. Ramka Danych
1. Wektory
Wektory są podstawowym elementem skģadowym danych w R. Zmienne R są w rzeczywistoķci wektorami. Wektor moŋe skģadaæ się tylko z wartoķci z tej samej klasy. Testy wektorów moŋna przeprowadziæ za pomocą funkcji is.vector(). Nazwa moŋe brzmieæ przeraŋająco, ale wektor to po prostu lista wartoķci. Wartoķciami wektorowymi mogą byæ liczby, ciągi znaków, wartoķci logiczne lub dowolny inny typ, o ile wszystkie są tego samego typu. Rodzaje wektorów: Caģkowity, Numeryczny, Logiczny, Znakowy, Zģoŋony. R zapewnia funkcjonalnoķæ, która umoŋliwia ģatwe tworzenie i manipulowanie wektorami. Poniŋszy kod R ilustruje sposób tworzenia wektora za pomocą funkcji ģączenia, c() lub operatora dwukropka:, Stwórzmy wektor liczb:
c(4,7,9)
Funkcja c (c jest skrótem od Combine) tworzy nowy wektor, ģącząc listę wartoķci. Utwórz wektor z ciągami znaków:
c("a", "b", "c")
Sekwencja wektorów
Moŋemy stworzyæ wektor z notacją początek : koniec, aby utworzyæ sekwencje. Zbudujmy wektor z sekwencji liczb caģkowitych od 5 do 9.
5:9 # Tworzy wektor o wartoķciach od 5 do 9
Moŋemy nawet wywoģaæ funkcję seq. Spróbujmy zrobiæ to samo z seq:
seq (5,9)
Dostęp do wektora
Po utworzeniu wektora z niektórymi ģaņcuchami i zapisaniu go, moŋemy odzyskaæ indywidualną wartoķæ w wektorze, podając jego indeks liczbowy w nawiasach kwadratowych.
sentence <- c('Learn', 'Data', 'Analytics')
sentence[3] # [1] "Analytics"
Moŋemy przypisaæ nowe wartoķci do istniejącego wektora. Spróbuj zmieniæ trzecie sģowo na "Science":
sentence [3] <- "Science"
Jeķli dodasz nowe wartoķci do wektora, wektor wzroķnie, aby je uwzględniæ. Dodajmy czwarte sģowo:
sentence [4] <- 'By YL, Prasad'
Moŋemy uŋyæ wektora w nawiasach kwadratowych, aby uzyskaæ dostęp do wielu wartoķci. Spróbuj uzyskaæ pierwsze i czwarte sģowo:
sentence [c(1, 4)]
Oznacza to, ŋe moŋesz pobraæ zakresy wartoķci. Uzyskaj od drugiego do czwartego sģowa:
sentence [2:4]
Moŋemy ustawiæ zakresy wartoķci, po prostu podając wartoķci w wektorze.
sentence [5:7] <- c('at', 'PRA', 'Analytix') #aby dodaæ sģowa od 5 do 7
Spróbuj uzyskaæ dostęp do siódmego sģowa wektora sentence:
sentence[7]
Nazwy wektorów
Stwórzmy 3-elementowy wektor i zapiszmy go w zmiennej rang. Moŋemy przypisywaæ nazwy do elementów wektora, przekazując drugi wektor wypeģniony nazwami do funkcji przypisywania nazw, w następujący sposób:
ranks <- 1:3
names(ranks) <- c("first", "second", "third")
ranks
Moŋemy uŋyæ tych nazw, aby uzyskaæ dostęp do wartoķci wektora.
ranks["first"]
Macierze
Macierz w R to zbiór jednorodnych elementów uģoŋonych w 2 wymiarach.
• Macierz jest wektorem z atrybutem dim, tj. wektorem liczb caģkowitych podającym liczbę lub wiersze i kolumny.
• Funkcje dim(), nrow() i ncol() zapewniają atrybuty macierzy.
• Wiersze i kolumny mogą mieæ nazwy, dimnames(), rownames(), colnames()
Przyjrzyjmy się podstawom pracy z macierzami, tworzeniem ich, uzyskiwaniem do nich dostępu i wykreķlenia. Stwórzmy macierz o wysokoķci 3 wierszy i szerokoķci 4 kolumn, z wszystkimi polami ustawionymi na 0.
Sample <- matrix (0, 3, 4)
Konstrukcja macierzy
Moŋemy zbudowaæ macierz bezpoķrednio z elementami danych, zawartoķæ matrycy jest domyķlnie wypeģniona wzdģuŋ orientacji kolumny. Spójrz na poniŋszy kod, zawartoķæ Sample jest wypeģniana kolumnami kolejno.
Sample <- matrix( 1:20, nrow=4, ncol=5)
Dostęp do macierzy
Aby uzyskaæ wartoķci z macierzy, wystarczy podaæ dwa wskažniki zamiast jednego. Wydrukujmy naszą macierz próbek:
print (Sample)
Spróbuj uzyskaæ wartoķæ z drugiego wiersza w trzeciej kolumnie Sample:
Sample [2,3]
Moŋemy uzyskaæ caģy wiersz macierzy, pomijając indeks kolumny (zachowując przecinek). Spróbuj pobraæ trzeci rząd:
Sample [3,] # [1] 3 7 11 15
Aby uzyskaæ caģą kolumnę, pomiņ indeks wiersza. Pobierz czwartą kolumnę:
Sample [,4] # [1] 13 14 15 16
Czynniki
Gdy chcemy, aby dane zostaģy pogrupowane wedģug kategorii, R ma specjalny typ zwany factor do ķledzenia tych skategoryzowanych wartoķci. Czynnik jest wektorem, którego elementy mogą przyjmowaæ jedną z okreķlonych wartoķci. Na przykģad "Pģeæ" zwykle przyjmuje tylko wartoķci "Męŋczyzna", "Kobieta" i "NA". Zbiór wartoķci, które mogą przyjmowaæ elementy czynnika, nazywa się jego poziomami.
Tworzenie Czynników
Aby kategoryzowaæ wartoķci, wystarczy przekazaæ wektor do funkcji factor:
gender <- c('male', 'female', 'male', 'NA', 'female')
types <- factor(gender)
print(gender)
Zobaczysz nieprzetworzoną listę ciągów, powtarzane wartoķci i inne. Teraz wyķwietl wspóģczynnik typów:
print(types)
Rzuæmy okiem na leŋące u podstaw liczby caģkowite. Przekaŋ wspóģczynnik do funkcji as.integer:
as.integer(types) # [1] 2 1 2 3 1
Za pomocą funkcji poziomów moŋna uzyskaæ tylko poziomy czynników:
levels(types) # [1] "female" "male" "NA"
Ramki danych
Ramki danych zapewniają strukturę do przechowywania i uzyskiwania dostępu do kilku zmiennych moŋliwie róŋnych typów danych. Ze względu na ich elastycznoķæ w obsģudze wielu typów danych, ramki danych są preferowanym formatem wejķciowym dla wielu funkcji modelowania dostępnych w R. Utwórzmy trzy indywidualne obiekty o nazwach Id, Gender i Age i poģączmy je w zbiór danych.
Id <- c(101, 102, 103, 104, 105)
Gender <- c('male', 'female', 'male', 'NA', 'female')
Age <- c(38,29,NA,46,53)
Id, Gender i Age są trzema pojedynczymi obiektami, R ma strukturę znaną jako ramka danych, która moŋe powiązaæ wszystkie te zmienne w jednej tabeli lub arkuszu kalkulacyjnym Excel. Ma okreķloną liczbę kolumn, z których kaŋda powinna zawieraæ wartoķci okreķlonego typu. Ma takŋe nieokreķloną liczbę wierszy - zestawy powiązanych wartoķci dla kaŋdej kolumny. Ģatwo jest utworzyæ zestaw danych, wystarczy wywoģaæ funkcję data.frame i podaæ argumenty Id, Gender i Age. Przypisz wynik do zestawu danych Test:
Test <- data.frame(Id, Gender, Age)
Wyķwietl test, aby zobaczyæ jego zawartoķæ:
print(Test)
fix(Test) # Aby wyķwietliæ ten zestaw danych obiektu
Dostęp do ramki danych: Dostęp do poszczególnych częķci ramki danych jest ģatwy. Moŋemy uzyskaæ poszczególne kolumny, podając ich numer indeksu w nawiasach podwójnych. Spróbuj uzyskaæ drugą kolumnę (Gender) Test:
Test [[2]]
Moŋesz podaæ nazwę kolumny jako ciąg w nawiasach podwójnych dla większej czytelnoķci
Test [["Age"]]
Moŋemy nawet uŋyæ skrótu: nazwa ramki danych, znak dolara i nazwa kolumny bez cudzysģowów.
Test$Gender
2.5 IMPORTOWANIE I EKSPORTOWANIE DANYCH
Doķæ często musimy pozyskiwaæ nasze dane z zewnętrznych plików, takich jak pliki tekstowe, arkusze Excela i pliki CSV, aby wykonaæ to R otrzymaģ moŋliwoķæ ģatwego ģadowania danych z zewnętrznych plików. Twoje ķrodowisko moŋe mieæ wiele obiektów i wartoķci, które moŋesz usunąæ za pomocą następującego kodu:
rm(list = ls ())
Funkcja rm() umoŋliwia usuwanie obiektów z okreķlonego ķrodowiska. Importowanie plików TXT: Jeķli masz plik .txt lub plik tekstowy rozdzielany tabulatorami, moŋesz go ģatwo zaimportowaæ za pomocą podstawowej funkcji R read.table ().
setwd ("D: / R Data")
Inc_ds <- read.table ("Income.txt")
W przypadku plików, które uŋywają ciągów separatora innych niŋ przecinki, moŋna uŋyæ funkcji read.table. Argument sep = definiuje znak separatora i moŋna okreķliæ znak tabulacji za pomocą "\t". Wywoģaj read.table na "Inc_tab.txt", uŋywając separatorów tabulatorów:
read.table ("Inc_tab.txt", sep= "\t")
Czy zauwaŋysz nagģówki kolumn "V1", "V2" i "V3"? Pierwszy wiersz nie jest automatycznie traktowany jako nagģówki kolumn w read.table. To zachowanie jest kontrolowane przez argument nagģówka. Ponownie wywoģaj read.table, ustawiając nagģówek na TRUE:
Inc_th <- read.table ("Inc_tab.txt", sep= "\ t", nagģówek = TRUE)
fix (Inc_th)
Importowanie plików CSV: Jeķli masz plik, który oddziela wartoķci przecinkiem, zwykle masz do czynienia z plikiem .csv. Moŋesz zaģadowaæ zawartoķæ pliku CSV do ramki danych, przekazując nazwę pliku do funkcji read.CSV.
read.CSV ("Employee.csv") # Wykonanie tego R oczekuje obecnoķci naszych plików w katalogu roboczym.
Eksporujemy pliki za pomocą funkcji write.table: Funkcja write.table generuje pliki danych. Pierwszy argument okreķla, która ramka danych w R ma zostaæ wyeksportowana. Następny argument okreķla plik do utworzenia. Domyķlny separator to pusta spacja, ale dowolny separator moŋna okreķliæ w opcji sep =. Poniewaŋ nie chcemy doģączaæ nazw wierszy, otrzymaliķmy opcję row.names = FALSE, Domyķlnym ustawieniem opcji quote jest uwzględnianie cudzysģowów wokóģ wszystkich wartoķci znaków, tj. Wokóģ wartoķci w zmiennych ģaņcuchowych i wokóģ nazw kolumn. Jak pokazaliķmy w tym przykģadzie, bardzo często nie chce się cytatów podczas tworzenia pliku tekstowego.
write.table(Employee, file="emp.txt", row.names = FALSE, quote = FALSE)
KROK 3
Eksploracja Danych
WPROWADZENIE
Ilekroæ mamy zamiar stworzyæ model, bardzo waŋne jest, aby zrozumieæ dane i znaležæ ukryty wgląd w dane. Powodzenie projektu analizy danych wymaga gģębokiego zrozumienia danych. Eksploracja danych pomoŋe ci stworzyæ dokģadne modele, jeķli wykonasz to w zaplanowany sposób. Przed formalną analizą danych analityk musi wiedzieæ, ile przypadków znajduje się w zbiorze danych, jakie zmienne są uwzględnione, ile brakujących obserwacji znajduje się w zbiorze danych. Etapy eksploracji danych obejmują zrozumienie zbiorów danych i zmiennych, sprawdzanie atrybutów danych, rozpoznawanie i usuwanie brakujących wartoķci, wartoķci odstających, zrozumienie podstawowej prezentacji danych itp. dziaģania w zakresie eksploracji danych obejmują badanie danych w zakresie podstawowych miar statystycznych i tworzenie wykresy i wykresy do wizualizacji i identyfikacji relacji i wzorców. Wstępna eksploracja zestawu danych pomaga odpowiedzieæ na te pytania, zapoznając analityków z danymi, z którymi pracują. Dodatkowe pytania i uwagi dotyczące etapu warunkowania danych obejmują: Jakie są žródģa danych? Jakie są pola docelowe? Jak czyste są dane? Jak spójna jest zawartoķæ i pliki? Jako specjalista ds. danych musisz ustaliæ, w jakim stopniu dane zawierają brakujące lub niespójne wartoķci oraz czy dane zawierają wartoķci odbiegające od normalnych, i oceņ spójnoķæ typów danych. Na przykģad, jeķli zespóģ spodziewa się, ŋe pewne dane będą liczbowe, potwierdž, ŋe są one numeryczne lub jest to poģączenie ciągów alfanumerycznych i tekstu. Przejrzyj zawartoķæ kolumn danych lub innych danych wejķciowych i sprawdž, czy mają one sens. Na przykģad, jeķli projekt obejmuje analizę poziomów dochodów, wyķwietl podgląd danych, aby potwierdziæ, ŋe wartoķci dochodów są dodatnie lub czy dopuszczalne są zera lub wartoķci ujemne. Poszukaj dowodów na systematyczny bģąd. Przykģady obejmują przesyģanie danych z czujników lub innych žródeģ danych, które ulegają awarii bez uprzedzenia, co powoduje nieprawidģowe, nieprawidģowe lub brakujące wartoķci danych. Przejrzyj dane do pomiaru, jeķli definicja danych jest taka sama dla wszystkich pomiarów. W niektórych przypadkach kolumna danych jest zmieniana lub kolumna przestaje byæ zapeģniana, bez opisywania tej zmiany lub powiadamiania innych. Po zebraniu przez zespóģ przynajmniej niektórych zestawów danych potrzebnych do póžniejszej analizy, przydatnym krokiem jest wykorzystanie narzędzi do wizualizacji danych w celu przeanalizowania wzorców wysokiego poziomu w danych, umoŋliwiając bardzo szybkie zrozumienie cech danych. Jednym z przykģadów jest uŋycie wizualizacji danych w celu zbadania jakoķci danych, takich jak to, czy dane zawierają wiele nieoczekiwanych wartoķci lub innych wskažników brudnych danych. Innym przykģadem jest Skoķnoķæ, jeķli większoķæ danych jest mocno przesunięta w kierunku jednej wartoķci lub koņca kontinuum. Wizualizacja danych umoŋliwia uŋytkownikowi wyszukiwanie interesujących obszarów, powiększanie i filtrowanie w celu znalezienia bardziej szczegóģowych informacji o danym obszarze danych, a następnie wyszukanie szczegóģowych danych w okreķlonym obszarze. Takie podejķcie zapewnia ogólny widok danych i duŋą iloķæ informacji o danym zbiorze danych w stosunkowo krótkim czasie.
WYTYCZNE I UWAGI
Przejrzyj dane, aby upewniæ się, ŋe obliczenia pozostaģy spójne w kolumnach lub tabelach dla danego pola danych. Na przykģad, czy czas ŋycia klienta zmieniģ się w pewnym momencie w trakcie gromadzenia danych? Lub jeķli pracujesz z finansami, czy obliczanie odsetek zmieniģo się z prostych na zģoŋone na koniec roku? Czy dystrybucja danych pozostaje spójna we wszystkich danych? Jeķli nie, jakie dziaģania naleŋy podjąæ, aby rozwiązaæ ten problem? Oceņ ziarnistoķæ danych, zakres wartoķci i poziom agregacji danych. Czy dane reprezentują populację będącą przedmiotem zainteresowania? W przypadku danych marketingowych, jeķli projekt koncentruje się na klientach w wieku wychowawczym, czy dane te reprezentują to, czy są peģne seniorów i nastolatków? Czy w przypadku zmiennych związanych z czasem pomiary są codzienne, tygodniowe, miesięczne? Czy to wystarczy? Czy wszędzie mierzy się czas w sekundach? A moŋe w niektórych miejscach są to milisekundy? Okreķl poziom szczegóģowoķci danych potrzebnych do analizy i oceņ, czy obecny poziom znaczników czasu w danych speģnia tę potrzebę. Czy dane są standaryzowane / znormalizowane? Czy skale są spójne? Jeķli nie, w jakim stopniu dane są spójne lub nieregularne? Są to typowe kwestie, które powinny byæ częķcią procesu myķlowego, gdy zespóģ ocenia zestawy danych uzyskane dla projektu. Zdobycie gģębokiej wiedzy na temat danych będzie miaģo kluczowe znaczenie, gdy przyjdzie czas na budowę i uruchamianie modeli w dalszej częķci procesu.
SPRAWDŽ CZĘĶÆ DANYCH DATASET
setwd("D:/R data")
Employee <- read.csv("Employee.csv")
fix(Employee)
print(Employee)
Funkcja print() wyķwietla zawartoķæ ramki danych (lub dowolnego innego obiektu). Zawartoķæ moŋna zmieniæ za pomocą funkcji edit().
edit(Employee)
SPRAWDŽ WYMIAR DANYCH
Uŋyj dim(), aby uzyskaæ wymiary ramki danych (liczba wierszy i liczba kolumn). Dane wyjķciowe to wektor.
Dim(Employee)
Uŋyj nrow() i ncol(), aby uzyskaæ odpowiednio liczbę wierszy i liczbę kolumn. Moŋemy uzyskaæ te same informacje, wyodrębniając pierwszy i drugi element wektora wyjķciowego z dim().
nrow(Employee)
ncol(Employee)
Sprawdž funkcje i zrozum dane, wyķwietlając kilka pierwszych wierszy za pomocą funkcji head(). Domyķlnie R wyķwietli pierwsze 6 wierszy. Moŋemy uŋyæ head(), aby uzyskaæ pierwsze n obserwacji, a tail(), aby uzyskaæ ostatnie n obserwacji; domyķlnie n = 6. Są to dobre polecenia do uzyskania intuicyjnego wyobraŋenia o tym, jak wyglądają dane, bez ujawniania caģego zestawu danych, który moŋe mieæ miliony wierszy i tysiące kolumn.
head(Employee)
Jeķli chcemy wybraæ tylko kilka wierszy, moŋemy okreķliæ tę liczbę wierszy.
Selecting Rows(Observations)
Samp <- Employee[1:3,]
head(mydata) # Pierwsze 6 wierszy zestawu danych
head(mydata, n=10) # Pierwsze 10 wierszy zestawu danych
head(mydata, n= -10) # Wszystkie wiersze oprócz ostatnich 10
tail(mydata) # Ostatnie 6 wierszy
tail(mydata, n=10) # Ostatnie 10 wierszy
tail(mydata, n= -10) # Wszystkie wiersze oprócz pierwszych 10
Nazwy zmiennych lub nazwy kolumn
names(Employee)
SPRAWDŽ CZĘĶÆ OPISU DATASETU
Częķæ deskryptora oznacza metadane (dane o danych):
str(Employee)
Funkcja str() zapewnia strukturę ramki danych. Ta funkcja identyfikuje caģkowite i liczbowe (podwójne) typy danych, zmienne czynnikowe i poziomy, a takŋe kilka pierwszych wartoķci dla kaŋdej zmiennej. Wykonując powyŋszy kod, moŋemy uzyskaæ informacje o atrybutach zmiennych, takich jak nazwa zmiennej, typ itp. "Num" oznacza, ŋe zmienna "count" jest liczbowa (ciągģa), a "Factor" oznacza, ŋe zmienna jest kategoryczna z kategoriami lub poziomami. Polecenie sapply (Employee, class) zwróci nazwy i klasy (np. numeryczne, liczby caģkowite lub znaki) kaŋdej zmiennej w ramce danych.
sapply(Employee, class)
Aby uzyskaæ wszystkie kategorie lub poziomy zmiennej jakoķciowej, uŋyj funkcji levels()
levels(Employee)
TWORZENIE WIZUALIZACJI
Powszechnie uŋywamy wizualizacji danych do eksploracji danych, poniewaŋ pozwala ona uŋytkownikom na szybkie i proste przeglądanie większoķci istotnych funkcji zestawu danych. Wizualizacje pomagają nam zidentyfikowaæ zmienne, które mogą mieæ interesujące relacje. Wyķwietlając dane graficznie za pomocą wykresów punktowych lub wykresów sģupkowych, moŋemy sprawdziæ, czy dwie lub więcej zmiennych koreluje i ustaliæ, czy są dobrymi kandydatami do dalszej szczegóģowej analizy. Przydatnym sposobem postrzegania wzorców i niespójnoķci w danych jest eksploracyjna analiza danych z wizualizacją. Wizualizacja daje zwięzģy obraz danych, które mogą byæ trudne do zrozumienia na podstawie samych liczb i podsumowaņ. Zmienne x i y danych w ramce danych moŋna zamiast tego wizualizowaæ na wykresie, który ģatwo przedstawia związek między dwiema zmiennymi. Wizualizacja pomaga nam tworzyæ róŋne typy wykresów, takie jak:
1. Histogram
2. Wykres koģowy
3. Wykres sģupkowy / liniowy
4. Fabuģa pudeģka
5. Wykres punktowy
Histogramy: Histogramy moŋna tworzyæ za pomocą funkcji hist(x), gdzie x jest wektorem liczbowym wartoķci do wykreķlenia. Opcja freq = FALSE wykreķla gęstoķci prawdopodobieņstwa zamiast częstotliwoķci. Opcja breaks = kontroluje liczbę pojemników.
# Prosty histogram
hist(Employee$Salary)
# Kolorowy histogram z róŋną liczbą pojemników
hist(Employee$Salary, breaks=12, col="red")
# Naģoŋone histogramy
hist(Employee$Salary, breaks="FD", col="green")
hist(Employee$Salary [Employee$Gender=="Male"], breaks="FD", col="gray",
add=TRUE)
legend("topright", c("Female","Male"), fill=c("green","gray"))
Wykresy koģowe: Wykresy koģowe są tworzone za pomocą funkcji pie(x, labels =), gdzie x jest nieujemnym wektorem numerycznym wskazującym obszar kaŋdego wycinka, a labels = zapisuje wektor znakowy nazw dla wycinków.
# Prosty wykres koģowy
Items_sold <- c(10, 12,4, 16, 8)
Location <- c("Hyderabad", "Bangalore", "Kolkata", "Mumbai", "Delhi")
pie(Items_sold, labels = Location, main="Pie Chart of Locations")
# 3D Rozģoŋony wykres koģowy
library(plotrix)
pie3D(slices,labels=lbls,explode=0.1, main="Pie Chart of Countries ")
Wykres sģupkowy / liniowy:
Wykres liniowy: Wykresy liniowe są zwykle preferowane, gdy mamy analizowaæ rozkģad trendów w danym okresie. Wykres liniowy nadaje się równieŋ do wykresów, w których musimy porównaæ względne zmiany wielkoķci w pewnej zmiennej (jak czas).
# Aby utworzyæ prosty wykres liniowy:
Plot(, type=l)
Wykresy pudeģkowe: Wykresy pudeģkowe moŋna tworzyæ dla poszczególnych zmiennych lub dla zmiennych wedģug grup. Format to boxplot(x, data =), gdzie x jest formuģą, a data = oznacza ramkę danych dostarczającą dane. Przykģadem formuģy jest grupa y~, w której dla kaŋdej wartoķci grupy generowany jest osobny wykres pudeģkowy dla zmiennej numerycznej y. Dodaj varwidth = TRUE, aby szerokoķci wykresu pudeģkowego byģy proporcjonalne do pierwiastka kwadratowego z rozmiarów próbek. Addhorizontal = TRUE, aby odwróciæ orientację osi.
# Boxplot wynagrodzenia wedģug wyksztaģcenia
boxplot(Salary~Education,data=Employee, main="Wynagrodzenia wedģug wyksztaģcenia", xlab="Education", ylab="Salary")
boxplot jest sģowem kluczowym do generowania boxplot. Wykres odbywa się między wynagrodzeniem pracowników a poziomem wyksztaģcenia. Istnienie wartoķci odstających w zbiorze danych obserwuje się jako punkty poza ramką.
Wykresy rozrzutu: Istnieje wiele sposobów tworzenia wykresu rozrzutu w R. Podstawową funkcją jest plot(x, y), gdzie x i y to wektory numeryczne oznaczające punkty (x, y) do wykreķlenia.
# Prosty wykres rozrzutu
attach(Employee)
plot(Age, Salary, main="Scatterplot on Age vs Salary",
xlab="Age", ylab="Salary ", pch= 19
BRAK DANYCH
Przyjrzyjmy się, jak moŋna wykryæ brakujące dane w fazie eksploracji danych za pomocą wizualizacji. Ogólnie rzecz biorąc, analitycy powinni szukaæ anomalii, weryfikowaæ dane ze znajomoķcią domeny i decydowaæ o najbardziej odpowiednim podejķciu do czyszczenia danych. Rozwaŋ scenariusz, w którym bank przeprowadza analizy danych posiadaczy rachunków w celu oceny zatrzymania klientów.
rowSums(is.na(mydata)) # Liczba braków w wierszu
colSums(is.na(mydata)) # Liczba braków w kolumnie / zmiennej
# Konwertuj na brakujące dane
mydata[mydata$age=="& ","age"] <- NA
mydata[mydata$age==999,"age"] <- NA
# Funkcja complete.cases() zwraca logiczny wektor wskazujący, które przypadki są zakoņczone
# lista wierszy danych, w których brakuje wartoķci
mydata[!complete.cases(mydata),]
# Funkcja na.omit () zwraca obiekt z listowym usunięciem brakujących wartoķci.
# Tworzenie nowego zestawu danych bez brakujących danych
mydata1 <- na.omit(mydata)
Wartoķci ekstremalne: obserwacje ekstremalne są przedmiotem zainteresowania i zasģugują na naszą uwagę, poniewaŋ są czymķ więcej niŋ zwykģymi wartoķciami odstającymi na koņcu krzywej dzwonowej. Są to te, które wypaczają rozkģad do pokazanego wczeķniej ksztaģtu F. Wykres pola dla wykrywania wartoķci odstających: wartoķæ odstająca jest wynikiem bardzo róŋnym od reszty danych. Analizując dane, musimy pamiętaæ o takich wartoķciach, poniewaŋ wpģywają one na model, który pasujemy do danych. Dobry przykģad tego uprzedzenia moŋna zobaczyæ, patrząc na prosty model statystyczny, taki jak ķrednia. Zaģóŋmy, ŋe film otrzymuje ocenę od 1 do 5. Siedem osób obejrzaģo film i oceniģo film z ocenami 2, 5, 4, 5, 5, 5 i 5. Wszystkie z wyjątkiem jednej z tych ocen są doķæ podobne (gģównie 5 i 4), ale pierwsza ocena byģa zupeģnie inna od pozostaģych. To byģa ocena 2. To jest przykģad wartoķci odstającej. Wykresy pudeģkowe mówią nam coķ o rozkģadach wyników. Wykresy pokazują nam najniŋszą (dolną poziomą linię) i najwyŋszą (górną) linię poziomą. Odlegģoķæ między najniŋszą poziomą linią a najniŋszą krawędzią przyciemnionego pudeģka to zakres, między którym przypada najniŋsze 25% wyników (tzw. dolny kwartyl). Ramka (zabarwiony obszar) pokazuje ķrodkowe 50% wyników (znane jako zakres międzykwartylowy); tj. 50% wyników jest większych niŋ najniŋsza częķæ zabarwionego obszaru, ale mniejsza niŋ górna częķæ zabarwionego obszaru. Odlegģoķæ między górną krawędzią przyciemnionego pudeģka a górną poziomą linią pokazuje zakres, pomiędzy którym przypada górne 25% wyników (górny kwartyl). Na ķrodku przyciemnionego pudeģka znajduje się nieco grubsza pozioma linia. To reprezentuje wartoķæ mediany. Podobnie jak histogramy, mówią nam równieŋ, czy rozkģad jest symetryczny czy pochylony. W celu symetrycznego rozmieszczenia wąsów po obu stronach pudeģka mają one równą dģugoķæ. Wreszcie zauwaŋysz maģe kóģka nad kaŋdym polem wykresu. Są to przypadki uwaŋane za wartoķci odstające. Kaŋde koģo ma obok siebie liczbę, która mówi nam, w którym rzędzie edytora danych znaležæ przypadek. Wykres ramkowy jest szeroko stosowany do badania istnienia wartoķci odstających w zbiorze danych. Dwa waŋne fakty, o których naleŋy pamiętaæ w przypadku wykresu pudeģkowego to : 1. Liczba obserwacji w zestawie danych musi wynosiæ co najmniej pięæ. 2. Jeķli w zestawie danych znajduje się więcej niŋ jedna kategoria, naleŋy je posortowaæ wedģug kategorii. Zestaw danych zawierający oceny 5 studentów z przedmiotów z języka angielskiego i przedmiotów ķcisģych istnieje w formacie CSV. boxplot jest sģowem kluczowym do generowania boxplot. Wykreķlanie odbywa się między ocenami uzyskanymi przez studentów a przedmiotem. Istnienie wartoķci odstających w zbiorze danych obserwuje się jako punkty poza ramką. Chcemy skupiæ się na interesujących momentach na peryferiach, znanych jako wartoķci odstające i dlaczego mogą byæ waŋne. Kiedy wartoķci odstające stają się skrajnymi obserwacjami po lewej lub po prawej stronie, moŋe to zmieniæ zaģoŋenia przyjęte przez statystę w konfiguracji badania dotyczące zachowania rekrutowanej populacji, co moŋe zagroziæ dowodowi badania i ostatecznie kosztownej poraŋce. Obserwacje ekstremalne są przedmiotem zainteresowania i zasģugują na naszą uwagę, poniewaŋ są czymķ więcej niŋ zwykģymi wartoķciami odstającymi na koņcu krzywej dzwonowej. Są to te, które wypaczają rozkģad do ksztaģtu F.
KROK 4
Przygotowanie Danych
WPROWADZENIE
Przygotowanie danych obejmuje etapy eksploracji, przetwarzania wstępnego i danych reklamacyjnych przed modelowaniem i analizą. Szczegóģowe zrozumienie danych ma kluczowe znaczenie dla powodzenia projektu. Musimy zdecydowaæ, w jaki sposób uwarunkowaæ i przeksztaģciæ dane, aby uzyskaæ format umoŋliwiający póžniejszą analizę. Moŋe byæ konieczne wykonanie wizualizacji danych, aby pomóc nam zrozumieæ dane, w tym ich trendy, wartoķci odstające i relacje między zmiennymi danych. Przygotowanie danych jest zwykle najbardziej pracochģonnym krokiem i w rzeczywistoķci zespoģy spędzają co najmniej 50% czasu projektu w tej krytycznej fazie. Jeķli zespóģ nie jest w stanie uzyskaæ wystarczającej iloķci danych o wystarczającej jakoķci, moŋe nie byæ w stanie wykonaæ kolejnych kroków w cyklu ŋycia. Przygotowanie danych odnosi się do procesu czyszczenia danych, normalizacji zestawów danych i wykonywania transformacji danych. Krytyczny krok w cyklu ŋycia analizy danych, warunkowanie danych moŋe obejmowaæ wiele skomplikowanych kroków w celu poģączenia lub scalenia zestawów danych lub w inny sposób wprowadzenia zestawów danych w stan umoŋliwiający analizę w kolejnych fazach. Uwarunkowanie danych jest często postrzegane jako etap przetwarzania wstępnego dla analizy danych, poniewaŋ obejmuje wiele operacji na zbiorze danych przed opracowaniem modeli do przetwarzania lub analizy danych. Etapy przygotowania danych obejmują:
1. Tworzenie nowych zmiennych.
2. Grupowanie danych, usuwanie duplikatów obserwacji w zbiorze danych.
3. Formatowanie.
4. Przechowywanie, upuszczanie, zmiana nazwy, etykietowanie.
5. Przetwarzanie warunkowe.
6. Funkcje.
7. Ģączenie zestawów danych.
8. Transpozycja danych.
TWORZENIE NOWYCH ZMIENNYCH
Wežmy zestaw danych pracowników, mamy ich miesięczne dane dotyczące dochodu, chcemy obliczyæ podwyŋkę ich wynagrodzeņ i obliczyæ nową pensję. Uŋywamy operatora przypisania (<-) do tworzenia nowych zmiennych.
setwd("D:/R data")
Employee <- read.csv("Employee.csv")
fix(Employee)
Utwórz zmienną o nazwie Bonus z 8% wzrostem wynagrodzenia
Employee$Bonus <- Employee$Salary*.08
Employee$Newsal <- Employee$Salary + Employee$Bonus
fix(Employee)
SORTOWANIE DANYCH
Aby zgrupowaæ ramkę danych w R, uŋyj funkcji order(). Domyķlnie sortowanie jest ROSNĄCE. Dodaj zmienną sortującą. Znak minus oznacza kolejnoķæ MALEJĄCO.
# Sortuj wedģug wieku
Agesort <- Employee[order(Age),]
#Sortowanie z wieloma zmiennymi, sortuj wedģug pģci i wieku
Mul_sort <- Employee[order(Gender, Age),]
Wykonując powyŋszy kod, posortowaliķmy ramkę danych na podstawie Gender jako pierwszej preferencji i Age jako drugiej.
#Sortuj wedģug Gender (rosnąco) i Age (malejąco)
Rev_sort <- Employee[order(Gender, -Age),]
detach(Employee)
IDENTYFIKACJA I USUWANIE DUPLIKOWANYCH DANYCH
Moŋemy usunąæ zduplikowane dane za pomocą funkcji duplicated() i unique(), a takŋe funkcji odrębnej w pakiecie dplyr. Funkcja duplicated() zwraca wektor logiczny, w którym PRAWDA okreķla, które elementy wektora lub ramki danych są duplikatami. Biorąc pod uwagę następujący wektor:
Cust_Id <- c (101, 104, 104, 105, 104, 105)
Aby znaležæ pozycję zduplikowanych elementów w x, moŋemy uŋyæ tego:
duplicated(Cust_Id)
Moŋemy wyķwietliæ zduplikowane elementy, wykonując następujący kod.
Cust_Id [duplicated(Cust_Id)]
Jeķli chcesz usunąæ zduplikowane elementy i uzyskaæ tylko unikalne wartoķci, uŋyj! Duplicated(), gdzie! jest logiczną negacją:
Uniq_Cust <- Cust_Id [! Duplicated (Cust_Id)]
W naszych codziennych zadaniach musimy tworzyæ, modyfikowaæ, manipulowaæ i przeksztaģcaæ dane, aby przygotowaæ je do analizy i raportowania. Uŋywamy niektórych lub innych funkcji do większoķci operacji na danych. Znajomoķæ tych funkcji moŋe znacznie uģatwiæ programowanie. Moŋemy usunąæ zduplikowane wiersze z ramki danych na podstawie wartoķci kolumn, w następujący sposób: # Usuņ duplikaty na podstawie kolumn Work_Balance
Uniq_WB <- Employee [!duplicated(Employee$ Work_Balance), ]
Moŋesz wyodrębniæ unikalne elementy w następujący sposób:
unique(Cust_Id)
Moŋliwe jest równieŋ zastosowanie unique() do ramki danych, aby usunąæ zduplikowane wiersze w następujący sposób:
unique(Employee)
Funkcja distinct() w pakiecie dplyr moŋe byæ uŋywana do przechowywania tylko unikatowych / odrębnych wierszy z ramki danych. Jeķli istnieją zduplikowane wiersze, zachowany zostanie tylko pierwszy wiersz. Jest to wydajna wersja podstawowej funkcji R unique(). Pakiet dplyr moŋna zaģadowaæ i zainstalowaæ w następujący sposób:
install.packages("dplyr")
library("dplyr")
Usuņ zduplikowane wiersze na podstawie wszystkich kolumn:
distinct(Employee)
#Usuņ zduplikowane wiersze na podstawie okreķlonych kolumn (zmiennych): Usuņ zduplikowane wiersze na podstawie JobSatisfaction.
distinct(Employee, JobSatisfaction)
# Usuņ zduplikowane wiersze na podstawie JobSatisfaction i Perf_Rating.
distinct(Employee, JobSatisfaction, Perf_Rating)
FILTROWANIE OBSERWACJI NA PODSTAWIE WARUNKÓW
Age_Con <- Employee[which(Employee$Age < 40), ]
Podczas filtrowania obserwacji na podstawie zmiennych znakowych musimy osadziæ ciąg w cudzysģowach.
Sex_Con <- Employee[which(Employee$Gender ="male"), ]
Filtruj obserwacje na podstawie wielu warunków
Mul_Con <-Employee[which(Employee $Gender=='Female' & Employee $Age < 30),]
Wybór za pomocą funkcji subset
Funkcja subset() jest najģatwiejszym sposobem wybierania zmiennych i obserwacji. W poniŋszym przykģadzie wybieramy wszystkie wiersze, które mają wartoķæ wieku większą lub równą 50 lub wiek mniejszą niŋ 30. Zachowujemy kolumny Emp_Id i Age.
# Korzystanie z funkcji podzbioru
Test <- subset(Employee, Age >= 50 | Age < 30, select=c(Emp_Id, Age))
Przetwarzanie warunkowe
Doķæ często musimy przetwarzaæ dane w oparciu o okreķlone warunki, a podejmowanie decyzji jest waŋną częķcią programowania. Moŋna to osiągnąæ za pomocą warunkowej instrukcji if ... else.
Skģadnia instrukcji If:
if (test_expression) {
statement
}
Moŋemy tworzyæ nowe zmienne, uŋywając, jeķli inaczej. Chcemy promowaæ nasz produkt tylko wķród osób, których dochód przekracza 40 tys.
Employee$Promo <- ifelse(Employee$Salary>40000,"Promote Product","Do not Promote Product")
fix(Employee)
# Tutaj sprawdzamy, czy elementy Wynagrodzenia pracownika $ są większe niŋ 40000, jeķli element jest większy niŋ 40000, przypisuje wartoķæ Promuj produkt do promocji pracownika, a jeķli nie jest on większy niŋ 40000, przypisuje wartoķæ z Nie promuj produktu na promocję $ pracownik. Chcemy przypisaæ wartoķci Low, Medium i High do zmiennej Sal_Grp. Aby to zrobiæ, moŋemy uŋyæ zagnieŋdŋonych instrukcji ifelse():
Employee$Sal_Grp <-ifelse(Employee$Salary >20000 & Employee$Salary<50000," Medium",
ifelse(Employee$Salary >= 50000, "High","Low"))
Teraz to mówi, najpierw sprawdž, czy kaŋdy element wektora Salary jest > 20000 i < 50000. Jeķli tak, przypisz Medium do Sal_Grp. Jeķli tak nie jest, sprawdž następną instrukcję ifelse (), czy Salary > 50000. Jeķli tak, przypisz Sal_Grp wartoķæ High. Jeķli nie jest to ŋaden z nich, przypisz Low.
FORMATOWANIE
Jest to powszechnie stosowane w celu poprawy wyglądu danych wyjķciowych, moŋemy uŋywaæ juŋ istniejących (zdefiniowanych przez system) formatów, a nawet tworzyæ niestandardowe formaty do wartoķci bin w efektywny sposób. Korzystając z tego, moŋemy grupowaæ dane na róŋne sposoby, bez koniecznoķci tworzenia nowego zestawu danych. Wyobražmy sobie, przeprowadziliķmy ankietę na temat nowego produktu (A / c): Ogólnie zadowolony - 1 - Bardzo niski 2 - Niski 3. OK, 4 - Dobry 5 Bardzo dobry. Chociaŋ istnieje wiele sposobów pisania niestandardowych rozwiązaņ, analityk powinien znaæ specjalne procedury, które mogą zmniejszyæ potrzebę niestandardowego kodowania. R będzie traktowaæ czynniki jako zmienne nominalne, a czynniki uporządkowane jako zmienne porządkowe. Moŋesz uŋyæ opcji w funkcjach factor() i ordered() do sterowania mapowaniem liczb caģkowitych na ciągi. Moŋemy uŋyæ funkcji czynnikowej do stworzenia wģasnych etykiet wartoķci.
setwd("D:/R data")
Shop <- read.csv("Shopping.csv")
fix(Shop)
# Zmienna marki w zestawie danych Sklepu ma kod 1, 2, 3 .: Chcemy doģączyæ etykiety wartoķci
1=Samsung, 2=Hitachi, 3=Bluestar.
Shop$Brand <- factor(Shop$Brand, levels = c(1,2,3),
labels = c("Samsung", "Hitachi", "Bluestar"))
# zmienna y jest kodowana 1,2, 3,4 i 5 # chcemy doģączyæ etykiety wartoķci 1 - Bardzo niski 2 - Niski 3. OK 4 - Ddobry 5 - Bardzo dobry.
Shop$Overall_Sat <- ordered(Shop$Overall_Sat, levels = c(1,2,3,4,5),
labels = c("Very Low", "Low", "OK", "Good", "Extremely Good"))
Czasami moŋesz chcieæ utworzyæ nową zmienną kategorialną, klasyfikując obserwacje wedģug wartoķci zmiennej ciągģej. Zaģóŋmy, ŋe chcesz utworzyæ nową zmienną o nazwie Age.Cat, która klasyfikuje ludzi jako "Mģodych", "Dorosģych" i "Starych" wedģug ich wieku. Osoby w wieku poniŋej 35 lat są klasyfikowane jako mģode, osoby między 35 a 60 rokiem ŋycia są klasyfikowane jako doroķli, a osoby powyŋej 60 lat są klasyfikowane jako osoby starsze.
Employee$Age.Cat<-cut(Employee$Age, c(18,35, 60,90), c("Young", "Adult", "Old")
UTRZYMANIE, OPADANIE, ZMIANA NAZWY, ETYKIETOWANIE
# Wybierz zmienne
myvars <- c("Brand", "Safety", "Look")
Sub_shop <- Shop[myvars]
fix(Sub_shop)
# Wyklucz 4 i 6 zmienną
Sub_data <- Shop[c(-4,-6)]
fix(Sub_data)
# Zmieņ nazwę interaktywnie
fix(Shop) # results are saved on close
# Zmieņ nazwę programowo
library(reshape)
Ren_Shop <- rename(Shop, c(Safety="Security"))
Etykietowanie zmiennych: Moŋemy przypisaæ etykiety zmiennych w var.labels do kolumn w danych ramki danych za pomocą etykiety funkcji z pakietu Hmisc.
install.packages("Hmisc")
library("Hmisc")
label(Shop[["Overall_Sat"]]) <- "Overall Satisfaction of the Customer"
label(Shop[["Look"]]) <- "Look and Feel of the Product"
label(Shop)
FUNKCJE
Funkcja zwraca wartoķæ z obliczeņ lub manipulacji systemem, która wymaga zero lub więcej argumentów. Funkcja jest tworzona przy uŋyciu sģowa kluczowego function. Podstawowa skģadnia definicji funkcji R jest następująca:
New_Var <- nazwa_funkcji (Argument1, Argument2, ... N).
Funkcja jest rozpoznawana przez uŋycie nazwy funkcji, po której następuje natychmiast argument (argumenty) funkcji, oddzielone przecinkami i ujęte w nawiasy. Liczba wymaganych i opcjonalnych argumentów jest jednak róŋna. Niektóre funkcje mają po prostu jeden wymagany argument. Inne mają jeden wymagany i jeden lub więcej opcjonalnych argumentów. W większoķci przypadków waŋna jest kolejnoķæ argumentów. Niektóre funkcje nie przyjmują argumentów, w takim przypadku wymagany jest zerowy zestaw nawiasów.
Funkcje znakowe
Funkcje toupper, tolower: Te funkcje zmieniają wielkoķæ liter argumentu
Name <- 'Ramya Kalidindi' #Przypisywanie wartoķci do zmiennej
upcf <- toupper (Name)
locf <- tolower(Name)
Funkcja trimws: Doķæ często dane, które otrzymujemy, mogą zawieraæ niepoŋądane spacje i chcemy je usunąæ, aby nasze dane byģy czyste. Uŋywamy funkcji trimws, aby radziæ sobie z odstępami ģaņcucha.
Name <- " Y Lakshmi Prasad "
Trimmed_Name <- trimws(Name, which = c("both", "left", "right"))
Funkcja substr: Ta funkcja sģuŋy do wydobywania znaków ze zmiennych ģaņcuchowych. Argumenty substr() okreķlają wektor wejķciowy, początkową pozycję znaku i koņcową pozycję znaku. Ostatni parametr jest opcjonalny. W przypadku pominięcia wszystkie znaki po lokalizacji okreķlonej w drugim miejscu zostaną wyodrębnione.
Req_Name <- substr(Name, 6, 12)
Tworzenie zmiennej ģaņcuchowej ze zmiennych numerycznych
stringx <- as.character (numericx)
typeof (stringx)
typeof (numericx)
Funkcja typeof() moŋe byæ uŋywana do weryfikacji typu obiektu, moŋliwe wartoķci to logiczne, caģkowite, podwójne, zģoŋone, znakowe, surowe, lista, NULL, zamknięcie (funkcja), specjalne i wbudowane.
Twórz zmienne numeryczne ze zmiennych ģaņcuchowych.
Argument w funkcji as.numeric, liczba caģkowita jest liczbą znaków w ģaņcuchu, podczas gdy liczba dziesiętna jest opcjonalną specyfikacją, ile znaków występuje po przecinku.
numericx <- as.numeric (stringx)
typeof (stringx)
typeof (numericx)
Zadanie: Oblicz przyrost na 10% i uzyskaj nowe wynagrodzenie dla kaŋdego Id.
Num_data <- data.frame(Id = c(101,102,103),
Salary =c(40700,12000,37000))
sapply(Num_data, mode)
Num_data$Char_sal <- as.character(Num_data$Salary)
typeof(Num_data$Char_sal)
Num_data$Saln <- as.numeric(Num_data$Char_sal)
typeof(Num_data$Saln)
Num_data$Bonus <- Num_data$Saln*.10
fix(Num_data)
Num_data$New_Sal <- Num_data$Saln+Num_data$Bonus
Funkcje numeryczne
Funkcja Abs: Uŋywamy tej funkcji do uzyskania wartoķci bezwzględnej;
a = 5
aba <- abs (a)
Val <- -28,86
Req <- abs (Val))
Wartoķci Floor(Base) and ceiling(Top):
Flx = floor(X) # Wartoķæ bazowa
Cilx = ceilling(X) # Najwyŋsza wartoķæ
Funkcja Round:
Val= 43.837
Rval1=round(Val) #44
Rval2=round(Val,digits=2) #43.84
Funkcja MAX: Zwraca największą brakującą wartoķæ z listy
X = maks. (2,6, NA, 8,0)
Funkcja MIN: Zwraca najmniejszą nie brakującą wartoķæ z listy
Y = min (2,6,1,7,0, -2)
Funkcja Sum: zwraca sumę (caģkowitą) wartoķci
Y = Sum(9,8,., 9)
Funkcja mean: Oblicza się ją, biorąc sumę wartoķci i dzieląc ją przez liczbę wartoķci w serii danych. Funkcja mean() sģuŋy do obliczenia tego w R.
# Utwórz wektor i znajdž jego ķrednią.
x <- c (7,3, NA, 4,18,2,54,8)
res_mean <- mean(x)
print (res_mean)
# Znajdž ķrednie spadające wartoķci NA.
resmean_na <- mean(x, na.rm = PRAWDA)
print (resmean_na)
Funkcja median: ķrodkową wartoķcią w serii danych jest mediana. Funkcja median() jest uŋywana w R do obliczenia tej wartoķci.
# Utwórz wektor i znajdž medianę.
x <- c (12,7,3,4.2,18,2,54, -21,8, -5)
median.result <- mediana (x)
print (median.result)
Funkcje daty / godziny: Funkcje daty / godziny to zestaw funkcji, które zwracają częķci daty, wartoķci daty lub godziny lub konwertują wartoķci liczbowe na wartoķci R daty lub godziny. Te funkcje są przydatne do wyodrębniania daty i godziny z wartoķci daty i godziny lub przeksztaģcania osobnych wartoķci miesiąca, dnia i roku w wartoķæ daty R.
Funkcje Sys.Date, date: Funkcja zwraca dzisiejszą datę z zegara systemowego, nie wymagając ŋadnych argumentów.
Sys.Date() zwraca dzisiejszą datę.
date() zwraca aktualną datę i godzinę.
# print today's date
today <- Sys.Date()
format(today, format="%B %d %Y")
format(today, format="%m %d %Y")
format(today, format="%m %d %y")
Moŋesz zauwaŋyæ, ŋe data systemowa jest prezentowana na róŋne sposoby, gdy zmieniamy format. Musimy znaležæ format, który lepiej pasuje do naszych wymagaņ i wybraæ go. Konwertowanie znaków na datę: Moŋesz uŋyæ funkcji as.Date () do konwersji danych znaków na daty. Format to As.Date (x, "format"), gdzie x to dane znakowe, a format daje odpowiedni format. Domyķlny format to rrrr-mm-dd
Testdts <- as.Date(c("1982-07-12", "1975-03-01"))
# Uŋyj as.Date () do konwersji ciągów na daty
Testdts <- as.Date(c("1982-07-12", "1975-03-01"))
# liczba dni między 7/12/82 a 03/01/75
days <- Testdts [1] - Testdts [2]
ĢĄCZENIE DANYCH
Odczytywanie danych z dwóch lub więcej zestawów danych i przetwarzanie ich przez Append Rows, Append Columns, Merging
Doģączanie wierszy: Ģączenie zestawów danych zasadniczo oznacza ukģadanie jednego zestawu danych na drugim, to znaczy, biorąc pod uwagę dwa zestawy danych, wszystkie rekordy z drugiego zestawu danych zostaną dodane na koņcu pierwszego zestawu danych podczas konkatenacji zestawów danych mają identyczną strukturę, ale inną zawartoķæ. Przez strukturę rozumiemy, ŋe tabele miaģyby takie same nazwy kolumn, a kolumny miaģyby ten sam typ (numeryczny lub znakowy). Jeķli kolumna istnieje w co najmniej jednym zestawie danych, ale nie w innym, kolumna ta jest uwzględniana we wszystkich rekordach wyjķciowych, ale z brakującą wartoķcią dla wszystkich rekordów w tabelach, które nie miaģy tej kolumny. Funkcja rbind umoŋliwia doģączenie jednego zestawu danych na dole drugiego, co jest znane jako doģączanie lub ģączenie zestawów danych. Jest to przydatne, gdy chcesz poģączyæ dwa zestawy danych, które zawierają róŋne obserwacje dla tych samych zmiennych. Korzystając z funkcji rbind, musimy upewniæ się, ŋe kaŋdy zestaw danych zawiera tę samą liczbę zmiennych i wszystkie nazwy zmiennych są zgodne. Konieczne moŋe byæ usunięcie lub zmiana nazw niektórych zmiennych w tym procesie. Zmienne nie muszą byæ uģoŋone w tej samej kolejnoķci w zestawach danych, poniewaŋ funkcja rbind automatycznie dopasowuje je wedģug nazwy. Funkcja rbind nie identyfikuje duplikatów ani nie sortuje danych. Moŋesz to zrobiæ dzięki funkcjom unikalnym i zamówieniowym.
sale1 <- data.frame(Cust_Id = c(101,103,105),
Amount_Spent =c(1700,1200,3700),
Pur_dt = c(20-03-2015,20-03-2015,20-03-2015))
fix(sale1)
sale2 <- data.frame(Cust_Id = c(103,104,105,108),
Pur_dt = c(22-03-2015,22-03-2015,22-03-2015,22-03-2015),
Amount_Spent =c(1800,3400,2500,3200))
fix(sale2)
saleall <-rbind(sale1, sale2)
fix(saleall)
Zauwaŋ, ŋe nowy zestaw danych zawiera wszystkie oryginalne dane w oryginalnej kolejnoķci, w tym dwie kopie danych dla Cust_Id 103 i 105. Moŋemy doģączyæ dwa lub więcej zbiorów danych w ten sam sposób.
Doģączanie kolumn: Funkcja cbind wkleja jeden zestaw danych na bok innego. Jest to przydatne, jeķli dane z odpowiednich wierszy kaŋdego zestawu danych naleŋą do tej samej obserwacji. Funkcji cbind moŋna uŋywaæ tylko do ģączenia zestawów danych o tej samej liczbie wierszy.
Scalanie zestawów danych przez wspólne zmienne: Funkcja scalania pozwala poģączyæ dwa zestawy danych poprzez dopasowanie obserwacji zgodnie z wartoķciami wspólnych zmiennych. Rozwaŋ zestawy danych sale1 i loc1. Zestawy danych mają wspólną zmienną o nazwie Cust_Id, której moŋna uŋyæ do dopasowania odpowiednich obserwacji.
loc1 <- data.frame(Cust_Id = c(101,102,103,104,105),
Location =c("Hyderabad","Bangalore","Chennai","Hyderabad","Bangalore"))
Merdata <- merge(sale1,loc1)
fix(Merdata)
Funkcja merge identyfikuje zmienne o tej samej nazwie i uŋywa ich do dopasowania obserwacji. W tym przykģadzie oba zestawy danych zawierają zmienną o nazwie Cust_Id, więc R automatycznie uŋywa tej zmiennej, aby dopasowaæ obserwacje.
All_mer <- merge (sale1, loc1, all = T)
fix (All_mer)
Po poģączeniu dwóch zestawów danych z funkcją merge R automatycznie wyklucza wszelkie niedopasowane obserwacje, które pojawiają się tylko w jednym z zestawów danych. Argumenty all, all.x i all.y pozwalają kontrolowaæ, w jaki sposób R radzi sobie z niedopasowanymi obserwacjami. Aby zachowaæ wszystkie niedopasowane obserwacje, ustaw argument all na T:
L_mer <- merge(sale1,loc1,all.x=T)
fix(L_mer)
R_mer <- merge(sale1,loc1,all.y=T)
fix(R_mer)
Aby poģączyæ dwie ramki danych (zestawy danych) w poziomie, uŋyj funkcji scalania. W większoķci przypadków ģączysz dwie ramki danych za pomocą jednej lub więcej wspólnych zmiennych kluczowych (tj. sprzęŋenia wewnętrznego).
# scal dwie ramki danych wedģug identyfikatora
total <- merge(data frameA,data frameB,by="ID")
Dodawanie wierszy: Aby poģączyæ dwie ramki danych (zestawy danych) pionowo, uŋyj funkcji rbind. Dwie ramki danych muszą mieæ te same zmienne, ale nie muszą byæ w tej samej kolejnoķci.
total <- rbind (data frame A, data frame B)
TRANSPOZYCJA DANYCH
Przeksztaģcanie zestawu danych jest równieŋ znane jako Obracanie, Transpozycja lub Transformacja zestawu danych. Zwykle ma to zastosowanie do zestawów danych, w których wykonano powtarzane pomiary, funkcja zmiany ksztaģtu sģuŋy do zmiany orientacji danych., Ale przed wykonaniem zmiany ksztaģtu musimy zadaæ sobie następujące pytania:
• Co powinno pozostaæ takie samo
• Która zmienna powinna wzrosnąæ
• Która zmienna powinna zmaleæ
• Która zmienna powinna przejķæ na ķrodek
# Przeniesienie danych
setwd("D:/R data")
Vitals <- read.csv("Vitals.csv")
fix(Vitals)
T_vitals<-reshape( Vitals, direction="wide", v.names="Result", timevar="VS_Test",
idvar="Pat_Id")
fix(T_vitals)
Poniewaŋ Pat_Id jest okreķlony w idvar, pozostaģ na tej samej pozycji, wszystkie pozostaģe zmienne zostaģy transponowane. Uŋyj argumentu v.names, aby okreķliæ zmienną, którą chcesz podzieliæ na róŋne kolumny. Uŋyj argumentu timevar, aby okreķliæ zmienną wskazującą, do której kolumny naleŋy wartoķæ. Uŋyj argumentu idvar, aby okreķliæ, która zmienna jest uŋywana do grupowania rekordów.
KROK 5
Myķlenie Statystyczne
WPROWADZENIE
Statystyka to nauka zajmująca się zbieraniem, klasyfikacją, analizą i interpretacją faktów liczbowych oraz wykorzystaniem teorii prawdopodobieņstwa w celu uporządkowania agregatów danych. Przyjrzyjmy się niektórym problemom biznesowym, z którymi boryka się czģowiek biznesu, gdzie potrzebuje statystycznych metod ich rozwiązywania.
• Gdzie powinniķmy otworzyæ nasz nowy sklep detaliczny?
• Jak duŋe pomieszczenia powinniķmy wynająæ?
• Ile osób powinienem obsģuŋyæ w tym sklepie?
• Jaki jest odpowiedni poziom zapasów dla kaŋdego produktu?
• Jak zwiększyæ wartoķæ klienta i ogólne przychody?
• Jak opracowaæ nowe, udane produkty?
• Czy powinniķmy przyjmowaæ zamówienia online, czy nie?
• Ile powinniķmy zainwestowaæ w reklamę?
• Jak obniŋyæ koszty operacyjne?
TERMINOLOGIA STATYSTYCZNA
Przed rozwiązaniem wyŋej wymienionych problemów przyjrzyjmy się terminom statystycznym, które pozwalają nam wygodnie radziæ sobie z tymi scenariuszami.
Populacja: Populacja to kompletny zestaw elementów, które mają co najmniej jedną wspólną cechę.
Próbka: podzbiór populacji wybrany do analizy.
Parametr: miara obliczana dla caģej populacji.
Statystyka: miara obliczana na próbce.
Statystyki opisowe: sģuŋą do opisywania lub podsumowywania danych w sposób znaczący i uŋyteczny. Moŋemy opisywaæ dane na wiele sposobów, takich jak miary tendencji centralnej, miary dyspersji, miary lokalizacji i ksztaģtu rozkģadu. Miary opisowe dają lepsze wyczucie danych i mogą przedstawiaæ ogólny obraz danych, statystyki te obejmują ķrednią, tryb, medianę, minimum, maksimum, wariancję, odchylenie standardowe, skoķnoķæ, kurtozę itp.
Statystyki wnioskowania: metody wykorzystujące teorię prawdopodobieņstwa do dedukcji wģaķciwoķci populacji na podstawie analizy wģaķciwoķci próbki danych z niej pobranej.
Statystyka predykcyjna: metody przewidywania przyszģych prawdopodobieņstw na podstawie danych historycznych.
Statystyka preskryptywna: Metody pozwalają nam na okreķlenie szeregu moŋliwych dziaģaņ i prowadzą nas w kierunku optymalnego rozwiązania.
Zmienna losowa: zmienna, której wartoķæ moŋe ulec zmianie ze względu na przypadek.
Odchylenie: Nadawanie niesprawiedliwej preferencji jednej rzeczy względem drugiej.
Zmienna: Zmienna jest cechą lub atrybutem, który moŋna zmierzyæ lub policzyæ.
Dane moŋna podzieliæ na 2 typy:
1. Dane jakoķciowe: Jeķli moŋemy ustawiæ dane w dowolnej liczbie grup, nazywamy te dane danymi jakoķciowymi. Jeķli nie ma uporządkowania między kategoriami, nazywamy tę zmienną, zmienną nominalną, jeķli kategorie mogą byæ uporządkowane, wówczas nazywamy tę zmienną jako zmienną porządkową.
2. Dane iloķciowe: jest to pomiar wyraŋony w liczbach, ale nie wszystkie liczby są liczbowe, takie jak numer telefonu komórkowego i kod pocztowy w Indiach, których nie moŋemy dodawaæ ani odejmowaæ.
SKALA POMIARU
Są to sposoby kategoryzacji róŋnych typów zmiennych.
Skala nominalna: Skala ta speģnia wģaķciwoķæ toŋsamoķci pomiaru. Wežmy na przykģad Pģeæ. Osoby mogą byæ klasyfikowane jako "męŋczyzna" lub "kobieta", ale ŋadna wartoķæ nie reprezentuje mniej więcej "pģci" niŋ druga. Religia i rasa to inne przykģady zmiennych, które są zwykle mierzone w skali nominalnej.
Skala porządkowa: ta skala ma wģaķciwoķæ zarówno toŋsamoķci, jak i wielkoķci. Kaŋda wartoķæ na skali porządkowej ma unikalne znaczenie i ma uporządkowany związek z kaŋdą inną wartoķcią na skali. Wežmy przykģad oceniania filmu ?. Otrzymujemy odpowiedzi na bardzo dobre, dobre, ķrednie, zģe itp.
Skala interwaģów: ta skala ma wģaķciwoķci identycznoķci, wielkoķci i równych przedziaģów. Doskonaģym przykģadem skali interwaģowej jest skala Fahrenheita do pomiaru temperatury. Skala skģada się z równych jednostek temperatury, tak ŋe róŋnica między 40 a 50 stopni Fahrenheita jest równa róŋnicy między 50 a 60 stopni Fahrenheita. Dzięki skali interwaģowej wiesz równieŋ, jak duŋe lub mniejsze są.
Skala stosunku: ta skala pomiaru speģnia wszystkie cztery wģaķciwoķci pomiaru: toŋsamoķæ, wielkoķæ, równe przedziaģy i zero bezwzględne. Na przykģad, jeķli waga obiektu wynosi 80 kilogramów, moŋemy powiedzieæ, ŋe ten obiekt jest podwójny w stosunku do obiektu który waŋy 40 kilogramów. Zmienne takie jak wzrost, wiek, waga mają unikalne znaczenie, mogą byæ uporządkowane wedģug rangi, jednostki wzdģuŋ skali są sobie równe, a absolutne zero.
TECHNIKI POBIERANIA PRÓBEK
Techniki pobierania próbek to metody stosowane do pobrania próbki z populacji. Istnieją róŋne metody próbkowania. Statystyka próby jest charakterystyczną cechą próby, statystyki próby mogą byæ wykorzystane jako oszacowanie punktowe dla parametru populacji. Wybór prostej próbki losowej (SRS):
• Bezstronny: Kaŋda jednostka ma równe szanse na wybór w próbie
• Niezaleŋny: Wybór jednej jednostki nie ma wpģywu na wybór innych jednostek
• SRS to zģoty standard, w stosunku do którego mierzone są wszystkie inne próbki
Wybieranie ramki próbkowania:
• Ramka próbkowania to po prostu lista elementów, z których moŋna pobraæ próbkę.
• Czy ramka próbkowania reprezentuje populację?
• Dostępna lista moŋe róŋniæ się od ŋądanej listy: np. nie mamy listy klientów, którzy nie kupili w sklepie.
• Czasami nie istnieje kompleksowa ramka próbkowania: przy prognozowaniu na przyszģoķæ. Tak więc peģna lista akceptacji ofert kart kredytowych jeszcze nie istnieje.
Typowe wady pobierania próbek:
• Zbieranie danych tylko od ochotników (próbka dobrowolnej odpowiedzi): - np. recenzje online (maps.google.com, tripadvisor.com)
• Wybór ģatwo dostępnych respondentów (próba wygody): - np. wybranie ankiety w centrum handlowym In-Orbit
• Wysoki wskažnik braku odpowiedzi (ponad 70%): - np. Ankiety CEO / CIO dotyczące niektórych trendów w branŋy
Wariacja próbkowania:
• Ķrednia próbki róŋni się w zaleŋnoķci od próbki
• Ķrednia próbki moŋe byæ (i najprawdopodobniej jest róŋna) od ķredniej populacji
• Ķrednia próbki jest zmienną losową
Centralne twierdzenie graniczne (CLT) i rozkģad ķredniej próbki:
Rozkģad ķredniej próbki będzie normalny, gdy rozkģad danych w populacji będzie normalny. W przeciwnym razie zakģadamy, ŋe jest on w przybliŋeniu normalny, nawet jeķli rozkģad danych w populacji nie jest normalny, jeķli wielkoķæ próby jest "doķæ duŋa". CLT jest waŋny, gdy kaŋdy punkt danych w próbce jest niezaleŋny od drugiego, a wielkoķæ próbki jest wystarczająco duŋa.
Jak duŋy jest wystarczająco duŋy?
• Zaleŋy od dystrybucji danych - przede wszystkim od symetrii i obecnoķci wartoķci odstających
• Jeķli dane są doķæ symetryczne i mają kilka wartoķci odstających, nawet mniejsze próbki są w porządku. W przeciwnym razie potrzebujemy większych próbek
• Próbka o wielkoķci 30 jest uwaŋana za wystarczająco duŋą, ale moŋe to / nie byæ wystarczające
Rozkģady próbkowania i centralne twierdzenie graniczne:
• Ilu nowych klientów pozyskam, jeķli otworzę sklep w tym obszarze?
• Jaki jest odpowiedni poziom zapasów
• Jaki jest odpowiedni poziom zapasów dla naszego nowego ereadera?
• Jaki jest wpģyw braku zapasów
• Jaki jest wpģyw braku zapasów na zachowanie konsumentów?
• Jakie oprocentowanie powinniķmy pobieraæ za tę poŋyczkę?
• Czy nasza jakoķæ poprawi się po zleceniu konsultacji?
• Ile czasu spędzają potencjalni klienci w sieci?
• Czy po poģączeniu skróciģy się terminy realizacji naszych zamówieņ?
• Ile ma takich poŋyczek Ile takich poŋyczek byģo niespģaconych w przeszģoķci?
• Jaka jest iloķæ osobogodzin potrzebnych do ukoņczenia takiego projektu?
Wprowadzenie do teorii prawdopodobieņstwa: prawdopodobieņstwo jest wykorzystywane w caģej firmie do oceny ryzyka związanego z podejmowaniem decyzji. Kaŋda podjęta przez nas decyzja niesie ze sobą pewną szansę na niepowodzenie, dlatego analiza prawdopodobieņstwa jest przeprowadzana formalnie i nieformalnie. Większoķæ z nas stosuje prawdopodobieņstwa z dwoma warunkami:
1. Kiedy wystąpi jedno lub drugie zdarzenie
2. W przypadku wystąpienia dwóch lub więcej zdarzeņ
Rozumiemy to na przykģadzie biŋuterii z okazji Dnia Festiwalu. Jakie jest prawdopodobieņstwo, ŋe dzisiejszy popyt przekroczy naszą ķrednią sprzedaŋ? Jakie jest prawdopodobieņstwo, ŋe popyt przekroczy naszą ķrednią sprzedaŋ, a ponad 20% naszych siģ sprzedaŋy nie zgģosi do pracy?
Zmienna losowa:
• Zmienna losowa opisuje prawdopodobieņstwo niepewnego przyszģego wyniku liczbowego losowego procesu.
• Jest to zmienna, poniewaŋ moŋe przyjąæ jedną z kilku moŋliwych wartoķci.
• Jest losowa poniewaŋ z kaŋdą moŋliwą wartoķcią wiąŋe się pewna szansa.
Niezaleŋna: gdy wartoķæ przyjmowana przez jedną zmienną losową nie wpģywa na wartoķæ przyjmowaną przez drugą zmienną losową: np. rzut dwiema kostkami.
Zaleŋna: gdy wartoķæ jednej zmiennej losowej daje nam więcej informacji na temat drugiej zmiennej losowej: np. wzrost i waga studentów.
TEORIA PRAWDOPODOBIEŅSTWA
Podejķcie klasyczne: prawdopodobieņstwo zdarzenia jest równe liczbie wyników, w których zdarzenie ma miejsce, podzielonej przez caģkowitą liczbę moŋliwych wyników.
Podejķcie względnej częstotliwoķci: Podczas rzucania monetą początkowo stosunek liczby gģów do liczby prób pozostanie zmienny. Wraz ze wzrostem liczby tials stosunek zbiega się do staģej liczby (powiedzmy 0,5).
Podejķcie prawdopodobieņstwa subiektywnego: opiera się na przeszģych doķwiadczeniach i intuicji jednostki. Większoķæ decyzji kierowniczych dotyczy konkretnych, unikalnych sytuacji
Rozkģad prawdopodobieņstwa: rozkģad prawdopodobieņstwa jest reguģą, która identyfikuje moŋliwe wyniki zmiennej losowej i przypisuje kaŋdemu prawdopodobieņstwo.
• Rozkģad dyskretny ma skoņczoną liczbę wartoķci: np. wartoķæ nominalna karty, staŋ pracy studentów zaokrąglony do najbliŋszego miesiąca.
• Rozkģad ciągģy ma wszystkie moŋliwe wartoķci w pewnym zakresie: np. miesięczna sprzedaŋ w sklepie detalicznym, tętno pacjentów w szpitalu. Ciągģe rozkģady są ģatwiejsze w obsģudze i są dobrym przybliŋeniem, gdy istnieje duŋa liczba moŋliwych wartoķci
Dyskretny rozkģad prawdopodobieņstwa: Zaģóŋmy, ŋe losowo wybraģeķ kartę z talii kart. Jakie jest prawdopodobieņstwo, ŋe ta karta będzie
• Większa niŋ 7?
• Równa lub większa niŋ 6?
• Mniejsza niŋ 3?
• Większa niŋ 4 i mniej niŋ 8?
Dzienna sprzedaŋ duŋych pģaskich telewizorów w sklepie (X): Jakie jest prawdopodobieņstwo sprzedaŋy? Jakie jest prawdopodobieņstwo sprzedaŋy co najmniej trzech telewizorów?
Oczekiwana wartoķæ lub ķrednia: Oczekiwana wartoķæ lub ķrednia (?) zmiennej losowej jest ķrednią waŋoną jej wartoķci, prawdopodobieņstwa sģuŋą jako wagi. Jaka jest ķrednia liczba zegarków sprzedawana dziennie?
Odchylenie i odchylenie standardowe: obie miary zmiennoķci lub niepewnoķci w zmiennej losowej.
Wariancja (σ2): Ķrednia waŋona kwadratowych odchyleņ od ķredniej, Prawdopodobieņstwa sģuŋą jako wagi, Jednostki są kwadratem jednostek zmiennej.
Odchylenie standardowe (σ): Pierwiastek kwadratowy wariancji, Mają takie same jednostki jak zmienna
Rozkģad dwumianowy: Rozkģad dwumianowy opisuje dyskretne dane wynikające z eksperymentu znanego jako proces Bernoulliego. Rzucanie monety okreķloną liczbę razy jest procesem Bernoulliego, a wyniki takich rzutów mogą byæ reprezentowane przez dwumianowy rozkģad prawdopodobieņstwa. Sukces lub poraŋka rozmówców w teķcie umiejętnoķci moŋe byæ równieŋ opisany przez proces Bernoulliego. Z drugiej strony rozkģad częstotliwoķci ŋywotnoķci ķwietlówek w fabryce byģby mierzony w ciągģej skali godzin i nie kwalifikowaģby się jako rozkģad dwumianowy. Funkcja masy prawdopodobieņstwa, ķrednia i wariancja jest następująca:
Charakterystyka rozkģadu dwumianowego
• Moŋliwe są tylko dwa moŋliwe wyniki: gģowy lub reszka, tak lub nie, sukces lub poraŋka
• Kaŋdy proces Bernoulliego ma swoje charakterystyczne prawdopodobieņstwo. Wežmy sytuację, w której historycznie siedem dziesiątych wszystkich osób, które ubiegaģy się o okreķlony rodzaj pracy, zdaģo egzamin. Powiedzielibyķmy, ŋe charakterystycznym prawdopodobieņstwem jest tutaj 0,7, ale moglibyķmy opisaæ nasze wyniki testów jako Bernoulli tylko wtedy, gdybyķmy byli pewni, ŋe odsetka tych
• Jednoczeķnie wynik jednego testu nie moŋe wpģywaæ na wynik innych testów.
Dystrybucja Poissona: Dystrybucja Poissona jest uŋywana do opisania szeregu procesów, w tym dystrybucji poģączeņ telefonicznych przechodzących przez system rozdzielnic, zapotrzebowania pacjentów na usģugi w placówce sģuŋby zdrowia, przyjazdu cięŋarówek i samochodów do punktu poboru opģat oraz liczba wypadków na skrzyŋowaniu.
Wszystkie te przykģady mają wspólny element: moŋna je opisaæ za pomocą dyskretnej zmiennej losowej, która przyjmuje wartoķci caģkowite (0, 1, 2, 3, 4 itd.). Liczba pacjentów przybywających do szpitala w danym przedziale czasu będzie wynosiæ 0, 1, 2, 3, 4, 5 lub inną liczbę caģkowitą. Podobnie, jeķli policzysz liczbę samochodów przybywających do punktu poboru opģat na autostradzie w ciągu okoģo 10 minut, liczba będzie wynosiæ 0, 1, 2, 3, 4, 5 itd. Funkcja masy prawdopodobieņstwa, ķrednia i wariancja są następujące:
Charakterystyka rozkģadu Poissona
• Jeķli wežmiemy pod uwagę przykģad liczby samochodów, ķrednią liczbę pojazdów, które przybywają na godzinę szczytu, moŋna oszacowaæ na podstawie danych o ruchu drogowym w przeszģoķci.
• Jeķli podzielimy godzinę szczytu na odstępy po jednej sekundzie kaŋda, stwierdzimy, ŋe następujące stwierdzenia są prawdziwe.
• Prawdopodobieņstwo, ŋe dokģadnie jeden pojazd dotrze do pojedynczej kabiny na sekundę, jest bardzo maģą liczbą i jest staģe dla kaŋdego przedziaģu jednej sekundy.
• Prawdopodobieņstwo, ŋe dwa lub więcej pojazdów dotrze w ciągu jednej sekundy, jest tak maģe, ŋe moŋemy przypisaæ mu wartoķæ zerową.
• Liczba pojazdów, które przybywają w danym interwale jednosekundowym, jest niezaleŋna od czasu, w którym interwaģ jednosekundowy występuje w godzinach szczytu.
• Liczba przylotów w dowolnym przedziale jednosekundowym nie zaleŋy od liczby przylotów w ŋadnym innym przedziale jednosekundowym.
ROZKĢAD NORMALNY
Co to jest rozkģad normalny?
• Jak wykonaæ obliczenia prawdopodobieņstwa związane z rozkģadem normalnym?
• Jakie są róŋne waŋne wģaķciwoķci rozkģadu normalnego?
Podstawy rozkģadu normalnego:
• Wykres pdf (funkcja gęstoķci prawdopodobieņstwa) jest krzywą w ksztaģcie dzwonu
• Normalna zmienna losowa przyjmuje wartoķci od -∞ do +∞
• Jest symetryczny i wyķrodkowany wokóģ ķredniej (która jest równieŋ medianą i trybem)
• Dowolny rozkģad normalny moŋna okreķliæ za pomocą tylko dwóch parametrów - ķredniej (?) i odchylenia standardowego (σ)
Piszemy to jako X ˜ N (μ, σ2)
Normalna dystrybucja ma zastosowania w wielu obszarach administracji biznesowej. Na przykģad:
• Wspóģczesna teoria portfela zwykle zakģada, ŋe zwroty ze zdywersyfikowanego portfela aktywów są zgodne z normalnym rozkģadem.
• W zarządzaniu operacjami zmiany procesów często są zwykle rozkģadane.
• W zarządzaniu zasobami ludzkimi wydajnoķæ pracowników jest czasem uwaŋana za normalnie rozģoŋoną.
Czy rozkģad jest normalny? Aby rozkģad byģ normalny, powinny zostaæ speģnione następujące warunki:
• Ķrednia, mediana i tryb powinny byæ prawie równe
• Odchylenie standardowe powinno byæ niskie
• Skoķnoķæ i kurtoza powinny byæ bliskie zeru
• Mediana powinna leŋeæ dokģadnie pomiędzy górnym i dolnym kwartylem
Wykres normalnego prawdopodobieņstwa: Wykres normalnego prawdopodobieņstwa to technika graficzna do testowania normalnoķci: ocena, czy zbiór danych jest w przybliŋeniu normalnie rozģoŋony. W tym przypadku porównujemy zaobserwowane prawdopodobieņstwo skumulowane z teoretycznym prawdopodobieņstwem skumulowanym. Jeķli obserwowane dane pochodzą z rozkģadu normalnego, powinniķmy uzyskaæ linię prostą. W przypadku rozkģadu normalnego 68,2% danych mieķci się w zakresie jednego odchylenia standardowego. (ķrednia - odchylenie standardowe, ķrednia + odchylenie standardowe).
Odstępstwa od normalnoķci: jak moŋemy powiedzieæ, ŋe rozkģad normalny jest rozsądnym przybliŋeniem danych? Moŋemy spojrzeæ na dane 1. Więcej niŋ jeden tryb sugerujący dane pochodzą z odrębnych grup, 2. Brak symetrii danych, 3. Niezwykģe wartoķci ekstremalne. Jeķli którykolwiek z nich zaobserwujemy, moŋemy powiedzieæ, ŋe dane nie są normalne. Moŋemy zidentyfikowaæ te róŋnice, patrząc na 1. Kontrola wzrokowa histogramu 2. Podsumowania numeryczne, takie jak Skoķnoķæ i Kurtoza 3. Podsumowania graficzne (wykres normalnego kwantylu).
1. Miary tendencji centralnej: Istnieją dokģadnie trzy sposoby znalezienia wartoķci centralnej:
Ķrednia arytmetyczna, mediana i tryb.
Ķrednia jest obliczana przez znalezienie sumy danych z badania i podzielenie ich przez caģkowitą liczbę danych. Okreķlenie częstoķci akcji serca jest waŋną częķcią stanu medycznego. Oto wektor zawierający liczbę uderzeņ serca. rytmy <- c (94, 83, 84, 93, 82, 78, 98, 84). Szybkim sposobem oceny naszych danych byģoby uzyskanie ķredniej liczby uderzeņ. Statystycy nazywają to "ķrodkiem". Wywoģaj funkcję ķrednią z uderzeņ serca.
mean(beats)
barplot (beats)
Jeķli narysujemy linię na wykresie reprezentującą ķrednią, moŋemy ģatwo porównaæ róŋne wartoķci ze ķrednią. Funkcja abline moŋe przyjmowaæ parametr h o wartoķci, przy której narysowana zostanie linia pozioma lub parametr v dla linii pionowej. Po wywoģaniu aktualizuje poprzednią fabuģę. Narysuj poziomą linię w poprzek wykresu na ķrodku:
abline (h = mean(beats))
Mediana jest ķrodkową wartoķcią w zestawie danych. Oblicza się go najpierw poprzez uporządkowanie danych w kolejnoķci numerycznej, a następnie zlokalizowanie wartoķci na ķrodku listy. Wežmy przykģad ocen uzyskanych przez grupę studentów. Zaģóŋmy, ŋe egzamin zostaģ przeprowadzony dla 50 znaków.
marks <- c (14, 13, 14, 23, 42, 24, 47, 18)
mean (marks)
Zobaczmy, jak ten nowy ķrodek pokazuje się na tym samym wykresie.
barplot (marks)
abline (h = mean (marks))
Rzeczywiste moŋe byæ stwierdzenie, ŋe nasi uczniowie mają ķrednio 24.375 ocen, ale prawdopodobnie równieŋ wprowadzają w bģąd. W takich sytuacjach prawdopodobnie bardziej przydatne jest mówienie o wartoķci "mediany". Mediana jest obliczana przez sortowanie wartoķci i wybranie ķrodkowej.
Wywoģaj funkcję mediany na wektorze:
median(marks)
Pokaŋmy medianę na wykresie. Narysuj poziomą linię w poprzek wykresu na ķrodkowej.
abline (h = median(marks))
Tryb to liczba, która pojawia się najczęķciej w zbiorze danych.
2. Miary dyspersji: Chcemy dowiedzieæ się, jak rozģoŋyæ dane na podstawie wartoķci centralnej, tj. ķredniej. W tym przypadku chcielibyķmy przyjrzeæ się miarom dyspersji, takim jak zasięg, wariancja, odchylenie standardowe.
Zakres: Aby uzyskaæ zakresu, odejmij najmniejszą liczbę od największej.
Wariancja: Pochodzi z sumy kwadratowej róŋnicy kaŋdej z danych ze ķredniej arytmetycznej danych.
Odchylenie standardowe: wež pierwiastek kwadratowy wariancji, otrzymamy odchylenie standardowe danych. Statystycy uŋywają pojęcia "odchylenie standardowe" od ķredniej, aby opisaæ zakres typowych wartoķci dla zestawu danych. W przypadku grupy liczb pokazuje, jak często róŋnią się one od wartoķci ķredniej. Aby obliczyæ odchylenie standardowe, naleŋy obliczyæ ķrednią wartoķci, a następnie odjąæ ķrednią od kaŋdej liczby i obliczyæ wynik, a następnie uķredniæ te kwadraty i przyjąæ pierwiastek kwadratowy z tej ķredniej. Wež wektor z wartoķciami wynagrodzeņ osób pracujących w dziale.
wynagrodzenie <- c (46000, 50000, 35000, 30000, 44800, 45000, 10200, 15000)
barplot (wynagrodzenie)
meanValue <- mean(wynagrodzenie)
Zobaczmy wykres pokazujący ķrednią wartoķæ:
abline (h = meanValue)
Do obliczenia odchylenia standardowego uŋywamy funkcji sd. Wywoģajmy teraz sd na wektorze wynagrodzeņ i przypiszmy wynik do zmiennej odchylenia.
odchylenie <- sd (wynagrodzenie)
Dodamy linię na wykresie, aby pokazaæ jedno odchylenie standardowe powyŋej ķredniej
abline (h = meanValuæ + odchylenie)
Teraz spróbuj dodaæ linię na wykresie, aby pokazaæ jedno odchylenie standardowe poniŋej ķredniej (dolnej częķci normalnego zakresu):
abline (h = meanValue - odchylenie)
3. Miary lokalizacji: Aby lepiej zrozumieæ dane, obserwujemy nawet miary lokalizacji, takie jak kwartyle, decyle i percentyle, które dzielą dane odpowiednio na 4, 10 i 100 częķci.
4. Ksztaģt rozkģadu: Istnieją dwie statystyki związane z ksztaģtem, skoķnoķcią i kurtozą.
Skoķnoķæ: wykrywa, czy dane są symetryczne względem centralnej wartoķci rozkģadu. Jeķli histogram ma dģugi lewy ogon, nazywamy to danymi ujemnie wypaczonymi, a jeķli histogram ma dģugi prawy ogon, moŋemy powiedzieæ, ŋe dane są wypaczone pozytywnie.
Kurtoza: Jest to miara, która moŋe powiedzieæ o tym, jak pģaskie lub szczytowe są dane. Jeķli wartoķæ kurtozy jest dodatnia, moŋemy zrozumieæ, ŋe dane są leptokurtyczne (szczytowe), jeķli wartoķæ jest ujemna, dane są platykurtyczne (pģaskie). Wartoķæ kurtozy dla rozkģadu mezokurtycznego wynosi zero (normalna). Rozkģad normalny jest asymetryczny, ciągģy rozkģad prawdopodobieņstwa, który jest jednoznacznie okreķlony przez ķrednią i odchylenie standardowe. Kaŋdy rozkģad normalny moŋna przeksztaģciæ w standardowy rozkģad normalny (wynik Z).
UZYSKANIE OPISOWYCH STATYSTYK
Aby obliczyæ konkretną statystykę dla kaŋdej ze zmiennych w zbiorze danych jednoczeķnie, uŋyj funkcji sapply, jeķli w zbiorze danych brakuje jakichkolwiek wartoķci, a następnie ustaw argument na.rm na T:
sapply (Zdrowie, ķrednia, na.rm = T)
Moŋemy zaobserwowaæ niektóre ostrzeŋenia w oknie konsoli, poniewaŋ jeķli dowolna zmienna w zbiorze danych nie jest numeryczna, funkcja sapply zachowuje się niespójnie. Tutaj próbujemy obliczyæ maksymalną wartoķæ dla kaŋdej ze zmiennych w zestawie danych Health. R zwraca komunikat o bģędzie, poniewaŋ kilka zmiennych w zestawie danych to zmienne czynnikowe. Aby uniknąæ tego problemu, wyklucz wszelkie zmienne nienumeryczne z zestawu danych, uŋywając funkcji podzbioru nawiasu. Jeķli chcemy pogrupowaæ wartoķci zmiennej numerycznej zgodnie z poziomami wspóģczynnika i obliczyæ statystyki dla kaŋdej grupy, moŋemy uŋyæ funkcji tapply lub agregacji.
tapply (Zdrowie $ Wiek, Zdrowie $ Pģeæ, ķrednia)
Moŋemy równieŋ uŋyæ funkcji agregującej do podsumowania zmiennych wedģug grup. Korzystanie z funkcji agregującej ma tę zaletę, ŋe moŋna podsumowaæ kilka zmiennych ciągģych jednoczeķnie.
aggregate (pracownik $ wynagrodzenie ~ pģeæ, pracownik, ķrednia)
Ponownie moŋesz takŋe uŋyæ więcej niŋ jednej zmiennej grupującej. Na przykģad, aby obliczyæ ķrednią pensji dla kaŋdej kombinacji pģci i wyksztaģcenia dla zestawu danych pracownika:
aggregate (wynagrodzenie ~ pģeæ + wyksztaģcenie, pracownik, ķrednia)
Aby podsumowaæ dwie lub więcej zmiennych ciągģych jednoczeķnie, zagnieždž je w funkcji cbind.
aggregate (cbind (wynagrodzenie, wiek) ~ poziom, pracownik, ķrednia)
Uzyskaj częstotliwoķæ między tabelami: Tabele tabel lub nieprzewidzianych tabel to rodzaj tabeli, która wyķwietla rozkģad częstotliwoķci zmiennych w wierszu, a druga w kolumnie. Te tabele są szeroko stosowane w Business Analytics, poniewaŋ zapewniają wzajemne powiązania między zmiennymi. Zbudujmy tabelę kontyngencji, uŋywając funkcji tabeli na czynnikach Health $ Gender i Health $ Response Moŋesz generowaæ tabele częstotliwoķci za pomocą funkcji table(), tabel proporcji za pomocą funkcji prop.table(), a częstotliwoķci brzeŋne za pomocą margin.table(). # zbuduj tabelę zdarzeņ awaryjnych w oparciu o pģeæ i czynniki reakcji
Health_table <- table (Health $ Pģeæ, Health $ Response)
Tabela zdrowia
margin.table (Health_table, 1) Częstotliwoķci # A (zsumowane nad B)
margin.table (Health_table, 2) Częstotliwoķci # B (zsumowane nad A)
prop.table (Health_table) # procenty komórek
prop.table (Health_table, 1) # procenty wierszy
prop.table (Health_table, 2) # wartoķci procentowe kolumny
Funkcja summary: Funkcja summary() zapewnia kilka statystyk opisowych, takich jak ķrednia i mediana, dotyczących zmiennej, takiej jak ramka danych Wysokoķæ w zdrowiu. Aby utworzyæ podsumowanie wszystkich zmiennych w zbiorze danych, uŋyj funkcji podsumowania. Funkcja podsumowuje kaŋdą zmienną w sposób odpowiedni dla jej klasy. W przypadku zmiennych numerycznych podaje ķrednią, medianę, zakres i zakres międzykwartylowy. W przypadku zmiennych czynnikowych podaje liczbę w kaŋdej kategorii. Jeķli zmienna ma jakieķ brakujące wartoķci, powie ci ile jest brakujących wartoķci. summary(Zdrowie) zapewni przegląd rozkģadu kaŋdej kolumny. Funkcja summary generuje wszystkie statystyki opisowe związane ze zmienną wysokoķcią w zestawie danych Health. Normalnoķæ rozkģadu implikuje element symetrii związane z dystrybucją. Skoķnoķæ i kurtoza zestawu danych występują w okolicach zera. Podstawowa analiza daje wynik, ŋe zmienna wysokoķæ jest zwykle rozkģadana w zbiorze danych Zdrowie.
UZYSKANIE NIERUCHOMOĶCI STATYSTYCZNYCH
Statystyki wnioskowania odnoszą się do wyciągania wniosków na temat populacji na podstawie danych z próby.
Przedziaģy ufnoķci: Podczas przeprowadzania analizy statystycznej musimy odpowiedzieæ na następujące pytania.
• Jak podaæ oszacowanie przedziaģu (przedziaģ ufnoķci) dla parametrów populacji, takich jak ķrednia?
• Jak skorygowaæ oszacowanie przedziaģu, jeķli odchylenie standardowe populacji nie jest znane?
• Jak obliczyæ przedziaģ ufnoķci dla proporcji populacji?
• Jaka powinna byæ wielkoķæ próbki do pobrania dla poŋądanej szerokoķci oszacowania przedziaģu?
Testowanie hipotez:
1. Czy powinienem obsģuŋyæ ten projekt z jeszcze jednym programistą?
2. Czy powinniķmy otworzyæ nasz nowy sklep detaliczny w lokalizacji X?
3. Czy powinniķmy zatrudniæ tę firmę konsultingową?
4. Czy powinniķmy nabyæ tę linię lotniczą?
5. Czy powinniķmy inwestowaæ w reklamę online?
6. Czy powinniķmy podwyŋszyæ oprocentowanie tej poŋyczki?
7. Czy powinniķmy wejķæ na indyjski rynek detaliczny?
Gdy rozwiązujemy tego rodzaju pytania, moŋe byæ konieczne znalezienie odpowiedzi na kilka dodatkowych pytaņ, takich jak:
• Jak i kiedy formuģowaæ hipotezy dotyczące parametrów populacji?
• Jak obliczyæ siģę dowodów?
• Co to są bģędy typu I i typu II?
Jak sformuģowaæ hipotezę: Hipoteza jest pozycją początkową, która jest otwarta na test i odrzucenie w ķwietle silnych dowodów negatywnych. Początkowe przekonanie nazywa się hipotezą zerową (H0). Na ogóģ status quo mówi: nie rób nic. Jego negacja nazywana jest hipotezą alternatywną (HA, Ha, H1). Często twierdzenie, które naleŋy przetestowaæ, lub zmiana, którą naleŋy wykryæ, mówi: zrób coķ. Te dwie hipotezy wykluczają się wzajemnie i wyczerpują się zbiorowo
Proces testowania hipotez: Rozpocznij od hipotez na temat parametru populacji. Parametrem moŋe byæ ķrednia, proporcja lub coķ innego. Zbierz informacje z losowo wybranej próbki i oblicz odpowiednią statystykę próbki. Odrzucamy / nie odrzucamy hipotezy na podstawie informacji o próbie, jeķli jest ona silnie niezgodna z hipotezą zerową? Jeķli tak, to odrzucona hipoteza.
Przykģad supermarketowego programu lojalnoķciowego: supermarket planuje uruchomiæ program lojalnoķciowy, jeķli spowoduje to, ŋe ķrednie wydatki na kupującego wyniosą ponad 120 USD tygodniowo. Losowa próba 80 kupujących zarejestrowanych w programie pilotaŋowym wydaģa ķrednio 130 USD w ciągu tygodnia ze standardowym odchyleniem 40 USD. Czy naleŋy uruchomiæ program lojalnoķciowy?
Proces testowania
• Zacznij od zaģoŋenia, ŋe H0 (zwykle status quo) jest prawdziwe? : np. Uwaŋam, ŋe wydatki będą mniejsze lub równe 120 USD.
• Okreķl, co naleŋy rozumieæ przez "wystarczająco silny dowód", aby odrzuciæ H0 np. prawdopodobieņstwo znalezienia ķredniej próby powinno byæ mniejsze niŋ 0,05
• Zbierz dowody, które zostaną wykorzystane do przetestowania H0: np. pilotaŋ przyniósģ ķrednie wydatki w wysokoķci 130 USD w próbie 80 klientów
• Oblicz prawdopodobieņstwo zaobserwowania danego lub silniejszego dowodu, np. Maksymalne prawdopodobieņstwo uzyskania próbki o wartoķci 130 USD lub większej w ramach H0 wynosi 0,01
• Zawrzeæ i podjąæ odpowiednie dziaģania? : na przykģad. dowody są wystarczająco silne (0,01 <0,05), aby odrzuciæ H0, a następnie uruchomiæ kartę. Podczas wyciągania wniosków moŋesz popeģniæ dwa rodzaje bģędów:
Decyzja / Rzeczywistoķæ : Nie odrzucaj H0 : Odrzuæ H0
H0 to prawda : Prawidģowa decyzja : Bģąd typu I.
H0 jest faģszem : Bģąd typu II : Prawidģowa decyzja
Prawdopodobieņstwo popeģnienia bģędu typu I jest takie samo jak wartoķæ p. Wartoķæ α moŋna interpretowaæ jako dopuszczalne prawdopodobieņstwo popeģnienia bģędu typu I (zwanego równieŋ poziomem istotnoķci). Hipoteza jest zaģoŋeniem dotyczącym parametru populacji, który podlega testowi i odrzuceniu na podstawie dowodów. Test hipotezy ma zastosowanie, gdy menedŋer zajmuje okreķloną pozycję w parametrze populacji, który naleŋy odrzuciæ, aby podjąæ dziaģanie. Naukowiec danych zazwyczaj atakuje bģąd typu I zwany poziomem istotnoķci. Jeķli obliczone prawdopodobieņstwo danej próbki jest mniejsze niŋ poziom istotnoķci w ramach hipotezy zerowej, odrzuca swoją hipotezę zerową i wprowadza niezbędną zmianę.
TEST CHI-KWADRAT
Test asocjacji chi-kwadrat: Test asocjacji chi-kwadrat pomaga ustaliæ, czy dwie lub więcej zmiennych kategorialnych jest powiązanych. Test ma hipotezę zerową, ŋe zmienne są niezaleŋne, a alternatywną hipotezę, ŋe nie są one niezaleŋne. Test jest odpowiedni tylko wtedy, gdy istnieją wystarczające dane, które są zwykle definiowane jako wszystkie komórki tabeli, które mają oczekiwane, co najmniej pięæ. W przypadku tabel dwukierunkowych moŋna uŋyæ narzędzia chisq.test (moja tabela) do przetestowania niezaleŋnoķci zmiennej wierszowej i kolumnowej. Domyķlnie wartoķæ p jest obliczana na podstawie asymptotycznego rozkģadu chi-kwadrat statystyki testowej.
chisq.test (Zdrowie $ Leczenie, Zdrowie $ Odpowiedž)
Poniewaŋ wartoķæ p jest mniejsza niŋ poziom istotnoķci 0,05, moŋemy odrzuciæ hipotezę zerową i stwierdziæ, ŋe oba są powiązane zmiennymi.
Dokģadny test Fishera: dokģadny test Fishera sģuŋy do testowania powiązania między dwiema kategorycznymi zmiennymi, z których kaŋda ma dwa poziomy. moŋna go uŋywaæ nawet wtedy, gdy dostępnych jest bardzo maģo danych. Test ma hipotezę zerową, ŋe dwie zmienne są niezaleŋne, a alternatywną hipotezę, ŋe nie są one niezaleŋne.
fisher.test (Zdrowie $ Leczenie, Zdrowie $ Odpowiedž)
Do wyników testu doģączony jest 95-procentowy przedziaģ ufnoķci dla ilorazu szans. Moŋesz zmieniæ rozmiar interwaģu za pomocą argumentu conf.level:
fisher.test (Health $ Treatment, Health $ Response, conf.level = 0.99)
fisher.test (x) zapewnia dokģadny test niezaleŋnoķci. x jest dwuwymiarową tabelą kontyngencji w postaci macierzy.
Analiza zmiennych ciągģych: Analizując zmienne ciągģe, moŋemy potrzebowaæ odpowiedzi na kilka pytaņ.
• Jak porównaæ ķrednie z dwóch populacji przy uŋyciu sparowanych obserwacji?
• Kiedy i jak porównaæ dwie populacje oznacza uŋycie niezaleŋnych próbek?
• Jak sprawdziæ róŋnice w dwóch proporcjach populacji?
Przykģad programu redukcji wagi: Ekspert odŋywiania chciaģby oceniæ wpģyw zorganizowanych programów diety na masę uczestników. Losowo wybiera 60 uczestników programu dietetycznego i mierzy ich wagę (w kg) tuŋ przed zapisaniem się do programu i bezpoķrednio po jego zakoņczeniu. Czy na podstawie tych dowodów nowy program diety skutecznie redukuje wagę? Ģaņcuch zdrowia moŋe poleciæ konwencjonalną dietę niskokaloryczną za darmo lub moŋe zaleciæ nową dietę, pģacąc opģatę licencyjną. Firma stwierdziģa, ŋe warto uiķciæ opģatę licencyjną, jeķli zdobędą wystarczającą liczbę dodatkowych czģonków, co jest moŋliwe, jeķli nowa dieta obniŋy ķrednią wagę o 3 kg lub więcej w porównaniu z konwencjonalną dietą niskokaloryczną. Firma zbiera dane na temat odchudzania od dwóch prostych losowych próbek osób, z których jedna przechodzi nową dietę, a druga konwencjonalną dietę przez 6 miesięcy
TEST
Test t dla jednej próbki sģuŋy do porównania ķredniej wartoķci próbki ze staģą wartoķcią oznaczoną m0. Ma hipotezę zerową, ŋe ķrednia populacji jest równa m0, i hipotezę alternatywną, ŋe nie jest.
# Jedna próbka t-test
setwd("D:/R data")
WR_Trt <- read.csv("Wt_red.csv")
fix(WR_Trt)
OS_ttest <- WR_Trt[which(WR_Trt$Treatment=="Dummy Pill"),]
OS_ttest$Change <- OS_ttest$Before-OS_ttest$After
fix(OS_ttest)
OS_tt_res<- t.test(OS_ttest$Change, mu=3)
Argument podaje wartoķæ, z którą chcesz porównaæ ķrednią próbki. Jest opcjonalny i ma domyķlną wartoķæ 0. Domyķlnie R wykonuje test dwustronny. Aby wykonaæ test jednostronny, ustaw alternatywny argument na "większy" lub "mniej". Aby dostosowaæ rozmiar interwaģu, uŋyj argumentu conf.level:
t.test(OS_ttest$Change, mu=1, alternative="greater")
t.test(OS_ttest$Change, mu=1, conf.level=0.99)
Dwupróbkowy test t sģuŋy do porównania ķrednich wartoķci dwóch niezaleŋnych próbek w celu ustalenia, czy są one pobierane z populacji w jednakowych ķrednich wartoķciach. Ma zerową hipotezę, ŋe dwa ķrednie są równe, i alternatywną hipotezę, ŋe nie są równe. Aby wykonaæ test t dla dwóch próbek z danymi w formie stosu, uŋyj polecenia: t.test(values~groups, dataset gdzie wartoķci to nazwa zmiennej zawierającej wartoķci danych, a grupa to zmienna zawierająca nazwy próbek. Jeķli zmienna grupująca ma więcej niŋ dwa poziomy, musisz okreķliæ, które dwie grup
t.test(WR_Trt$Change~WR_Trt$Treatment, WR_Trt, Treatment %in% c("Old_Trt",
"Test_Drug"))
Domyķlnie R uŋywa osobnych oszacowaņ wariancji podczas przeprowadzania testów dwóch prób i sparowanych. Jeķli uwaŋasz, ŋe wariancje dla dwóch grup są równe, moŋesz skorzystaæ z oszacowania ģącznej wariancji. Aby uŋyæ oszacowania wariancji w puli, ustaw argument var.equal na T.
Sparowany test T: sparowany test t sģuŋy do porównania ķrednich wartoķci dla dwóch próbek, gdzie kaŋda wartoķæ w jednej próbce odpowiada okreķlonej wartoķci w drugiej próbce. Ma hipotezę zerową, ŋe dwa ķrednie są równe, a alternatywną hipotezę, ŋe nie są równe.
# paired t-test
t.test(WR_Trt$Before,WR_Trt$After,paired=T)
Jest to naturalne, a takŋe wykonalne przed i po pomiarach na tych samych obiektach, w tym przypadku uŋywamy testu sparowanego.
Rozkģady próbkowania ķrednich dwóch próbek: Dwa rozkģady ķrednich prób są normalne, pod warunkiem ŋe warunek Twierdzenia o granicy centralnej jest speģniony osobno dla 1. Niezaleŋnoķæ taka jak kto jest w próbce nie wpģywa na to, kto jeszcze jest w tej próbce i kto jest w próbce nie wpģywa na to, kto jest w drugiej próbie. 2. Warunki wielkoķci, takie jak Liczba obserwacji w kaŋdej próbce, muszą przekraczaæ 10-krotnoķæ wartoķci bezwzględnej Kurtozy i 10-krotnoķæ kwadratowej Skoķnoķci w tej próbce.
Przykģad: Odsetek dietetyków, którzy tracą na wadze: Zaģóŋmy, ŋe alternatywnym wskažnikiem pomiaru wydajnoķci programu dietetycznego jest odsetek uczestników, którzy stracili więcej niŋ 3 kg. Najlepszym sposobem porównania ķrednich dwóch rozkģadów jest uŋycie sparowanych obserwacji, jeķli jest to wykonalne. Ķrednia róŋnica w sparowanych obserwacjach próbki jest zgodna z rozkģadem normalnym zgodnie z Central Limit Theorem. Gdy sparowane obserwacje nie są moŋliwe, uŋywamy niezaleŋnych próbek i formuģujemy hipotezę dotyczącą róŋnicy między dwoma ķrednimi. Waŋne jest, aby upewniæ się, ŋe badani zostali losowo przydzieleni do dwóch próbek, aby uniknąæ pomyģek. Podobne podejķcie moŋna zastosowaæ do przetestowania róŋnicy proporcji między dwoma.
ANALIZA WARIANCJI (ANOVA)
Analiza wariancji pozwala porównaæ ķrednie z trzech lub więcej niezaleŋnych próbek. Jest odpowiedni, gdy wartoķci są rysowane z rozkģadu normalnego i gdy wariancja jest w przybliŋeniu taka sama w kaŋdej grupie. Hipoteza zerowa dla testu jest taka, ŋe ķrednia dla wszystkich grup jest taka sama, a alternatywna hipoteza jest taka, ŋe ķrednia jest róŋna dla co najmniej jednej pary grup. Zastanówmy się nad następującymi pytaniami i spróbuj odpowiedzieæ na nie w studium przypadku.
• Dlaczego do porównania ķrednich populacji wymagana jest analiza wariancji (ANOVA)?
• Jaka jest zasada sumy kwadratów?
• Jak przeprowadziæ test ANOVA?
• Jaką dalszą analizę naleŋy wykonaæ, jeķli test ANOVA jest istotny?
Studium przypadku: Program redukcji wagi: Zaģóŋmy, ŋe ekspert odŋywiania chciaģby dokonaæ oceny porównawczej trzech programów dietetycznych. Losowo przypisuje równą liczbę uczestników do kaŋdego z tych programów ze wspólnej puli wolontariuszy. Zaģóŋmy, ŋe ķrednie straty masy w kaŋdej grupie (ramionach) eksperymentów wynoszą 4 kg, 7 kg, 5,4 kg. Co ona moŋe wyciągnąæ? Tutaj waŋne są dwa rodzaje zmian. Nie kaŋda osoba w kaŋdym programie zareaguje identycznie na program diety. Ģatwiej jest zidentyfikowaæ zmiany w róŋnych programach, jeķli zmiany w programach są mniejsze, dlatego metoda nazywa się Analiza wariancji (ANOVA). Formalizowanie intuicji stojącej za wariacjami. Bardziej zaskakujące i przydatne jest: Suma kwadratów ogóģem (SST), Suma kwadratów Leczenie (SSTR), Suma kwadratów Bģąd (SSE)
Test statystyczny pod kątem równoķci ķrednich:
n przedmiotów równo podzielonych na r grupy
Hipotezy: H0: ?1 = ?2 = ?3 =
= ?r. Odrzuæ hipotezę zerową, jeķli wartoķæ p
aov(Change~Treatment, WR_Trt)
Wyniki analizy skģadają się z wielu komponentów, których R nie wyķwietla automatycznie. Jeķli zapiszesz wyniki w obiekcie, jak pokazano tutaj, moŋesz uŋyæ dalszych funkcji, aby wyodrębniæ róŋne elementy wyniku:
aovobject<-aov(Change~Treatment, WR_Trt)
#Once zapisaniu wyników jako obiekt moŋesz wyķwietliæ tabelę ANOVA z funkcją anova:
anova (aovobject)
# Aby wyķwietliæ wspóģczynniki modelu, uŋyj funkcji coef:
coef (aovobject)
# Aby wyķwietliæ przedziaģy ufnoķci dla wspóģczynników, uŋyj funkcji confint:
confint (aovobject)
# One Way Anova (caģkowicie losowy projekt)
fit <- aov (Zmiana ~ Leczenie, WR_Trt)
Tabela ANOVA: Jeķli odrzucimy hipotezę zerową, ŋe wszystkie ķrednie są równe, prawdopodobieņstwo popeģnienia bģędu wynosi mniej niŋ 2,5%. Czy moŋemy stwierdziæ, ŋe dieta testowa jest bardziej skuteczna niŋ stara dieta ?. Zakres zmiennoķci między grupami i wewnątrz grup determinuje siģę dowodów w stosunku do hipotezy zerowej, ŋe ķrednie wszystkich grup są równe. Suma kwadratów odchyleņ (wokóģ ķredniej ķredniej) jest równa sumie bģędów kwadratów odchyleņ (wokóģ odpowiednich ķrednich grup) plus suma leczenia odchyleņ kwadratu (grupa oznacza wokóģ wielkiego ķrodka). Test ANOVA porównuje ķrednie kwadratowe leczenie ze ķrednimi kwadratowymi bģędami. Jeķli stosunek ten jest "znacznie" większy, moŋemy odrzuciæ hipotezę zerową, ŋe ķrednie są równe.
KROK 6
Machine Learning
WPROWADZENIE
Czy kiedykolwiek myķlaģeķ, ŋe Maszyny mogą uczyæ się i organizowaæ pracę bardziej konsekwentnie niŋ Ty? Czy kiedykolwiek myķlaģeķ o tych pytaniach?
• Jakie zadania są dobre do wykonania przez maszyny, które dla ludzi nie są dobre lub odwrotnie
• Co to oznacza uczenie maszynowe?
• Jak nauka wiąŋe się z inteligencją? Czy czģowiek moŋe naprawdę stworzyæ Inteligentne Maszyny, które mogą przewyŋszyæ Czģowieka na wiele sposobów? Co to znaczy byæ inteligentnym?
• Czy wierzysz, ŋe kiedykolwiek zostanie zbudowana maszyna ujawniająca inteligencję?
• Co to znaczy byæ ķwiadomym, czy moŋna byæ inteligentnym i nieķwiadomym lub odwrotnie?
Kiedy widzimy wiele danych, nie jesteķmy pewni, czego szukaæ i co tam jest, i co zostanie znalezione. Miej to na uwadze, uczenie się to nie tylko podejķcie do ŋycia, ale takŋe podejķcie do eksploracji danych i uczenia maszynowego, zawsze podchodzimy do danych i uczenia maszynowego z takim podejķciem, które zaprowadzi Cię bardzo daleko. Omówmy filozofię uczenia się, uczymy się na wiele sposobów. Uczymy się przez asymilację, czytamy duŋo ksiąŋek, oglądamy duŋo filmów, sģuchamy piosenek, to jest asymilacja. Rzeczy, których się uczymy, muszą byæ zastosowane, w przeciwnym razie zapomnimy, stosujemy te rzeczy, robiąc i omawiając. Ten tekst będzie zawieraģa zarówno teoretyczne, jak i praktyczne scenariusze, postaramy się zastosowaæ niektóre rzeczy tutaj do rzeczywistych zestawów danych, moŋesz uŋyæ dowolnego języka, jakiego potrzebujesz, dowolnego ulubionego narzędzia (uŋywam R jako narzędzia), stosujemy rzeczy, których się nauczyliķmy. Po skoņczeniu aplikacji moŋemy przejķæ do dostosowywania wszystkiego, czego się nauczyģeķ i stworzyæ coķ nowego. Po wypeģnieniu tego tekstu chcę, takie jakieķ stwierdzenie : Wiedza jest tym, co pozostaģo po zapomnieniu faktów. Ten tekst nie dotyczy uczenia się okreķlonych formuģ, ale tak naprawdę dotyczy pojęæ. Zajmę się tematami z róŋnych dziedzin, róŋnymi problemami rozwiązanymi za pomocą uczenia maszynowego. Ten tekst pomoŋe Ci zrozumieæ, jakie są róŋne algorytmy uczenia maszynowego, których uŋywamy w branŋy do rozwiązywania problemów biznesowych. Są trzy I, które stworzą ķwietny produkt. Spójrzmy na radio i telewizję, byģy ķwietnymi produktami swoich czasów, ale dziķ zobaczmy, jakie cechy sprawiają, ŋe produkt jest ķwietny. Pierwsze I to Interfejs produktu. Czy muszę czytaæ instrukcję obsģugi produktu, czy mój produkt moŋe obsģugiwaæ 5-latek lub nawet 70-letni facet, pole wyszukiwania Google to przykģad ķwietnego interfejsu. Następne I to Infrastruktura, budujemy produkty nie na komputery PC. Nastąpiģa zmiana paradygmatu, wczeķniej ludzie budują produkty takie jak Windows O/S, Outlook, wszystkie te są przeznaczone na komputery PC. Jeķli spojrzysz na LinkedIn, YouTube, Google, Facebook, są to produkty stworzone dla ķwiata, z których mogą korzystaæ miliardy ludzi na caģym ķwiecie. Trzecie I , aby stworzyæ ķwietny produkt, to Inteligencja. Jeķli spojrzysz na wyszukiwanie w Google i wpiszesz zapytanie, ma ono pewną autosugestię. Kiedy na nie patrzysz, masz wraŋenie, ŋe Google czyta w twoich myķlach, filmy z YouTube'a podczas oglądania, sugerują podobne filmy, czujesz, ŋe produkt jest inteligentny. LinkedIn, Amazon, Netflix, kiedy z nich korzystasz i przeglądasz rekomendacje, które uwaŋamy za bardzo inteligentne. Ta funkcja jest znana jako sztuczna inteligencja, bez której produkty te mogą nie odnieķæ takiego sukcesu. Tak więc, ilekroæ myķlisz o zbudowaniu nowego produktu, pomyķl w ten sposób, ŋe powinien on zawieraæ wszystkie Trzy Ja. Moja ksiąŋka dotyczy częķci Inteligencji i zawsze dyskutujemy o tym, jak stworzyæ Inteligentny produkt za pomocą uczenia maszynowego
DLACZEGO UCZENIE MASZYNOWE?
Uczenie maszynowe, sztuczna inteligencja, eksploracja danych, analiza duŋych zbiorów danych - wszystko to wygląda podobnie i prawie dotyczy tego samego. Moŋe istnieæ niewielka róŋnica w podejķciu i nakģadaniu się między nimi, ale wszystko, co musisz zrozumieæ, to wszystko to samo. Uczenie maszynowe jest tradycyjnym terminem uŋywanym i uŋywamy tego samego terminu. Pozwólcie, ŋe przedstawię perspektywę uczenia maszynowego: wezmę przykģad rankingu stron internetowych. Jest to proces przesģania zapytania do wyszukiwarki, która następnie wyszukuje strony internetowe powiązane z zapytaniem i zwraca je w odpowiedniej kolejnoķci. Aby osiągnąæ ten cel, wyszukiwarka musi "wiedzieæ", które strony są trafne, a które pasują do zapytania. Taką wiedzę moŋna uzyskaæ ze struktury linków stron internetowych, ich zawartoķci, częstotliwoķci, z jaką uŋytkownicy będą podąŋaæ za sugerowanymi linkami w zapytaniu. Filtrowanie grupowe to kolejna aplikacja do uczenia maszynowego, sklep e-commerce, taki jak Amazon, intensywnie wykorzystuje te informacje, aby zachęciæ uŋytkowników do zakupu dodatkowych towarów. Spójrzmy na filtrowanie spamu, jesteķmy zainteresowani odpowiedzią tak / nie, czy e-mail zawiera odpowiednie informacje, czy nie. Jest to caģkowicie zaleŋne od uŋytkownika: w przypadku często podróŋujących wiadomoķci e-mail od linii lotniczych informujące go o ostatnich zniŋkach mogą okazaæ się cennymi informacjami, podczas gdy dla wielu innych odbiorców moŋe to byæ bardziej uciąŋliwe. Aby zwalczyæ te problemy, chcemy zbudowaæ system, który będzie w stanie nauczyæ się klasyfikowaæ nowe wiadomoķci e-mail. Spójrzmy na diagnozę raka, ma wspólną strukturę, która biorąc pod uwagę dane histologiczne tkanki pacjenta, moŋemy wnioskowaæ, czy pacjent jest zdrowy, czy nie. Tutaj nawet jesteķmy proszeni o wygenerowanie odpowiedzi tak / nie na podstawie zestawu obserwacji. wszyscy pracujemy dla róŋnych firm, widzieliķmy okreķloną iloķæ danych, jeķli cofniesz się i spojrzysz na to, co robi ķwiat, to po prostu cudowne, ŋe zebrali wiele danych, jeķli spojrzysz na sekwencję genów, projekt genomu czģowieka, ludzi są zebrane sekwencje genów kaŋdego organizmu, jest to miliard sekwencji, które musisz przeanalizowaæ, teraz moŋesz sobie wyobraziæ, ile to danych. Za kaŋdym razem, gdy przesuwasz kartę kredytową lub debetową, tworzysz duŋo danych, Za kaŋdym razem, gdy kupujesz lub sprzedajesz akcje, generowany jest punkt danych, za kaŋdym razem, gdy piszesz ksiąŋkę lub dokument prawny, lub gdy wysyģasz satelitę, te satelity gromadzą wszelkiego rodzaju dane. Pozwólcie, ŋe dam trochę pojęcia o Big Data, kaŋdego dnia odbywa się prawie 200 milionów tweetów i istnieje okoģo 500 milionów kont na Twitterze. Uŋytkownicy YouTube przesyģają 100 godzin filmów co minutę, w Internecie co minutę powstaje 800 nowych stron internetowych, Facebook przetwarza 100 terabajtów danych kaŋdego dnia, co miesiąc udostępnianych jest 30 miliardów elementów, co daje ponad 30 petabajtów danych uŋytkownika. Google przetwarza 20 petabajtów danych dziennie, chodzi o indeksowanie sieci, indeksowanie sieci itp. Wal-Mart ponad 1 milion transakcji klientów co godzinę, to zupeģnie nowy ķwiat, w którym ŋyjcie w arkuszach kalkulacyjnych Excel, nie wystarczy, ŋe nie moŋna zaģadowaæ danych do komputera, przetwarzaæ danych za pomocą komputera i tworzyæ wglądu w dane, nie jest to moŋliwe. Zastanówmy się, jak się tu dostaliķmy? Nie dotarliķmy tu przypadkiem, wiele rzeczy musiaģo się tu dostaæ, ta eksplozja danych jest moŋliwa dzięki lepszym czujnikom, kiedy mówię czujnik, wszystko, co zbiera punkt danych, to czujnik, termometr to czujnik, GPRS w samochodzie jest czujnikiem, nawet my jesteķmy czujnikami, za kaŋdym razem, gdy generujemy punkty danych, kiedy wykonujesz poģączenie z telefonu, tworzysz dane, za kaŋdym razem, gdy przesuwasz kartę, generujesz dane, chcę, abyķ wyobraziģ sobie nowy ķwiat, w którym ŋyjemy. Po zebraniu danych, kiedy uzyskujemy pewne statystyki, nadal jesteķmy w stanie wygenerowaæ wiele statystyk, raportów i histogramów, ale to nie jest inteligencja. To są obliczenia brutalnej siģy, musimy zdawaæ sobie sprawę ze wszystkich rzeczy, które robimy. Eksperci od uczenia maszynowego myķlą o futurystycznych rzeczach, twierdzą, ŋe nasza technologia jest taka, ŋe nasze maszyny są częķcią ludzkoķci. Stworzyliķmy je, aby się rozwijaæ, co jest wyjątkowe w ludziach. To stwierdzenie jest prawdziwe przez caģy czas, jeķli spojrzysz na nagich ludzi, stworzyli narzędzia do polowania, wymyķlili ogieņ, stworzyli koģa, chcemy zobaczyæ bardzo daleko wynaleziony teleskop, chcieliķmy zobaczyæ bardzo maģy tak wynaleziony mikroskop, cokolwiek stworzymy, jak samoloty, džwigi, ma się rozszerzyæ. To czego nie przedģuŋono, co zawsze chcemy stworzyæ i wciąŋ nie odnosimy sukcesów, jest nasz mózg, kiedy patrzę na problem, jak go rozwiązaæ, kiedy zobaczyliķmy obraz, jak to zrobiæ rozpoznajemy to? Teraz naszym celem jest stworzenie maszyny, która jest inteligentna, nie tylko kalkulator, nie tylko przechowuje duŋo danych, nie tylko zģoŋony program, ale w jaki sposób uczyniæ inteligentną maszynę tak inteligentną jak ludzki mózg. Spójrzmy nawet na ewolucję komputerów, wyobraž sobie, ŋe pierwszy komputer zostaģ stworzony tak ,ŋe musisz wejķæ do komputera, podģączyæ przewody, aby programowaæ. Potem wymyķlono komputery IBM, potem laptopy, od jednego komputera uniwersyteckiego do jednego komputera w kaŋdym domu, dzięki IBM i Microsoft, posiadanie komputera w domu to ich wizja. Jaka jest kolejna ewolucja informatyki? Przetwarzanie w chmurze to kolejna ewolucja. Jest to centrum danych, pģyty gģówne są poģączone jeden po drugim w szafie, nie potrzebujemy do nich monitora ani klawiatury. Wszystkie dane generowane przez Amazon, YouTube, LinkedIn, Twitter, Facebook itp. znajdują się w centrum danych. Jaka jest przyszģoķæ. Przyszģoķciąæ nazywamy komputere kwantowy, wykraczającym poza tradycyjny rodzaj obliczeņ, który wykorzystuje stany kwantowe atomu do obliczeņ i przechowywania informacji. Caģe centrum danych moŋe zmieķciæ się w tym komputerze kwantowym, więc moŋesz sobie wyobraziæ przyszģoķæ komputerów. Porównaj pierwszy komputer z komputerem kwantowym, oba wyglądają na niezdarne, ale ten drugi jest bilion razy szybszy niŋ pierwszy komputer. W najbliŋszych dniach moŋemy mieæ miniaturę komputerów kwantowych, a centra danych komputera kwantowego zastanawiają się, co się stanie. Trzeba pamiętaæ, ŋe moc obliczeniowa roķnie w ogromnym tempie wykģadniczym, a my moŋemy sobie poradziæ z danymi bez względu na rozmiar. Spójrzmy na ewolucję technologii informacyjnej. Podzieliģem je na trzy częķci. Pierwsza to era indeksowania, w której jedyne, co musieliķmy zrobiæ, to znaležæ sposób na zebranie danych, przechowywaæ je w bazie danych w taki sposób, abyķmy mogli je pobraæ za pomocą zapytania SQL. To byģa era indeksowania, tutaj nawet nowoczesne wyszukiwarki naleŋą do tej kategorii, nawet wyszukiwarka Google to gigantyczny system indeksowania, kluczem jest sģowo, a wartoķæ to dokument zawierający wszystkie sģowa, ale w gruncie rzeczy to nic więcej niŋ system SQL. Ludzie pytali o podstawowe pytania, takie jak czy mogę wziąæ ķrednią wszystkich osób pracujących w dziale lub w okreķlonej technologii z okreķlonym wieloletnim doķwiadczeniem. Wģaķnie tam zakoņczyģ się system indeksowania. Następna era to era interpretacji, w tej erze myķleliķmy, ŋe powinienem móc zinterpretowaæ dane w bardzo interesujący sposób, czy istnieje jakiķ ukryty wzorzec w danych, czy dane mówią coķ, czego nie jestem ķwiadomy, oto co to nauka bez nadzoru, której się nauczymy. Chodzi o to, aby wyjķæ poza zapytania i pozwoliæ, aby dane mówiģy o tym, co ma, poniewaŋ zadaję więcej pytaņ niŋ proste zapytanie. Widzimy wiele przykģadów na ten temat w caģym tekķcie. Następna era to era inteligencji, w której podejmujemy decyzje. Czy mogę korzystaæ z moich danych, nie tylko jako bazy danych, czy mogę równieŋ przewidywaæ przyszģoķæ ?, Czy ten klient zamierza odejķæ ?, Którą osobę polecisz na LinkedIn w przyszģoķci ?, Jaki jest nowy produkt, który powinienem stworzyæ dla rynku ?, Jak mogę podjąæ decyzję na podstawie moich przeszģych doķwiadczeņ, we wszystkich danych, które miaģem? W erze inteligencji nadzorowane uczenie się i optymalizacja upadną. Istnieją dwa cele uczenia maszynowego. Do tej pory rozumiemy, ŋe jesteķmy w ķwiecie bogatym w dane i musimy coķ zrobiæ z tymi danymi. Uczenie maszynowe jest na to sposobem.
JAK DZIAĢA UCZENIE MASZYNOWE?
Aby to zrozumieæ, musimy pomyķleæ o naturze umysģu? Czy chcemy zrozumieæ, jak dziaģa umysģ? Czym jest inteligencja? Czego się uczysz? Co myķlisz? Na przykģad mogę zbudowaæ system OCR do odczytu znaków tekstowych ksiąŋki, ale czy on rozumie tekst. Czy moŋemy przejķæ od czytania tekstu do rozumienia tekstu? Czy moŋemy przejķæ od sģuchania do sģuchania i rozumienia džwięku? Czy telefon komórkowy, kamera wideo, której uŋywasz do robienia zdjęæ lub filmów, mogą je zrozumieæ i zinterpretowaæ jako jak lubisz? Jak moŋemy rozszerzyæ maszyny na ten poziom? To jeden z celów Sztucznej Inteligencji. W 1950 roku Alan Turing przyszedģ ze swoim testem. Jak moŋemy powiedzieæ, ŋe maszyny są inteligentne? Wymyķliģ ciekawy test zwany testem Turinga, w zasadzie test polega na tym, czy dana osoba rozmawia z dwoma polami czatu, jeden z czatów jest podģączony do komputera drugi z prawdziwą osobą, osobą. Celem jest okreķlenie, który jest maszyną, a którnie, jeķli osoba A nie moŋe powiedzieæ, ŋe rozmawia z maszyną lub osobą, moŋemy powiedzieæ, ŋe osiągnąģ poziom sztucznej inteligencji. Obecnie mówimy o naszej wyszukiwarce Google, bardzo ostroŋnie wybieramy sģowa kluczowe, zachowujemy kolejnoķæ, poniewaŋ moŋe on rozumieæ tylko zapytania oparte na sģowach kluczowych, nie moŋe zrozumieæ pytaņ i zapomnieæ o rozmowach. Chcemy ewoluowaæ od sģów kluczowych po pytania, a nawet rozmowy. Firmy takie jak Google starają się rozwiązaæ ten problem i stworzyæ maszynę tak dobrą jak ludzki mózg. Drugim celem uczenia maszynowego są decyzje oparte na danych. Pozwólcie, ŋe podam kilka przykģadów, w jakiej pozycji reklama / strona ma byæ wyķwietlana dla danego zapytania?. Czy powinienem zatwierdziæ tę poŋyczkę mieszkaniową, czy nie? Który film pokaŋe się następnie na YouTube? Firmy muszą odpowiedzieæ na wszystkie te pytania, to nie jest jedna wielka decyzja, wszystkie są mikro decyzjami, które naleŋy podjąæ kilka razy. Celem jest podejmowanie decyzji w sposób bardziej systematyczny, bardziej zorganizowany. Powinieneķ spojrzeæ na swoją firmę i zobaczyæ, jakie decyzje podejmują twoje firmy, czy są one oparte na odczuciu, czy są oparte na wczeķniejszych studiach przypadków, czy naprawdę są oparte na danych? Musimy sprawdziæ, czy mamy wystarczającą iloķæ danych, aby podjąæ decyzję, jak mierzymy i zatwierdzamy decyzję, to wģaķnie jest celem tego kursu, aby uczyniæ cię lepszym naukowcem danych, który moŋe gromadziæ dane i konwertowaæ je na problem badawczy, opracowywaæ modele, wdraŋaæ modele itp., Nauka o danych jest kombinacją trzech rzeczy: 1. Dane 2. Algorytmy ML 3. Domena wiedzy. Kaŋdy z nas moŋe byæ silny w jednej lub dwóch i musimy wybraæ innąh, aby zostaæ naukowcem danych. Wyobraž sobie, ŋe jeķli jesteķ absolwentem informatyki, z przyjemnoķcią poradzisz sobie z algorytmami, stosując algorytmy do zestawów danych dostarczonych przez klienta, ale kiedy przychodzisz do prawdziwego ķwiata, zajmowanie się danymi jest ogromnym problemem. Spróbujmy zrozumieæ sģowo Data Mining, Mining to proces poszukiwania diamentów w ogromnej masie kamieni. W rzeczywistoķci dane są skąpe, na wiele sposobów nawet nie moŋesz sobie wyobraziæ. Musimy zrozumieæ, ŋe dane nie są proste, jak zakģadamy. To jest jak twój 2-letni dzieciak. Lubisz go, ale robi wiele rzeczy, z których nie jesteķ zadowolony. Nie zachowuje się tak, jak chcesz. Zaģóŋmy, ŋe jesteķmy silni zarówno w zakresie algorytmów danych, jak i uczenia maszynowego, które wciąŋ musimy wiedzieæ jak zastosowaæ je wszystkie w rzeczywistych sytuacjach, poniewaŋ dane w róŋnych domenach zachowują się inaczej. Domena wiedzy odgrywa bardzo waŋną rolę w Data Science. Tylko wtedy, gdy masz silną domenę, zrozumiesz, którego parametru szukaæ , jakiego rodzaju funkcji szukaæ. Zrozumiaģem, ŋe wszystkie te trzy elementy odgrywają istotną rolę w Data Science. Ludzie, którzy są silni we wszystkich tych trzech, będą nazywani naukowcami danych. Mam nadzieję, ŋe po przeczytaniu tego tekstu staniesz się silny we wszystkich trzech rzeczach.
RODZAJE NAUCZANIA MASZYNOWEGO
Uczenie się bez nadzoru: Otrzymaģeķ mnóstwo danych, nie powiedziano ci, czego szukaæ? Teraz moŋesz byæ bardziej kreatywny. Wyobraž sobie, ŋe dostarczyģeķ swojemu dziecku papier, szkicowniki i wszystkie inne rzeczy i poprosiģeķ go, aby coķ narysowaģ. Potrafi byæ bardzo kreatywny i rysowaæ, co mu się podoba, i wyjaķnia, co to za rysunek. To jest nauka bez nadzoru. W tym przypadku staramy się znaležæ strukturę i gramatykę w danych, abyķmy mogli je wyczuæ. W uczeniu się bez nadzoru, to nad czym pracujemy, to dane nieoznakowane. Wyobraž sobie, ŋe daģem Ci wszystkie filmy z YouTube, który film jest oglądany ile razy, i kto oglądaģ, który film, ale nie powiedziaģem, co z tym zrobiæ, staje się to problemem bez nadzoru.
Nadzorowane uczenie się: wyobraž sobie, ŋe twoje dziecko po prostu do ciebie wraca i pyta, co narysowaæ? Jeķli podasz kolejne dane wejķciowe, takie jak narysuj Drzewo lub narysuj Dom, wówczas będzie to nadzorowane uczenie się. Oznacza to, ŋe nauka nadzorowana ma miejsce wtedy, gdy wiesz, czego szukaæ. W uczeniu nadzorowanym oznaczyliķmy dane danymi i staramy się znaležæ zarówno strukturę, jak i zmienną, która powoduje drugą zmienną (struktura i przyczynowoķæ) poprzez budowanie modeli. Kiedy budujesz model, który mówi przewidywanie oszustwa, przewidywanie odejķcia klienta, przewidywanie następnego filmu na youtube, który klient obejrzy, przewidywanie rekomendacji LinkedIn, przewidywanie raka, kiedy podasz bardzo konkretny problem, wówczas stanie się on nadzorowanym nauczaniem. Pomyķlmy o uczeniu się bez nadzoru, wyobraž sobie, ŋe zaczynasz nową dziaģalnoķæ, przejrzaģeķ róŋne studia przypadków i odkryģeķ 20 problemów z CRM (zarządzanie relacjami z klientami), teraz moŋemy pracowaæ nad tymi 20 problemami z CRM i moŋemy się cieszyæ, ŋe znalazģeķ odpowiedzi na wszystkie problemy. Ale czy moŋesz się z nimi dobrze czuæ? Czy mamy gwarancję, ŋe nie będzie ŋadnych innych problemów? Jaki jest problem z tym podejķciem? Wyobražmy sobie, ŋe wszystkie studia przypadków znajdują się w krajach zachodnich i chcesz je zastosowaæ w Indiach. Problemy w Indiach byģyby bardzo trudne i mogą byæ bardzo róŋne. Wyobraž sobie, dlaczego Amazon nie mógģ pracowaæ w Indiach takimi, jakimi są? Poniewaŋ w Indiach Fabmart (wiele osób uwaŋa, ŋe Flipkart) wprowadziģ nową koncepcję zwaną pobraniem (COD), bez tej opcji, w Indiach Amazon nie odniósģby sukcesu. Musimy więc byæ pokorni w zakresie wiedzy o Twojej dziedzinie. musimy sprawdziæ, czy dane coķ do Ciebie mówią, tam się otwieramy i powiedzieæ, ŋe pozwolę sobie na naukę bez nadzoru. Pozwól mi zobaczyæ, co mówią dane poza tym, co myķlaģeķ.
Uczenie częķciowo nadzorowane: w tego rodzaju uczeniu otrzymujesz dane oznaczone i nieznakowane, iloķæ oznaczonych danych jest mniejsza w porównaniu z caģkowitą iloķcią danych. Uczenie częķciowo nadzorowane polega na tym, jak wykorzystaæ uczenie się bez nadzoru w poģączeniu z oznaczonymi danymi, aby zbudowaæ jeszcze lepszy model.
Aktywne uczenie się : powiedzmy, ŋe mamy 2000 przykģadów oznakowanych danych, proces etykietowania jest bardzo kosztowny, muszę wybraæ następnego faceta z 10 milionów przykģadów, które wciąŋ nie są oznaczone, muszę wybraæ kolejne 20 zdjęæ, poniewaŋ mam po prostu ograniczenia, takie jak finansowanie i czas, które przykģady powinienem oznaczyæ jako pierwszy? Poniewaŋ to okreķli następny model, który zbudujesz. Nazywa się to aktywnym uczeniem się.
Uczenie się ze wzmocnieniem: W tego rodzaju uczeniu się nie budujemy modelu, który odwzorowuje od A do B, ale budujemy model, który odwzorowuje caģą sekwencję dziaģaņ na wynik. Podobnie jak w szachach, kaŋda pozycja figury okreķla, czy wygrasz, czy przegrasz. Nie moŋesz oceniæ pojedynczego kroku, ale moŋesz oceniæ caģą grę jako jednostkę. Wyobraž sobie scenariusz bankowy, w którym ocenia swoich klientów na podstawie sekwencji dziaģaņ od otwarcia konta do zamknięcia konta. Seria dziaģaņ staje się prowadziæ do lojalnoķci klienta lub rezygnacji. W koņcu, gdy się odejdzie, zrozumiesz, ŋe jedno lub więcej dziaģaņ w tej sekwencji byģo niewģaķciwych. Oznacza to, ŋe pracujesz nad serią decyzji, a nie jedną. Pozwól mi wziąæ przykģad sģów reklamowych Google, wchodzisz, otwierasz firmę, otwierasz konto sģów reklamowych i okreķlasz te sģowa kluczowe, których chcemy uŋywaæ w mojej firmie. Teraz dzieje się wiele oszustw, co się dzieje, ludzie uŋywaj sģów takich jak Mahatma Gandhi w sklepie z zabawkami, dlaczego? klient zastosowaģ tę sztuczkę? wiesz, ŋe to dobre zapytanie, gdy jest dobre, pojawi się moja reklama, ale nie ma to znaczenia. Teraz istnieją dobre algorytmy uczenia maszynowego, które okreķlają, czy sģowo kluczowe jest odpowiednie dla firmy, czy nie. Ale czasami decyzje byģy bardzo niejasne. Teraz algorytm uczenia maszynowego nie moŋe daæ ci rozwiązania, musisz podjąæ ostateczne wezwanie, poniewaŋ model uczenia maszynowego nie jest w stanie podjąæ decyzji. Wtedy dzieje się duŋo aktywnego uczenia się. Musimy więc zrozumieæ, ŋe nie ma systemu opartego wyģącznie na uczeniu maszynowym, zawsze ģączymy uczenie maszynowe z ludzkim myķleniem. Automatyzujemy, ale kiedy maszyna nie jest pewna, co robiæ, uŋywamy ludzkiego myķlenia.
KROK 7
Redukcja Wymiarów
WPROWADZENIE
Jeķli mam setki zmiennych, tworzenie wykresów rozrzutu i znajdowanie relacji między zmiennymi nie jest takie ģatwe. Aby zrozumieæ dane, co moŋemy zrobiæ poza wykresami rozrzutu? Robimy redukcję wymiarów, w zasadniczy sposób i jeden z najczęķciej uŋywanych algorytmów zwany analizą gģównych skģadników. Przy duŋej liczbie zmiennych macierz dyspersji moŋe byæ zbyt duŋa, aby wģaķciwie badaæ i interpretowaæ. Par byģoby zbyt wiele aby korelacje między zmiennymi do rozwaŋenia. Graficzne wyķwietlanie danych moŋe równieŋ nie byæ szczególnie pomocne w przypadku, gdy zestaw danych jest bardzo duŋy. Aby interpretowaæ dane w bardziej sensownej formie, konieczne jest zatem zmniejszenie liczby zmiennych do kilku, moŋliwych do interpretacji, liniowych kombinacji danych. Kaŋda kombinacja liniowa będzie odpowiadaæ elementowi gģównemu. Kiedy mamy do czynienia z sytuacją, w której mamy ogromny zestaw funkcji z mniejszą liczbą punktów danych, w tej sytuacji dopasowanie modelu moŋe skutkowaæ niŋszą mocą prognozowania. Nazywa się to Klątwą Wymiarów. Tutaj rozwiązaniem moŋe byæ dodanie większej liczby punktów danych lub zmniejszenie przestrzeni funkcji. Nazywa się to redukcją wymiarowoķci.
TECHNIKI REDUKCJI RÓŊNEJ WYMIAROWOĶCI
Kiedy mamy do czynienia z ogromnymi danymi, nie jesteķmy pewni przydatnoķci zebranych informacji. Mamy więc tendencję do usuwania niektórych zmiennych, zakģadając, ŋe nie są one tak naprawdę przydatne. To moŋe nie byæ poprawnym podejķciem, poniewaŋ dostępnych jest niewiele technik do ģączenia tych zmiennych razem i tworzenia nowego czynnika lub gģównego skģadnika. Istnieje wiele technik, których moŋemy uŋyæ do redukcji wymiarów
1. Analiza czynnikowa,
2. Analiza gģównych skģadników,
3. Analiza dyskryminacyjna. itp.
Będziemy teraz badaæ ten algorytm. Pozwól nam zrozumieæ, dlaczego przeprowadzamy analizę gģównych skģadników. Analiza gģównego skģadnika jest jedną z metod stosowanych do zrozumienia struktury danych, ksztaģtu danych, kowariancji danych, co nie jest moŋliwe w przypadku prostych wykresów rozrzutu. Analiza czynnikowa jest pomocna w następujących przypadkach:
• Kiedy mamy duŋą liczbę zmiennych w naszym zbiorze danych i musimy zmniejszyæ tę liczbę.
• Przed wykonaniem analizy regresji lub analizy skupieņ na zbiorze danych ze skorelowanymi zmiennymi.
• Podczas analizy wyników ankiety, w których odpowiedzi na wiele pytaņ wydają się byæ wysoce skorelowane.
Przed wykonaniem redukcji wymiarów musimy sprawdziæ, czy wymagana jest redukcja wymiarów, sprawdzając wspóģliniowoķæ. Redukcję wymiarów wykonujemy w przypadku naruszenia zaģoŋeņ OLS z powodu wspóģliniowoķci. W redukcji wymiarowoķci moŋemy zastosowaæ 1. podejķcie do ekstrakcji cech lub 2. podejķcie do wyboru cech
WSPÓĢLINIOWOĶÆ
Wspóģliniowoķæ oznacza, ŋe zmienne niezaleŋne są ze sobą wysoce skorelowane. W analizie regresji waŋne jest zaģoŋenie, ŋe model regresji nie powinien mieæ do czynienia z problemem wspóģliniowoķci.
Dlaczego wspólliniowoķæ jest problemem? : Jeķli celem badania jest sprawdzenie, w jaki sposób zmienne niezaleŋne wpģywają na zmienną zaleŋną i jeķli te zmienne wyjaķniające są silnie skorelowane, trudno jest stwierdziæ, która konkretna zmienna ma wpģyw na zmienną zaleŋną. Innym sposobem spojrzenia na problem wspóģliniowoķci jest: indywidualne wartoķci P testu t mogą wprowadzaæ w bģąd. Oznacza to, ŋe wartoķæ P moŋe byæ wysoka, co oznacza, ŋe zmienna nie jest waŋna, nawet jeķli zmienna jest waŋna.
Jak wykryæ wspóģliniowoķæ ?: Variance Inflation Factor (VIF) - Zapewnia wskažnik, który mierzy, o ile wariancja (kwadrat szacowanego odchylenia standardowego) szacowanego wspóģczynnika regresji jest zwiększona z powodu kolinearnoķci.
Interpretacja VIF: Jeŋeli wspóģczynnik inflacji wariancji zmiennej predykcyjnej wynosi 5, oznacza to, ŋe wariancja wspóģczynnika tej zmiennej predykcyjnej jest 5 razy większa niŋ w przypadku, gdyby zmienna predyktorowa nie byģa skorelowana z innymi zmiennymi predykcyjnymi.
Studium przypadku: Zaģóŋmy, ŋe analizujesz produkt (pralkę), zebraģeķ informacje od róŋnych uŋytkowników w caģym kraju, zadając następujące pytania:
Oceņ to w skali 1-5 (1: bardzo niska, 5: - bardzo wysoka)
• Jak dobrze wygląda produkt?
• Jak wygodnie korzystasz z produktu?
• Jak często napotykasz trudnoķci w korzystaniu z produktu?
• Jak często dzwoniģeķ do dziaģu obsģugi klienta?
• Jaka jest odpowiedž z Call Center?
• Jak bardzo jesteķ zadowolony z naszego produktu?
Chcesz się dowiedzieæ, czy te zmienne mają problem z wspóliniowoķcią, czy nie. Moŋemy to zrobiæ, uruchamiając model lm i obliczając VIF (Variance Inflation Factor).
# Krok 1: Odczytaj dane
setwd('D:/R data')
Cus.drt <- read.csv("Cus_satis.csv", header=T)
# Krok 2: Sprawdž problem wspóģliniowoķci
Model = lm(Overall ~ ., data=Cus.drt)
Rsq = summary(Model)$r.squared
vif = 1/(1 - Rsq)
vif
Poniewaŋ uzyskana wartoķæ vif jest mniejsza niŋ 5, moŋemy powiedzieæ, ŋe problem wspóģliniowoķci nie istnieje.
GĢÓWNA ANALIZA KOMPONENTÓW
PCA: Jeķli mamy mniejszą liczbę funkcji, moŋemy uŋyæ wykresów rozrzutu do ich oceny. Ale wyobraž sobie, jak odkryjesz dane 100-wymiarowe. Czy nawet w tym celu moŋemy wykonaæ parowanie wykresów punktowych? Tutaj nadal chcemy wiedzieæ, jaka jest struktura danych. Co jest innego niŋ wykresy rozrzutu? Tak nazywamy Projekcje, gģówną analizę komponentów. Omówmy, czym jest PCA i dlaczego jest bardzo przydatne? Zrozumiesz, jeķli nie PCA, jakie inne techniki moŋna zastosowaæ ? PCA jest techniką stosowaną do zrozumienia struktury danych, ksztaģtu opartego na kowariancji danych. Co to jest projekcja? Uŋywamy terminu projekcja doķæ często, więc zrozummy, co to jest. Pozwól mi podaæ kilka przykģadów, aby wyjaķniæ ten termin. Wyobraž sobie, ŋe jesteķmy na boisku do krykieta, patrząc na trzy pniaki, których uŋywamy w krykieta. To jest trójwymiarowa struktura. Wyobražmy sobie, ŋe wzięliķmy ķwiatģo pochodni, skupiamy ķwiatģo na pniakach i obserwujemy cieņ po drugiej stronie. Nazywa się to projekcją. Jeķli zmienimy žródģo ķwiatģa pod róŋnymi kątami, otrzymamy inną projekcję. Dane są nadal takie same. Projektujemy je w innym kierunku, aby uzyskaæ róŋne wymiary. Zaģóŋmy, ŋe jeķli rzutujemy je poziomo pod kątem 180 stopni otrzymujemy linię prostą jako rzut. Teraz rozumiem wymiar linii prostej. Jest 1-wymiarowy. Ale musimy pomyķleæ, jaka jest utrata informacji, gdy wyķwietlamy dane pod kątem 180 stopni? Jeķli oryginalne dane zostaģy usunięte po projekcji, czy moŋemy je zrekonstruowaæ? Ile informacji straciliķmy? Oto pytania, które musimy sobie zadaæ przed wyķwietleniem danych. PCA to liniowa transformacja ortogonalna, która przeksztaģca dane w nowy ukģad wspóģrzędnych, tak ŋe największa wariancja przy dowolnym rzucie danych leŋy na pierwszej wspóģrzędnej, druga największa wariancja na drugiej wspóģrzędnej i tak dalej. PCA wykorzystuje ortogonalne odwzorowanie silnie skorelowanych zmiennych do zestawu wartoķci liniowo nieskorelowanych zmiennych zwanych skģadowymi gģównymi. Liczba gģównych skģadników jest mniejsza lub równa liczbie oryginalnych zmiennych. Ta transformacja liniowa jest zdefiniowana w taki sposób, ŋe pierwszy gģówny skģadnik ma największą moŋliwą wariancję. To odpowiada jak największej zmiennoķci danych, biorąc pod uwagę cechy wysoce skorelowane. Teraz zrozummy terminologię:
1. Kierunek projekcji: Žródģo ķwiatģa i kąt ķwiatģa
2. Surowe dane w przestrzeni 3D: rzeczywiste pniaki, które są zamocowane w przestrzeni trójwymiarowej.
3. Dane rzutowane w przestrzeni 2D: cieņ na drugim koņcu.
W zaleŋnoķci od kierunku projekcji cieņ się zmieni, ale nie dane. Jeķli zmienię ķwiatģo dalej, otrzymam inną projekcję. Tak więc projekcja, którą otrzymujemy, jest funkcją tego skąd pochodzi ķwiatģo i zawsze cieņ znajduje się po drugiej stronie. Wyobražmy sobie, ŋe rzutowaliķmy trzy pnie pod czterema róŋnymi kątami i otrzymujemy projekcje A, B, C, D. Teraz, jak moŋemy zdecydowaæ, która z tych projekcji w A, B, C, D jest najlepszą projekcją? Mierzymy trafnoķæ projekcji na podstawie iloķci informacji, które moŋe zachowaæ. Projekcja, która zachowuje maksymalną iloķæ informacji, nazywana jest najlepszą projekcją. Zaģóŋmy, ŋe uwaŋamy "A" za najlepszą projekcję, co projekcja A robi inaczej niŋ inne? Co się dzieje, gdy wykonujemy inne prognozy, tracimy informacje. Wģaķciwie surowe dane są w 3 wymiarach, potem zrobiliķmy projekcję, projekcja jest przybliŋeniem surowych danych. Po projekcji otrzymujemy dwuwymiarową przestrzeņ, co oznacza, ŋe tracimy trochę informacji, poniewaŋ przechodzimy z 3D na 2D. Celem redukcji wymiarowoķci, projekcji jest utrata minimalnej iloķci informacji. Tak więc prawidģowa odpowiedž zaleŋy od kryteriów, których uŋywamy. Tutaj naszym kryterium jest zminimalizowanie utraty informacji lub prognoza, która zachowuje maksymalną iloķæ informacji w surowych danych, jest najlepszą prognozą. W tej definicji najlepsza jest projekcja A, poniewaŋ zachowuje ona maksymalną strukturę surowych danych. Oczywiķcie stracimy trochę struktury, ale stratę utrzymamy na minimalnym poziomie. W przypadku D, jeķli pokazują nam tylko rzut, ale nie surowe dane, nie moŋemy zrekonstruowaæ surowych danych. Oznacza to, ŋe nie moŋemy mieæ pojęcia, jakie są surowe dane. Myķleliķmy, ŋe w rzeczywistoķci nieprzetworzone dane są linią prostą. Straciliķmy więc ogromną iloķæ informacji w D, a bardzo niewiele informacji zachowano w D. Więc pamiętajcie o tym, ilekroæ projektujemy dane, powinniķmy utraciæ informacje, ale projekcja, w której mamy minimalną iloķæ utraty informacji, jest uwaŋana za najlepsza projekcja. Moŋemy więc zdefiniowaæ pojęcie najlepszej projekcji jako projekcję, w której tracimy minimalną iloķæ informacji. Wežmy jeszcze jeden przykģad, wyobražmy sobie sferyczne dane, kiedy projektujemy dane 2D, otrzymamy dane rzutowane w przestrzeni 1D. Tutaj straciliķmy trochę informacji, poniewaŋ punkty na tej samej linii poziomej pojawią się jako jeden punkt na ekranie. Więc straciliķmy to rozróŋnienie. poniewaŋ nie moŋemy odróŋniæ róŋnicy między dwoma róŋnymi punktami danych na tej samej linii poziomej. Ale moglibyķmy zmniejszyæ wymiarowoķæ z 2D do 1 D. Wyobražmy sobie, ŋe jeķli skierujemy ķwiatģo w róŋnych innych kierunkach, otrzymamy róŋne rzuty, zaģóŋmy, ŋe jeķli mamy trzy rzuty A, B, C, powiedz mi, która jest najlepszą projekcją? Nie, nie moŋemy powiedzieæ, poniewaŋ wszystkie są takie same. Ilekroæ dane są sferyczne, oznacza to, ŋe są równo rozdzielone, a obie funkcje są caģkowicie nieskorelowane, co oznacza, ŋe cechy są caģkowicie niezaleŋne od siebie, w takim przypadku, bez względu na to, co robisz w zakresie projekcji, stracisz taką samą iloķæ informacji. Dlatego badamy kowariancję, poniewaŋ chcemy osiągnąæ stan, w którym dane stają się tak sferyczne, ŋe wszystkie prognozy są równie dobre lub równie zģe. Koncepcyjnie mogą istnieæ nieskoņczone sposoby wyķwietlania danych, ale kiedy projektujemy dane ortogonalnie, przechwytujemy informacje o róŋnych rodzajach punktów danych i róŋnych rodzajach struktur, w pierwszym przypadku przechwytuję rozkģad pionowy, a w drugim przechwytuję rozkģad poziomy, to, co przechwytuję z jednej strony, jest caģkowicie róŋne od tego, co przechwytuję z drugiej strony, i te dwie projekcje ģącznie przechwytują peģne informacje na temat surowych danych. Pomysģ polega na tym, ŋe kiedy dostaję pierwszą projekcję, w której przechwyciģem większoķæ danych, następna najlepsza projekcja, która da mi inne informacje, które utraciģem w pierwszej projekcji. To powinno byæ prostopadģe do pierwszej projekcji. Poniewaŋ dane są w 2D, potrzebuję tylko 2 rzutów, aby uchwyciæ peģną informację w danych. Spójrz na pozostaģe dwa rzuty, iloķæ informacji zarejestrowanych w obu rzutach jest dokģadnie taka sama. Pozwólcie, ŋe podam kolejny przykģad rzutów ortogonalnych, gdy uŋywamy róŋnych rzutów ortogonalnych, które są pod kątem 90 stopni względem siebie, te dwa rzuty są ortogonalne, co oznacza, ŋe informacje przechwycone przez jedną projekcję są caģkowicie róŋne od informacji przechwyconych przez inną projekcję, oba w poģączeniu otrzymam peģną informację. Moŋna powiedzieæ, ŋe rzutowanie jest dobre, gdy rzut uwzględnia ksztaģt i zachowuje wariancję. Projekcję, która zachowuje maksymalną wariancję, nazywamy ich skģadnikiem Pierwszej Podstawowej, w którym zachowana jest maksymalna wariancja. Tutaj wariancja oznacza, ŋe iloķæ informacji jest zachowana. Wyobraž sobie, ŋe funkcja nie ma wariancji, to nie ma w niej zawartoķci informacyjnej. Tak więc zachowanie wariancji jest jednym z kryteriów najlepszej projekcji. Pierwszy gģówny skģadnik przechwytuje maksymalną wariancję i cokolwiek pozostaģa wariancja zostanie przechwycona przez drugi gģówny skģadnik i tak dalej i tak dalej. Teraz wyobraž sobie, ŋe jeķli masz dane 100-wymiarowe, pierwszy gģówny skģadnik przechwytuje maksymalną wariancję, a drugi gģówny skģadnik, który jest prostopadģy do pierwszego, przechwytuje drugą najlepszą wariancję. Wtedy wszystko, co pozostanie, zostanie przechwycone przez trzeci, który będzie prostopadģy do pierwszych dwóch gģównych elementów i tak dalej. W PCA staramy się znaležæ w kolejnoķci sekwencyjnej zestaw rzutów, tak aby pierwszy gģówny skģadnik przechwytywaģ maksymalną wariancję i trwaģ do koņca. Jeķli moje dane mają N wymiarów, mogę mieæ co najwyŋej N gģównych skģadników, Wyobražmy sobie dwuwymiarowe punkty danych, w regionie jest X punktów danych, Mu jest ķrednią z tych punktów danych. (Mu (X)) . X(n) jest n-tym punktem danych w X punktach danych, a jeķli rzutujemy je razem, naszą koncepcją jest zachowanie maksymalnej wariancji. Zaģóŋmy, ŋe rzutowaliķmy ķwiatģo z dwóch žródeģ, a Mu(Y) jest rzutowaną wersją Mean, a Y(n) jest rzutowaną wersją N-tego punktu danych. Wyobražmy sobie, ŋe spojrzeliķmy na projekty na dwa sposoby, moŋemy zrozumieæ, ŋe pierwsza projekcja zachowaģa maksymalną wariancję w porównaniu do drugiej. Teraz powinniķmy obliczyæ, jaka jest przewidywana ķrednia Mu(Y), czyli N dla caģego Y(n). Celem byģo zmaksymalizowanie zachowania wariancji. Patrzę na rzutowaną przestrzeņ i dowiaduję się, która z nich jest lepszą projekcją. Projekcja to nic innego jak tylko nieprzetworzone dane, pomnoŋenie ich przez wektor, i daje jedną liczbę, która daje jedną projekcję. Y(n) jest pojedynczą liczbą, która mówi mi, jak daleko jest od tego punktu i tak dalej. Teraz, jeķli chcę obliczyæ ķrednią, to, co mówię, to 1 powyŋej N, ķrednia dla wszystkich wartoķci Y. To tylko przykģad jednego punktu, ale w rzeczywistoķci projektujemy wszystkie punkty przestrzeni i bierzemy ķrednie wartoķci tych punktów i jeķli rozwinę równanie W transponuje Xn (W to wektor liniowy, który mówi mi o kierunku projekcji) .Wyciągam podsumowanie, a pozostaģa częķæ to nic innego jak ķrednia. Ķrednią moŋna wykonaæ na dwa sposoby, np. najpierw rzutujesz wszystkie punkty danych i bierzesz ķrednią, albo bierzesz ķrednią i rzutujesz wszystkie punkty póžniej. W obu sytuacjach otrzymasz ten sam wynik. Jaka jest wariancja w przestrzeni Y? Rozbieŋnoķæ jest niczym innym, jak tylko wziąæ kaŋdy punkt danych. Jak daleko jest od ķredniej, jeķli masz dane wraz z kierunkiem chmury, starasz się zachowaæ lub zmaksymalizowaæ wariancję, poniewaŋ otrzymany ksztaģt jest dģuŋszy, to jest to, co próbujemy to zrobiæ, jeķli podstawię wartoķæ Y, Y jest niczym innym jak W transponuje tutaj X, jeķli zrobię tu trochę matematyki, to co się stanie, W transponuje kowariancję razy W, staje się to przestrzenią kowariancji. Idea polega na tym, ŋe staje się to kowariancją, w zasadzie to, co robimy, bierzemy W razy transpozycja razy kowariancję razy W i to staje się, w postaci pojedynczej liczby, liczba ta będzie tutaj znacznie niŋsza, ta sama liczba będzie znacznie wyŋsza w innym przypadku. Tak więc, jeķli chcesz zmaksymalizowaæ wariancję, znajdž W, która maksymalizuje wariancję. Teraz staje się to problemem optymalizacji, tak to ujęliķmy, bierzesz macierz kowariancji danych, masz surowe dane, takie jak dane czterowymiarowe, bierzesz ķrednią ze wszystkich kolumn, otrzymujemy cztery liczby, bierz kowariancję macierzy, ta macierz nazywa się W, chcesz znaležæ tę W, która jest kierunkiem, tak ŋe wariancja jest zmaksymalizowana w rzutowanej przestrzeni. Kiedy robisz to zasadniczo, rozwiązujesz problem wektora wģasnego, kowariancji. Byæ moŋe zrozumiaģeķ koncepcyjnie, co próbujemy zrobiæ. Staramy się znaležæ ten kierunek, który maksymalizuje zachowanie wariancji. Stwierdzamy, ŋe W, które maksymalizuje i jest caģkowicie związane z macierzą kowariancji danych. Spójrzmy na to w przypadku zestawu danych, który ma 8 zmiennych numerycznych i 500 obserwacji. tutaj moŋesz uzyskaæ macierz 8 * 8, a kiedy spojrzymy na kowariancję, przekątna jest wariancją kaŋdej cechy, co jest rozkģadem samej cechy, jest to macierz 8 * 8. Wzięliķmy sumowanie ponad 500 punktów, z których kaŋdy jest sumą wielkoķci 8 * 8, mi x i mi x to 8-wymiarowy punkt, ķrodek wszystkich punktów, Xn jest n-tym punktem danych, w zasadzie biorąc ķrednio 500 macierzy 8 * 8, to daje macierz kowariancji. Kiedy wežmiesz wektor wģasny, staje się on pierwszym gģównym skģadnikiem. gdy obliczasz wartoķci wģasne zasadniczo, daje to 8 wektorów wģasnych. Pamiętaj, ŋe nieprzetworzone dane mają 8 wymiarów, więc prognozy równieŋ będą wynosiæ 8, więc otrzymaliķmy 8 gģównych skģadników ģącznie, i dla kaŋdego gģównego skģadnika daje równieŋ . W wartoķciach wģasnych, które mówią, w jakim kierunku występuje wariancja kaŋdego gģównego skģadnika, moŋemy zobaczyæ pierwszy gģówny skģadnik, który zachowuje bardzo duŋą wariancję. W PCA staramy się wziąæ caģą wariancję danych, staramy się wycisnąæ caģą wariancję w pierwszym gģównym skģadniku danych, oczywiķcie nie moŋemy uzyskaæ caģej wariancji pierwszego gģównego skģadnika, ale moŋemy spróbowaæ to zmaksymalizowaæ. Tak mówimy po przeanalizowaniu wyniku, staramy się uzyskaæ maksymalną moŋliwą wariancję w pierwszym gģównym skģadniku, a następnie w drugim i tak dalej. Pomysģ jest taki, ŋe 8-wymiarowe dane dają 8 gģównych skģadników, ale pierwszy gģówny skģadnik będzie miaģ maksymalną kowariancję. Jeķli wežmiesz wszystkie 8 wymiarów, wówczas pokrywamy caģą wariancję, ale dane mają trochę szumu, dobrze jest straciæ trochę informacji, waŋne jest, aby zachowaæ odpowiednią iloķæ informacji i odpowiedni rodzaj informacji, dlatego rzutujemy dane na 2 lub 3 gģówne elementy.
Zobaczmy kilka przykģadów bez nadzoru:
W PCA projekcja jest jednym rodzajem struktury, gdzie moŋe się wydawaæ, ŋe dane mają 200 wymiarów lub 1000 wymiarów, te kolumny nie nadeszģy, poniewaŋ dane mają te kolumny, te kolumny nadeszģy, poniewaŋ ktoķ uznaģ, ŋe to waŋna kolumna. Zawsze dobrze jest byæ konserwatywnym i na początku mieæ więcej kolumn, poniewaŋ nie wiesz, ile będziesz chciaģ póžniej uŋyæ. Firma taksówkowa moŋe gromadziæ Twoje dane, na przykģad ile czasu moŋesz poczekaæ, do jakiej częķci miasta naleŋysz, o której godzinie zaczynasz pracę w biurze itp. nie wiedzą, jak z nich korzystaæ teraz, ale byæ moŋe wykorzystają je póžniej . Zasadniczo zbieramy więcej kolumn, aby zachowaæ ostroŋnoķæ, poniewaŋ póžniej nie powinniķmy mówiæ och! Powinienem byģ nawet zebraæ to pole danych, dlatego nazywamy zbieranie danych sztuką, sztuką myķlenia koncepcyjnego. Ale kiedy zbierzesz więcej kolumn, twój zestaw danych będzie grubszy, teraz musimy dowiedzieæ się, jaka jest prawdziwa struktura danych. Przydaje się więc PCA.
Studium przypadku: Organizacja zajmująca się oprogramowaniem ma problem z wyczerpaniem i chce znaležæ powody odejķcia pracowników z organizacji. Zebrali róŋne wymiary i chcą skompresowaæ je do kilku funkcji, aby mogli skoncentrowaæ się na tych problemach. Teraz naszym zadaniem jest dowiedzieæ się, czy moŋemy zmniejszyæ wymiary, czy nie. Chcemy dowiedzieæ się, ile wymiarów wystarcza do przeniesienia co najmniej 80% wariancji danych. Eksploracyjna analiza czynnikowa (EFA) jest powszechną w naukach spoģecznych techniką wyjaķniania wariancji między kilkoma zmiennymi mierzonymi jako mniejszym zestawem zmiennych ukrytych. EFA jest często uŋywana do konsolidacji danych ankietowych poprzez ujawnienie grup (czynników) leŋących u podstaw poszczególnych pytaņ.
WYKONYWANIE ANALIZY CZYNNIKA
# Krok 1: Odczytaj dane
setwd('D:/R data')
Emp.fa <- read.csv("Emp_satis.csv", header=T)
# Krok 2: Zainstaluj i zaģaduj pakiet
install.packages ("psych")
library(psych)
#Krok 3: Przeglądaj dane
head(Emp.fa) #show sample data
dim(Emp.fa) #check dimensions
str(Emp.fa) #show structure of the data
fix(Emp.fa)
# Krok 4: Przygotowanie danych
fa.req <- subset(Emp.fa, select=-c(Empid,Overall))
#Krok 5: Oblicz i wyķwietl matrycę korelacji
corMat <- cor(fa.req)
corMat
#Krok 6: Wykonaj analizę czynnikową
Uŋyj fa(), aby przeprowadziæ skoķną analizę eksploracyjną czynnika w osi gģównej i zapisaæ rozwiązanie dla zmiennej R. Aby uzyskaæ rozwiązanie czynnikowe, uŋyjemy funkcji fa() z pakietu psych, który otrzymuje następujące podstawowe argumenty.
Mod.fa <- fa (r = corMat, nfactors = 3, rotate = "varimax", fm = "ml")
Gdzie,
#r: macierz korelacji
#nfactors: liczba czynników do wyodrębnienia (domyķlnie = 1)
#rotate: jedna z kilku metod rotacji macierzy, takich jak "varimax" lub "oblimin"
#fm: jedna z kilku metod faktorowania, takich jak "pa" (oķ gģówna) lub "ml" (maksymalne prawdopodobieņstwo)
Naleŋy pamiętaæ, ŋe podczas przeprowadzania EFA dostępnych jest kilka metod rotacji i faktorowania. Metody rotacji moŋna opisaæ jako ortogonalne, które nie pozwalają na korelację uzyskanych czynników, i skoķne, co pozwala na korelację uzyskanych czynników. Metody faktorowania moŋna opisaæ jako powszechne, które są stosowane, gdy celem jest lepsze opisanie danych, oraz komponent, które są stosowane, gdy celem jest zmniejszenie iloķci danych.
#Krok 7: Wyķwietl wyniki rozwiązania
Mod.fa
WYKONANIE GĢÓWNEJ ANALIZY KOMPONENTÓW
# Krok 1: Odczytaj dane
setwd('D:/R data')
Emp.drt <- read.csv("Emp_satis.csv", header=T)
#Krok 2: Przeglądaj dane
head(Emp.drt) #show sample data
dim(Emp.drt) #check dimensions
str(Emp.drt) #show structure of the data
fix(Emp.drt)
colnames(Emp.drt)
# Krok 3: Przygotowanie danych
Emp.req <- subset(Emp.drt, select=-c(Empid))
# Krok 4: Sprawdž problem wielokoliniowoķci
Model = lm(Overall ~ ., data=Emp.req)
Rsq = summary(Model)$r.squared
vif = 1/(1 - Rsq)
vif
Poniewaŋ uzyskana wartoķæ vif jest większa niŋ 5, moŋemy powiedzieæ, ŋe występuje wielokoliniowoķæ. Zdecydowaliķmy się więc na redukcję wymiarów.
# Krok 5: Przygotowanie danych
Emp.pro <- subset(Emp.drt, select=-c(Empid,Overall))
#Krok 6: Utwórz gģówne skģadniki
Emp.pca <- prcomp(Emp.pro,center=TRUE,scale=TRUE)
print(Emp.pca)
#Krok 7: Utwórz wykres piargowy
plot(Emp.pca, type="lines")
Metoda #summary opisuje znaczenie komputerów osobistych. Pierwszy wiersz opisuje ponownie odchylenie standardowe związane z kaŋdym komputerem. Drugi rząd pokazuje odsetek wariancji w danych wyjaķnionych przez kaŋdy skģadnik, podczas gdy trzeci rząd opisuje skumulowany odsetek wyjaķnionej wariancji.
#Krok 8: Wykonaj podsumowanie
KROK 8
Grupowanie
WPROWADZENIE
Grupowanie jest procesem organizowania obiektów w grupy, których czģonkowie są w pewien sposób podobni, które zajmuje się znajdowaniem Struktury w zbiorze Nieoznaczonych Danych. Gromada jest zatem zbiorem obiektów, które są między nimi "podobne" i są "niepodobne" do obiektów naleŋących do innych klastrów. Wežmy przykģad firmy z laptopem, która promuje swoją najnowszą markę laptopów. Chcą dostosowaæ modele reklam, ludzie mieszkający w jednej częķci miasta róŋnią się od ludzi, którzy mieszkają w innej częķci miasta. Musimy wysģaæ inną reklamę do róŋnych osób. Co my tu zrobiliķmy? Klastrowanie wykonujemy intuicyjnie. Moŋemy zacząæ od jednej lub dwóch wiadomoķci i moŋemy to zrobiæ aŋ do indywidualnej, tj. spersonalizowanej reklamy. Grupowanie jest więc tym, co robimy, gdy chcemy tworzyæ grupy, poniewaŋ nie moŋna utworzyæ jednej wiadomoķci dla kaŋdej osoby, jest to zbyt kosztowne na jednym koņcu spektróm i nie moŋna wysģaæ tej samej wiadomoķci do wszystkich, poniewaŋ jest ona zbyt duŋa. Co teraz zrobisz? Robisz coķ w ķrodku, co nazywa się klastrowaniem? Teraz Pomyķl o centrum obsģugi klienta firmy taksówkowej. Chcą wiedzieæ, jakie są problemy CRM, zaczynają od niektórych problemów i rozwiązaņ, a następnie udoskonalają zestaw problemów w oparciu o problemy CRM. Pomyķl o tym, skąd znają te problemy jeszcze przed zaģoŋeniem firmy ? Byæ moŋe wzięli pod uwagę problemów zgģoszonych przez poprzednie firmy taksówkowe, a potem staģ się problemem klasyfikacyjnym. W jaki sposób odkrywasz nowe rzeczy, które się pojawiają na twoim rynku, my zajmujemy się grupowaniem. Róŋne rodzaje technik klastrowania:
1. Wyģączne klastrowanie (klastrowanie częķciowe): Klastrowanie K-Means
2. Nakģadające się klastry: Klastrowanie Fuzzy C-Means
3. Hierarchiczne grupowanie: góra-dóģ (dzielenie), dóģ-góra (gromadzenie)
4. Grupowanie probabilistyczne: Mieszanka Gaussa
5. Grupowanie widmowe
CZĘĶCIOWA KLASTROWANIE
Klastrowanie częķciowe moŋe byæ twarde lub miękkie, w klastrowaniu twardym to tak, jakbyķ grupowaģ punkt danych do jednej okreķlonej funkcji klastra. Skoro naleŋy do tego klastra, nie moŋe naleŋeæ do ŋadnego innego klastra. W miękkim klastrowaniu uwaŋamy, ŋe punkt danych wygląda jak naleŋący do tego klastra, ale ma nawet cechy drugiego klastra, więc częķciowo naleŋy do tego, a częķciowo do innego. Pozwólcie, ŋe zastosuję obie strategie do tego punktu danych, który nazywa się miękkim klastrowaniem. Początkowo, kiedy tworzysz klastry, nie wiesz, jak dokģadne są centra klastrów, więc nie chcesz robiæ twardego klastrowania. Jeķli twoje dane zawierają zbyt duŋo haģasu, nie chcesz robiæ twardego klastrowania, poniewaŋ nie masz pewnoķci.
Hierarchizm: To nie jest technika grupowania, jest to w rzeczywistoķci filozofia patrzenia na dane, zawsze twoje dane mają hierarchię. Bez względu na domenę, w której się znajdujesz, moŋe to byæ sekwencja genów, finanse, ubezpieczenie, zawsze istnieje hierarchia. Ķwiat skģada się z hierarchii. Hierarchia jest integralną częķcią natury, mózg rozumie hierarchie. Ilekroæ ktoķ przekazuje ci dane, pierwsze pytanie, jakie naleŋy zadaæ, to jaka jest w tym hierarchia? Twój model mentalny jest zawsze tutaj jest hierarchią. Jak uwaŋasz, ŋe hierarchia zaleŋy od ciebie. Jaki poziom hierarchii zastosujesz, zaleŋy od ciebie. Ile zaleŋy Ci na poziomie w hierarchii. Pomyķl tylko o systemie menu w call center telekomu, jeķli masz ten problem, naciķnij 1, a jeķli to problem, naciķnij 2 itd., Nawet po naciķnięciu 1 otrzymasz więcej opcji menu i tak dalej. Hierarchia to wbudowany proces w systemie biznesowym, organizacji, a nawet w danych. Uczenie się bez nadzoru polega na uczeniu się struktury danych, kiedy mówimy, ŋe struktura, to naprawdę oznacza hierarchię. Moŋesz zadaæ mi pytanie, jeķli wszystko jest w hierarchii, dlaczego więc potrzebujemy klastrowania częķciowego? Jeķli chcemy zastosowaæ podejķcie oddolne do tworzenia klastrów, powinniķmy znaæ odlegģoķæ par między wszystkimi parami, punktami danych od siebie. Czy jest to moŋliwe dla duŋej liczby punktów danych? Nie, więc jeķli zastosujemy podejķcie odgórne, musimy wykonaæ klastrowanie częķciowe na kaŋdym etapie klastrowania. Chodzi o to, ŋe najpierw muszę zbudowaæ 5 klastrów, poniewaŋ nie mogę mieæ systemu menu, który dziaģa do 100. Tak więc najpierw zbuduję 5 klastrów, a następnie zbuduję podgrupy, poniewaŋ wiem, ŋe dane są zgodne z hierarchią. Oznacza to, ŋe uŋywam w tym przypadku obu metod grupowania, ale moim modelem koncepcyjnym jest hierarchia. Oznacza to, ŋe uŋywamy klastrowania częķciowego jako częķci klastrowania z góry na dóģ. Tego oczekuje przemysģ od naukowca danych.
Klastrowanie K-Means zaleŋy od:
• Musisz znaæ liczbę klastrów
• W zaleŋnoķci od inicjalizacji, którą spotkaģeķ, uzyskasz inny klaster
• W zaleŋnoķci od funkcji odlegģoķci moŋesz uzyskaæ inny klaster.
Kiedy mówię, funkcja odlegģoķci, nie ma czegoķ takiego jak funkcja odlegģoķci, musisz stworzyæ wģasną funkcję odlegģoķci, to jest tak, jakby iķæ na piknik, musisz zabraæ ze sobą stóģ piknikowy, poniewaŋ nie idziemy do restauracji . Podobnie, musisz wprowadziæ wģasną funkcję odlegģoķci do częķci uczenia maszynowego. To bardzo waŋna częķæ. Im lepsze funkcje odlegģoķci, tym lepiej zdefiniowane algorytmy uczenia maszynowego. K-Means, oznacza ,ŋe w klastrze nie ma znaczenia, jak zdefiniujesz funkcję odlegģoķci. Jjeķli wszystko jest narzędziem, nie musimy robiæ tego kursu z tak duŋym stresem. Jaka jest Twoja rola jako naukowca danych? Tam wģaķnie przybędą nasze umiejętnoķci. Pomyķl teraz o tym, jak zdefiniujesz, ŋe funkcja odlegģoķci między dwoma wznawia się? Starszeņstwo to jedno, zestaw umiejętnoķci to drugie , firmy, dla których pracowaģ, uniwersytet, do którego uczęszczaģ, jest inny i tak dalej. Pomyķl o funkcji odlegģoķci między profilem jednej osoby a profilem drugiej osoby, jaka jest odlegģoķæ między dwoma filmami? Aktorzy, reŋyser, muzyka ,moŋna zdefiniowaæ bardzo skomplikowane funkcje odlegģoķci. Tak więc jedną z najwaŋniejszych ról badaczy danych jest zdefiniowanie funkcji odlegģoķci. Caģa kreatywnoķæ tkwi w tych rzeczach, nikt nie zdefiniuje tych rzeczy dla ciebie, poniewaŋ lepiej znasz domenę, znasz dane i lepiej znasz dystrybucję, Twoim zadaniem jest zdefiniowanie tych rzeczy. Teraz trzeci rodzaj grupowania nazywany jest klastrowaniem spektralnym. Wiele razy dane przychodzą do nas w tej formie, podobnie jak tabela, w której kaŋdy wiersz jest punktem danych, a my mamy okreķlone cechy jako kolumny lub wymiary. Moŋesz uŋyæ grupowania K-Means lub grupowania gromadzenia tylko wtedy, gdy zdefiniujesz odlegģoķæ między dwoma punktami danych. Dlatego funkcją odlegģoķci jest waŋna, ale często otrzymujesz dane róŋnego rodzaju, które są podobne do siebie. Nie dowiemy się, jak wyglądają dane, powiedzą nam tylko, ŋe jest to podobne. W takim przypadku dane wyglądają jak wykres, na którym kaŋdy węzeģ jest punktem danych, nie ma swoich funkcji, wszystko co wiemy, to odlegģoķci między punktami danych. Celem w grupowaniu jest intuicyjne minimalizowanie odlegģoķci między punktami a ich przedstawicielami. Wyobražcie sobie system demokratyczny, poniewaŋ wszyscy nie mogą zasiadaæ w parlamencie, wysyģamy naszych przedstawicieli tak, aby przedstawiciel byģ najbliŋej wszystkich punktów danych. Uŋyj tej analogii, aby pomyķleæ o grupowaniu k-ķrednich, ŋe wektor ķredni jest reprezentatywny dla grupy ludzi lub grupy punktów danych, a dobry wektor ķredni musi znajdowaæ się blisko wszystkich tych punktów, które reprezentuje.
• Jak wykorzystujemy tę analogię do zdefiniowania funkcji celu?
• Jakie są parametry?
Istnieją dwa rodzaje parametrów: 1. Parametr asocjacji, który mówi, jak się masz przypisz klaster do punktu danych i 2.Jak zaktualizowaæ ķredni wektor? Spójrzmy na Formuģę Grupowania:
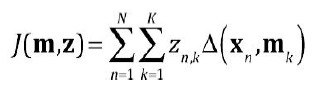
W formule moŋna zobaczyæ dwa symbole sumowania, jeden dla punktów danych, a drugi dla klastrów, nie ma to nic wspólnego z liczbą wymiarów. Korzystam z funkcji odlegģoķci euklidesowej. Podczas wykonywania grupowania K-Means. Musimy zrozumieæ, ŋe wybraliķmy przedstawiciela grupy, kiedy on przenosi się z naszej grupy do innej grupy, staje się przedstawicielem nowej grupy, a jakiķ inny facet zostanie przedstawicielem grupy, która zostaģa pominięta. Chodzi o to, ŋe moŋemy mieæ dowolną liczbę przedstawicieli, ale chcę to zrobiæ w optymalny sposób. Pomyķl o tym jak o problemie z kurczakiem i jajami, jeķli zdecydujemy o powiązaniu, moŋemy obliczyæ ķrednią lub zdecydowaæ o ķredniej i obliczyæ powiązanie. Są to dwa powiązane problemy i nie wiemy od czego zacząæ. Moŋemy albo zacząæ od losowego przypisania centrów skupieņ, albo moŋemy zacząæ od przypisania losowych lokalizacji w danych, poniewaŋ oznacza to, ŋe jedno z dwóch jest prawidģowym punktem początkowym. To jest tak: Biorąc pod uwagę deltę - znajdž ķrednią lub biorąc pod uwagę ķrednią znajdž deltę. Kiedy te problemy zostaną rozwiązane, nadejdzie etap, w którym ķrednia i delta się nie zmienią, co nazywamy to konwergencją. Grupowanie jest algorytmem iteracyjnym, zaczynamy od jakiegoķ wektora ķredniego, a losowe inicjalizacje, póžniej omówimy więcej inicjalizacji, a potem co się stanie? jakie są punkty, które niektórzy idą na m1, a jakie są punkty na m2? Następnie drugie pytanie, biorąc pod uwagę ķrednią w iteracji p, chcemy znaležæ przypisanie do klastra. Kiedy mówię Iteracja, zaczyna się od ķredniej, znajdując wģaķciwą deltę, a następnie uŋywając delty do znalezienia następnej ķredniej. To jest jedno równanie. Początkowo t wynosi 0, co oznacza, ŋe jest to iteracja 0, i powoli zwiększamy t. Kiedy mamy punkty danych, bierzemy punkty jako wektory i obliczamy odlegģoķæ, przypisujemy punkty danych do wektora na podstawie odlegģoķci. Następnie zaktualizuj wartoķæ ķrednią i przejdž do następnej iteracji. Chodzi o to, aby zacząæ od pewnych ķrodków, uŋyliķmy ķredniej do przypisania klastra, a następnie bierzemy przypisanie klastra do obliczenia ķredniej. Następnie iterujemy jeszcze raz i jeszcze raz, aŋ się zbiegnie. Nazywa się to krokiem oczekiwania. W kroku maksymalizacji mówi się, ŋe biorąc pod uwagę, ŋe są to zadania, naleŋy zmaksymalizowaæ funkcję celu.
Krok E: Centra klastrów -> Przypisania klastrów
Krok M: Przydziaģy klastrów -> Centra klastrów.
Pomyķl tylko o chodzeniu: jeķli wežmiemy jedną nogę, jest ona stroma w ksztaģcie litery E, a następnie stawiamy nogę i bierzemy drugą nogę, którą jest M-Step. W ŋadnym punkcie chodzenia nie moŋna podnieķæ obu nóg ani postawiæ obu nóg. Odpowiedzmy na dwa kolejne pytania:
• Jak wybieramy K?
• Jak inicjujemy?
Jak optymalnie przypisujemy przedstawicieli do punktów danych? podczas rozwiązywania tego problemu optymalizacji nie ma gwarancji, ŋe istnieje jedno dobre rozwiązanie. Teraz wyobraž sobie, ŋe Twoim celem jest wspięcie się na najbliŋsze wzgórze lub celem jest upadek najbliŋszej doliny. Albo spadasz, by znaležæ najniŋszy punkt, albo wspinasz się, by znaležæ najbliŋsze wzgórze. Jeķli chcę się wspiąæ, pójdę w kierunku, który daje mi maksymalną zgodę na pochylenie, i osiągnę jeden szczyt , ale jeķli zacznę od innego punktu, dojdę do innego szczytu, a większoķæ algorytmów uczenia maszynowego ma tego rodzaju problem. W wielu przypadkach funkcja optymalizacji jest taka, ma wiele lokalnych optimów, z których jeden jest globalnym optimum. Jaki klaster K-Means gwarantuje, gdziekolwiek zaczniesz, gwarantuję lokalne optymalne parametry, ŋe nie moŋe zagwarantowaæ, ŋe osiągniesz globalne optymalne wartoķci. Dlatego inicjalizacja odgrywa bardzo waŋną rolę w klastrowaniu K-Means. Nawet jeķli milion razy korzystasz z klastrowania K-Means, nikt nie moŋe zagwarantowaæ Ci globalnego optymalnego rozwiązania. To, co moŋemy zrobiæ w klastrowaniu K-Means, to spróbowaæ z róŋnymi punktami inicjalizacji i znaležæ optymima, a wķród tych lokalnych optymów moŋesz wybraæ najlepszy. Dlatego za kaŋdym razem, gdy przeprowadzamy klastrowanie, musimy spróbowaæ uzyskaæ rozģoŋenie początkowych punktów na wszystkie punkty danych.
Najdalszy pierwszy punkt Inicjalizacji: Jest to technika uŋywana do rozwiązania problemu inicjalizacji. W tej metodzie najpierw wybieramy ķrednią i wybieramy najdalszy punkt od ķredniej i uŋywamy jej jako pierwszego centrum skupieņ. Teraz traktuj to jako ziarno i oblicz najdalszy punkt z tego nowego zarodka i rozwaŋ ten punkt jako drugie centrum klastrów, teraz mam dwa centra klastrów, które zagwarantowaģy mi maksymalne rozproszenie danych. Teraz potrzebuję trzeciego ziarna, które powinno byæ najdalej od obu nasion, musimy powiedzieæ, ŋe odlegģoķæ od obu nasion powinna byæ maksymalna, obliczamy wynik wszystkich punktów, tak aby nowe ziarno byģo w maksymalnej odlegģoķci od obu punktów, a następnie wybieramy czwarte nasienie, które powinno byæ maksymalną odlegģoķcią od wszystkich trzech punktów danych. Nie przeszkadza nam, gdy mamy do czynienia z 4 lub 5 klastrami, ale w czasie rzeczywistym moŋe byæ konieczne radzenie sobie z nimi setki wymiarów i miliony obserwacji, to jak zdecydujesz o liczbie klastrów? Mogę mieæ wszystkie moje punkty danych w jednym klastrze lub utworzyæ klaster dla kaŋdego punktu danych. Tutaj oba podejķcia nie są przydatne. Celem jest znalezienie odpowiedniej liczby klastrów. Są dwa sposoby myķlenia. Opiera się na naszym problemie biznesowym. Jeķli podam trzy opcje, czy chcesz utworzyæ 2, 5 lub 200 klastrów? Decyzje te opierają się na naszych potrzebach biznesowych. Jeķli powiemy, ŋe moŋemy obsģuŋyæ 5 rodzajów skarg, poniewaŋ mamy ograniczone zasoby, nie moŋemy zrobiæ 200 klastrów i osobno zajmowaæ się wszystkimi skargami, poniewaŋ jest to bardzo kosztowne, pozwól mi zgrupowaæ te 200 koncepcji w 5 klastrów więc 5 to rozsądna liczba. Moŋemy uŋyæ ogólnej reguģy, która stanowi uģamek pierwiastka kwadratowego danych. Pierwiastek kwadratowy z liczby punktów danych. Moŋemy nawet wybraæ odpowiednią liczbę klastrów na podstawie decyzji opartych na uczeniu maszynowym. Istnieje poprawna liczba klastrów dla kaŋdego zestawu danych, ale pytanie brzmi, czy moŋemy ją znaležæ, czy nie. Wģaķciwa liczba klastrów jest waŋnym zagadnieniem, poniewaŋ poza którym staje się haģasem, poniŋej którego nie przechwytuje się ŋadnej struktury (Sygnaģ). Podczas klastrowania PCA lub K-Means musimy zastanowiæ się, ile szumu i ile sygnaģu jest w danych. Moŋemy uŋyæ statystyk Gap, aby znaležæ odpowiednią liczbę klastrów, próbujemy z szeregiem klastrów, powiedzmy od 3 do 20 dla kaŋdego klastra, którego uŋywasz albo najdalszy algorytm próbkowania pierwszego punktu lub wiele losowych inicjalizacji, cokolwiek zrobisz, otrzymasz trochę statystyk. Wykreķl te statystyki i oblicz lukę, a ona powie ci odpowiednią liczbę klastrów. Caģy czas ķledzimy ten proces, przerwa nie moŋe byæ ujemna, poniewaŋ oczekiwany zakģada caģkowicie losowy haģas lub caģkowicie jednolity rozkģad. Zakģadając, ŋe liczba punktów danych, które są równomiernie rozmieszczone, jest najgorszą moŋliwą strukturą, jaką moŋemy mieæ, to jest to, co sģuŋy do obliczenia oczekiwanego, który zawsze będzie niŋszy niŋ obserwowany. Mamy więc nadzieję, ŋe dane będą miaģy strukturę, która wykracza poza losowy rozkģad danych.
HIERARCHICZNE KLASTROWANIE
W tym typie mamy dwa podejķcia, takie jak: 1. Z góry na dóģ (dzieląca) 2. Z doģu na górę (skupiająca). W podejķciu z góry na dóģ bierzemy caģy zestaw jako pojedynczy klaster i dzielimy je na dwa klastry, a z obu klastrów dzielimy kolejne klastry i tak dalej. Robiąc klastrowanie na kaŋdym etapie, przyjmujemy podejķcie klastrowania K-ķrednich w przypadku danych wielowymiarowych i klastrowania sferycznego w przypadku danych tekstowych. Jeķli tworzymy bezpoķrednio 4-5 klastrów za jednym razem, co nazywa się klastrowaniem partycjonowanym, podczas gdy to podejķcie dzielenia ich krok po kroku nazywa się klastrowaniem dzielącym, podobnie jak najpierw tworzymy dwa klastry z klastra gģównego, a następnie dzielimy oba klastry na dwa. . Takie podejķcie nazywa się hierarchicznym klastrowaniem z góry na dóģ, a my ciągle idziemy w dóģ i w dóģ i tak dalej. Teraz moŋesz zapytaæ, czy jeķli zastosujemy podejķcie K-ķrednie i podejķcie odgórne, czy gwarantujemy, ŋe na koņcu otrzymamy taką samą liczbę klastrów z tymi samymi podmiotami? Odpowiedž brzmi: nie. Hierarchia jest naturalnym sposobem, w jaki dane się pojawiają, w miarę moŋliwoķci powinniķmy myķleæ hierarchicznie, zawsze moŋemy uŋywaæ klastrowania częķciowego na kaŋdym poziomie, ale ostatecznie robimy klastrowanie hierarchiczne. Spójrzmy na inny rodzaj klastrowania, tj. skupiające hierarchiczne klastrowanie, które jest bardzo często wykorzystywane w następującym scenariuszu. Wyobraž sobie, ŋe punkty danych nie są bardzo duŋe, co oznacza, ŋe nie mamy zbyt wielu punktów danych, ale chcemy naprawdę dobrego klastra, w takim przypadku ludzie wolą stosowaæ klastrowanie skupiające. Wežmy przykģad niektórych sekwencji genów, grupujemy geny razem, a one tworzą klaster. Wyobraž sobie, ŋe istnieją pewne punkty danych, chcę móc je grupowaæ i organizowaæ, uŋyģem grupowania aglomeracyjnego. Mógģbym to uzyskaæ, metodą odgórną lub metodą oddolną. Więc nie mówię, której metody uŋywam. Chodzi o to, ŋe moŋemy zorganizowaæ dane w węžle liķcia w hierarchię. Wežmy przykģady liczb 0-9 i chcemy znaležæ, które są bardziej podobnymi punktami danych, najpierw bierzemy dwie liczby, które wyglądają bardzo podobnie, istnieje bardzo jasne pojęcie, ŋe 1 i 7 wyglądają podobnie, więc je scalam, więc, kiedy je scalam, otrzymuję klaster o rozmiarze drugim i mam n-2 klastrów o rozmiarze 1, mogę traktowaæ kaŋdy punkt danych jako klaster, początkowo gdy nic nie zrobiģem, kaŋdy punkt danych jest grupa. Ilekroæ myķlimy o klastrowaniu, moŋemy myķleæ o tym, jaka jest najmniejsza liczba klastrów, jaką moŋemy mieæ i jaka jest największa liczba klastrów, jaką moŋemy mieæ? więc najmniejszą liczbą moŋe byæ 1, a największą liczbą moŋe byæ liczba punktów danych. Klaster skupiający pomaga nam budowaæ klastry od n do jednego, ģącząc klastry oddolnie. Otrzymasz spektrum wszystkich moŋliwych klastrów od 1 do N.
OCENA TENDENCJI KLASTRA
Przed zastosowaniem jakiejkolwiek metody klastrowania w zbiorze danych naturalne pytanie brzmi: czy zestaw danych zawiera jakieķ nieodģączne klastry ? Duŋym problemem w uczeniu maszynowym bez nadzoru jest to, ŋe metody klastrowania zwracają klastry, nawet jeķli dane nie zawierają ŋadnych klastrów. Innymi sģowy, jeķli ķlepo zastosujesz analizę skupieņ w zbiorze danych, podzieli dane na klastry. Dlatego przed wyborem podejķcia klastrowego musimy zdecydowaæ, czy zestaw danych zawiera znaczące klastry, czy nie. Jeķli tak, to ile jest tam klastrów. Proces ten jest definiowany jako ocena tendencji do tworzenia klastrów lub wykonalnoķci analizy klastrów. Moŋemy zastosowaæ metody statystyczne i wizualne do oceny tendencji do tworzenia klastrów. Moŋna zauwaŋyæ, ŋe algorytm k-ķrednich i klastrowanie hierarchiczne narzucają klasyfikację losowo równomiernie rozmieszczonego zestawu danych, nawet jeķli nie ma w nim znaczących klastrów. Aby uniknąæ tego problemu, stosuje się metody oceny tendencji do tworzenia klastrów. Metody oceny tendencji do tworzenia klastrów: Ocena tendencji do tworzenia klastrów okreķla, czy dany zestaw danych zawiera znaczące klastry. Istnieją dwie metody okreķlania tendencji do tworzenia klastrów: 1) statystyczna (statystyka Hopkinsa) i 2) metody wizualne (wizualna ocena algorytmu tendencji klastra (VAT)).
Statystyka Hopkinsa: Statystyka Hopkinsa sģuŋy do oceny tendencji klastrowania zbioru danych poprzez pomiar prawdopodobieņstwa, ŋe dany zestaw danych zostanie wygenerowany przez jednolity rozkģad danych. Innymi sģowy, testuje losowoķæ przestrzenną danych. Wartoķæ H okoģo 0,5 oznacza, ŋe są blisko siebie, a zatem dane D są równomiernie rozmieszczone. Hipotezę zerową i alternatywną definiuje się następująco. Hipoteza zerowa polega na tym, ŋe zestaw danych D jest równomiernie rozģoŋony (tj. Bez znaczących klastrów), a alternatywna hipoteza to zestaw danych D nie jest jednolicie rozproszone (tj. zawiera znaczące klastry). Jeķli wartoķæ statystyki Hopkinsa jest bliska zeru, moŋemy odrzuciæ hipotezę zerową i wyciągnąæ wniosek, ŋe zestaw danych D jest w znacznym stopniu klastrem danych. Funkcja R do obliczania statystyki Hopkinsa: Funkcja hopkins() moŋe byæ uŋywana do statystycznej oceny tendencji do tworzenia klastrów w R.
#1.Odczytaj plik csv, aby zaģadowaæ dane
setwd("D:/R data")
Clus_ds <- read.csv("Clus_sample.csv", header=TRUE)
head(Clus_ds)
str(Clus_ds)
fix(Clus_ds)
#2. Sprawdž klastrowanie za pomocą metody wizualnej Metoda: Utwórz wykres rozproszenia
plot(CAD~Neuro,Clus_ds)
# Oblicz statystyki Hopkinsa dla zestawu danych
set.seed(123)
hopkins(Clus_stan, n = nrow(Clus_stan)-1)
#Jeķli wartoķæ H jest znacznie poniŋej progu 0,5, jest wysoce zdolna do skupiania.
Okreķl liczbę Klastrów
setwd("D:/R data")
Clus_ds <- read.csv("Cluster.csv", header=TRUE)
Clus_req <- Clus_ds[-c(1,8)]
Clus_stan <- scale(Clus_req)
wssplot <- function(Clus_stan, nc=5, seed=1234){
wss <- (nrow(Clus_stan)-1)*sum(apply(Clus_stan,2,var))
for (i in 2:nc){
set.seed(seed)
wss[i] <- sum(kmeans(Clus_stan, centers=i)$withinss)}
plot(1:nc, wss, type="b", xlab="Number of Clusters",
ylab="Within groups sum of squares")}
# Parametr danych to numeryczny zestaw danych do analizy, nc to maksymalna liczba klastrów do rozwaŋenia, a seed to seed o losowej liczbie.
wssplot(Clus_stan)
library(NbClust)
set.seed(1234)
nc <- NbClust(Clus_stan, min.nc=2, max.nc=5, method="kmeans")
table(nc$Best.n[1,])
barplot(table(nc$Best.n[1,]),
xlab="Numer of Clusters", ylab="Criteria",
main="Choose Number of Clusters by 26 Criteria")
STUDIUM PRZYPADKU
Wielospecjalistyczna sieæ szpitali zajmująca się kardiologią, endokrynologią, psychiatrią i specjaliķci od urologii chcą stworzyæ okreķlone strategie mające na celu poprawę ich dziaģalnoķci i optymalnie wykorzystują swoje zasoby. Teraz Twoim zadaniem jest tworzenie klastrów i sugerowanie, które powinny byæ strategią, którą naleŋy stosowaæ w kaŋdym klastrze.
# Krok 1: Zainstaluj i zaģaduj wymagane pakiety
if(!require(clustertend)) install.packages("clustertend")
library(clustertend)
# Krok 2: Zaģaduj dane
setwd("D:/R data")
Clus_ds <- read.csv("Cluster.csv", header=TRUE)
#Krok 3: Przeglądaj dane
fix(Clus_ds)
head(Clus_ds)
str(Clus_ds)
#Krok 4: Usuņ zmienne jakoķciowe, takie jak identyfikator i stan
Clus_req <- Clus_ds [-c (1,8)]
# Krok 5: Usunięcie brakujące po liķcie
Clus_req <- na.omit (Clus_req)
summary (Clus_req)
str (Clus_req)
#Krok 6: Wykonaj normalizację
Clus_stan <- scale(Clus_req) # standardize variables
head(Clus_stan)
summary(Clus_stan)
# Krok 7: Okreķl liczbę klastrów
library(NbClust)
set.seed(1234)
nc <- NbClust(Clus_stan, min.nc=2, max.nc=5, method="kmeans")
table(nc$Best.n[1,])
barplot(table(nc$Best.n[1,]),
xlab="Numer of Clusters", ylab="Criteria",
main="Choose Number of Clusters by 26 Criteria")
# Krok 8: Oblicz odlegģoķæ: Hierarchiczne grupowanie totemów
dt <- dist(Clus_stan, method = "euclidean") # distance matrix
fit.hc <- hclust(dt, method="ward.D2")
# Krok 9: Utwórz dendrogram klastra za pomocą peģnej metody ģączenia
plot (fit.hc) # display dendrogram
#Krok 10: Wytnij drzewo na 4 grupy
groups<- cutree (fit.hc, k = 4)
#Krok 11: Utwórz dendrogram klastra z czerwonymi ramkami wokóģ 4 klastrów
rect.hclust (fit.hc, k = 4, border = "red")
#Krok 12: Wykonaj analizę skupieņ K-ķrednich
set.seed (1234)
fit.km <- kmeans (Clus_stan, 4, nstart = 25)
#Krok 13: Okreķl liczbę punktów danych w kaŋdym klastrze
fit.km $size
#Krok 14: Pokaŋ centra
fit.km$centers
#Krok 15: Pokaŋ klastry
fit.km $cluster
#Krok 16: Uzyskaj ķrodki klastra
aggregate(Clus_stan,by=list(fit.km$cluster),FUN=mean)
# Krok 17: Doģącz przypisanie klastra do oryginalnego zestawu danych
Clus_Fin <- data.frame(Clus_ds,fit.km$cluster)
fix(Clus_Fin)
#Krok 18: Utwórz wykres klastra
library(cluster)
clusplot(Clus_Fin, fit.km$cluster, color=TRUE, shade=TRUE, labels=4, lines=0)
KROK 9
Analiza Koszyka Rynku
WPROWADZENIE
Analiza koszyka rynkowego ma kilka nazw, takich jak Wykrywanie wzorców / Wyszukiwanie wzorców / Reguģy stowarzyszenia / Analiza koszyka rynkowego / Wyszukiwanie zestawów przedmiotów. Zapewnia wgląd w to, które produkty są zazwyczaj kupowane razem i które najbardziej odpowiadają promocji. Uczenie się reguģ asocjacyjnych jest popularną techniką Data Mining do odkrywania interesujących relacji między zmiennymi w duŋych bazach danych.
Co to jest wykrywanie wzorców?
Wzorce: zestaw elementów, podsekwencji lub podstruktur, które często występują razem w zestawie danych. Wzory reprezentują nieodģączne i waŋne wģaķciwoķci zestawów danych. Wykrywanie wzorców to odkrywanie wzorców z ogromnych zestawów danych. Wykrywanie wzorców sģuŋy do znajdowania nieodģącznych prawidģowoķci w zbiorze danych i moŋe dziaģaæ jako podstawa dla wielu podstawowych zadaņ eksploracji danych, takich jak asocjacja, korelacja, analiza szeregów czasowych, analiza przyczynowoķci, analiza skupieņ, wzorce sekwencyjne i strukturalne.
Co to są wzorce: wzorce to zestaw elementów, które często występują razem w zbiorze danych, który reprezentuje waŋne wģaķciwoķci zestawów danych. Moŋemy uŋyæ reguģ asocjacyjnych, aby odpowiedzieæ na tego rodzaju pytania:
• Jakie produkty często kupowano razem?
• Jakie są kolejne zakupy po zakupie okreķlonego produktu?
• Jakie sekwencje sģów prawdopodobnie tworzą frazy w tym korpusie?
• Jakie są częste przedmioty, które kupuje ten klient?
• Jaka jest ķrednia liczba produktów na zamówienie?
• Jaki jest najczęstszy przedmiot znaleziony w jednym zamówieniu?
• Kiedy kupiģ laptopa, kiedy kupi drukarkę?
• Skoro kupiģ iPhone6, czy będzie zainteresowany iPhone7?
• Do której strony wszedģ, gdzie się przeniósģ, ile czasu tam spędziģ?
• Które choroby występują częķciej u osób z tą specyficzną sekwencją genową?
• Klienci, którzy kupili ten produkt, jakie inne produkty kupują?
• Jaka jest ķrednia liczba zamówieņ na klienta?
• Jaka jest ķrednia liczba unikalnych przedmiotów na zamówienie?
• Nietypowe kombinacje roszczeņ ubezpieczeniowych mogą byæ oznaką oszustwa,
• Jak je znaležæ?
• Historie pacjentów medycznych mogą wskazywaæ na prawdopodobne powikģania w oparciu o okreķlone kombinacje leczenia. Jak często występują te zdarzenia niepoŋądane?
Celem zasad asocjacji jest rozpoznanie ekscytujących relacji między przedmiotami. Kaŋda z odsģoniętych reguģ ma postaæ X → Y, co oznacza, ŋe gdy obserwowany jest punkt X, obserwowany jest równieŋ punkt Y. W tym przypadku lewa strona (LHS) reguģy to X, a prawa strona (RHS) tej reguģy to Y. Wežmy listę kilku transakcji podanych w pliku Transact.txt ze sklepu spoŋywczego sąsiadującego z centrum fitness.
Moŋemy chcieæ odpowiedzieæ na następujące pytania:
• Jakie dwa przedmioty będą częķciej kupowane razem niŋ jakiekolwiek inne przedmioty?
• Który produkt nigdy nie jest kupowany z Jam?
Na te pytania moŋna odpowiedzieæ, obserwując dane ręcznie. Teraz prawdziwym problemem jest to, w jaki sposób generujemy te reguģy automatycznie na duŋych danych?
TERMINOLOGIA ODKRYCIA WZORÓW
Zestaw przedmiotów: Kaŋda transakcja, która zawiera jedną lub więcej pozycji. Jest równieŋ znana jako zestaw przedmiotów. Termin itemset odnosi się do zbioru przedmiotów lub pojedynczych bytów, które zawierają pewien rodzaj relacji. Moŋe to byæ zestaw przedmiotów zakupionych razem w jednej transakcji, zestaw profili wyszukiwanych na LinkedIn w jednej sesji lub zestaw hiperģączy klikanych przez jednego uŋytkownika w danej sesji.
Zestaw elementów K: Zestaw elementów zawierający k elementów nazywa się zestawem elementów K. Uŋywamy nawiasów klamrowych, takich jak {pozycja 1, pozycja 2, ... pozycja k}, aby oznaczyæ zestaw k-pozycji.
Wsparcie: Jednym z kluczowych elementów reguģ stowarzyszenia jest wsparcie. Biorąc pod uwagę zestaw przedmiotów X, obsģuga X jest procentem transakcji zawierających X.
Bezwzględne wsparcie (liczba) X: Częstotliwoķæ lub liczba wystąpieņ zestawu przedmiotów X.
Obsģuga względna: Częķæ transakcji zawierająca X (tj. Prawdopodobieņstwo, ŋe transakcja zawiera X)
Dla 1 zestawu przedmiotów: Wsparcie = częstotliwoķæ (X) / N
Dla 2 zestawów przedmiotów: Wsparcie = częstotliwoķæ (X, Y) / N
W podanym przykģadzie, jeķli chleb pojawiģ się 4 razy w 5 transakcjach, to znaczy, ŋe 4/5 (80%) wszystkich transakcji zawiera itemset {chleb}, wówczas wsparcie {chleb} wynosi 0,8. Podobnie, jeķli 60% wszystkich transakcji zawiera itemset {Chleb, Mleko}, wówczas wsparcie {Chleb, Mleko} wynosi 0,6. Zestaw przedmiotów X jest częsty, jeķli wsparcie X jest nie mniejsze niŋ próg minsup (oznaczony jako ?). Częsty zestaw przedmiotów zawiera elementy, które pojawiają się razem ponad kryterium minimalnego wsparcia. Jeķli minimalne wsparcie jest ustawione na 0,5, dowolny zestaw przedmiotów moŋe byæ uwaŋany za częsty zestaw przedmiotów, jeķli wsparcie dla częstego zestawu przedmiotów powinno byæ większe lub równe minimalnemu wsparciu. W naszym przykģadzie zarówno {Chleb}, jak i {Chleb, mleko} są uwaŋane za częste zestawy przedmiotów przy minimalnym wsparciu 0,5.
Zaufanie: Zaufanie definiuje się jako miarę pewnoķci lub wiernoķci związaną z kaŋdą odkrytą reguģą. Matematycznie zaufanie jest procentem transakcji zawierających zarówno X, jak i Y spoķród wszystkich transakcji zawierających X.
Pewnoķæ, c: warunkowe prawdopodobieņstwo, ŋe transakcja zawierająca X równieŋ zawiera Y. Pewnoķæ = Częstotliwoķæ (X, Y) / Częstotliwoķæ (X)
Na przykģad jeķli {Chleb, Banan, Mleko} ma wsparcie 0,20, a {Chleb, Banan} ma równieŋ wsparcie 0,20, pewnoķæ reguģy {Chleb, Banan} ? {Mleko} wynosi 1, co oznacza 100% czasu, w którym klient kupuje chleb i banan, kupuje się równieŋ mleko. Zasada jest zatem poprawna dla 100% transakcji zawierających chleb i banan. Relacja jest ekscytująca, gdy algorytm identyfikuje relację za pomocą miary zaufania większej lub równej minimalnej ufnoķci. istnieje ograniczenie pewnoķci, poniewaŋ moŋe zidentyfikowaæ interesujące reguģy ze wszystkich reguģ kandydujących, bierze pod uwagę tylko poprzednik (X) i wspóģwystępowanie X i Y; to robi aby nie braæ pod uwagę konsekwencji reguģy (Y). Tak więc zaufanie nie jest w stanie stwierdziæ, czy reguģa zawiera prawdziwe implikacje relacji, czy teŋ reguģa jest czysto przypadkowa. Czasami X i Y mogą byæ statystycznie niezaleŋne, ale nadal uzyskują wysoki wynik ufnoķci. Winda poradzi sobie z tym problemem.
Podnoszenie: Podnoszenie mierzy, ile razy X i Y występują razem, niŋ się spodziewano, jeķli są statystycznie niezaleŋne od siebie. Wzrost jest miarą tego, w jaki sposób X i Y są naprawdę powiązane, a nie przypadkiem dzieje się razem.
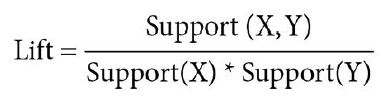
Wzrost wynosi 1, jeķli X i Y są statystycznie niezaleŋne od siebie. Natomiast wzrost X ? Y większy niŋ 1 wskazuje, ŋe reguģa jest warta zachodu. Większa wartoķæ wzrostu sugeruje większą skutecznoķæ powiązania między X i Y. Zakģadając 10 transakcji, z {Chlebem, Masģem} występującym w 4 transakcjach, {Chleb} występujący w 4, a {Masģo} występujący w 5, następnie Lift (Chleb ? Masģo) = 0,4 / (0,4 * 0,5) = 2,0 Jeķli {Masģo, Zboŋe} występujące w 3 transakcjach z nich, {Zboŋe} występujące w 4, a {Masģo} pojawiające się w 5, następnie Lift (Masģo ? Zboŋe) = 0,3 / (0,5 * 0,4) = 1,5. Obserwując je, moŋemy powiedzieæ, ŋe chleb i masģo mają silniejszy związek niŋ pģatki zboŋowe i masģo.
ALGORYTM APRIORI
Algorytm Apriori stosuje iteracyjne podejķcie do ujawnienia częstego zestawu przedmiotów, najpierw okreķlając wszystkie moŋliwe zestawy 1-przedmiotów, na przykģad {Bread}, {Cereal}, {Butter} i identyfikuje, które z nich są częste. Przyjmijmy, ŋe kryterium minimalnego wsparcia wynosi 0,5, algorytm identyfikuje i zachowuje zestaw przedmiotów, który pojawia się w co najmniej 50% wszystkich transakcji i odrzuca zestaw przedmiotów, który ma wsparcie mniejsze niŋ 0,5, proces ten nazywa się przycinaniem.
Zasada przycinania Apriori: jeķli jakiķ zestaw przedmiotów jest rzadki, jego nadzbiór nie powinien nawet zostaæ wygenerowany. W następnej iteracji zidentyfikowane częste zestawy 1-elementowe są sparowane w zestawy 2-elementowe ({Chleb, Pģatki}, {Chleb, Masģo}, ...) i ponownie oceniane pod kątem znalezienia wķród nich częstych zestawów 2-elementowych. Jest to proces iteracyjny, przy kaŋdej iteracji algorytm sprawdza, czy moŋna speģniæ kryterium wsparcia. Jeķli speģnia kryterium, algorytm powiększa zestaw elementów, powtarzając proces, aŋ skoņczy się obsģuga lub dopóki zestaw elementów nie osiągnie ustalonej dģugoķci.
Zaģoŋenia Apriori: Zaģóŋmy, ŋe {chleb, masģo} jest częste. Poniewaŋ kaŋde wystąpienie chleba, masģo obejmuje zarówno chleb, jak i masģo, to zarówno chleb, jak i masģo muszą byæ równieŋ częste. Tak więc, jeķli zestaw elementów K jest częsty, wszystkie jego podzestawy (zestawy elementów K-1, k-2) są równieŋ częste
Kroki w wykonaniu algorytmu Apriori:
• Zarys Apriori (poziom, generowanie i testowanie kandydatów)
• Początkowo zeskanuj DB raz, aby uzyskaæ częsty zestaw 1 elementów
• Powtórz
• Wygeneruj kandydujące zestawy przedmiotów o dģugoķci (k + 1) z zestawów przedmiotów o dģugoķci-k
• Przetestuj kandydatów na DB, aby znaležæ częste zestawy (k + 1)
• Ustaw k: = k +1
• Do momentu wygenerowania zestawu częstych lub kandydujących
• Zwraca wszystkie wyprowadzone częste zestawy przedmiotów
Zalety algorytmu Apriori:
• Uŋywa duŋej wģaķciwoķci itemset.
• Ģatwo zrównoleglony.
• Ģatwy do wdroŋenia.
Wady algorytmu Apriori:
• Zakģada, ŋe baza danych transakcji jest rezydentem pamięci. Wymaga do m skanowania baz danych. Algorytm Apriori moŋe byæ bardzo wolny, a wąskim gardģem jest generowanie kandydatów. Na przykģad, jeķli DB transakcji ma 104 częste zestawy 1 elementów, wygenerują 107 zestawów 2 elementów, nawet po zastosowaniu zamknięcia w dóģ. Aby obliczyæ te z sup więcej niŋ minsup, baza danych musi byæ skanowana na kaŋdym poziomie. Potrzebuje (n +1) skanów, gdzie n jest dģugoķcią najdģuŋszego wzoru.
Metody poprawy wydajnoķci Apriori:
1. Liczenie zestawów przedmiotów na podstawie skrótu: zestaw przedmiotów k, którego odpowiadająca liczba koszyków mieszających jest poniŋej progu, nie moŋe byæ częsta
2. Redukcja transakcji: Transakcja, która nie zawiera częstych zestawów przedmiotów K, jest bezuŋyteczna w kolejnych skanach
3. Partycjonowanie: Kaŋdy zestaw elementów, który jest potencjalnie częsty w DB, musi byæ częsty w co najmniej jednej partycji DB
4. Próbkowanie: eksploracja podzbioru danych, dolny próg wsparcia + metoda okreķlania kompletnoķci
5. Dynamiczne zliczanie zestawów przedmiotów: dodawaj nowy zestaw przedmiotów tylko wtedy, gdy szacuje się, ŋe wszystkie ich podzbiory są częste
Istnieje wiele zastosowaņ Reguģ Stowarzyszenia, które obejmują:
• Analiza koszyka rynkowego
• Fizyczne lub logiczne umieszczenie produktu w pokrewnych kategoriach produktów,
• Cross-marketing, (Cross Selling, Up selling)
• Projektowanie katalogu,
• Analiza kampanii sprzedaŋowych,
• Programy promocyjne,
• Analiza strumienia kliknięæ lub analiza dziennika internetowego,
• Analiza sekwencji biologicznych, systemy rekomendujące programy kart lojalnoķciowych, takie jak Amazon, Facebook, LinkedIn i Netflix
STUDIUM PRZYPADKU
Wczesnym rankiem wežmy zestaw danych transakcji w pobliŋu centrum fitness. Pozwól nam zrozumieæ, jakie są częste zakupy biegaczy lub spacerowiczów, i znajdž powiązanie między nimi, aby sklepikarz chciaģ przygotowaæ wymagane rzeczy dla swoich klientów.
Krok 1: Zaģaduj zestaw danych
setwd("D:/R data")
basket <-read.table("Transact.txt", header=TRUE, sep="\t")
Krok 2: Zobacz pierwsze 10 obserwacji
head(basket, n=10)
Krok 3: Zrozumienie struktury i częķci deskryptora danych
str (basket)
Krok 4: W razie potrzeby przekonwertuj zmienne numeryczne na czynniki
fac <- c (1,2,4)
basket [, fac] <- lapply (basket [, fac], factor)
str (basket)
Krok 5: Podziel dane
dt <- split(basket$Products, basket$ID)
Krok 6: Zaģaduj wymagane pakiety i biblioteki
if(!require(arules)) install.packages("arules")
Jesteķmy teraz gotowi wydobyæ kilka zasad. Zawsze będziesz musiaģ przejķæ wymagane minimum wsparcia i pewnoķæ siebie. Zaģóŋmy, ŋe chcielibyķmy ustawiæ minimalne wsparcie na 0.3 i minimalne zaufanie 0,8. Chcemy pokazaæ 5 najwaŋniejszych zasad
Krok 7: Uzyskaj zasady
rules <- apriori(basket, parameter = list(supp = 0.3, conf = 0.8)))
Krok 8: Konwertuj dane na poziom transakcji
dt2 = as(dt,"transactions")
summary(dt2)
inspect(dt2)
Krok 9: Znajdž najczęstsze przedmioty
itemFrequency (dt2, type = "relative")
itemFrequencyPlot (dt2, topN = 5)
Krok 10: Zgromadž i zwięžle zasady:
Jeķli reguģy są zbyt dģugie. Moŋemy zwięziæ reguģy, dodając parametr "maxlen" do twojej funkcji Apriori:
rules = apriori(dt2, parameter=list(support=0.3, confidence=0.8))
rules = apriori(dt2, parameter=list(support=0.3, confidence=0.8, minlen = 3))
rules = apriori(dt2, parameter=list(support=0.3, confidence=0.8, maxlen = 4)))
Krok 11: Konwertuj reguģy na ramkę danych
rules3 = as (rules, "data.frame")
write (rules, "D: \\ rules.csv", sep = ",")
Krok 12: Pokaŋ tylko okreķlone reguģy dotyczące produktów
inspect( subset( rules, subset = rhs %pin% "Bread" ))
Krok 13: Pokaŋ 10 najwaŋniejszych zasad
options(digits=2)
inspect(rules[1:10]))
Krok 14: Uzyskaj informacje podsumowujące
summary(rules)
Krok 15: Sortuj reguģy, poniewaŋ chcemy najpierw napisaæ najbardziej odpowiednie reguģy wedģug poufnoķci lub podnoszenia
rules<-sort(rules, by="confidence", decreasing=TRUE)
rules<-sort(rules, by="lift", decreasing=TRUE)
Krok 16: Usuņ niepotrzebne reguģy
Czasami reguģy się powtarzają. Jako analityk moŋesz usunąæ element z zestawu danych. Alternatywnie moŋesz usunąæ wygenerowane zbędne reguģy.
subset.matrix <- is.subset(rules, rules)
subset.matrix[lower.tri(subset.matrix, diag=T)] <- NA
redundant <- colSums(subset.matrix, na.rm=T) >= 1
which(redundant)
rules.pruned <- rules[!redundant]
rules<-rules.pruned
Krok 17: Wyczyķæ zasady
rules3$rules=gsub("\\{", "", rules3$rules)
rules3$rules=gsub("\\}", "", rules3$rules)
rules3$rules=gsub("\"", "", rules3$rules)
Krok 18: Podziel reguģę
library(splitstackshape)
Rules4=cSplit(rules3, "rules","=>")
names(Rules4)[names(Rules4) == 'rules_1'] <- 'LHS'
Rules5=cSplit(Rules4, "LHS",",")
Rules6=subset(Rules5, select= -c(rules_2))
names(Rules6)[names(Rules6) == 'rules_3'] <- 'RHS'"
Krok 19: Celowanie w przedmioty:
Teraz, gdy wiemy, jak generowaæ reguģy, ogranicz wydajnoķæ, powiedzmy, ŋe chcieliķmy kierowaæ elementy i generowaæ reguģy. Zilustrowano dwa typy celów, którymi moŋemy byæ zainteresowani na przykģadzie "Chleba":
# Co klienci prawdopodobnie kupią przed zakupem "Chleba"
rules<-apriori(data=dt, parameter=list(supp=0.5,conf = 0.8),
appearance = list(default="lhs",rhs="Bread"), control = list(verbose=F))
rules<-sort(rules, decreasing=TRUE,by="confidence")
inspect(rules[1:4])
# Co klienci prawdopodobnie kupią, jeķli kupią "Chleb"
rules<-apriori(data=dt, parameter=list(supp=0.5,conf = 0.7),
appearance = list(default="rhs",lhs="Bread"), control = list(verbose=F))
rules<-sort(rules, decreasing=TRUE,by="confidence")
inspect(rules[1:3])
Krok 20: Wizualizacja:
Wreszcie chcemy zmapowaæ reguģy na wykresie. Do tego potrzebujemy pakietu "arulesViz".
# Zainstaluj pakiet arulesViz
library(arulesViz)
plot(rules,method="graph",interactive=TRUE,shading=NA)
KROK 10
Szacowanie Gęstoķci Jądra
WPROWADZENIE
Kiedy patrzymy na dane, pierwszą rzeczą, którą chcemy dowiedzieæ się, czy to struktura danych, w tym celu tworzymy histogramy danych w oparciu o jedną lub więcej funkcji. Funkcje są równieŋ znane jako wymiary, zmienne, kolumny, dlatego uŋywamy tych terminów zamiennie. Histogram pokazuje wiele rzeczy, na przykģad miejsca, w których punkty danych są bardziej widoczne, a gdzie mniej. Moŋemy to nazwaæ Funkcjami gęstoķci prawdopodobieņstwa, poniewaŋ po prostu patrząc na histogram moŋemy powiedzieæ, jakie jest prawdopodobieņstwo wystąpienia okreķlonego punktu danych. Jest to jednowymiarowe oszacowanie gęstoķci. Ale jednowymiarowy histogram to za maģo, tak naprawdę to, czego naprawdę chcemy, to oszacowanie gęstoķci poģączenia. Czy sģyszysz historię pięciu niewidomych, którzy dotykają Sģonia i opisują go? Co oni tam robili? Kaŋdy niewidomy męŋczyzna w opowieķci wyjaķniający jeden wymiar sģonia i wreszcie moŋemy dojķæ do wniosku, poniewaŋ ŋaden z nich nie opisuje sģonia w caģoķci. Kiedy patrzymy na pojedynczy wymiar, moŋemy odnieķæ wraŋenie, ŋe dane mogą byæ niepoprawne. Jeķli spojrzymy na te same dane z innego wymiaru, mogę uzyskaæ zupeģnie inne wraŋenie. Teraz rzeczywistym rozkģadem moŋe byæ kombinacja tych dwóch w wspólnej przestrzeni. Celem oszacowania gęstoķci jest ustalenie wspólnej dystrybucji. Pozwól, ŋe dam ci jeszcze jeden przykģad, aby zrozumieæ oszacowanie gęstoķci. Wežmy naszą kartę kredytową za przykģad i uŋywamy jej normalnie przez wiele lat. Jeķli ktoķ ukradģ twoją kartę kredytową, moŋe uŋyæ karty nieco inaczej, poniewaŋ nie wie, w jaki sposób korzystamy z naszej karty i gdzie uŋywamy jej częķciej. Teraz wyobraž sobie, w jaki sposób firma wydająca karty kredytowe wykrywa to nieco nietypowe lub nieco nienormalne zachowanie? Jak to uchwyciæ? Co robi model? Pozwólcie, ŋe podam jeszcze jeden przykģad: otrzymaliķmy reklamę w Google dotyczącą okreķlonego sģowa kluczowego. Zwykle ludzie mogą klikaæ tę reklamę w pewnym tempie na podstawie danego dnia i liczby zapytaņ oraz liczby wyķwietleņ itp. Na podstawie tych sģów kluczowych. uzyskaæ w przybliŋeniu pewną liczbę kliknięæ. Wyobražmy sobie, ŋe mam konkurenta. Mój konkurent chce, aby moje pieniądze zostaģy zmarnowane. Co moŋe zrobiæ, moŋe stworzyæ robota, pisząc program, który wielokrotnie klika reklamę, za kaŋdym razem, gdy pojawia się pytanie dotyczące tego konkretnego punktu . Teraz czego oczekujesz od Google? Oczekujesz, ŋe Google wykryje to nienormalne zachowanie i miejsce, z którego dochodzi do kliknięæ. W tym miejscu przydatne jest wģaķnie oszacowanie gęstoķci jądra. Pozwól, ŋe powiem ci bardzo waŋną zasadę danych. Pierwszą rzeczą jest to, ŋe dane mają hierarchię. Drugą rzeczą jest to, ŋe dane mają strukturę i haģas. Dane zawsze będą miaģy strukturę i haģas. Naszym celem w nauczaniu bez nadzoru (szacowanie gęstoķci jądra) jest ustalenie, która częķæ, jeķli dane mają strukturę, a która częķæ danych ma haģas. Kiedy zrobiliķmy PCA, zachowaliķmy trochę. Gģówne skģadniki i odrzuciliķmy niektóre inne elementy, poniewaŋ uwaŋaliķmy, ŋe niektóre elementy mają w sobie strukturę, a inne mają haģas. Jak decydujemy, ile gģównych elementów musimy zachowaæ? Jak decydujemy, ile klastrów musimy utworzyæ? To jest nasze wezwanie i to jest piękno, jeķli nauka danych. Tutaj naszym celem jest dowiedzieæ się, jak skompletowaæ poŋądany model, aby wychwytywaģ on maksymalny sygnaģ, a nie szum. Jeķli uznamy, ŋe istnieje tylko jedno zachowanie uŋytkownika karty kredytowej, nie udaje nam się uchwyciæ struktury zachowania karty kredytowej, poniewaŋ istnieją róŋne rodzaje ludzi z róŋnymi rodzajami zachowaņ karty kredytowej, takimi jak sposób korzystania z karty przez nastolatków i sposób korzystania z karty przez producenta domu oraz w jaki sposób student korzysta z karty itp. W oparciu o domenę, którą masz do czynienia, musisz zdecydowaæ o strukturze i wspóģczynniku szumów oraz ile danych lub szumów moŋemy się tutaj spodziewaæ? Pozwolę sobie na prosty przykģad, jeķli mamy do czynienia z danymi tekstowymi, jeķli popatrzymy na naukową grupę dokumenty, moŋemy się spodziewaæ więcej danych i mniej haģasu, poniewaŋ są one dobrze napisane i nie byģoby bģędów ortograficznych i gramatycznych. Ale jeķli mamy do czynienia z danymi na Twitterze, moŋemy popeģniæ wiele bģędów ortograficznych. Na tej podstawie musimy sprawdziæ, ile danych potrzebujemy przechwyciæ i jak skomplikowany byģby mój model. Haģas moŋe byæ naturalny, a haģas moŋe byæ zamierzony. W scenariuszu dotyczącym karty kredytowej oszustwo jest umyķlnym haģasem, a na Twitterze jest to niezamierzony haģas.
CO TO JEST KERNEL?
Jądro jest specjalnym rodzajem funkcji gęstoķci prawdopodobieņstwa (PDF) z dodaną wģaķciwoķcią, ŋe musi byæ nieujemne, równe i rzeczywiste. Co to jest estymacja gęstoķci jądra? : Estymacja gęstoķci jądra jest nieparametryczną metodą szacowania funkcji gęstoķci prawdopodobieņstwa (PDF) ciągģej zmiennej losowej. Jest nieparametryczny, poniewaŋ nie zakģada ŋadnego podstawowego rozkģadu dla zmiennej. Metoda szacowania gęstoķci jądra przezwycięŋa dyskrecję podejķcia histogramu poprzez centrowanie gģadkiej funkcji jądra w kaŋdym punkcie danych, a następnie sumowanie w celu uzyskania oceny gęstoķci. Zasadniczo w kaŋdym punkcie danych tworzona jest funkcja jądra z punktem danych w ķrodku, co zapewnia symetrycznoķæ jądra względem danych. Plik PDF jest następnie szacowany jako ķrednia z zaobserwowanych punktów danych w celu utworzenia pģynnego przybliŋenia danych, aby zapewniæ, ŋe speģnia następujące wģaķciwoķci pliku PDF. Kaŋda moŋliwa wartoķæ pliku PDF, tj. Funkcja nie jest ujemna. Zdefiniowana caģka pliku PDF ponad jego zestawem pomocniczym wynosi 1. Szacunkowa gęstoķæ jądra jest sumą wypukģoķci, która jest przypisana do kaŋdego punktu danych, a wielkoķæ wypukģoķci reprezentuje prawdopodobieņstwo przypisane sąsiedztwu wartoķci wokóģ tego punktu danych . Kaŋda nierównoķæ jest wyķrodkowana w punkcie danych i rozkģada się symetrycznie, aby pokryæ sąsiednie wartoķci punktu danych. Kaŋde jądro ma przepustowoķæ i okreķla szerokoķæ guza. Większa przepustowoķæ skutkuje krótszym i szerszym wybrzuszeniem, które rozciąga się dalej od ķrodka i przypisuje większe prawdopodobieņstwo sąsiednim wartoķciom.
KROKI W BUDOWIE SZACUNKU GĘSTOĶCI ZIARNA
1. Wybierz jądro, typowe są jak normalne (gaussowskie), jednolite (prostokątne).
2. W kaŋdym punkcie danych zbuduj skalowaną funkcję jądra, gdzie K() jest wybraną funkcją jądra. Parametr h nazywa się przepustowoķcią, szerokoķcią okna lub parametrem wygģadzania.
3. Dodaj wszystkie indywidualne skalowane funkcje jądra i podziel przez n, co daje prawdopodobieņstwo 1 / n dla kaŋdego Xi. Zapewnia równieŋ, ŋe oszacowanie gęstoķci jądra integruje się z 1 w stosunku do jego zestawu wsparcia.
Wybór przepustowoķci
Wybór przepustowoķci jest najtrudniejszym krokiem w tworzeniu dobrego oszacowania gęstoķci jądra, który uwzględnia podstawowy rozkģad zmiennej. Moŋemy przestrzegaæ prostych zasad, takich jak:
1. Maģe h powoduje maģe odchylenie standardowe, a jądro umieszcza większoķæ prawdopodobieņstwa na punktach danych. Uŋywamy tego, gdy wielkoķæ próbki jest duŋa, a dane są ciasno upakowane.
2. Duŋe h powoduje duŋe odchylenie standardowe, a jądro rozkģada większe prawdopodobieņstwo z punktu danych na sąsiednie wartoķci. Uŋywamy tego, gdy próbka jest maģa, a dane są rzadkie. Funkcja density() w R oblicza wartoķci oszacowania gęstoķci jądra. Zastosowanie funkcji plot() do obiektu utworzonego przez density() wykreķli oszacowanie. Zastosowanie funkcji summary() do obiektu ujawni przydatne statystyki dotyczące oszacowania. Uŋywamy tej metody, aby poznaæ strukturę i gramatykę danych. Jeķli sģuchamy utworu muzycznego, moŋemy powiedzieæ, ŋe pochodzi on od Rahmana lub Ilayi radŋy.
Jak moŋemy to zrobiæ? Nasz mózg przechowaģ muzykę i znajduje strukturę w okreķlonej kolejnoķci. Nawiasem mówiąc, wykonujemy wiele oszacowaņ gęstoķci w naszym mózgu. Zaģóŋmy, ŋe wszystkie samochody na ķwiecie mają ten sam kolor i ksztaģt, widzieliķmy wiele danych, spróbuj skompresowaæ je do modelu. Nie pamiętamy wszystkich samochodów, ale wciąŋ moŋemy rozpoznaæ nowy samochód, poniewaŋ widzieliķmy wiele danych, rozpoznajemy, jakie są samochody, a następnie kiedy widzę inne dane lub nowy obiekt, mogę powiedzieæ, ŋe to samochód. Co się dzieje? Co robi twój mózg? Widzisz duŋo danych, twój mózg stworzyģ model, a gdy zobaczyģeķ nowy punkt danych, moŋesz zrozumieæ, ŋe to samochód. W tym celu wystarczy Twój model za kaŋdym razem, gdy nie potrzebujesz danych. Uŋywamy techniki KDE nawet w celu znalezienia wartoķci odstających. Oprócz tego, aby dowiedzieæ się, ile jest sygnaģu i szumu, moŋemy zdefiniowaæ, w jaki sposób zģoŋonoķæ modelu. Im bardziej zģoŋony model, zaczynamy rejestrowaæ haģas, jeķli model jest zbyt prosty, nie moŋemy uchwyciæ struktury. Tak więc musimy mieæ odpowiednią zģoŋonoķæ modelu. Oszacowanie gęstoķci ma wiele rzeczy psychologicznych, które robimy. Wyobražmy sobie sytuację, w której chcesz podarowaæ Ŋonie wyjątkowy prezent. Jak moŋe się czuæ / mierzyæ wyjątkowoķæ? Bierze wszystkie moŋliwe prezenty i oblicza prawdopodobieņstwo, jeķli prawdopodobieņstwo jest większe, nazywamy to normalnym. Jeķli prawdopodobieņstwo jest bardzo rzadkie, nazywamy to Unikatowym / Powieķcią. Oszacowanie gęstoķci jądra jest uŋywane w
• Oszustwo z wykorzystaniem karty kredytowej
• Wykrywanie wģamaņ
• Oszustwo sprzedawcy
• Zachowanie terrorystyczne
Oszacowanie gęstoķci sģuŋy nawet do rozwiązywania problemów klasyfikacyjnych. Wyobraž sobie, ŋe wzięliķmy sekwencję genów i dowiadujemy się, czy on jest cukrzycą, czy nie, wyobraž sobie zģoŋonoķæ modelu. Moŋemy mieæ 1 milion danych o sekwencji genów pacjentów z cukrzycą i 1 milion sekwencji genów osób bez cukrzycy. Wyobraž sobie tutaj zģoŋonoķæ. Zebraliķmy sekwencje genów 1 miliona pacjentów z cukrzycą i 1 miliona osób bez cukrzycy i staramy się ustaliæ częķæ sekwencję genów, na którą powinienem spojrzeæ i którą częķæ sekwencji genów muszę zmodyfikowaæ przy narodzinach dziecka, aby nie mógģ rozwinąæ cukrzycy przez caģe ŋycie. Jeķli wiemy, jak zbudowaæ estymację gęstoķci jądra, moŋemy zrobiæ tak skomplikowaną rzecz. Próbujemy znaležæ te sekwencje, które są bardziej powszechne u diabetyków, i jak mogę zmodyfikowaæ te sekwencje po urodzeniu, aby nigdy nie miaģy cukrzycy przez resztę ŋycia. Aby to zrobiæ, staramy się zrozumieæ oszacowanie gęstoķci, więc moŋemy zbudowaæ tak skomplikowany klasyfikator.
Szkolenie: Mogliķmy zobaczyæ wiele danych, zrozumieæ róŋne typy i sekwencje genów kompresujących je do ksztaģtu. Na tej podstawie staramy się stworzyæ model.
Punktacja: Po utworzeniu modelu zastosuj model do nowego punktu danych, tak jak gdy zobaczysz nowy punkt danych, moŋemy powiedzieæ, ŋe jest to sekwencja genowa cukrzycy, czy nie. Moŋemy nawet powiedzieæ, ŋe jakie jest prawdopodobieņstwo, ŋe będzie on miaģ cukrzycę. Podczas gdy histogram jest funkcjonalnie odpowiedni do wyķwietlania szerokiej gamy danych czesnych, tak moŋe byæ frustrujące wizualnie, aby zbadaæ rozkģad, poniewaŋ widz jest zmuszony do mentalnego poģączenia kropek między pojemnikami. Ponadto wybrane rozmiary pojemników i punkty ķrodkowe wydają się ukrywaæ trzy podgrupy w rozkģadzie. Wykres moŋna ulepszyæ, dodając szacunkową gęstoķæ jądra (KDE), poniewaŋ histogram moŋe byæ frustrujący i wprowadzaæ w bģąd, szczególnie gdy przedziaģy lub punkty ķrodkowe nie mają odpowiedniego rozmiaru lub poģoŋenia. Szacunki gęstoķci jądra zapewniają pģynną linię, podobną do "rozmiaru bin ", który moŋe znieksztaģciæ rozkģad danych na histogramie. Wybór przepustowoķci jest waŋną częķcią oszacowania gęstoķci jądra. W większoķci technik szacowania gęstoķci jądra jądra mają ten sam ksztaģt i szerokoķæ pasma. Chociaŋ istnieje kilka opcji wyboru metody przepustowoķci , które automatycznie wybierają odpowiedni rozmiar jądra, najbardziej popularna jest metoda Sheather-Jones Plug-In (SJPI), która jest uŋywana domyķlnie w procedurze KDE. Inne metody wyboru przepustowoķci:
• Simple Normal Reference (SNR),
• SNR z zakresem międzykwartylowym (SNRQ),
• Zasada kciuka Silvermana (SROT) i
• Ponad wygģadzony (OS).
Zrozumienie oceny gęstoķci jądra z analizą przypadku: Spójrzmy na dane Jewel, poszliķmy do sklepu jubilerskiego, gdzie obserwowaliķmy ozdoby z róŋnych metali i modeli. wymiar / cecha / zmienna / kolumna. Spójrzmy na zestaw danych Jewel, w powyŋszych danych chcemy pracowaæ nad dwiema cechami / zmiennymi / wymiarami / kolumnami, tj. metalem i modelem. Metal moŋe przyjmowaæ trzy dyskretne (Nominalne) wartoķci, tj. Srebro, Zģoto i Platynę, Model moŋe nawet przyjmowaæ trzy wartoķci Normalny, Fantazyjny, Antyczny. nazywamy to problemem klasyfikacyjnym. Chcemy tutaj znaležæ P (fantazyjne, zģote) i tak dalej. gdybym mógģ to zrobiæ dla wszystkich kombinacje, moŋemy powiedzieæ, ŋe zbudowaliķmy model. i wyrzucamy dane, poniewaŋ stworzyliķmy model, prawdopodobieņstwo wszystkich kombinacji.
Zróbmy to:
P (fantazyjne, platynowe) = liczba (fantazyjne, platynowe) / caģkowita liczba klientów = (15/150) = 0,10, więc moŋemy powiedzieæ, ŋe szacowanie gęstoķci naprawdę dotyczy liczenia i normalizacji. Jeķli mamy rzeczywiste wartoķci, dzielimy je na bin i wykonujemy histogramy, a następnie normalizujemy. Zastanówmy się nad stworzeniem modelu:
Co to jest P (zwykģy, srebrny) i co to jest P (antyczny, zģoty)? Jeķli obliczę wszystkie parametry, to skoņczę. Czy ma znaczenie, jak duŋy jest sklep z biŋuterią i ilu klientów jest tam? jeķli zbudujemy model, moŋemy go uŋyæ w maģym sklepie lub bardzo duŋym sklepie. Jeķli dane są ogromne, mój model będzie znacznie bardziej wytrzymaģy. W danych nie ma czegoķ takiego jak zģoŋonoķæ, moŋemy mieæ zģoŋonoķæ w modelu, ale nie w danych. Ilekroæ myķlimy o stworzeniu modelu dla KDE, musimy zadaæ sobie kilka pytaņ:
• Ile tu jest parametrów?
• Ile jest wolnych parametrów?
• Czy mamy jakieķ ograniczenia?
W tym przykģadzie mamy 9 (3 * 3) parametrów, a ograniczenie polega na tym, ŋe powinny się sumowaæ do jednego. Zatem wolne parametry to 8 (liczba parametrów - liczba ograniczeņ) (9-1).
Wolny parametr: Aby zrozumieæ wolny parametr, pozwól mi wziąæ przykģad rzucania monetą. Jeķli chcę oszacowaæ Prawdopodobieņstwa, wystarczy znaæ prawdopodobieņstwo Gģowy. Nie muszę znaæ prawdopodobieņstwa ogonów, poniewaŋ wiemy, ŋe P (ogon) + P (gģowa) równa 1. Więc gdy mamy ograniczenie, liczba wolnych parametrów zmniejsza się. Więc mogę obliczyæ
P (tail) = 1- P (head).
Ograniczenie: Jeķli rzucisz szeķciostronną kostką: Prawdopodobieņstwo uzyskania 1: 1/6, Prawdopodobieņstwo uzyskania 2: 1/6, ..., Prawdopodobieņstwo uzyskania 6: 1/6. Oznacza to, ŋe wszystkie szeķæ prawdopodobieņstw powinno sumowaæ się do 1. jest to ograniczenie. Zrozum prawdopodobieņstwo obliczeņ: jeķli jesteķ osobą, która martwi się wszystkimi rzeczami, które dzieją się wokóģ ciebie, uŋywasz wspólnego prawdopodobieņstwa. (Niepokój) Jeķli jesteķ osobą, która wcale nie martwi się o nic wokóģ ciebie, uŋywasz prawdopodobieņstwa. (Depresja). Wspólne prawdopodobieņstwo (zakģada, ŋe wszystko jest skorelowane): M = M1M2 ... Mn Przybliŋone prawdopodobieņstwo (zakģada, ŋe wszystko jest niezaleŋne): M = M1 + M2 + ... Mn. W pierwszym przypadku jest zbyt skomplikowany, a w drugim jest tak prosty, ŋe nie moŋna tego nawet uŋyæ w uczeniu maszynowym. Sztuką uczenia maszynowego jest znalezienie odpowiedniego modelu zģoŋonoķci. Wyobraž sobie, ŋe ktoķ zostaģ poproszony o sprawdzenie, które miasto jest preferowane dla osób starszych w Indiach, i zebraģeķ następujące informacje, takie jak wiek, dochód, wyksztaģcenie , poziom, ruch, zanieczyszczenie, temperatura itp. w róŋnych miastach. Teraz musimy odpowiedzieæ na pytania : Jak Bangalore, jeķli chodzi o zanieczyszczenie, wypada w porównaniu z Delhi? A co z ruchem drogowym? Czy preferencje miasta zaleŋą od wieku lub dochodów? Oszacowanie gęstoķci jądra w takich sytuacjach jest przydatne. Wežmy kolejny przykģad: w wywiadzie menedŋer chce wybraæ tych, którzy są bardzo dobrzy w kodowaniu, daģ zadanie ludziom i wyjaķniģ metodologię, którą naleŋy zastosowaæ. Zebraģ czas poķwięcony na wykonanie tego zadania w minutach. Po utworzeniu histogramu i obserwacji wykresu moŋemy zrozumieæ, jak wielu programistów zajmuje 15-20 minut wykonanie zadanie. Oznacza to, ŋe jeķli komuķ zajmuje więcej niŋ 40 minut (wartoķæ odstająca), moŋemy powiedzieæ, ŋe nie nadają się do pracy programisty.
STUDIUM PRZYPADKU
Zrozummy przypadek cukrzycy, w którym niewielu kobietom w ciąŋy podano glukozę doustnie, a wartoķæ glukozy w osoczu zebrano po godzinie, aby sprawdziæ, czy kobieta ma problem z cukrzycą wywoģaną ciąŋą, czy nie? Zebrano ķrednią i odchylenie standardowe "OGTT" i musimy utworzyæ wykresy gęstoķci. Z tego wynika, ŋe w tym zestawie danych przypadki cukrzycy są związane z wyŋszym poziomem "OGTT". Zostanie to wyjaķnione na podstawie wykresów funkcji szacowanej gęstoķci. Pokazuje szacunkowe gęstoķci p (OGTT | cukrzyca = 1), p(OGTT | cukrzyca = 0) i p (OGTT). Szacunki gęstoķci są szacunkami gęstoķci jądra z wykorzystaniem jądra Gaussa. Oznacza to, ŋe umieszczona jest funkcja gęstoķci Gaussa w kaŋdym punkcie danych, a suma funkcji gęstoķci jest obliczana w caģym zakresie danych. Funkcja jądra okreķla ksztaģt wypukģoķci, a szerokoķæ okna h okreķla ich szerokoķæ.
# Krok 1: Ustaw katalog roboczy i odczytaj dane
setwd('D:/R data')
Diabdata <- read.csv("Diab.csv", header=T)
# Krok 2: Utwórz wymagane obiekty z danych Diab
OGTT <- Diabdata[, 'OGTT']
d0 <- Diabdata[, 'Diabetic'] == 'No'
d1 <- Diabdata[, 'Diabetic'] == 'Yes'
# Krok 3: Utwórz wykres gęstoķci
plot(density(OGTT[d0]),bty="n",lwd=2, col='blue', xlim=c(10,250),
xlab="Oral Glucose Tolerance Test(OGTT)", ylab='estimate p(OGTT)',
main="Distribution of people by OGTT")
lines(density(OGTT[d1]),col="#FFCCCC")
#Krok 4: Upiększanie fabuģy:
# Wybierz i dodaj kod koloru HTML, który wygląda na przezroczysty na wydruku
polygon(density(OGTT),col="#FFCCCC")
#Dodaj linię dla ķredniej
abline (v = mean(OGTT))
#Dodaj szerszą i ciemnoszarą przerywaną linię dla ķrodkowej
abline (v = median(OGTT), lwd = 2, lty = 3, col = "# 999999")
KROK 11
Regresja
WPROWADZENIE
Analiza regresji jest techniką statystyczną stosowaną do wnioskowania o wielkoķci i kierunku moŋliwej zaleŋnoķci przyczynowo-skutkowej między obserwowanym wzorem a zmiennymi, które mają wpģyw na obserwowany wzór. Regresja powie ci, czy związek istnieje? To analityk decyduje, czy istnieje związek przyczynowy, czy nie. Statystyka - jest to wnioskowanie statystyczne. To (regresja) jest podejķciem matematycznym, a wszystkie zmienne wpģywające na wzór są losowymi próbkami z populacji bazowej. Wielkoķæ - Wielkoķæ wpģywu, Kierunek - Przyczyny dodatnie lub ujemne - Związek przyczynowo-skutkowy - np. wielkoķæ opadów musi wpģywaæ na uprawy , ale plon nie wpģywa na opady deszczu.
Studium przypadku: Zacznijmy od problemu, pracujesz dla firmy ubezpieczeniowej i chcesz zrozumieæ, co powoduje ofiary ķmiertelne na autostradach, aby pomóc w odpowiednim ustalaniu premii. Zaczynamy od zastanowienia się nad moŋliwymi czynnikami wpģywającymi na ofiary ķmiertelne. Alkohol, miesiąc, kierowcy, zatory, co jeszcze?. Moŋe byæ wiele innych przyczyn ofiar ķmiertelnych na drogach. Bardzo trudno jest przeanalizowaæ wszystkie moŋliwe ofiary ķmiertelne w kaŋdym kraju w populacji ķwiatowej. Zaģóŋmy, ŋe postanowiliķmy gromadziæ dane, które są ģatwo dostępne. Udaģo nam się uzyskaæ zestaw danych, który zawiera:
• Liczba ofiar ķmiertelnych miesięcznie
• Czy dzieņ byģ weekendem czy dniem tygodnia?
• Liczba licencjonowanych kierowców
• Liczba wypadków pod względem miesiąca
• Liczba mil przejechanych pojazdów na milę drogi (zatģoczenie)
• Kierowcy pod wpģywem alkoholu lub nie
Teraz, korzystając z tych danych, chcemy przeanalizowaæ związek między dostępnymi zmiennymi a ofiarami ķmiertelnymi, aby zaproponowaæ sposoby ustalania premii uwzględniające czynniki, które potencjalnie wpģywają na ofiary ķmiertelne. Jakie są moŋliwe sposoby oceny relacji? Moŋemy uŋyæ wizualizacji graficznych lub korelacji.
DLACZEGO REGRESJA?
Do tego problemu moŋna zastosowaæ techniki regresji, aby zrozumieæ wpģyw dostępnych zmiennych na zgony. Zaletą stosowania techniki regresji jest to, ŋe dzięki technice regresji moŋemy oceniæ wpģyw kaŋdego czynnika, biorąc pod uwagę wpģyw innych czynników, równieŋ wziętych jednoczeķnie. Po pierwsze, jeķli uwaŋamy, ŋe na Ķmieræ ma wpģyw kilka czynników, to zasadniczo postulujemy, ŋe ofiary ķmiertelne są funkcją zidentyfikowanych czynników:
Matematycznie jest reprezentowany w następujący sposób: - Zgony = f (kierowcy, zatory)
Gdy dowiemy się, ŋe wiele czynników ma wpģyw na liczbę ofiar ķmiertelnych, musimy wiedzieæ, w jaki sposób liczba kierowców i zatory mają wpģyw na liczbę ofiar ķmiertelnych. Rozwiązaniem naszego problemu jest regresja. Na razie ograniczmy się do przypadku, w którym jesteķmy martwiąc się tylko o jedną zmienną, która wpģywa na ofiary ķmiertelne w sposób liniowy. Mamy więc hipotezę, ŋe liczba zgonów roķnie wraz ze wzrostem liczby licencjonowanych kierowców.
Zgony = f (kierowcy), gdzie f jest dodatnie
Prosta regresja liniowa: Prosty model regresji liniowej jest zwykle oznaczany przez:
Y = β0 + β1X + e Gdzieβ0 = punkt przecięcia, β1 = nachylenie, e = bģąd. Musimy oszacowaæ bety, abyķmy mogli zrozumieæ związek między Y i X.
Zmienna zaleŋna: Y: Zmienne prognozowane: Zmienna, której zachowanie hipotetycznie moŋemy wyjaķniæ lub na które wpģyw mają inne czynniki.
Niezaleŋne zmienne: X: przewidywane predyktory wpģywają na zmienną zaleŋną.
Wspóģczynnik (wspóģczynniki) beta: oszacowanie wielkoķci wpģywu zmian predyktora (ów) na przewidywaną zmienną.
Bģąd: (e): Wpģyw nieobserwowanych zmiennych na zmienną zaleŋną zwykle obliczany jako róŋnica między przewidywaną wartoķcią Y przy szacowanej funkcji regresji a rzeczywistą wartoķcią Y.
• Jeķli B = 0, wówczas Y jest staģą, więc nie ma związku między Y i X, poniewaŋ niezaleŋnie od zmiany w X, Y się nie zmienia.
• Co się stanie, gdy punkt przecięcia = 0 ?. Linia regresji przechodzi przez Początek. (X α Y)
• Co się stanie, gdy Nachylenie = 0 . Linia regresji będzie równolegģa do osi X (brak zaleŋnoķci między zmienną zaleŋną i zmienną niezaleŋną).
Wracając do przykģadu ofiar ķmiertelnych, jeķli zaģoŋymy na chwilę, ŋe mamy tylko dane dotyczące liczby kierowców, a wówczas naszym modelem regresji byģoby, Zgony = β0 + β1 * Liczba kierowców + e
Jeķli oszacujemy wartoķæ β, będziemy mogli zrozumieæ, jak silny wpģyw ma liczba kierowców na liczbę ofiar ķmiertelnych, i przyjrzeæ się, co moŋna zrobiæ, aby zmniejszyæ liczbę ofiar ķmiertelnych. Istnieje wiele sposobów szacowania wspóģczynników beta. Na razie skupimy się na jednym z najbardziej intuicyjnych: zwykģej metdoa najmniejszych kwadratów.
REGRESJA ZWYKĢEJ METODY NAJMNIEJSZYCH KWADRATÓW (OLS)
Technika regresji metodą najmniejszych kwadratów zwykģych szacuje wspóģczynniki zmiennych, które mają wpģyw na zmienną będącą przedmiotem zainteresowania, identyfikując linię, która minimalizuje sumę kwadratów róŋnic między punktami na linii szacowanej i rzeczywistymi wartoķciami zmiennej niezaleŋnej
• Wspóģczynniki: Bety (β1 i β0)
• Minimalizuje: najmniej (wartoķæ)
• Suma róŋnic kwadratowych: Kwadrat reszt
• Szacowana linia: Linia regresji
• Rzeczywiste wartoķci: wartoķci w zestawie danych
Oczywiķcie moŋemy dopasowaæ wiele linii prostych, z których kaŋda pokryje niektóre punkty. Poniewaŋ linia prosta nie moŋe trafiæ we wszystkie punkty, jednym ze sposobów wyboru linii jest zidentyfikowanie linii, która wyjaķniģaby większoķæ zmian w Y, lub innymi sģowy, ma najmniejszy bģąd. Zwykģa regresja najmniejszych kwadratów znajduje tę linię, patrząc na reszty (lub róŋnicę między punktami na kaŋdej linii a rzeczywistym Y) i minimalizując sumę ich kwadratów. Resztki wychwytują wychwytują bģąd w szacowanej linii (róŋnica między szacowaną linią a rzeczywistymi wartoķciami). Po oszacowaniu linii ?0 jest przecięciem tej linii, podobnie ?1 jest nachyleniem tej linii. Jak w rzeczywistoķci oceniamy "najlepszą" linię? Moŋemy byæ pewni, ŋe biorąc pod uwagę dane, linia szacowania zwykģego najmniejszego kwadratu minimalizuje bģędy bardziej niŋ jakakolwiek inna linia, którą wybieramy. Czy jest jakaķ linia prosta, która moŋe trafiæ we wszystkie punkty?
Oszacowania OLS: regresja zwykģych najmniejszych kwadratów znajduje tę linię, patrząc na resztki (lub róŋnicę między punktami na kaŋdej linii a rzeczywistym Y) minimalizując sumę ich kwadratów. Dlaczego suma kwadratów?: Aby przezwycięŋyæ, dodatnie i ujemne róŋnice matematyczne, minimalizujemy
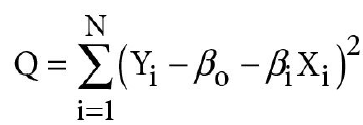
za pomocą rachunku róŋniczkowego otrzymamy
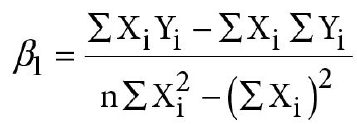
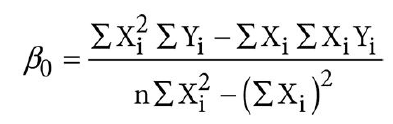
Oszacowania te nazywane są zwykģymi oszacowaniami najmniejszych kwadratów. A linia prosta reprezentowana przez Y = ?0 + ?1X będzie tutaj linią najmniej kwadratową. Szacunki te nazywane są linią szacunkową zwykģych najmniejszych kwadratów, która minimalizuje bģędy bardziej niŋ jakakolwiek inna linia, którą wybieramy. Po oszacowaniu wspóģczynników otrzymujemy takie równanie: Ķmieræ = Szacunek przechwytywania + Wspóģczynnik Beta * Liczba kierowców. Pamiętaj, ŋe jest to najlepiej dopasowana linia, ale ta linia nie obejmie kaŋdego punktu na wykresie punktowym. Jeķli obliczamy wartoķci ofiar ķmiertelnych na podstawie rzeczywistych wartoķci liczby kierowców, które widzimy w danych, obliczamy liczbę "przewidywanych" zgonów. Róŋnica między przewidywaną wartoķcią ofiar ķmiertelnych a rzeczywistą wartoķcią ofiar ķmiertelnych w danych dla kaŋdej wartoķci liczby kierowców to reszty. Korzystając z zestawu danych o ofiarach ķmiertelnych, uruchom prostą regresję i znajdž punkt przecięcia (A) i nachylenie (B). Dlatego teraz szacowana linia regresji będzie, Zgony = A + B * Liczba wspóģczynników beta kierowców: Dla kaŋdego wzrostu liczby kierowców w jednostce spodziewamy się wzrostu liczby ofiar ķmiertelnych o podaną liczbę. Oznacza to, ŋe dla wzrostu liczby kierowców o 100 nie spodziewamy się wzrostu liczby ofiar ķmiertelnych o tę liczbę. Znak dodatni na wspóģczynniku wielu kierowców oznacza pozytywny związek między liczbą kierowców a ofiarami ķmiertelnymi. P-Wartoķæ: H0 - Brak wpģywu nie. kierowców (oķ X) w przypadkach ķmiertelnych (oķ Y) Wartoķæ P-Wartoķæ: Jeķli wartoķæ p wynosi < 0,05, wówczas wspóģczynnik jest znaczący na poziomie 5%. Niŋsza wartoķæ p oznacza większe prawdopodobieņstwo odrzucenia hipotezy H0. Jeķli wartoķæ P jest znacznie mniejsza niŋ 0,05, odrzucamy H0. Wreszcie moŋemy stwierdziæ, ŋe ŋaden ze sterowników nie ma znaczenia statystycznego wpģyw na ofiary ķmiertelne. Chociaŋ równanie regresji jest najlepszym moŋliwym równaniem linii prostej, jak oceniamy skutecznoķæ caģego modelu? Jednym ze sposobów jest spojrzenie na miarę "Wyjaķnialnoķci", czyli na ile zmiennej zaleŋnej Y wyjaķnia X? Lub, lepiej to ująæ, ile wariancji w Y wyjaķnione przez X? Matematycznym sposobem na obliczenie tego jest:
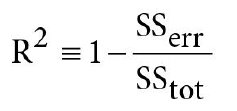
Gdzie
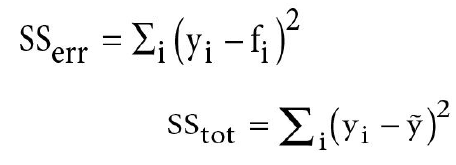
Oblicz na przykģad wartoķæ R-Square, jeķli R2 = 0,9399, oznacza to, ŋe 93,99% zmiany zmiennej ķmiertelnoķci jest wyjaķnione zmianą liczby zmiennych kierowcy. Im wyŋsza wartoķæ R2, tym większa zmiennoķæ zmiennej zaleŋnej (Y) tģumaczy się zmiennoķcią zmiennej niezaleŋnej (X). Zbuduj model z najlepszą moŋliwą R2 z danymi, które masz, wypróbowując róŋne kombinacje zmiennych, które masz. R2 jest jedynym sposobem sprawdzania poprawnoķci modelu, ale nie jedynym sposobem sprawdzania poprawnoķci modelu. R2 równieŋ roķnie wraz z dodawaniem zmiennych, istotnych lub nie, więc lepiej uŋyæ skorygowanego pomiaru R2. Skorygowany R2: Skorygowano R2 patrząc na wpģyw znaczących zmiennych w modelu. Nawet jeķli masz nieistotne zmienne w modelu, R2 wzroķnie, ale skorygowany R2 pójdzie w górę tylko model zawiera znaczące zmienne.
REJESTRACJA WIELU REGRESJI
Przejdžmy teraz do przypadku, w którym spodziewamy się, ŋe wiele zmiennych będzie miaģo wpģyw na okreķloną zmienną zaleŋną. Tak jest wyražnie w prawdziwym ŋyciu. Dopóki oczekujemy liniowej zaleŋnoķci między kaŋdą zmienną niezaleŋną a zmienną zaleŋną, moŋemy uŋywaæ technik najmniejszych kwadratów, która pozwala uzyskaæ estymatory wspóģczynników beta. Ponownie oszacowalibyķmy linię w wielu wymiarach, która zminimalizowaģaby sumę kwadratów reszt. Zastanówmy się nad trzema zmiennymi, które będą miaģy wpģyw na zgony: zatģoczenie, kierowca i alkohol. Zatory: jak zatģoczone są drogi miejskie? Kierowcy: Liczba licencjonowanych kierowców w mieķcie. Alkohol: 0 oznacza, ŋe kierowca nie piģ alkoholu, a 1 oznacza, ŋe kierowca spoŋywaģ alkohol. Równanie oszacowania OLS byģoby następujące:
Zgony = β0 + β1 * Zatory + β2 * Kierowcy + β3 * Alkohol + e
Teraz musimy oszacowaæ 4 wspóģczynniki Beta: ?0, ?1, ?2 i ?3. Zastosowalibyķmy to samo podejķcie OLS, aby zminimalizowaæ sumę kwadratów reszt w wielu wymiarach. Wspóģczynnik kierowcy zmieni się ze względu na to, ŋe teraz kontrolujemy równieŋ wpģyw zatorów i alkoholu. Jeķli celem jest przewidzenie wpģywu sterowników, nie uwzględniamy zmiennej modelu przeciąŋenia w modelu. W takim przypadku moŋemy upuķciæ zmienną przeciąŋającą i ponownie uruchomiæ model z tylko istotnymi zmiennymi.
ZBUDUJ MODEL I WALIDUJ GO NA PODANYM PLIKU WYPADKÓW
Krok 1: Zainstaluj i zaģaduj wymagane pakiety:
library(ggplot2)
library(caret)
library(lattice)
Krok 2: Zaģaduj dane
Fataldata =read.csv(file="D:\\R data\\Fatalities.csv", header=TRUE, sep=",")
Krok 3: Przeglądaj dane
str (Fataldata)
fix (Fataldata)
Krok 4: Przygotuj dane
4.1 Konwersja zmiennych kategorialnych na czynniki
Fataldata $ Weekend = as.factor (Fataldata $ Weekend)
Fataldata $ Alcohol = as.factor (Fataldata $ Alcohol)
Fataldata $ Month = wspóģczynnik as (Fataldata $ Month)
4.2 Usuņ zmienną zaleŋną
Fataldata_a = subset(Fataldata, select = -c(Deaths))
4.3 Zidentyfikuj zmienne numeryczne
numericdata <- Fataldata_a [sapply (Fataldata_a, is.numeric)]
4.4 Obliczanie korelacji
descrCor <- cor (numericdata)
highlyCorrelated <- findCorrelation(descrCor, cutoff=0.4)
4.5 Zidentyfikuj nazwy zmiennych wysoce skorelowanych zmiennych
highlyCorCol <- colnames(numericdata)[highlyCorrelated]
4.6 Wydrukuj wysoce skorelowane atrybuty
highlyCorCol
4.7 Usuņ wysoce skorelowane zmienne i utwórz nowy zestaw danych
dat3 <- Fataldata[, -which(colnames(Fataldata) %in% highlyCorCol)]
dim(dat3)
str(dat3
Krok 5: Zbuduj model regresji liniowej
fit0 = lm(Deaths ~ Drivers, data=Fataldata)
fit2 = lm(Deaths ~ Weekend, data=Fataldata)
fit3 =lm(Deaths ~ Weekend+Drivers, data=Fataldata)
fit =lm(Deaths ~ ., data=Fataldata)
Krok 6: Sprawdž wydajnoķæ modelu
summary(fit)
summary(fit0)
6.1 Wydzielanie wspóģczynników
summary(fit)$coeff
6.2 Wyodrębnianie wartoķci Rsquared
summary(fit)$r.squared
6.3 Wyodrębnianie Adj. Wartoķæ Rsquared
summary(fit)$adj.r.squared
6.4 Krokowy wybór na podstawie AIC
library(MASS)
step <- stepAIC(fit, direction="both")
summary(step)
6.5 Selekcja wsteczna na podstawie AIC
step <- stepAIC(fit, direction="backward")
summary(step)
6.6 Wybór do przodu na podstawie AIC
step <- stepAIC(fit, direction="forward")
summary(step)
6.7 Krokowy wybór za pomocą BIC
n = dim(dat3)
stepBIC = stepAIC(fit,k=log(n))
summary(stepBIC)
Krok 7: Diagnostyka modelu
Musimy sprawdziæ poprawnoķæ gģównych zaģoŋeņ modelu regresji liniowej. Odnosi się to do rozkģadu terminów bģędów modelu, tj. Jednorodnej wariancji, normalnoķci i niezaleŋnoķci. Analiza zaobserwowanych pozostaģoķci moŋe pomóc w ocenie prawdopodobieņstwa tego zaģoŋenia. Sprawdzanie nietypowych i wpģywowych obserwacji to kolejna częķæ diagnostyki regresji.
Sprawdzanie wartoķci odstających: Pakiet samochodowy zawiera test wartoķci odstających Bonferroni, który po prostu oblicza i ocenia wartoķci odstające.
library(car)
outlierTest(stepBIC) # Outliers - Bonferonni test
Sprawdzanie normalnoķci: Histogramy i wykresy ramkowe są równieŋ odpowiednie do sprawdzania normalnoķci, wraz ze statystykami opisowymi, takimi jak na przykģad skoķnoķæ i kurtoza.
hist(residuals(fit))
boxplot(residuals(fit))
# Normalnoķæ reszt: # wykres qq dla reszt studenckich
qqPlot (fit, main = "QQ Plot")
Test normalnoķci Shapiro-Wilksa: #Normalnoķæ reszt (powinna wynosiæ> 0,05). Hipotezą zerową jest to, ŋe reszty mają rozkģad normalny. Wartoķæ p statystyki testowej jest w tym przykģadzie duŋa. Wynika z tego, ŋe hipoteza zerowa nie zostaģa odrzucona.
res=residuals(stepBIC,type="pearson")
shapiro.test(res)
Autokorelacja: statystyka Durbina - Watsona jest statystyką testową stosowaną do wykrywania obecnoķci autokorelacji (relacji między wartoķciami oddzielonymi od siebie okreķlonym opóžnieniem czasowym) w resztach (bģędach prognozowania) z analizy regresji. Wartoķæ p wskazuje ŋe nie ma dowodów na skorelowane bģędy, ale wyniki naleŋy postrzegaæ sceptycznie ze względu na pominięcie brakujących wartoķci.
# Test na bģędy autokorelacji
durbinWatsonTest (stepBIC)
Wielokoliniowoķæ: Sprawdzamy VIF wszystkich zmiennych w celu przetestowania wielokoliniowoķci. Wspóģczynniki inflacji wariancji (VIF) mierzą, o ile zawyŋona jest wariancja szacowanych wspóģczynników regresji w porównaniu do tego, kiedy zmienne predykcyjne nie są liniowo powiązane. VIF jest uŋyteczny do opisania, jak wiele wielokoliniowoķci (korelacja między predyktorami) istnieje w analizie regresji. Wielokoliniowoķæ jest problematyczna, poniewaŋ moŋe zwiększaæ wariancję wspóģczynników regresji, czyniąc je niestabilnymi i trudnymi do interpretacji. Moŋemy uŋyæ następujących wytycznych do interpretacji VIF: Jeķli VIF jest mniejsza lub równa 1, moŋemy powiedzieæ, ŋe predyktory nie są skorelowane, Jeķli VIF wynosi od 1 do 5 predyktorów są umiarkowanie skorelowane, a jeķli VIF jest większy niŋ 5, moŋemy wyciągnąæ wniosek, ŋe predyktory są wysoce skorelowane.
# Oceņ wielokoliniowoķæ
vif (stepBIC) # zmiennoķæ czynników inflacyjnych
Homoscedastycznoķæ (staģa wariancja): Waŋnym zaģoŋeniem regresji liniowej jest brak heteroscedastycznoķci reszt. Oznacza to, ŋe wariancja reszt nie powinna rosnąæ wraz z dopasowanymi wartoķciami zmiennej odpowiedzi. utynowo sprawdza się heteroscedastycznoķæ reszt po zbudowaniu modelu regresji liniowej. Poniewaŋ chcemy sprawdziæ, czy w ten sposób zbudowany model nie jest w stanie wyjaķniæ jakiegoķ wzorca w zmiennej odpowiedzi (Y), która ostatecznie pojawia się w resztkach. Spowodowaģoby to nieefektywny model regresji, który mógģby dawaæ dziwne prognozy póžniej, kiedy faktycznie uŋywamy tego modelu. Istnieje kilka testów, które moŋemy wykorzystaæ do sprawdzenia obecnoķci lub braku heteroscedastycznoķci 1. Test Breusha-Pagana i 2. Test NCV.
Breush Pagan Test
HS_test1 <- bptest (fit) # Breusch-Pagan test
Test NCV
HS_test2 <- ncvTest (fit) # Niestaģy test wyniku wariancji
Zarówno HS_test1, jak i HS_test2 mają wartoķæ p mniejszą niŋ poziom istotnoķci 0,05, dlatego moŋemy odrzuciæ hipotezę zerową, ŋe wariancja reszt jest staģa i wnioskowaæ, ŋe heteroscedastycznoķæ jest rzeczywiķcie obecna. Moŋemy rozwiązaæ ten problem za pomocą dwóch metod:
1. Przebuduj model za pomocą nowych predyktorów. 2. Wykonaj transformację zmienną, taką jak transformacja Box-Cox.
Transformacja Box-Cox: Transformacja Box-Cox jest matematyczną transformacją zmiennej, która przybliŋa ją do rozkģadu normalnego. Przeprowadzenie przeksztaģcenia skrzynkowego zmiennej Y często rozwiązuje problem heteroscedastycznoķci.
Death_Boxcox <- caret :: BoxCoxTrans (Fataldata $ Deaths)
print (Death_Boxcox)
Model tworzenia transformowanej zmiennej box-Cox jest gotowy. Zastosujmy go teraz na Fatalata $ Deaths i doģączmy do nowej ramki danych. Doģącz przeksztaģconą zmienną do Fataldata.
Fataldata <- cbind(Fataldata, Deaths_new=predict(Death_Boxcox, Fataldata$ Deaths))
Przeksztaģcone dane dla naszego nowego modelu regresji są gotowe. Zbudujmy model i sprawdžmy heteroscedastycznoķæ.
Fatal_bc <- lm (Deaths_new ~., Data = Fataldata)
Ponownie wykonaj test Breuscha-Pagana, aby sprawdziæ, czy rozwiązano problem heteroscedastycznoķci.
bptest (Fatal_bc)
Poniewaŋ uzyskana wartoķæ P jest większa niŋ 0,05, moŋemy powiedzieæ, ŋe reszty są teraz homoscedastyczne.
Obserwacje wpģywowe: Obserwacja wpģywowa to obserwacja do obliczeņ statystycznych, których usunięcie z zestawu danych znacząco zmieniģoby wynik obliczeņ. Wpģywową obserwację definiuje się jako obserwację zmieniającą nachylenie z linii. Punkty wpģywające mają zatem duŋy wpģyw na dopasowanie modelu. Musimy więc sprawdziæ wpģywowe obserwacje w naszym zestawie danych. Miara odlegģoķci Cooka to poģączenie efektu resztkowego i džwigni. celem pomiaru odlegģoķci Cooka jest wykrycie wpģywowych obserwacji i wykrycie ģącznego wpģywu wartoķci odstających, zarówno w zmiennej odpowiedzi Y, jak i zmiennych wyjaķniających X.
# Wykres D Cooka: zidentyfikuj wartoķci D> 5 / (n-k-1)
cutoff <- 5/((nrow(Fataldata)-length(fit$coefficients)-2))
plot(fit, which=5, cook.levels=cutoff)
# Względne znaczenie
library(relaimpo)
calc.relimp(stepBIC)
# Patrz przewidywana wartoķæ
pred = predict(stepBIC,Fataldata)
# Patrz Rzeczywista vs. Przewidywana wartoķæ
finaldata = cbind (Fataldata, pred)
print(head(subset(finaldata, select = c(Deaths,pred)))
Krok 8: Obliczanie RMSE
rmse <- sqrt (mean ((Fataldata $ Deaths - pred) ^ 2))
print (rmse)
# Obliczanie Rsquared ręcznie
y = Fataldata[,c("Deaths")]
R.squared = 1 - sum((y-pred)^2)/sum((y-mean(y))^2)
print(R.squared)
#Calculating Adj. Rsquared ręcznie
n = dim(Fataldata)[1]
p = dim(summary(stepBIC)$coeff)[1] - 1
adj.r.squared = 1 - (1 - R.squared) * ((n - 1)/(n-p-1))
print(adj.r.squared)
KROK 12
Regresja logistyczna
WPROWADZENIE
Wiele problemów badawczych ma dychotomiczny wynik, niezaleŋnie od tego, czy klient odejdzie, czy nie, czy poŋyczka zostanie spģacona czy niespģacona, czy pacjent ma raka czy nie, i tak dalej. zwykle pytania te byģy rozwiązywane za pomocą zwykģej regresji metodą najmniejszych kwadratów (OLS) lub liniowej analizy funkcji dyskryminacyjnej. Jednak okazuje się, ŋe nie są one idealne do radzenia sobie z dychotomicznymi wynikami ze względu na ich ķcisģe zaģoŋenia statystyczne, takie jak liniowoķæ, normalnoķæ i ciągģoķæ regresji OLS i normalnoķæ wielowymiarową z jednakowymi wariancjami i kowariancją dla analizy dyskryminacyjnej. Regresja logistyczna rozszerza idee regresji liniowej na sytuację, w której zmienna zaleŋna Y jest kategoryczna. Moŋemy pomyķleæ o zmiennej kategorycznej jako podziaģ obserwacji na klasy. Na przykģad, jeķli Y oznacza, czy dany klient prawdopodobnie kupi produkt (1), czy nie kupi (0), mamy zmienną kategoryczną z 2 kategoriami lub klasami (0 i 1). Hipoteza regresji liniowej moŋe byæ znacznie większa niŋ 1 lub znacznie mniejsza niŋ zero, a zatem początki stają się trudne. W regresji logistycznej wykonujemy dwa kroki: 1. Znajdž szacunki prawdopodobieņstwa przynaleŋnoķci do kaŋdej klasy. Przypadek, gdy Y = 0 lub 1, prawdopodobieņstwo przynaleŋnoķci do klasy 1, P (Y = 1) i 2. Uŋyj wartoķci odcięcia dla tych prawdopodobieņstw, aby sklasyfikowaæ kaŋdy przypadek w jednej z klas. Na przykģad w przypadku binarnym wartoķæ graniczna wynosząca 0,5 oznacza, ŋe przypadki o szacowanym prawdopodobieņstwie P (Y = 1)> 0,5 są klasyfikowane jako naleŋące do klasy 1, natomiast przypadki o P (Y = 0) <0,5 są klasyfikowane jako naleŋące do klasy 0. Wartoķæ graniczną nie trzeba ustawiaæ na 0,5. Kiedy wydarzenie w pytaniu jest zdarzeniem o niskim prawdopodobieņstwie, wyŋsza niŋ ķrednia wartoķæ odcięcia, chociaŋ poniŋej 0,5 moŋe wystarczyæ do klasyfikacji. Decyzja o wartoķci granicznej to raczej "sztuka" niŋ nauka. Analiza regresji logistycznej stosowana do przewidywania zmiennych jakoķciowych (dwumianowa, porządkowa) przy uŋyciu kombinacji predyktorów ciągģych i dyskretnych. Regresja logistyczna jest stosowana, gdy zmienna zaleŋna: zmienna kategoryczna i zmienna niezaleŋna mają charakter ciągģy lub kategoryczny. Regresję logistyczną stosuje się, gdy cel badawczy koncentruje się na tym, czy zdarzenie miaģo miejsce, czy nie, a nie wtedy, gdy wystąpiģo, tj. Nie wykorzystano informacji o przebiegu czasu. Tutaj zamiast budowaæ model predykcyjny dla "Y (Response)", podejķcie modeluje Log Odds (Y); stąd nazwa Logistic lub Logit.
Przykģady:
• Domyķlnie - karta kredytowa
• Odpowiedž - Direct Mailer
• Przejęcie - klient
• Polecam - zakup
Wiele rodzajów regresji logistycznej
Log binarny:
• Uŋywany, gdy zmienna odpowiedzi jest binarna lub dychotomiczna
• Ma tylko 2 wyniki, np. Dobry v/s Zģy, Tak v/s Nie
Logizm wielomianowy:
• Uŋywane, gdy zmienna odpowiedzi ma więcej niŋ 2 wyniki, oraz
• Rezultatów nie moŋna zamówiæ w ŋaden sposób, np. wybór napoju, wybór miejsca turystycznego.
Logit zamówiony:
• Uŋywane, gdy zmienna odpowiedzi ma więcej niŋ 2 wyniki, oraz
• Wyniki moŋna uporządkowaæ w znaczący sposób, np. Wysoka / ķrednia / niska, mocno Zgadzam się / Zgadzam się / Nie zgadzam się / Zdecydowanie się nie zgadzam
Studium przypadku: Rozwaŋmy próbkę klientów, którzy zostali nagrodzeni przez bank kredytem mieszkaniowym. Chcemy stworzyæ model, który ocenia wpģyw wielu czynników na kwalifikowalnoķæ kredytu mieszkaniowego.
Dostępne są następujące dane:
• ID
• Wiek wnioskodawcy
• Pģeæ
• Doķwiadczenie w latach
• Miesięczny dochód w tysiącach
• Rozmiar rodziny
• Poziom edukacji
• Loan_Sanctioned lub nie
Jednym ze sposobów oceny wpģywu czynników na kwalifikowalnoķæ osobistej poŋyczki jest zbudowanie modelu regresji
• Kwalifikowalnoķæ poŋyczki = f (dochód, wiek, wyksztaģcenie)
Jakie byģoby równanie OLS dla takiego modelu regresji?
Kwalifikowalnoķæ (Y) = β0 + β1 * Dochód + β2 * Wiek + β3 * Edukacja + e
DLACZEGO REGRESJA LOGISTYCZNA?
Prawdopodobieņstwo Loan_Sanction nie jest liniowe. Widzimy, ŋe prawie nikt nie jest ukarany poŋyczką na niskim poziomie, a prawie wszyscy są sankcjonowani poŋyczką na wysokim koņcu dochodu. Zmiana prawdopodobieņstwa sankcjonowania poŋyczki na niskim i wysokim koņcu dochodu jest minimalna, podczas gdy w poģowie przedziaģu zmiana prawdopodobieņstwa jest duŋa. Jakie mogą byæ wartoķci Y?. Jeķli uŋyjemy modelu regresji liniowej, przewidywane wartoķci są nieograniczone (-∞ do +∞). Ale tutaj, w tym przypadku, wartoķci prawdopodobieņstwa są ograniczone do 0 do 1. Jednym wziąæ dziennik.
• p / (l-p) - moŋe przyjmowaæ wartoķci od 0 do,
• log (p / 1-p) moŋe przyjmowaæ wartoķci od -? do +?
• Matematyczną koncepcją leŋącą u podstaw regresji logistycznej jest logit, logarytm naturalny ilorazu szans.
Co to jest "iloraz szans"?: Jest to standardowy termin statystyczny oznaczający prawdopodobieņstwo sukcesu do prawdopodobieņstwa niepowodzenia. Jeķli prawdopodobieņstwo sukcesu wynosi 0,75, to iloraz szans = (0,75 / 0,25) = 3. Innymi sģowy, istnieje szansa na sukces 3:1. Przeksztaģcenie od prawdopodobieņstwa do szansy jest transformacją monotoniczną, co oznacza, ŋe szanse rosną wraz ze wzrostem prawdopodobieņstwa lub odwrotnie. Zakres prawdopodobieņstwa wynosi od 0 do 1. Zakres prawdopodobieņstwa wynosi od 0 do dodatniej nieskoņczonoķci. Transformacja z kursów do dziennika szans jest transformacją dziennika. Ponownie jest to monotoniczna transformacja. Oznacza to, ŋe im większe szanse, tym większy dziennik szans i vice versa. Dlaczego podejmujemy tyle trudu, by przeksztaģciæ prawdopodobieņstwo z logarytmu szans? Jednym z powodów jest to, ŋe zazwyczaj trudno jest modelowaæ zmienną o ograniczonym zakresie, na przykģad prawdopodobieņstwo. Ta transformacja jest próbą obejķcia problemu ograniczonego zasięgu. Odwzorowuje prawdopodobieņstwo w zakresie od 0 do 1, aby rejestrowaæ szanse od ujemnej nieskoņczonoķci do dodatniej nieskoņczonoķci. Innym powodem jest to, ŋe spoķród wszystkich nieskoņczenie wielu moŋliwoķci transformacji, log szans jest jednym z najģatwiejszych do zrozumienia i interpretacji. Ta transformacja nazywa się transformacją logit.
Formularz modelu regresji logistycznej
Wzór formularza jest zatem:
• Dodatek: log (p / 1-p) = Y = ?0 + ?1 * Dochód
• Pojęcia mnoŋące: (p / 1-p) = e ?0 * e ?1 * Dochód
• Wartoķci Y nie są ograniczone do 0 i 1.
• Transformacja logu ma liniowy związek z predyktorami (zmiana jednostki w X doprowadzi do staģej zmiany% w logY)
• Pod względem Y: zmiana jednostki w X doprowadzi do multiplikatywnej zmiany e? w Y (mnoŋnik szans)
• % zmiany w przybliŋeniu Y = 100 * (e ? -1) (dla maģych wartoķci wspóģczynnika)
Gdybyķmy chcieli model pod względem p:
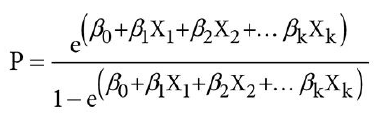
Gdzie:
P - Prawdopodobieņstwo zdarzenia
β0 - parametr przechwytujący (wartoķæ zmiennej zaleŋnej, gdy zmienna niezaleŋna (x) jest równa zero)
X - zbiór zmiennych niezaleŋnych (predyktory)
βk jest parametrem nachylenia (zmienna niezaleŋna od zmiany dla zmiany jednostkowej zmiennych predykcyjnych).
ZESTAW DANYCH POŊYCZEK KREDYTOWYCH
Bank chciaģ zrozumieæ czynniki, które wpģywają na kwalifikowalnoķæ do kredytu mieszkaniowego, na podstawie danych historycznych o jego obecnych klientach.
Przygotowanie danych: Przygotowanie danych dla regresji logistycznej obejmuje:
• Kodowanie zmiennej odpowiedzi: Zmienna odpowiedzi (lub zmienna docelowa) będzie musiaģa zostaæ przekonwertowana na 1/0. Kod "Sankcjonowana poŋyczka mieszkaniowa" jako "1" i "Odrzucona poŋyczka mieszkaniowa" jako "0".
• Brakujące traktowanie wartoķci - przy uŋyciu logicznych reguģ.
• Wykrywanie wartoķci odstających - aby upewniæ się, ŋe nie mamy mocno wypaczonych wartoķci.
• Wielokoliniowoķæ - dwie niezaleŋne zmienne nie dostarczają podobnych informacji.
• Transformacje zmienne - mamy znaczącą transformację zmiennych w zaleŋnoķci od zakresu badaņ i zakresu modelowania.
• Statystyka opisowa - naleŋy przedstawiæ podstawowe miary tendencji centralnej, aby sprawdziæ, czy do modelowania wykorzystywane są prawidģowe dane
Partycjonowanie danych: Podziel próbkę na 2 podpróbki, 1. Próbkę rozwojową (szkolenie), 2. Próbkę walidacyjną. Próbka programistyczna to próbka uŋyta do zbudowania modelu regresji logistycznej. Próbka walidacyjna sģuŋy do oszacowania uzyskanego z próbki programistycznej, która zostanie tutaj przetestowana w celu porównania i sprawdzenia odpornoķci modelu.
Zrównowaŋone próbki: idealnie: proporcja 1 do 0 nie powinna byæ mniejsza niŋ 2%. Jeŋeli "odsetek rzadkich zdarzeņ wynoszący 1: <2% - nadpróbka. Zachowaj rzadkie zdarzenia w próbce bez zmian. To sztuczne podejķcie nie zmienia nieodģącznej formy modelu. Ma wpģyw w staģym terminie lub punkcie przecięcia i musi zostaæ poprawiony po sfinalizowaniu modelu.
Wspóģczynnik korekcji zrównowaŋonej próbki: W tym przypadku mamy postaæ modelu regresji logistycznej jako
Log (pi / 1-pi) = a + blX1 + b2X2 + b3X3.
Oszacowanie parametru regresji logistycznej
Szacowanie dla logistyki: Wspóģczynniki dla równania logistycznego są szacowane przy uŋyciu techniki znanej jako oszacowanie maksymalnego prawdopodobieņstwa (MLE). MLE jest popularną metodą szacowania, poniewaŋ nie ma ŋadnych podstawowych zaģoŋeņ dotyczących dystrybucji. Gdy podstawowy rozkģad terminów bģędów jest normalny, oszacowania MLE są podobne do oszacowaņ OLS. OLS, podobnie jak wiele innych dystrybucji, jest szczególnym przypadkiem ML
WYKONANIE MODELU REJESTRACJI LOGISTYCZNEJ
Aby oceniæ wydajnoķæ modelu regresji logistycznej, musimy wziąæ pod uwagę kilka wskažników.
1. Test wspóģczynnika wiarygodnoķci: model utworzony przez regresję logistyczną jest uwaŋany za lepsze dopasowanie do danych, jeŋeli wykazuje dobre dopasowanie przy mniejszej liczbie predyktorów. W teķcie wspóģczynnika wiarygodnoķci porównujemy prawdopodobieņstwo danych w peģnym modelu z modelem z mniejszą liczbą predyktorów. Usunięcie zmiennych predykcyjnych z modelu prawie zawsze powoduje sģabsze dopasowanie modelu, ale konieczne jest sprawdzenie, czy zaobserwowana róŋnica w dopasowaniu modelu jest statystycznie istotna. Uwaŋamy, ŋe hipoteza zerowa (H0) utrzymuje, ŋe model zredukowany jest prawdziwy, a wartoķæ p dla ogólnej statystyki dopasowania modelu, która jest mniejsza niŋ 0,05, odrzucamy hipotezę zerową. Test wspóģczynnika prawdopodobieņstwa moŋna wykonaæ w R za pomocą funkcji lrtest () z pakietu lmtest lub za pomocą funkcji ANOVA () w bazie.
model <- glm (Loan_sanctioned ~ Wiek + Doķwiadczenie + Dochód + Rodzina,
dane = tren_poŋyczkowy, rodzina = dwumianowy)
model2 <- glm (Loan_sanctioned ~ Income + Family,
dane = tren_poŋyczkowy, rodzina = dwumianowy)
anova (model, model2, test = "Chisq")
biblioteka (lmtest)
lrtest (model, model2)
Uzyskaliķmy wartoķæ znacznie większą niŋ 0,05, więc nie odrzucamy hipotezy zerowej i dochodzimy do wniosku, ŋe usunięcie wieku i doķwiadczenia z modelu nie ma ŋadnego wpģywu na wydajnoķæ modelu.
2. Zmienne znaczenie: Uŋywamy funkcji varImp w pakiecie karetki, aby oceniæ względne znaczenie poszczególnych predyktorów w modelu, moŋemy równieŋ spojrzeæ na wartoķæ bezwzględną statystyki t dla kaŋdego parametru modelu.
biblioteka (karetka)
varImp (model)
varImp (model2)
Patrząc na wartoķci, moŋemy powiedzieæ, ŋe dochód i wielkoķæ rodziny odgrywają waŋną rolę w przewidywaniu, czy poŋyczka będzie sankcjonowana, czy nie. Moŋemy więc usunąæ Wiek i Doķwiadczenie z modelu.
3. Walidacja przewidywanych wartoķci (wskažnik klasyfikacji): Obejmuje to wykorzystanie oszacowaņ modelu do przewidywania wartoķci w zestawie treningowym i porównywania przewidywanej zmiennej docelowej z wartoķciami obserwowanymi dla kaŋdej obserwacji.
Macierz pomyģek: Macierz pomyģek jest tabelą, która jest często uŋywana do opisywania wydajnoķci modelu klasyfikacyjnego na zbiorze danych testowych, dla których znane są prawdziwe wartoķci.
Dokģadnoķæ: odsetek caģkowitej liczby poprawnych prognoz.
Dokģadnoķæ = (A + D) / (A + B + C + D)
Pozytywna wartoķæ predykcyjna lub precyzja: odsetek pozytywnych przypadków, które zostaģy poprawnie zidentyfikowane.
Precyzja = A / (A + B)
Negatywna wartoķæ predykcyjna: odsetek prawidģowo zidentyfikowanych przypadków negatywnych.
NPV = D / (C + D)
Czuģoķæ lub Przywoģanie lub Prawdziwie pozytywny wskažnik: odsetek rzeczywistych przypadków pozytywnych, które zostaģy poprawnie zidentyfikowane.
TPR = A / (A + C)
Swoistoķæ lub prawdziwie ujemny wskažnik: odsetek rzeczywistych przypadków ujemnych, które są poprawnie zidentyfikowane.
TNR = D / (B + D)
4. Krzywa charakterystyki pracy odbiornika (Krzywa ROC): Charakterystyka pracy odbiornika jest miarą wydajnoķci klasyfikatora. Korzystając z odsetka pozytywnych punktów danych, które są poprawnie uwaŋane za dodatnie, i odsetka negatywnych punktów danych, które bģędnie są uwaŋane za dodatnie, generujemy grafikę, która pokazuje kompromis między szybkoķcią, z jaką moŋna poprawnie przewidzieæ coķ z częstotliwoķcią niepoprawnie przewidywaæ coķ. Ostatecznie niepokoi nas obszar pod krzywą ROC lub AUROC. Ta metryka mieķci się w przedziale od 0,50 do 1,00, a wartoķci powyŋej 0,80 wskazują, ŋe model dobrze sobie radzi z rozróŋnianiem dwóch kategorii, które skģadają się na naszą zmienną docelową.
# Oblicz AUC dla przewidywania Poŋyczki z uwzględnieniem zmiennej Dochód
biblioteka (ROCR)
pred <- przewidywanie (przewidywanie, dane_ pociągu $ Poŋyczka_sankcjonowana)
perf <- wydajnoķæ (pred, "tpr", "fpr")
wykres (perf, koloruj = PRAWDA, text.adj = c (-0,2; 1,7)) wykres (f1, col = "czerwony")
auc <- wydajnoķæ (pred, Measure = "auc")
auc <- auc@y.values [[1]]
auc
Uzyskaliķmy wartoķæ auc (Area Under Curve), która jest większa niŋ 90%, dzięki czemu moŋemy stwierdziæ, ŋe nasz model dziaģa bardzo dobrze, i nasz model zostaģ zatwierdzony. Krzywa ROC jest praktycznie niezaleŋna od wskažnika odpowiedzi. Jest tak, poniewaŋ ma dwie osie wystające z obliczeņ kolumnowych macierzy pomieszania. Licznik i mianownik zarówno osi x, jak i y zmienią się na podobnej skali w przypadku przesunięcia wskažnika odpowiedzi. Jest to zaleta stosowania krzywej ROC.
5. Bģąd ķredniego kwadratu pierwiastkowego (RMSE): RMSE jest najpopularniejszym miernikiem oceny stosowanym w problemach z regresją. Wynika to z zaģoŋenia, ŋe bģąd jest bezstronny i ma normalny rozkģad. Charakter "kwadratowy" tej metryki pomaga uzyskaæ bardziej wiarygodne wyniki, które zapobiegają anulowaniu dodatnich i ujemnych wartoķci bģędów. Unika stosowania bezwzględnych wartoķci bģędów, co jest wysoce niepoŋądane w obliczeniach matematycznych. Na wartoķci RMSE duŋy wpģyw mają wartoķci odstające. Dlatego musimy upewniæ się, ŋe usuwamy wartoķci odstające z naszego zestawu danych przed uŋyciem tej miary.
6. AIC (Akaike Information Criteria): AIC jest miarą dopasowania, która karze model za liczbę wspóģczynników modelu. Dlatego zawsze preferujemy model o minimalnej wartoķci AIC.
7. Walidacja krzyŋowa skģadania K: W tej metodzie dzielimy dane na k jednakowych rozmiarów segmentów (zwanych "faģdami"). Jeden faģd jest trzymany w celu walidacji, podczas gdy inne faģdy k-1 są wykorzystywane do trenowania modelu, a następnie wykorzystywane do przewidywania zmiennej docelowej w naszych danych testowych. Ten proces powtarza się k razy, przy czym wydajnoķæ kaŋdego modelu w przewidywaniu zestawu wstrzymaņ jest ķledzona przy uŋyciu metryki wydajnoķci, takiej jak dokģadnoķæ. Najczęstszą odmianą walidacji krzyŋowej jest 10-krotna walidacja krzyŋowa. Walidacja krzyŋowa k-fold jest szeroko stosowana do sprawdzania, czy model jest pasujący czy nie. Dla maģego k mamy większy bģąd selekcji, ale niską wariancję występów. Dla duŋego k mamy maģy bģąd selekcji, ale duŋą zmiennoķæ występów.
Test Hosmera-Lemeshowa: Statystyka Homera-Lemeshowa, która jest obliczana na podstawie danych po podzieleniu obserwacji na grupy na podstawie porównywalnych przewidywanych prawdopodobieņstw. Sprawdza, czy zaobserwowane proporcje zdarzeņ są podobne do przewidywanych prawdopodobieņstw wystąpienia w podgrupach zbioru danych za pomocą testu chi-kwadrat. Maģe wartoķci z duŋymi wartoķciami p wskazują na dobre dopasowanie do danych, natomiast duŋe wartoķci z wartoķciami p poniŋej 0,05 wskazują na sģabe dopasowanie.
BUDOWA REJESTRACJI LOGISTYCZNEJ
#Krok 1: Ģadowanie danych do R:
setwd("D:/R data")
loandata=read.csv(file="Housing_loan.csv", header=TRUE)
# Krok 2: Przygotowanie danych:
# Usuņ kolumny ID i pģeæ z danych
loandata2=subset(loandata, select=-c(ID, Gender))
fix(loandata2)
Krok 3: Utwórz zmienne Dummy:
# Zmienna "Edukacja" ma więcej niŋ dwie kategorie (1: licencjackie, 2: magisterskie, 3: zaawansowane / profesjonalne), więc musimy stworzyæ fikcyjne zmienne dla kaŋdej kategorii aby uwzględniæ je w analizie
#Zainstaluj i zaģaduj pakiet "dummies", aby utworzyæ zmienne zastępcze
install.packages("dummies")
library(dummies)
Edu_dum=dummy(loandata2$Education)
head(Edu_dum)
loandata3=subset(loandata2,select=-c(Education))
loandata4=cbind(loandata3,Edu_dum)
head(loandata4)
#Krok 4: Standaryzacja danych:
Standaryzuj dane, stosując metodę "Range"
install.packages("vegan")
library(vegan)
loandata5=decostand(loandata4,"range")
# Krok 5: Przygotuj zestawy danych Train & Test:
Pobierz losową próbkę 80% rekordów danych pociągu.
train = sample(1:1000,800)
train_data = loandata5[train,]
nrow(train_data)
# Wež losową próbkę 20% rekordów dla danych testowych
train = sample(1:1000,800)
train_data = loandata5[train,]
nrow(train_data)
#Krok 6: Podsumowanie danych dla zmiennej odpowiedzi "Loan_sanctioned":
table(loandata5$Loan_sanctioned) #Total Data
table(train_data $Loan_sanctioned) #Train Data
table(test_data$Loan_sanctioned) #Test Data
#Krok 7: Zbuduj model regresji logistycznej
model<- glm(Loan_sanctioned~ Age+Experience+
Income+Family+ Education1+Education2+ Education3,
data=train_data, family = binomial)
Krok 8: Sprawdž podsumowanie modelu i oceņ model, uzyskując macierz nieporozumieņ
summary(model)
predict <- predict(model, type = 'response')
table(train_data$Loan_sanctioned, predict > 0.5)
Krok 9: Utwórz krzywą ROC i sprawdž obszar pod krzywą
pred <- prediction(predict, train_data$Loan_sanctioned)
perf <- performance(pred, 'tpr','fpr')
plot(perf, colorize = TRUE, text.adj = c(-0.2,1.2))
#Krok 10: Wypróbuj róŋne kombinacje zmiennych i oceņ wydajnoķæ modelu
model2<- glm(Loan_sanctioned~ Age+Experience+Income+Family,
data=loan_train, family = binomial)
summary(model2)
predict <- predict(model2, type = 'response')
# macierz konfuzji
table(loan_train$Loan_sanctioned, predict > 0.5)
model3<- glm(Loan_sanctioned~ Income+Family,
data=loan_train, family = binomial)
summary(model3)
predict <- predict(model3, type = 'response')
# macierz konfuzji
table(loan_train$Loan_sanctioned, predict > 0.5)
KROK 13
Drzewa Decyzyjne
WPROWADZENIE
Drzewo decyzyjne jest potęŋną metodą klasyfikacji i prognozowania oraz uģatwiającą podejmowanie decyzji w sekwencyjnych problemach decyzyjnych. Moŋemy uŋyæ trzech rodzajów drzew decyzyjnych, tj. 1. Aby zareagowaæ na dziaģanie w oparciu o sekwencję węzģów informacyjnych 2. Drzewa klasyfikacji i regresji oraz 3. Drzewa przetrwania. Ale przez większoķæ czasu uŋywamy drzewa decyzyjnego do rozwiązywania problemów z klasyfikacją. Przyjrzyjmy się niektórym problemom i zrozummy, czy jest to problem klastrowania, czy problem klasyfikacji.
1. Rodzaje stron w sieci?
2. Czy zatwierdziæ osobistą poŋyczkę, czy nie?
3. Rodzaje klientów centrum handlowego?
4. Czy ten klient kupi produkt, czy nie?
5. Jakie jest następne miejsce, które turysta chciaģby odwiedziæ?
6. Czy sygnaģem radiowym jest supernowa, biaģy karzeģ czy czerwony gigant?
7. Rodzaje osób na Twoim koncie Facebook / LinkedIn?
8. Rodzaje wiadomoķci e-mail w skrzynce odbiorczej?
9. Ten artykuģ dotyczy sportu, rozrywki, polityki czy nauki?
10. Rodzaje genów w ludzkim genomie?
Jaka jest róŋnica między grupowaniem a klasyfikacją? Ilekroæ nie podajesz celu do przewidzenia, jeķli powiem, ŋe jest tu kilka stron internetowych, podaģem tylko te informacje, wtedy moŋemy pomyķleæ o strukturze danych, na przykģad o tym, jakie rodzaje stron tam są, pozwól mi zrobiæ grupowanie i rozwiązaæ. Kolejne pytanie brzmi: ilu jest klientów, nie jesteķmy tego pewni. Jeķli nie jesteķmy pewni co do celu, jeķli otrzymamy tylko dane wejķciowe, X, a nie Y, wówczas spróbujemy zrobiæ coķ takiego jak grupowanie, PCA lub dowolna inna technika uczenia bez nadzoru. Ale ilekroæ otrzymasz dane wejķciowe i wyjķciowe do przewidzenia, powiem tutaj, ŋe historia transakcji przewiduje oszustwo, a nie oszustwo. Oto wiadomoķæ e-mail z informacją, czy jest to promocja spamu, czy gģówna. Kiedy zadam ci wskazane pytanie, zaklasyfikuj je do jednej z kategorii, to jest to problem z klasyfikacją. Jak to dziaģa w prawdziwym ķwiecie? pozwólcie, ŋe wezmę przykģad taksówki Uber. Kiedy zaģoŋyli firmę, zaczynają otrzymywaæ informacje zwrotne od klientów, nie wiedzą, jaki rodzaj opinii otrzymują, więc zrobili grupowanie. Wyobraž sobie, ŋe zebrali się w pięciu klastrach, a kiedy wymyķlą pięæ klastrów, skonfigurują proces okreķlający, co zrobiæ dla kaŋdego klastra. Teraz te klastry stają się etykietami klas. Teraz następna informacja zwrotna musi zostaæ przypisana do jednej z nich. Jeķli nie, to musi to byæ osobna klasa. Jeķli naleŋy do jednego z juŋ utworzonych grup, a następnie wiesz, co robiæ, w przeciwnym razie musisz utworzyæ proces wokóģ tego. Musimy więc zrozumieæ, czy struktura zostaģa odkryta, czy nie. Wyobraž sobie, ŋe skargi klientów trafiają na jeden adres e-mail, a następnie musimy zacząæ je klasyfikowaæ. Moŋemy przyjąæ wszystkie 100 tysięcy skarg, pogrupowaæ je w 5-6 rodzajów skarg. Jak mapujesz surowe dane na typy, aby odkryæ typy, potrzebujemy grupowania. kiedy znamy typy, dokonujemy klasyfikacji.? moŋemy uzyskaæ nowe skargi poza podanymi typami, a następnie utworzymy nową klasę.
Opisowe vs. Dyskryminujące klasyfikatory: kiedy ludzie patrzą na dane, poģowa z was robi jedną rzecz, a druga poģowa robi drugą rzecz. Niektórzy z was mogą zbudowaæ model dla kaŋdej klasy, na przykģad jaka jest struktura i ksztaģt klasy. model ten nazywa się modelem opisowym, co oznacza, ŋe opisujesz, jak wyglądają dane. Druga poģowa z was mówi: hej, jak mam rozróŋniæ tych dwóch. Nie dbam o ksztaģt jednego kontra drugi, dbam o granicę jednego kontra drugiego. Dyskryminacyjne klasyfikatory nie polegają na ksztaģcie klasy, ale na granicy. Myķlcie, ŋe klasyfikatorzy opisowi są ministerstwem kraju, dbają o ksztaģt kraju w ķrodku. jak w tych dwóch krajach kaŋdy jest zainteresowany swoim krajem, ale dyskryminujący klasyfikatorzy są jak ministerstwo obrony. skupiają się bardziej na granicy. ci dwaj patrzą na te same dane, ale na róŋne sposoby. Pozwól, ŋe wezmę mój zestaw danych, dokonaģem inŋynierii funkcji, teraz Jeķli wezmę jedną klasę, po prostu zajmę się jedną klasą, obliczę ķrednią i macierz kowariancji tej klasy, i to samo dla pozostaģych dwóch, to mam te trzy parametry Kiedy obliczam ķrednią i kowariancję jednej klasy, po prostu rozwaŋam tę klasę i nie przejmuję się drugą klasą. Macierz kowariancji będzie opisywaæ ksztaģt, a ķrednia będzie opisywaæ lokalizację. Jeķli uŋyję innego rodzaju klasyfikatora, regresji logistycznej, spróbuje on oddzieliæ klasy. Tutaj obaj robią to samo, ale w inny sposób.
CO TO JEST KLASYFIKACJA?
W klasyfikacji chcemy sklasyfikowaæ dane w taki sposób, aby jedna grupa zawieraģa punkty z jednej klasy, a inna grupa zawieraģa punkty z innej klasy. chcemy podzieliæ przestrzeņ na regiony, które powinny byæ czyste w odniesieniu do wszelkich etykiet mojej klasy. Wežmy przykģad Indii podzielonych na stany, co wykorzystali jako kryteria. Uŋywali języka, poniewaŋ chcą wymyķliæ identycznoķæ, aby punkty w jednej grupie byģy do siebie podobne, a punkty w innej grupie byģy do siebie podobne. Klasyfikacja dzieli przestrzeņ (cechę) na czyste regiony przypisane do kaŋdej klasy. Jeķli mamy przestrzeņ podobną do grupy punktów, moŋemy ją przesuwaæ, ale moŋemy przenosiæ partycje. Mamy przestrzeņ funkcji, która pochodzi z caģej inŋynierii funkcji, którą wykonaģeķ ,upewnij się, ŋe są znormalizowane itp. W tym obszarze funkcji mamy kilka punktów danych i chcemy stworzyæ granicę decyzji. ta granica podzieli przestrzeņ na mniejsze regiony, a teraz ile granic decyzji mógģbym wybraæ? Jakie są moŋliwe sposoby podziaģu przestrzeni na partycje? odpowiedž jest nieskoņczona. Mógģbym uŋyæ nieskoņczonej liczby sposobów na podzielenie przestrzeni na dwa regiony. spoķród wszystkich nieskoņczonych sposobów wielu partycji muszę znaležæ jedną partycję, która speģnia kryteria, która maksymalizuje kryteria. Jakie są te kryteria? Kryteria są takie, ŋe kaŋdy region powinien byæ tak czysty, jak to moŋliwe, w odniesieniu do etykiety klasy. ale nigdy nie uzyskamy idealnej partycji. Przyczyny mogą byæ następujące:
• Przestrzeņ funkcji moŋe byæ niepeģna, mogliķmy przeoczyæ waŋną funkcję.
• Mogą występowaæ wartoķci odstające,
• Haģas w funkcjach,
• Model moŋe nie byæ idealny,
• Haģas na etykiecie, przy tych wszystkich regionach moŋemy nie uzyskaæ idealnego modelu.
Dlatego nasza praca naukowca danych jest bardzo trudna. Mamy listę powodów, dla których nasz model nie dziaģa. Kiedy klasyfikujemy przestrzeņ do niektórych regionów, a kaŋdy z nich ma swój wģasny zestaw czystoķci. niektóre klasy mają większą czystoķæ w porównaniu do innych. Czy mogģem zrobiæ lepiej? Mógģbym podzieliæ się na mniejsze regiony, patrząc na więcej funkcji. Mógģbym stworzyæ granice nieliniowe, zbudowaģbym bardziej zģoŋone modele, aby zrobiæ jeszcze lepiej. Mógģbym zrobiæ tak wiele rzeczy, aby ulepszyæ ten klasyfikator. Wyobraž sobie, ŋe ktoķ przekazaģ ci ten zestaw danych do opracowania, jaki jest najprostszy model, jaki moŋesz wymyķliæ? taka jest granica decyzyjna prostej prostej, ale jaki jest problem z prostą granicą, nie jest ona tak czysta, jak byķ chciaģ. więc ideą jest prostota nie oznacza czystoķci ani dokģadnoķci. Co mógģbyķ teraz zrobiæ? Jeķli piszę matematycznie, jaki to model? Sigma (W0 + EWiXi) da to linię, z linią o tym poziomie zģoŋonoķci modelu moŋesz zrobiæ tylko tyle. Będzie tylko jeden optymalny, jeķli ograniczę cię do modelu liniowego. Teraz mówimy nie, Linear nie jest wystarczająco dobry, potrzebujemy czegoķ bardziej zģoŋonego, co teraz robimy? Przyjmujemy regresję logistyczną i komplikujemy ją, dodając funkcje nieliniowe. Nie tylko więcej funkcji, jesteķmy ograniczeni funkcjami, ale czy moŋemy je poģączyæ razem. Teraz mogę powiedzieæ coķ takiego jak Sigma (W0 + EWiXi + EWijXiXJ) teraz otrzymujemy bardziej zģoŋony model, ile parametrów mam teraz? W0 -> 1, EWiXi -> n, EWijXiXJ -> N wybierz 2, co oznacza, ŋe kiedy zwiększę zģoŋonoķæ poprzez dodanie większej liczby parametrów, moŋemy zbudowaæ bardziej zģoŋoną granicę decyzji. Wyobražmy sobie sytuację, w której zbudowaliķmy model z wielomianem stopnia 2 (kwadraty drugiego rzędu). I inny model z wielomianem stopnia 9, poniewaŋ istnieje wiele róŋnych 9 infekcji, więc jest to wielomian 9 stopnia, który wykonuje dobrą robotę, w porównaniu z wielomianem pierwszego stopnia, który jest klasyfikatorem liniowym. Czy mogę zrobiæ jeszcze lepiej? Wyobraž sobie, ŋe jeķli wezmę wielomian 100 stopnia, istnieje tutaj bardzo waŋna zasada, którą musimy zrozumieæ, pomyķl teraz, który z tych trzech modeli jest rozsądnym modelem? Gdzie byķ przestaģ oczywiķcie nikt nie chce przejķæ do wielomianu 100 stopnia, nawet jeķli daje to dokģadniejsze wyniki. Pozwól, ŋe porozmawiam o ogólnej zasadzie niezaleŋnej od problemu. Nasza zasada mówi, czy mam pobiæ dane do przesģania? jeķli zrobimy trzeci, nie moŋemy wyjaķniæ modelu, dlaczego to zrobiliķmy? Gģówny problem polega na tym, ŋe koņczymy szkolenie danych treningowych, tj. zapamiętujemy dane treningowe, które mogliķmy straciæ moŋliwoķæ uogólnienia, poniewaŋ zapamiętaliķmy. Mogę byæ dobrym mistrzem quizu GK, ale moŋe nie sądzę, ŋe to wģaķciwie oznacza, ŋe mam dobrą pamięæ, ale nie uogólniģem modelu. Zazwyczaj wybieramy modele, które nie są ani zbyt proste, ani zbyt zģoŋone, gdzieķ poķrodku znajduje się prawidģowy model, a sztuką analizy danych jest ustalenie, jaki jest odpowiedni poziom zģoŋonoķci w modelu. Mogę daæ ci drzewo decyzyjne lub regresję logistyczną, nadal moŋesz stworzyæ bardziej zģoŋony lub mniej zģoŋony model, w którym przestajesz byæ twoim wyborem. iedy patrzysz na modele, model powinien robiæ dobrze, nie powinien byæ ani zbyt prosty, ani zbyt skomplikowany. Musimy zrozumieæ kompromis. To wģaķnie nazywamy sygnaģem dla stosunku haģasu. Kaŋde dane ma pewną strukturę (sygnaģ) i trochę haģasu. musimy sprawiæ, by model byģ wystarczająco zģoŋony, aby uchwyciæ strukturę, ale nie haģas.
Uogólnienie: Zdolnoķæ przewidywania lub przypisywania etykiety do nowej obserwacji na podstawie modelu zbudowanego na podstawie wczeķniejszych doķwiadczeņ. Nazywamy to zģoŋonoķcią i dokģadnoķcią modelu. To, co robimy normalnie, pobieramy dane dotyczące danych szkoleniowych, jeķli ciągle zwiększamy model zģoŋonoci, dokģadnoķæ wzrasta do maksimum. Ale to nie jest nasz cel. Celem jest sprawdzenie zestawu sprawdzania poprawnoķci lub zestawu testów, który jest niewidzialnym danymi, w pewnym momencie wyniki sprawdzania poprawnoķci zaczną maleæ. Jest to punkt, w którym powinieneķ przestaæ zwiększaæ zģoŋonoķæ, poniewaŋ nie dziaģa ona zbyt dobrze na zbiorze danych sprawdzania poprawnoķci. Jeķli przeszkolimy coķ, model zapamięta, ale się nie nauczy. Tak więc, nadmierny trening jest czymķ, o co musimy się martwiæ. Wrócimy do tego za kaŋdym razem, gdy studiujemy model. Kiedy tworzysz model, musimy zrozumieæ, jakie byģy oczekiwania klienta. Jesteķmy zainteresowani stworzeniem uogólnionego modelu, który będzie dokģadny. Dokģadnoķæ to nie tylko kryteria, ale musimy przyjrzeæ się interpretowalnoķci modelu. Jeķli twój model jest zbyt skomplikowany, staje się niemoŋliwy do interpretacji, nawet wtedy jest to problem. Wtedy moŋesz mieæ model bardzo dokģadny, model uogólniony, ale nie model wysoce interpretowalny. To kolejne kryterium. Pozostaģe kryteria to punktacja w czasie rzeczywistym. Jeķli masz bardzo zģoŋony model, który zajmuje jedną sekundę, aby zdobyæ jeden punkt danych, to znowu musisz przyciąæ rogi. Dlatego mamy do czynienia z tymi wszystkimi ograniczeniami. Chcę dobrego uogólnienia, chcę interpretacji i wysokiej przepustowoķci. Teraz jaki model zbuduję? Dlatego nie jest oczywiste, jaka jest wģaķciwa odpowiedž. To zaleŋy od wszystkich tych ograniczeņ. Jeķli wežmiemy tutaj dwie sytuacje, aby to zrozumieæ, wyobraž sobie, ŋe budujemy model wykrywania oszustw. Kryterium tego modelu jest dokģadnoķæ. Jeķli zdecyduję się zatrzymaæ kartę lub pozwoliæ jej odejķæ, nie muszę nikomu wyjaķniaæ. Tutaj interpretacja nie jest waŋna, dokģadnoķæ jest waŋna. Pozwólcie, ŋe wezmę inną sytuację, w której budujemy model oceny zdolnoķci kredytowej. Kiedy dokonuję oceny zdolnoķci kredytowej, ilekroæ odrzucamy poŋyczkę, musimy podaæ trzy gģówne powody, dla których odrzucamy poŋyczkę, tutaj interpretacja jest waŋniejsza w modelu oceny wiarygodnoķci kredytowej. Dlatego modele stosowane w modelu ratingu kredytowego są bardzo róŋne w porównaniu z modelem stosowanym w wykrywaniu oszustw związanych z kartami kredytowymi. Musimy zadaæ następujące pytania za kaŋdym razem, gdy tworzymy Model. Jaki jest charakter granicy decyzyjnej klasyfikatora? Jaka jest zģoŋonoķæ granicy decyzyjnej klasyfikatora? Jak kontrolowaæ zģoŋonoķæ klasyfikatora? Skąd mam wiedzieæ, kiedy klasyfikator jest wystarczająco zģoŋony / Jak wybraæ odpowiedni klasyfikator do uŋycia? Modele oparte na drzewach: Partycjonowanie rekurencyjne jest podstawowym narzędziem w eksploracji danych. Pomaga nam badaæ strukturę zestawu danych, a jednoczeķnie opracowuje ģatwe do wizualizacji reguģy decyzyjne przewidywania wyniku kategorycznego (drzewo klasyfikacji) lub ciągģego (drzewo regresji). Drzewa klasyfikacji i regresji moŋna generowaæ za pomocą pakietu rpart.
KROKI W TWORZENIU DRZEWA DECYZJI.
Wyhoduj drzewo
rpart (formuģa, dane =, metoda =, kontrola =) gdzie,
Formuģa ma format wynik ~ predyktor 1 + predyktor 2 + predyktor 3 + ect.
Dane = okreķla ramkę danych
Metoda = "klasa" dla drzewa klasyfikacji, "anova" dla drzewa regresji
Kontrola = opcjonalne parametry do kontrolowania wzrostu drzewa.
Na przykģad control = rpart.control (minsplit = 30, cp = 0,001) wymaga minimum liczby obserwacji w węžle , 30 przed próbą podziaģu, a podziaģ musi się zmniejszyæ przez ogólny brak dopasowania o wspóģczynnik 0,001 (wspóģczynnik zģoŋonoķci kosztów) przed podjęciem próby.
Sprawdž wyniki
Poniŋsze funkcje pomagają nam zbadaæ wyniki.
printcp (fit) #wyķwietl tablicę cp
plotcp (fit) #wykreķl wyniki krzyŋowej weryfikacji
rsq.rpart (dopasowanie) # wykres przybliŋony R-kwadrat i bģąd względny dla róŋnych podziaģów (2 wykresy). etykiety są odpowiednie tylko dla metody "anova".
print (fit) #wyķwietla wyniki.
summary(fit) # szczegóģowe wyniki, w tym podziaģy zastępcze
plot (fit) #plot drzewo decyzyjne
text(fit) # etykieta wykres drzewa decyzyjnego
post (fit, file =) # stwórz wykres postscriptowy drzewa decyzyjnego
Przycinanie drzewa
Przycinanie wspiera drzewo, aby uniknąæ przepeģnienia danych. Zazwyczaj będziesz chciaģ wybraæ rozmiar drzewa, który minimalizuje bģąd sprawdzany krzyŋowo, kolumnę xerror drukowaną przez printcp (). Przycinaj drzewo do poŋądanego rozmiaru za pomocą przycinania (fit, cp =). W szczególnoķci uŋyj printcp (), aby sprawdziæ wyniki bģędu z potwierdzeniem krzyŋowym, wybierz parametr zģoŋonoķci związany z bģędem minimalnym i umieķæ go w funkcji prune().
ZBUDUJ MODEL DRZEWA DECYZJI NA ZBIÓR DANYCH POŊYCZKI MIESZKANIOWEJ
# Wykorzystajmy dane poŋyczki mieszkaniowej, aby przewidzieæ, czy poŋyczka zostanie objęta sankcjami, czy nie, na podstawie wieku, doķwiadczenia, dochodów, wielkoķci rodziny i poziomu wyksztaģcenia.
Krok 1: Zainstaluj i zaģaduj wymagane pakiety
install.packages("rpart")
library(rpart)
library(dummies)
?rpart
Krok 2: Ģadowanie danych do R:
loandata=read.csv(file="D:\\R data\\Housing_loan.csv", header=TRUE, sep=",")
fix(loandata)
Krok 3: usuņ kolumny danych, kolumny Pģeæ z danych
loandata2=subset(loandata, select=-c(ID, Gender))
fix(loandata2
Krok 4: Utwórz zmienne Dummy
Edu_dum =dummy(loandata2$Education)
loandata3=subset(loandata2,select=-c(Education))
fix(loandata3)
loandata4=cbind(loandata3,Edu_dum)
fix(loandata4)
Krok 5: Standaryzuj dane, stosując metodę "Range"
install.packages("vegan")
library(vegan)
loandata_stan=decostand(loandata4,"range")
fix(loandata_stan)
Krok 6: Napraw ziarno, aby uzyskaæ te same dane za kaŋdym razem
set.seed (123)
Krok 7: Pobierz losową próbkę 60% rekordów danych pociągu
train = sample(1:1000,600)
loan_train = loandata_stan[train,]
# Pobierz losową próbkę 40% rekordów dla danych testowych
test = (1:1000) [-train]
loan_test = loandata_stan[test,]
table(loandata_stan$Loan_sanctioned)
table(loan_train$Loan_sanctioned)
table(loan_test$Loan_sanctioned)
# Usuņ niepotrzebne obiekty
rm(loandata2, loandata3, loandata4,loandata_stan, Edu_dum, test, train)
Krok 8: Zbuduj drzewo decyzyjne
fit <- rpart(Loan_sanctioned~ Age +Experience+ Income +Family+
Education1+Education2+Education3, data=loan_train, method="class",
control=rpart.control(minsplit=10, cp=0.001))
#formula ma format wynik ~ predyktor 1 + predyktor 2 + predyktor 3 + itd.
# data = Okreķla ramkę danych
# method = "class" dla drzewa klasyfikacji, "anova" dla drzewa regresji
# control = Opcjonalne parametry do kontrolowania wzrostu drzewa.
# control = rpart.control (minsplit = 10, cp = 0,001) wymaga, aby minimalna liczba obserwacji w węžle wynosiģa 10 przed próbą # podziaģu, a podziaģ musi zmniejszaæ ogólny brak dopasowania o wspóģczynnik 0,001 (koszt wspóģczynnik zģoŋonoķci) przed próbą.
Krok 9: Wyķwietl wyniki
printcp(fit) # wyķwietl wyniki
plotcp (fit) # wizualizuj wyniki weryfikacji krzyŋowej
summary(fit) # szczegóģowe podsumowanie podziaģów
Krok 10: Drzewo wydruku
plot(fit, uniform=TRUE, main="Classification Tree for Housing Loan")
text(fit, use.n=TRUE, all=TRUE, cex=.8)
Krok 11: Przycinaj drzewo
pfit<- prune(fit, cp= fit$cptable[which.min(fit$cptable[,"xerror"]),"CP"])
# Odsuņ drzewo, aby uniknąæ dopasowania danych. moŋesz wybraæ rozmiar drzewa, który minimalizuje bģąd sprawdzany krzyŋowo, kolumnę xerror drukowaną przez printcp (). Drzewa wnioskowania warunkowego moŋna utworzyæ za pomocą pakietu partyjnego, który zapewnia nieparametryczne drzewa regresji dla odpowiedzi nominalnych, porządkowych, numerycznych, ocenzurowanych i wielowymiarowych. Moŋesz utworzyæ drzewo regresji lub klasyfikacji za pomocą funkcji ctree (formuģa, dane =). Rodzaj utworzonego drzewa będzie zaleŋeæ od zmiennej wynikowej (wspóģczynnik nominalny, wspóģczynnik uporządkowany, numeryczny itp.). Wzrost drzewa opiera się na statystycznych zasadach zatrzymywania, więc przycinanie nie powinno byæ wymagane.
KROK 14
Klasa Najbliŋszego Sąsiada
WPROWADZENIE
Zanim omówimy KNN, zrozummy róŋnicę między pamięcią a uczeniem się. Pamięæ to proces rejestrowania, przechowywania i wyszukiwania informacji. W pamięci przechowujemy dane i zawsze do nich wracamy, gdy jest to konieczne. Uczenie się to proces lub zachowanie związane z nabywaniem wiedzy. Nie chodzi tylko o pozyskiwanie i przechowywanie informacji, ale o zdolnoķæ do wdraŋania informacji i korzystania z nich w praktycznych okolicznoķciach. Jeķli zbudujemy model, który jest znacznie bardziej skompresowaną wersją danych, wówczas zapominamy o danych, uŋywamy jedynego modelu w przyszģoķci. tak dziaģa nasz mózg. Moŋemy więc powiedzieæ, ŋe uczenie się jest procesem, który zmodyfikuje póžniejsze zachowanie. Z drugiej strony pamięæ to zdolnoķæ pamiętania wczeķniejszego doķwiadczenia. Najbliŋszy sąsiad K to prosty algorytm, który przechowuje wszystkie dostępne przypadki i klasyfikuje nowe przypadki większoķcią gģosów swoich sąsiadów. Ten algorytm dzieli nieoznaczone punkty danych na dobrze zdefiniowane grupy. Klasyfikator KNN jest jednym z najprostszych i najpiękniejszych klasyfikatorów. Wyobraž sobie wykres rozproszenia z punktami danych klas róŋowych i niebieskich, w których róŋowe punkty danych są bardziej widoczne w lewym górnym rogu, a w prawym dolnym rogu niebieskie są bardziej widoczne, ale w danych jest duŋo szumu. takie są prawdziwe dane. Teraz, jeķli dam wam nowy punkt danych i poproszę o sklasyfikowanie go. Co zrobisz? zaczynasz znajdowaæ punkt najbliŋszy podanemu nowemu punktowi danych na podstawie odlegģoķci, Zaģóŋmy, ŋe najbliŋszy jest róŋowy. Co będziesz robiæ gdy ten nowy punkt danych zostanie przypisany do róŋowego. Nazywa się to 1 Najbliŋszym sąsiadem. To jest coķ takiego: chcesz obejrzeæ film, zadzwoniģeķ do jednego ze znajomych i zapytaģeķ, czy to dobrze, czy žle. Cokolwiek powie, zrobisz. Czy to zrobisz? Nie, więc co zrobisz? Dzwonimy do większej liczby osób, ģączymy się z internetem i czytamy recenzje. Oglądasz zwiastun, a potem decydujesz, prawda. Zatem proces decyzyjny zaleŋy od danych zewnętrznych, im więcej danych wejķciowych zdobędziesz, tym silniejsza będzie twoja decyzja. Co mogę zrobiæ zamiast korzystaæ z 1 najbliŋszego sąsiada? Mogę korzystaæ z 2 najbliŋszych sąsiadów, teraz zadzwoniģem do 2 przyjacióģ, pierwszy facet powiedziaģ, idž obejrzeæ, a drugi mówi, ŋeby nie oglądaæ. Teraz jestem jeszcze bardziej zdezorientowany. Zatem w najbliŋszych sąsiadach K unikamy uŋywania K jako liczby parzystej. Jeķli pójdę z 3 najbliŋszymi sąsiadami, znów się to zmienia w zaleŋnoķci od liczby punktów. Jeķli pójdę jeszcze wyŋej, etykieta moŋe się zmieniæ. i tak dalej i tak dalej. Jak kontrolujesz tutaj zģoŋonoķæ? Jaki jest model prosty i zģoŋony w K najbliŋszych sąsiadów? Biorą surowe dane, które są róŋowe i niebieskie, zakģadając, ŋe to przykģad testowy, uŋyli okreķlonej wartoķci K i powiedzieli, ŋe jeķli uŋyję trzech najbliŋszych sąsiadów, jaka byģaby moja etykieta? Róŋowy czy niebieski ?. To jest przestrzeņ i podzieliliķmy ją na 2 regiony. Nikt nie mówi, ŋe regiony muszą byæ ģadne i piękne. Teraz niebieski region ma pewną czystoķæ i kaŋdy punkt naleŋący do niebieskiego zostanie przypisany do niebieskiego regionu. Co się stanie, gdy K wzroķnie? Regiony zmieniģy się w niektórych punktach, wraz ze wzrostem K, gģadsze granice, a nasz model staje się coraz bardziej odporny na haģas. Wczeķniej za bardzo reagowaģo na haģas. Czego się tutaj uczysz? Im wyŋszy K, tym bardziej solidny jest model i mniej zģoŋony model. Model wygląda prawie jak regresja liniowa. Podczas budowania klasyfikatora musimy wziąæ pod uwagę kilka pytaņ. Jakie są parametry? czy nauczyliķmy się jakichķ parametrów? Czy w regresji logistycznej poznaliķmy jakieķ parametry? Cięŋary to moje parametry. Rzeczy, których się nauczyģem. W K-oznacza klastrowanie centra klastra to parametry, a K to hiperparametr. W K najbliŋsi sąsiedzi K nazywani są hiperparametrami. To jest coķ, co daje systemowi kontrolę nad zģoŋonoķcią. W przypadku KNN nie ma parametrów. Nie ma modelu. Dlatego w KNN czas szkolenia wynosi zero, poniewaŋ niczego się nie uczy. Dlatego nazywany jest modelem nieparametrycznym. Jakie są wady tego KNN ?. Jak dģugo musisz zdobyæ punkt danych? Wyobraž sobie, ŋe jeķli dam ci 100 tysięcy punktów danych w zestawie szkoleniowym, a powiesz, ŋe nadchodzi nowy punkt danych, co musisz zrobiæ? Musisz zmierzyæ odlegģoķæ od wszystkich 100 tysięcy punktów, a następnie posortowaæ ją i wybraæ górną K, zobaczyæ, jakie są ich etykiety, to æwiczenie jest rzędu N, w czasie treningu. Czy uŋyģbyķ takiego klasyfikatora do podejmowania decyzji w czasie rzeczywistym ?. Wybierając technikę modelowania, patrzymy nie tylko na jej dokģadnoķæ, ale nawet na czas obliczeņ. Jeķli muszę zbudowaæ model, który trzeba bardzo szybko trenowaæ, Moje dane zmieniają się bardzo szybko, to potrzebujesz modelu, który w ogóle nie ma czasu na szkolenie. Kluczem tutaj jest sposób zdefiniowania funkcji odlegģoķci. Zdefiniowanie funkcji odlegģoķci jest najtrudniejszym zadaniem. Wyobraž sobie dwie zmienne, takie jak wiek i dochód, w jaki sposób okreķlasz odlegģoķæ między nimi? Odlegģoķæ między dwoma profilami LinkedIn, Odlegģoķæ między dwiema sekwencjami genowymi itp., Dwa sygnaģy džwiękowe, dwa dokumenty w Internecie, dwa tweety, dwa filmy i trwa. Wežmy prosty przykģad sekwencji genów raka, mamy okoģo 10 tysięcy sekwencji genów pacjentów z rakiem i 1 milion sekwencji genów pacjentów nienowotworowych. kiedy pojawia się nowy punkt danych, musimy zdecydowaæ, czy musimy sprawdziæ, czy wszystkie miliardy sekwencji genów pasują do wszystkich sekwencji genów i obliczyæ odlegģoķci między nimi, znaležæ K i tak dalej, jest to doķæ trudne do zrobienia . Tak więc, wybierając technikę modelowania, musimy zastanowiæ się, co to jest K ?, co to jest funkcja odlegģoķci ?, czy będę w stanie teraz szybciej zdobywaæ punkty? wszystkie te rzeczy. Kolejnym problemem związanym z KNN jest faktyczna odlegģoķæ, której nie wziąģbym pod uwagę. Mówię tylko o górze K. Nie mówię, jak daleko. jest to jeszcze jeden problem z KNN, poniewaŋ traci on informacje o odlegģoķci. Kolejnym problemem związanym z KNN jest to, ŋe nie jest odporny na haģas. O ile nie zwiększysz zbyt mocno K, nie będzie to zbyt odporne na haģas.
JAK WYBRAÆ ODPOWIEDNĄ WARTOĶÆ K?
Wybór liczby najbliŋszych sąsiadów, tj. oOkreķlenie wartoķci K, odgrywa istotną rolę w okreķleniu skutecznoķci modelu. Zatem wybór K okreķli, jak dobrze dane mogą byæ wykorzystane do uogólnienia wyników algorytmu kNN. Duŋa wartoķæ k ma zalety, które obejmują zmniejszenie wariancji ze względu na zaszumione dane, efektem ubocznym jest rozwijanie uprzedzeņ, w wyniku których uczący się ignoruje mniejsze wzorce, które mogą mieæ uŋyteczny wgląd.
Algorytm kNN - zalety i wady
Plusy: Algorytm ma wysoce bezstronny charakter i nie zakģada wczeķniej podstawowych danych. Poniewaŋ jest prosty i skuteczny z natury, jest ģatwy do wdroŋenia i zyskaģ dobrą popularnoķæ.
Wady: Rzeczywiķcie algorytm kNN nie tworzy modelu, poniewaŋ nie wymaga ŋadnego procesu abstrakcji. Tak, proces szkolenia jest naprawdę szybki, poniewaŋ dane są przechowywane dosģownie, ale czas przewidywania jest doķæ dģugi, a czasami brakuje przydatnych informacji. Dlatego zbudowanie tego algorytmu wymaga czasu na zainwestowanie w przygotowanie danych w celu uzyskania solidnego modelu.
BUDUJ MODEL KNN NA DIABETYCZNYM ZBIORZE DANYCH
Wykrywanie cukrzycy: Uczenie maszynowe znajduje szerokie zastosowanie w przemyķle farmaceutycznym, szczególnie w wykrywaniu cukrzycy i raka. Zobaczmy proces budowania tego modelu przy uŋyciu algorytmu kNN w Programowaniu R.
Krok 1: Zbieranie danych:
Wykorzystamy zestaw danych pacjentów z cukrzycą do wdroŋenia algorytmu KNN, a tym samym interpretacji wyników. Zbiór danych skģada się z 500 obserwacji i 7 zmiennych, które są następujące: W rzeczywistoķci istnieje dziesiątki waŋnych parametrów potrzebnych do pomiaru prawdopodobieņstwa cukrzycy, ale dla uproszczenia poradzimy sobie z 7 z nich.
• Pat_Id
• Pģeæ
• OGTT
• DBP
• BMI
• Wiek
• Cukrzyca
Krok 2: Eksploracja danych
setwd ("D: / R data") # Zaimportujmy plik danych "Diab.csv". To polecenie sģuŋy do wskazywania folderu zawierającego wymagany plik.
Diabdata <- read.csv("Diab.csv", header = TRUE,stringsAsFactors = FALSE) # To polecenie importuje wymagany zestaw danych i zapisuje go w ramce danych Diabdata. stringsAsFactors = FALSE # To polecenie pomaga przekonwertowaæ kaŋdy wektor znaków na czynnik, tam gdzie ma to sens.
str(Diabdata) # Uŋywamy tego polecenia, aby sprawdziæ, czy dane mają strukturę, czy nie. Stwierdzamy, ŋe dane mają strukturę 7 zmiennych i 500 obserwacji. Jeķli obserwujemy zestaw danych, pierwsza zmienna "Pat_Id" ma unikalny charakter i moŋna ją usunąæ, poniewaŋ nie dostarcza uŋytecznych informacji.
Krok 3: Przygotowanie danych
# Usuņ pierwszą zmienną (Pat_Id) ze zbioru danych.
Diabdata <- Diabdata [-1]
Zestaw danych zawiera pacjentów, u których zdiagnozowano cukrzycę lub cukrzycę
# Szybkie spojrzenie na atrybut Diabetic poprzez pokazuje, ŋe podziaģ.
table(Diabdata$Diabetic)
Zmienna Diabetic jest naszą zmienną docelową, tj. Ta zmienna okreķla wyniki diagnozy na podstawie innych zmiennych liczbowych. # Jeķli chcesz sprawdziæ procentowy podziaģ atrybutu Cukrzyca, moŋesz poprosiæ o tabelę proporcji:
round(prop.table(table(Diabdata$Diab)) * 100, digits = 1)
# Dogģębne Zrozumienie Twoich Danych
summary(Diabdata)
# Moŋesz takŋe zawęziæ podsumowanie, dodając okreķlone atrybuty
summary(Diabdata[c("OGTT", "BMI")])
Krok 4: Normalizacja:
Ta funkcja ma ogromne znaczenie, poniewaŋ skala zastosowana dla wartoķci kaŋdej zmiennej moŋe byæ inna. Najlepszą praktyką jest normalizacja danych i przeksztaģcenie wszystkich wartoķci na wspólną skalę.
# Moŋemy wykonaæ normalizację funkcji, najpierw tworząc wģasną funkcję normalizacji:
normalize <- function(x) {
num <- x - min(x)
denom <- max(x) - min(x)
return (num/denom)
}
Diab_norm <- as.data.frame(lapply(Diabdata[3:6], normalize))
summary(Diab_norm)
fix(Diab_norm)
Sprawdžmy za pomocą zmiennej "BMI", czy dane zostaģy znormalizowane.
summary(Diab_norm$BMI)
Krok 5: Tworzenie zestawu danych treningowych i testowych:
Algorytm kNN jest stosowany do zestawu danych treningowych, a wyniki są weryfikowane w zestawie danych testowych. W tym celu podzielilibyķmy zestaw danych na 2 porcje w stosunku 60: 40 odpowiednio dla zestawu danych treningowych i testowych. Moŋesz uŋyæ zupeģnie innego wspóģczynnika w zaleŋnoķci od wymagaņ biznesowych
# Zestawy szkoleniowe i testowe
set.seed (1234)
Indicator <- sample(2, nrow(Diab_norm), replace=TRUE, prob=c(0.6, 0.4))
# Moŋemy następnie uŋyæ próbki zapisanej w zmiennej Indicator do zdefiniowania treningu i zestawy testowe:
Diab.training <- Diab_norm [Indicator == 1, 1: 4]
Diab.test <- Diab_norm [Indicator == 2, 1: 4]
Naszą zmienną docelową jest "Cukrzycowa", której nie uwzględniliķmy w zestawach danych szkoleniowych i testowych.
Diab.trainLabels <- Diabdata [Wskažnik == 1, 7]
Diab.testLabels <- Diabdata [Wskažnik == 2, 7]
Krok 6: Trening modelu na danych:
Funkcji knn () naleŋy uŋyæ do wyszkolenia modelu, dla którego musimy zainstalowaæ pakiet "class". Funkcja knn () identyfikuje najbliŋszych sąsiadów za pomocą odlegģoķci euklidesowej, gdzie k jest liczbą okreķloną przez uŋytkownika.
install.packages ("class")
library (class)
Teraz jesteķmy gotowi do uŋycia funkcji knn () do klasyfikacji danych testowych. Pozwól nam zbudowaæ nasz klasyfikator. Aby zbudowaæ twój klasyfikator, musimy wziąæ funkcję knn () i po prostu dodaæ do niej kilka argumentów.
Diab_pred <- knn (train = Diab.training, test = Diab.test, cl = Diab.trainLabels, k = 11)
Diab_pred
Wartoķæ k jest na ogóģ wybierana jako pierwiastek kwadratowy z liczby obserwacji. knn () zwraca wartoķæ wspóģczynnika przewidywanych etykiet dla kaŋdego z przykģadów w zestawie danych testowych, który jest następnie przypisywany do ramki danych Diab_pred. Wynikiem tego polecenia jest wektor czynnikowy z przewidywanymi klasami dla kaŋdego wiersza danych testowych.
Krok 7: Ocena twojego modelu:
Aby sprawdziæ wydajnoķæ modeli, moŋemy zaimportowaæ pakiet gmodels:
install.packages ("gmodels")
#Jeķli juŋ zainstalowaģeķ ten pakiet, moŋesz po prostu wejķæ
library(gmodels)
# Następnie tworzymy tabelę krzyŋową lub tabelę zdarzeņ awaryjnych.
CrossTable (x = Diab.testLabels, y = Diab_pred, prop.chisq = FALSE)
Nie stwierdzono przypadków faģszywie ujemnych (FN), co oznacza, ŋe nie odnotowano ŋadnych przypadków, które faktycznie mają charakter cukrzycowy, ale zostaģy przewidziane jako niecukrzycowe. FN stanowi potencjalne zagroŋenie z tego samego powodu, a gģównym celem jest zwiększenie dokģadnoķci modelu jest zmniejszenie FN. Caģkowita dokģadnoķæ modelu wynosi 60% ((TN + TP) / 35), co pokazuje, ŋe mogą istnieæ szanse na poprawę wydajnoķci modelu Krok 8: Poprawa wydajnoķci modelu
Moŋna to wziąæ pod uwagę, powtarzając kroki 3 i 4 oraz zmieniając wartoķæ k. Zasadniczo jest to pierwiastek kwadratowy z obserwacji i w tym przypadku przyjęliķmy k = 10, który jest idealnym pierwiastkiem kwadratowym ze 100. Wartoķæ k moŋe się wahaæ wi wokóģ wartoķci 10, aby sprawdziæ zwiększoną dokģadnoķæ Model. Wypróbuj to z wybranymi wartoķciami, aby zwiększyæ dokģadnoķæ. Musimy pamiętaæ o tym, aby wartoķæ FN byģa jak najniŋsza.
KROK 15
Klasyfikatory Bayesowakie
WPROWADZENIE
Twierdzenie Bayesa jest twierdzeniem matematycznym, za pomocą którego próbujemy znaležæ związek między danymi a klasą. Musimy pomyķleæ, jeķli to są dane, to jaka powinna byæ klasa. Tutaj próbujemy dokonaæ mapowania między danymi a klasą.
1. Jakie jest prawdopodobieņstwo, ŋe klient odpowie na tę ofertę i kupon.
2. Jakie jest prawdopodobieņstwo zachorowania na raka, czy nie, biorąc pod uwagę tę konkretną sekwencję genową?
Pozwól mi omówiæ zasadę Bayesa. Pozwól nam zrozumieæ, dlaczego jest to tak waŋna rzecz
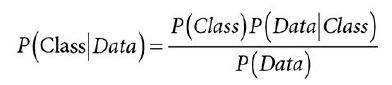
P (Class) → Class Prior
P (Dane | Klasa) → Prawdopodobieņstwo danych dla danej klasy
P (dane) → Dane przed (marginalne)
P (klasa | dane) → prawdopodobieņstwo póžniejsze (prawdopodobieņstwo klasy po obejrzeniu danych)
Pozwólcie, ŋe porozmawiam o bardzo prostej wģaķciwoķci ģącznego rozkģadu prawdopodobieņstwa: jeķli powiem, P (a, b) mogę zapisaæ go w dwóch typach, jako P(a) razy p(b biorąc pod uwagę a) lub P(b) razy p(b) a). Pozwól nam to zrozumieæ na przykģadzie: Wyobraž sobie, ŋe jesteķ lekarzem, czekasz na przyjķcie kolejnego pacjenta. Czy juŋ wiesz, jaka będzie choroba? Czy potrafisz zgadnąæ, jaka byģaby choroba? cokolwiek wiemy bez patrzenia na dane, nazywamy to wczeķniej. Kiedy poprosiģem o rozmowę z kandydatem w organizacji zajmującej się oprogramowaniem, nie patrząc na kandydata, nie patrząc na jego CV, co mogę powiedzieæ, czy kandydat zostanie zatrudniony, czy nie? Jak mam to zrobiæ? Patrzę na wszystkich ludzi, którzy brali udziaģ w wywiadach i jaką częķæ z nich zatrudnimy?. To się nazywa wczeķniejsze prawdopodobieņstwo. Ten sam lekarz widziaģ wielu pacjentów w przeszģoķci i prawidģowo je zdiagnozowaģ, a następnie oczekujemy od punktu danych, aby zaklasyfikowaæ ich do tej klasy (dane, które prawdopodobnie daģy klasę). Następnie muszę rozwaŋyæ nawet to, jakie jest prawdopodobieņstwo, ŋe taki pacjent kiedykolwiek do mnie przyjdzie (Data Prior Marginal). Na podstawie tych informacji muszę przewidzieæ przyszģoķæ. Biorąc pod uwagę ten nowy punkt danych, powiedz mi, jakie jest prawdopodobieņstwo tej klasy. Wģaķnie to staramy się zrobiæ, więc twierdzenie Bayesa nie jest matematyczną ŋonglerką prawdopodobieņstwa warunkowego. To naprawdę sposób na poģączenie swoich przeszģych doķwiadczeņ z prognozami na przyszģoķæ. Istnieje caģa masa technik modelowania opartych na twierdzeniu Bayesa. Większoķæ uczenia maszynowego spędza czas na danych, które prawdopodobnie daģy klasę. Maksymalne prawdopodobieņstwo oznacza, jakie jest prawdopodobieņstwo tych danych pochodzących z tej klasy, a my po prostu staramy się na nich maksymalnie wykorzystaæ. Są dwa sposoby myķlenia o twierdzeniu bayesowskim. 1. Decyzja o maksymalnym prawdopodobieņstwie 2. Maksymalna decyzja o prawdopodobieņstwie póžniejszym.
MYĶLENIE JAK PODOBNY BAYESJAN
To tylko zastosowanie naszej teorii prawdopodobieņstwa w podejmowaniu decyzji. Przedstawię wam scenariusz, przekonwertujemy zdania angielskie jako prawdopodobieņstwa i prawdopodobieņstwa warunkowe i przejdziemy przez obliczanie prawdopodobieņstw póžniejszych. Wyobraž sobie, ŋe jesteķ producentem maszyny. Wež setki osób, które znasz na raka, i przetestuj je, jeķli stwierdzenie mówi, ŋe maszyna da 95% poprawnych wyników pozytywnych.
P (Test_positive | Has_Cancer) = .95, P (Test_Negative | Has_Cancer) = .05
Oznacza to, ŋe nawet maszyna mówi negatywnie i masz raka, to nie znaczy, ŋe nie masz raka. Co to są dane i klasa tutaj? Wynik testu to dane, Rak bez raka jest wynikiem. Wyobraž sobie, ŋe jesteķ producentem maszyny. Wež setki osób, które nie mają raka, i przetestuj je. Jeķli maszyna daje poprawny wynik ujemny 90% razy.
P (Test_Negative | No_Cancer) = .9, P (Test_Positive | No_Cancer) = .1
I tylko 0,8% caģej populacji ma raka:
P (Has_Cancer) = 0,008, P (No_Cancer) = 0,992
Mamy tutaj do czynienia z dwiema zmiennymi: 1. Niezaleŋnie od tego, czy pacjent ma raka, czy nie, 2. Test wyszedģ pozytywnie lub negatywnie. Teraz pozwól mi zapytaæ, jakie jest prawdopodobieņstwo, ŋe test jest pozytywny? Aby odpowiedzieæ na to pytanie, musimy obliczyæ dwie rzeczy: 1. pacjent ma raka jest maszyną z wynikiem dodatnim lub nie., 2. pacjent nie ma raka jest maszyną z wynikiem dodatnim lub nie.
= [P (Test_positive | Has_Cancer) * P (Has_Cancer) +
P (Test_Positive | No_Cancer) * P (No_Cancer)]
= 0,95 * 0,008 + .1 * 0,992 = 0,1068
Jakie jest wczeķniejsze prawdopodobieņstwo, ŋe test jest negatywny?
= [P (Test_Negative | Has_Cancer) * P (Has_Cancer) +
P (Test_Negative | No_Cancer) * P (No_Cancer)]
= 0,05 * 0,008 + .9 * 0,992 = 0,8932
Tak myķlimy jak Bayesian. Nie mogę zmierzyæ, ile razy będzie to pozytywne. To zaleŋy od rodzaju pacjentów poddawanych testom. Nie moŋemy po prostu obserwowaæ danych, ignorując etykietę klasy. Wežmy przykģad, chciaģbym przewidzieæ, czy dzisiaj kichniesz? To zaleŋy od tego, jakie są przyczyny kichania i czy zamierzasz je ujawniæ, to moŋemy powiedzieæ, czy kichasz, czy nie. Teraz pozwól mi zadaæ drugie pytanie. Jeķli nowy pacjent wejdzie i wynik testu będzie pozytywny, zastosujemy twierdzenie Bayesa. Jakie jest prawdopodobieņstwo raka, jeķli wynik testu będzie pozytywny?
P (Has_Cancer | Test_Positive)
= [P (Test_positive | Has_cancer) * P (Has_Cancer) / P (Test_Positive)]
= [(0,95 * 0,008) / 0,1068] = 0,07116
Jakie jest prawdopodobieņstwo raka, jeķli wynik testu jest ujemny?
P (Has_Cancer | Test_Negative)
= [P (Test_Negative | Has_cancer) * P (Has_Cancer) / P (Test_Negattive)]
= [(0,05 * 0,008) / 0,8932] = 0,00045
nawet dowody mówią, ŋe pacjent ma raka, ale nie musimy się martwiæ, poniewaŋ wczeķniejsza liczba jest bardzo niska. Aby obliczyæ NaiveBayes, musimy wiedzieæ, jak obliczyæ ķrednią, kowariancję i obliczenie prawdopodobieņstwa Bayesa.
Odlegģoķæ Mahalanobisa: kiedy bierzesz dane, wež PCA danych, co robisz, gdy bierzesz PCA danych, zasadniczo usuwasz w nim kowariancję, a następnie obliczasz odlegģoķæ, aby staģa się odlegģoķcią Mahalanobisa.
Bayesowski klasyfikator Granica decyzyjna: Pamiętaj, ŋe omawialiķmy 2 typy klasyfikatorów w poprzednich częķciach, 1. Ksztaģt klasy 2. Granica decyzyjna. W granicy decyzji bayesowskiej klasyfikatora uŋywamy obu. To, co robimy, to tworzymy jednego Gaussa na kaŋdą klasę i gdziekolwiek dwa są równe, to jest granica naszej decyzji.
NAIWNY KLASYFIKATOR BAYESOWSKI
NaiveBayes jest bardzo waŋną klasą klasyfikatorów bayesowskich. Warunkowa niezaleŋnoķæ: znamy niezaleŋnoķæ między dwiema zmiennymi. Jeķli powiem, ŋe dzieją się dwa zdarzenia i są one caģkowicie losowe, co moŋemy powiedzieæ o wspólnym prawdopodobieņstwie?
P (A, B) = P (A) * P (B).
Zaģóŋmy, ŋe weszliķmy do komnaty lekarzy i powiedzieliķmy, ŋe mamy gorączkę i bóle ciaģa. myķlisz, ŋe te dwa objawy są niezaleŋne? Nie, istnieje wspólna przyczyna obu powyŋszych objawów. lekarze próbują ustaliæ wspólną przyczynę wszystkich niezaleŋnych objawów. Powiedzmy, ŋe infekcja wirusowa powoduje te dwa objawy. Tak więc przyczyną jest infekcja wirusowa. Następnie moŋemy napisaæ to zdanie w następujący sposób: P (gorączka, ból ciaģa | wirusowy) = P (gorączka | wirusowy) * P (ból ciaģa | wirusowy) to wģaķnie nazywa się warunkową niezaleŋnoķcią.
Ponownie wracając do twierdzenia Bayesa, chcę dowiedzieæ się prawdopodobieņstwa infekcji wirusowej, biorąc pod uwagę, ŋe pacjent ma gorączkę i ból ciaģa.
P (wirusowa | gorączka, ból ciaģa) = [P (gorączka, ból ciaģa | wirusowy) * P (wirusowa)] / P (gorączka, ból ciaģa).
ZBUDUJ NAIVEBAYES Z DIABETYCZNEGO ZBIORU DANYCH
Krok 1: Uzyskaj swoje dane:
# load w zestawie danych za pomocą następującego polecenia:
setwd("D:/R data")
Diabds <- read.csv("Diab.csv", header = TRUE)
fix(Diabds)
Krok 2: Poznaj swoje dane:
Lepszym pomysģem jest sprawdzenie zestawu danych poprzez wykonanie
head(Diabds)
str(Diabds)
names(Diabds)
summary(Diabds
Krok 3: Przygotuj swoje dane:
Usuņ pierwszą zmienną (Pat_Id) ze zbioru danych.
Diabdata <- Diabds [-1]
Krok 4: Zaģaduj wymagane pakiety:
Zainstaluj i zaģaduj pakiet e1071
install.packages('e1071',dependencies=TRUE)
library(e1071)
Krok 5: Podziel zestaw danych
Diab_test = sample(1:nrow(Diabdata),200)
Diab_train = setdiff(1:nrow(Diabdata),Diab_test)
Krok 6: Zbuduj model
Diab_nb = naiveBayes(Diabdata[Diab_train,2:5],Diabdata[Diab_train,6])
Dia_res = predict(Diab_nb,Diabdata[Diab_test,2:5])
Krok 7: Wyķwietl macierz nieporozumieņ
table(Dia_res,Diabdata[Diab_test,6])
Krok 8: Dokģadnoķæ obliczeņ
cm_Diab = table(Dia_res,Diabdata[Diab_test,6])
# oblicz sumę wartoķci przekątnych w macierzy
correct = sum(diag(cm_Diab))
accuracy = correct / sum(cm_Diab)
KROK 16
Sieci Neuroowe
WPROWADZENIE
Sieæ neuronowa (NN) ma neurony i warstwy w swojej architekturze. 3 warstwy w sieci neuronowej to Warstwa wejķciowa, Warstwa ukryta i Warstwa wyjķciowa. Kaŋda z tych warstw ma w sobie jednostki lub neurony.
Ludzka sieæ neuronowa: Podstawową jednostką obliczeniową w ukģadzie nerwowym jest komórka nerwowa lub neuron. Neuron ma 1. Dendryty (dane wejķciowe) 2. Ciaģo komórki 3. Akson (dane wyjķciowe). Neuron otrzymuje dane wejķciowe z innych neuronów, dane wejķciowe są sumowane, a gdy dane wejķciowe przekraczają wartoķæ krytyczną neuron wyģadowuje impuls elektryczny, który przemieszcza się przez ciaģo w dóģ aksonu, do następnego neuronu. To zdarzenie szczytowe jest równieŋ nazywane depolaryzacją, a po nim następuje okres refrakcji, podczas którego neuron nie jest w stanie strzelaæ. Zakoņczenia aksonów prawie się stykają z dendrytami lub ciaģem komórkowym następnego neuronu. Przekazywanie sygnaģu elektrycznego z jednego neuronu do drugiego odbywa się za pomocą neuroprzekažników, substancji chemicznych uwalnianych z pierwszego neuronu i wiąŋących się z receptorami w drugim. To ģącze nazywa się synapsą. Zakres, w jakim sygnaģ z jednego neuronu jest przekazywany do następnego, zaleŋy od wielu czynników, np. iloķæ dostępnego neuroprzekažnika, rozmieszczenie receptorów, iloķæ neuroprzekažników wchģoniętych ponownie, itd. Przyjrzyjmy się algorytmowi EM. W klastrze K-oznacza ,ŋe to co zrobiliķmy, przypisujemy klastry do punktów danych i obliczamy ķrednią, po obliczeniu ķredniej ponownie przypisujemy punkty danych. Poniewaŋ nie znamy modelu, zaczynamy gdzieķ i stamtąd.
Zastosowania sieci neuronowej:
1. Robotyka - nawigacja, rozpoznawanie wzroku
2. Medycyna - Przechowywanie dokumentacji medycznej
3. Rozpoznawanie mowy
4. Prognozy gieģdowe
5. Kompresja danych
6. Przetwarzanie obrazu
7. Rozpoznawanie twarzy
8. Ķledzenie pozycji kabiny lub cięŋarówki
9. Przetwarzanie sygnaģu
10. Rozpoznawanie znaków odręcznych.
DLACZEGO SIECI NEURONOWE?
Sieæ neuronowa jest przeģomowym algorytmem w uczeniu maszynowym. Po pierwsze, zrozummy, dlaczego regresja logistyczna nie wystarczy? Gdy istnieją więcej niŋ 2 klasy, dotychczas sugerowaliķmy wykonanie następujących czynnoķci: Przypisz jeden węzeģ wyjķciowy do kaŋdej klasy, ustaw wartoķæ docelową kaŋdego węzģa na 1, jeķli jest to poprawna klasa, a 0 w przeciwnym razie. Uŋyj sieci liniowej z funkcja ķredniej kwadratowej bģędu. Istnieją problemy z tą metodą. Po pierwsze, istnieje rozbieŋnoķæ między definicją funkcji bģędu a okreķleniem klasy. Bģąd minimalny nie musi powodowaæ, ŋe sieæ ma największą liczbę poprawnych prognoz. Nowa interpretacja: Wynik yi jest interpretowany jako prawdopodobieņstwo, ŋe i jest poprawną klasą. Oznacza to, ŋe wyjķcie kaŋdego węzģa musi wynosiæ od 0 do 1. Suma wyników wszystkich węzģów musi byæ równa 1. Wežmy problem XOR, brama EXCLUSIVE-OR jest bramką z dwoma wejķciami i jednym wyjķciem , to klasyczny przykģad, dlaczego potrzebujemy sieci neuronowej. XOR. Po prostu wežmy dwukierunkowy mechanizm przeģączający w naszym domu, jeķli oboje byliķmy wģączeni lub oboje byliķmy wyģączeni, przeģącznik uwaŋa się za wyģączony. Jeķli którykolwiek z nich jest wģączony, uznaje się, ŋe przeģącznik jest wģączony. Mówi, ŋe jeķli oba są zerami lub oba są jedynymi, otrzymujemy wartoķæ X, a kaŋdy z nich jest równy zero / Jeden otrzymujemy wartoķæ Y. Bramki XOR dają wartoķæ 0, gdy oba wejķcia są zgodne. Podczas wyszukiwania okreķlonego wzorca bitowego lub sekwencji PRN w bardzo dģugiej sekwencji danych, moŋna uŋyæ szeregu bramek XOR do równolegģego porównania ciągu bitów z sekwencji danych z sekwencją docelową. Następnie moŋna policzyæ liczbę 0 wyjķæ, aby okreķliæ, jak dobrze sekwencja danych pasuje do sekwencji docelowej. Ile linii musimy narysowaæ, aby odróŋniæ takie punkty danych? Co najmniej dwa, poniewaŋ jednym nie mogę caģkowicie rozróŋniæ danych. Tutaj musimy zrozumieæ, ŋe regresja logistyczna jest niewystarczająca, poniewaŋ zģoŋonoķæ danych jest większa niŋ zģoŋonoķæ modelu.
Jakie rodzaje linii mogę mieæ? Czy mam unikalne rozwiązanie? Moŋemy uzyskaæ róŋne rozwiązania. istnieją cztery róŋne rozwiązania tego problemu. jeden z nich jest podany na obrazku, przynajmniej z tymi dwiema liniami mogę coķ zrobiæ. cokolwiek robimy, ostatecznie to, co robię, to dzielę przestrzeņ na wiele czystych regionów. Jednak robię to, niezaleŋnie od tego, czy robię to poprzez ustalenie Gaussa, czy mieszanki Gaussów, z dwoma Gaussianami na klasę, Wyobraž sobie, ŋe gdybym musiaģ rozwiązaæ ten sam problem z klasyfikatorem opisowym, co bym zrobiģ, to wystarczy jeden Gaussian na klasę? Nie, jeden Gauss nie wystarczy. W obu przypadkach, niezaleŋnie od tego, czy wybierasz opis, czy dyskryminację, jest to niezaleŋne, charakter danych mówi, ŋe jeden gaussowski nie wystarczy, a jedna linia nie wystarczy. Dlatego potrzebuję dwóch Gaussów lub dwóch linii w dyskryminującym klasyfikatorze. Kiedy mówimy, ŋe istnieje wiele lokalnych minimów, rozumiemy przez to, ŋe dolna linia to jedno lokalne minima, co oznacza, ŋe da mi dobrą odpowiedž, jeķli spojrzysz na inne, to jest inny zestaw parametrów, który równieŋ, dajcie mi bardzo czyste regiony, czyli kolejne lokalne minima. Moŋemy więc zrozumieæ, ŋe istnieje wiele rozwiązaņ tego problemu. Wģaķnie dlatego tego rodzaju algorytmy stanowią wyzwanie. Pozwól mi wziąæ jedno równanie na linię. Teraz mam dwie linie, czy to wystarczy? Pierwsza linia mówi tylko, czy jesteķ po tej czy po tej stronie. Nie mówi, jaka jest klasa. Powyŋsza linia mówi równieŋ, czy jesteķ po tej czy po tej stronie. Nie mówi nawet, jaka jest klasa. Potrzebujemy kogoķ, kto wysģucha obu linii i poģączy wyjķcie, a następnie powie, jaka jest klasa ostateczna. Tak wygląda sieæ neuronowa. To jest najprostsza sieæ neuronowa, to jest jeden neuron równy jednej linii, to jest inny neuron, który jest inną linią, i spójrz na wagi, ta linia mówi 2 razy X1 plus 2 razy X2 minus 1, co daje jedną linię. drugą linię moŋna wyjaķniæ w ten sam sposób. Powyŋszy punkt przypomina kierownika zespoģu, sģucha wszystkich i bierze ich wyniki, odpowiednio je waŋy i popycha do przodu. To jest ostateczna decyzja, którą podejmuje. Pamiętaj, ŋe omawialiķmy Hierarchie, tak jak kaŋdy inŋynier robi jedną rzecz, i potrzebujemy kogoķ, kto poģączy ich wyniki i podejmie ostateczną decyzję. Do tej pory zrozumieliķmy, dlaczego potrzebujemy sieci neuronowej. Nauczmy się je interpretowaæ. Sieæ neuronowa jest niczym więcej niŋ jedną regresją logistyczną i kombinatorem na nich. Nazywa się to równieŋ wielowarstwowym perceptronem. Pomyķlmy w ten sposób, jakby nowy punkt danych znajdowaģ się powyŋej pierwszej linii i poniŋej drugiej linii, to mówimy, ŋe jest czerwony. w przeciwnym razie jesteķ niebieski. Generalnie, kiedy podejmujemy zasady i decyzje, jest to zbiór Oķwiadczeņ. Wežmy na przykģad, jeķli jesteķ po tej stronie linii i po tej stronie drugiej linii, jaka jest odpowiedž?. Spójrzmy na linię, która oznacza, ŋe jesteķ powyŋej dolnej linii. A poniŋej górnej linii, jeķli oba te warunki są speģnione, jesteķ czerwony. W systemie opartym na reguģach są one ci przekazywane, nie uczysz się ich, a my po prostu tworzymy reguģę na podstawie tych stwierdzeņ. Ale w sieciach neuronowych tworzymy reguģę w ten sposób. W drzewie decyzyjnym reguģą jest caģa ķcieŋka. Pozwól mi poģączyæ to z sytuacją opieki zdrowotnej, ŋe jeķli masz dreszcze i gorączkę, problemem moŋe byæ gorączka malaryczna. Sieci neuronowe nazywane są równieŋ jako Perceptronami wielowarstwowymi. Jeķli mam surowe dane, w których jedna grupa punktów jest osadzona w innej grupie punktów, Teraz powiedz mi, ile linii potrzebuję? Teraz potrzebuję co najmniej trzech lub więcej. Co mówimy kaŋda ukryta jednostka jest linią. Interpretacja przebiega za kaŋdym razem, gdy dodajemy jednostkę, jest to jedna linia, druga ukryta jednostka to inna linia i tak dalej. w zaleŋnoķci od zģoŋonoķci problemu mogę dodawaæ coraz więcej ukrytych jednostek i moŋe to dawaæ mi coraz więcej linii. a następnie dodajemy staģą. Pamiętaj, co powiedzieliķmy wczeķniej o neuronie, natura neuronu się nie zmienia, jego wkģad moŋe się zmieniæ. Neuron poķrodku pobiera informacje z dwóch lewych jednostek, a próg znajduje się na górze. Aktywacja i przeģącznik tworzą neuron. Neuron najbardziej na prawo nie pobiera surowych danych wejķciowych. Jest to uogólniony model liniowy, który przyjmuje punkty ķrodkowe jako dane wejķciowe. Nic nie wie o surowych danych, co oznacza, ŋe role kaŋdego neuronu są bardzo jasne, wiedzą, co powinien robiæ, a czego nie. Nasz podstawowy element obliczeniowy (model neuronu) jest często nazywany węzģem lub jednostką. Odbiera dane wejķciowe z niektórych innych jednostek lub byæ moŋe ze žródģa zewnętrznego. Kaŋde wejķcie ma przypisaną wagę w, którą moŋna modyfikowaæ, aby modelowaæ uczenie synaptyczne. Jednostka oblicza funkcję f waŋonej sumy swoich danych wejķciowych:
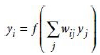
• Suma Σjwijyj waŋona nazywana jest wkģadem netto do jednostki i, często zapisywanym neti.
• Naleŋy pamiętaæ, ŋe wij odnosi się do masy od jednostki j do jednostki i (nie na odwrót).
• Funkcja f jest funkcją aktywacji urządzenia. W najprostszym przypadku f jest funkcją toŋsamoķci, a wyjķciem jednostki jest tylko jej wejķcie netto. Nazywa się to jednostką liniową.
Jeķli dam ci architekturę sieci neuronowej, powiedzmy, ŋe mam wejķcia D i zawsze mamy staģą X0 to zawsze 1. Zawsze istnieje staģy termin na warstwę. a na koņcu mamy ukryte jednostki H, a na koņcu klasy C. Pozwólmy zrozumieæ w przypadku Diabetic Data, gdzie dane wejķciowe i wyjķciowe są ustalone. Nic nie moŋemy na to poradziæ. Co moŋemy zmieniæ liczbę ukrytych jednostek i liczbę ukrytych warstw? To daje ci zģoŋonoķæ. Jeķli zģoŋonoķæ osiągnie okreķlony poziom, dokģadnoķæ wzroķnie. Teraz powiedz mi, ile mam wag, których się uczę. dla jednej ukrytej jednostki mam W0 i liczbę wejķæ, co oznacza wagi D + 1. Ile mam ukrytych jednostek. H ukrytych jednostek. to jest liczba parametrów od teraz do tutaj, dla ukrytej jednostki w następnej warstwie, jest ona obliczana ponownie, w ten sam sposób, dla klasy koņcowej, jest obliczana jak (H + 1) C. więc ostateczna odpowiedž to (D + 1) H + (H + 1) C. W ten sposób moŋemy obliczyæ parametry dla dowolnej zģoŋonoķci. Powiem jeszcze raz, prostym sģowem: sieæ neuronowa jest w peģni poģączona, pomyķl o pierwszym neuronie, jest poģączona ze wszystkimi wejķciami D, kaŋde wejķcie ma wagę, pomyķl o tym jak o g (W0 + W1X1 + .. . WdXd) jest to regresja logistyczna. daje mi to wyjķcie jednego neuronu. Ile tam jest parametrów? Jakie są stopnie swobody? Ile parametrów się uczy? Uczą się (D + 1) i jest to prawdą nawet w przypadku innych jednostek, poniewaŋ wszystkie uczą się wag D + 1, więc (D + 1) H. Teraz ta sama logika jest stosowana do następnej warstwy i tak dalej. Wežmy jednostki wyjķciowe C, tutaj dane wejķciowe będą ukrytymi jednostkami poprzedniej warstwy (H + 1), a ja mam C takich jednostek. więc C (H + 1). W ten sposób moŋemy obliczyæ szereg parametrów dla dowolnej zģoŋonoķci. Powiedzmy, ŋe mamy w siatkówce 10000 pikseli, to jest twój wkģad, powiedz mi, ile róŋnych nachyleņ linii moŋesz mi powiedzieæ. i wyobražmy sobie, jak wiele wychyleņ moŋemy wykryæ wizualnie, jest to 60. moŋemy nawet zrobiæ dobrą ocenę, ale powiedzmy 60. To znaczy, ŋe z 10000 wejķæ trafiģeķ do 60 ukrytych jednostek. Teraz, jeķli powiem, nie tylko linie proste, co z krzywymi, moŋesz wykryæ wszystkie rodzaje krzywych, moŋesz wykryæ krzywe o innej orientacji, mogę kontynuowaæ i kontynuowaæ i mogę mieæ więcej niŋ liczbę danych wejķciowych, podobnie w następna warstwa, jeķli powiem koģa, owal, trójkąty i inne, jeķli idziemy w górę w hierarchii, nie oznacza to, ŋe zmniejszasz liczbę funkcji. to wģaķciwie kombinatoryczna eksplozja. Przy niewielkiej liczbie rzeczy stopieņ kombinacji faktycznie roķnie i roķnie. Tak wģaķnie dziaģa gģęboka sieæ. radzi sobie z taką zģoŋonoķcią. Tak mówi natura, jej natura jest tak zģoŋona, jeķli zwierzę lub czģowiek musi zrozumieæ taką zģoŋonoķæ, Potrzebujemy bardzo zģoŋonej sieci neuronowej, ale nie moŋemy tworzyæ neuronów, które są róŋne, więc powiedzmy : Jak mogę stworzyæ zģoŋoną sieæ z tym samym elementem konstrukcyjnym i tym, co musimy zrobiæ, zmienia elementy skģadowe. To jest piękno sieci neuronowej. Kaŋdy neuron wciąŋ robi to samo. Wszystko, co robi, to liniowa kombinacja danych wejķciowych, po której następuje funkcja logistyczna. Wszystkie miliardy neuronów robią dokģadnie to samo. Przy takiej prostocie masz tyle zģoŋonoķci. Poniewaŋ architektura jest inna. Moŋesz mnie zapytaæ, co z klasyfikacją gradientową. Jest to rodzaj regresji logistycznej, która ma gradient. Wyobražmy sobie początkowo, ŋe te linie są bardzo losowe, jeķli zobaczymy, jak to wygląda przed treningiem, jest bardzo chaotyczne. Nie wiemy nawet, która z tych linii stanie się tą konkretną linią. Potrzebujemy mechanizmu do wykonywania miękkich przejķæ linii. Wyobraž sobie teraz zespóģ nowych pracowników, przez który rozwiązywaliķmy 5 problemów, i powiedziaģem, ŋe potrzebuję kogoķ do wykrycia linii pionowych, kogoķ do wykrycia linii poziomej, a oni wszyscy walczą, aby to zrobiæ. W koņcu jakiķ facet mówi, pozwól mi znaležæ tę linię, a ty idž i znajdž inną linię, tak, ŋe wszyscy zrobimy coķ dobrego, nie moŋemy dokonaæ klasyfikacji. Takie zachowanie wyģania się z początkowo przypadkowych dzieci do geniuszu.
JAK DECYDUJESZ O LICZBIE UKRYTYCH WARSTW I JEDNOSTEK?
Waŋne jest, w jaki sposób decydujesz o liczbie klastrów w klastrze K-ķrednich, jak decydujesz o gģębokoķci drzewa decyzyjnego, jak decydujesz o K w najbliŋszych sąsiadach, jak decydujesz o szerokoķci okno parzana, wszystkie są hiperparametrami. Kontrolują one zģoŋonoķæ modelu. to jest coķ, co musisz daæ. Nie decydujemy o liczbie danych wejķciowych i nie decydujemy o liczbie danych wyjķciowych, a nawet nie decydujemy o wagach. Uczymy się cięŋarów. Im bardziej zģoŋony model jest wyŋszy, tym większa moŋe byæ dokģadnoķæ, ale naleŋy zapewniæ optymalną zģoŋonoķæ. Ludzie pytają mnie, jaki model powinien byæ odpowiedni? To nie jest wģaķciwe pytanie, wģaķciwe pytanie, czy zaleŋy ci na interpretacji wyników, czy nie? Pozwólcie, ŋe wezmę dwie sytuacje w pierwszej sytuacji, w której chcą wykryæ oszustwo, i nie obchodzi ich, ŋe naleŋy to wyjaķniæ konsumentowi, dlaczego nazywamy to oszustwem. Tutaj interpretacja modelu nie jest waŋna, waŋnoķæ modelu byģa waŋna. W tym przypadku korzystamy z sieci neuronowej, poniewaŋ bardzo trudno ją interpretowaæ. Jeķli zaleŋy Ci na interpretacji, musimy skorzystaæ z drzewa decyzyjnego. Pozwól, ŋe wezmę inny przykģad, w innym przypadku, jeķli odrzucisz poŋyczkę dla kogoķ, musisz podaæ powody, nie moŋesz po prostu odrzuciæ poŋyczki, musisz mieæ waŋny powód, dlatego tutaj interpretacja modelu jest bardzo waŋna, nie moŋna tutaj zbudowaæ sieci neuronowej, nawet kosztem mniejszej dokģadnoķci uŋywamy drzew decyzyjnych, poniewaŋ interpretowalnoķæ jest wysoka. Decydując między drzewami decyzyjnymi a sieciami neuronowymi, musisz zapytaæ, która z nich jest dla Ciebie waŋniejsza - jej dokģadnoķæ lub interpretowalnoķæ. Istnieją inne takie kryteria. Kryteria okreķlają, jak szybko zmienia się twój model ?. Jeķli masz do czynienia z bardzo dynamicznym ķrodowiskiem, jeden model, który zbudowaģeķ na lato, nie będzie dziaģaģ na zimę, to musisz przebudowaæ swój model, więc czy mogę szybko odbudowaæ model? Ile czasu zajmuje zbudowanie modelu? Innym kryterium jest to, czy twoja decyzja jest podejmowana w czasie rzeczywistym czy w partii? Jeķli decyzja jest podejmowana w czasie rzeczywistym, musisz zbudowaæ model, który moŋe szybko przetwarzaæ dane i podejmowaæ decyzję. podjęcie decyzji w sprawie oszustwa związanego z kartą kredytową musi byæ decyzją podejmowaną w czasie rzeczywistym. Ale jeķli budujesz model oceny kredytu , moŋesz uŋyæ drzewa decyzyjnego. Więc moŋesz zadaæ mi jeszcze jedną wątpliwoķæ, czy mogę uŋyæ KNN? Moŋe byæ bardzo dokģadny, ale zajmie to duŋo czasu, poniewaŋ w KNN oblicza odlegģoķæ od wszystkich punktów, więc nie moŋna go uŋywaæ w czasie rzeczywistym. Wģaķciwe pytanie nie brzmi, który model jest dobry? Wģaķciwe pytanie brzmi: na jakich kryteriach Ci zaleŋy? Pozwól, ŋe powiem ci, jakie są cztery kryteria, na które musisz spojrzeæ.
1. Podejmowanie decyzji w czasie rzeczywistym czy nie?
2. Dokģadnoķæ, której potrzebujesz, czy nie?
3. jak szybko trzeba odbudowaæ swój model?
4. Interpretowalnoķæ ma znaczenie czy nie?
pomyķl o tych czterech pytaniach, a następnie zdecydujesz, której techniki modelowania naleŋy uŋyæ. Idea zģoŋonoķci jest taka: Wyobraž sobie, co się stanie, jeķli naģoŋą jeszcze jedną ukrytą warstwę na tę istniejącą warstwę. Jeķli chcesz bardziej zģoŋonoķci, innym kierunkiem jest zwiększenie liczby warstw. Pozwól nam zrozumieæ równanie: Wyjķcie z poprzedniej warstwy j-ta jednostka z poprzedniej warstwy, dając ci waŋoną sumę, logistycznie na niej, daje wynik następnej warstwy. jest to równanie rekurencyjne, poniewaŋ g w warstwie n prowadzi do g w n + 1. Ciągle idzie naprzód, to jest to, co robi neuron, ale to, gdzie siedzi, robi róŋnicę. Rozmawialiķmy o uogólnionych modelach liniowych. Powiedzieliķmy, ŋe jeķli chcemy wykonaæ regresję liniową, nie chcemy tego robiæ tylko na X, moŋna to zrobiæ na dowolnej funkcji X, To wģaķnie robi ukryta jednostka w przeciwieņstwie do jednostki wejķciowej, a następnie, to jest nadal model liniowy, zaczynam J od 0, poniewaŋ W0 jest równieŋ częķcią tego równania liniowego, nie chcę powiedzieæ W0 plus coķ, dlatego tutaj wstawiamy 1 i zaczynamy od W0 bezpoķrednio. Następnie moŋemy powiedzieæ, ŋe jest to model liniowy, nie moŋemy poradziæ sobie z liniami, musimy upewniæ się, ŋe nasze neurony są ograniczone, poniewaŋ wyobraž sobie, ŋe jeķli twój neuron moŋe naprawdę strzelaæ bardzo wysoko, twój mózg pęknie, więc zachowaliķmy funkcję logistyczną , wówczas górny koniec staje się pochlebny, więc funkcja logistyczna w kombinacji liniowej prowadzi do wyjķcia neuronu. Moŋemy okreķliæ algorytm sieci neuronowej, taki jak poniŋszy
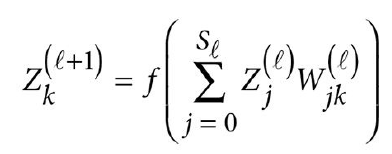
gdzie
Zk(l + 1) → Aktywacja k-tego neuronu w następnej warstwie
f → Funkcja aktywacji
Z0jl → Aktywacja jth Neuronu w bieŋącej warstwie
Wjkl → Wagi (parametry)
Pozwól, ŋe podsumuję to samo, istnieją róŋne komponenty, moŋesz mapowaæ to do struktury neuronu, więc dane wejķciowe to ci faceci, dendryty pochodzące z poprzedniej warstwy, wszystkie są agregowane, wysyģają przez Axon do z drugiej strony, po funkcji aktywacji, jest to wyjķcie neuronu, który trafia do przyszģych neuronów. Neuron nie wie, co zrobiæ z wyjķciem, po prostu mówi, ŋe jeķli się ze mną poģączycie, to wģaķnie otrzymacie. Zadaniem funkcji aktywacyjnych jest upewnienie się, ŋe liniowa rzecz nie idzie w nieskoņczonoķæ, w kierunku dodatnim lub ujemnym, więc po prostu ogranicza, ŋe w systematyczny sposób istnieją róŋne rodzaje funkcji aktywacyjnych. Wystarczy spojrzeæ na ich ksztaģty, wszyscy robią to samo, niezaleŋnie od tego, co się zbliŋa, dane wejķciowe mogą byæ bardzo duŋe, chcę zawrzeæ ten zakres wyjķciowy w zakresie od 0 do 1. z tego powodu potrzebujemy czegoķ powiązaæ dane wyjķciowe. Wģaķnie dlatego wstawiliķmy regresję logistyczną w pierwszej kolejnoķci. więc ksztaģt się zmienia. Wszystkie te funkcje robią to samo z niewielkimi zmianami, koncepcja jest blisko granicy, musisz byæ w stanie zrobiæ coķ gģadkiego, aby nie wyglądaģa jak twardy Perceptron, i z dala od granicy muszą byæ w stanie zawieraæ wartoķci od 0 do 1. jeķli te dwie wģaķciwoķci istnieją, moŋemy zdefiniowaæ wszystkie rodzaje takich funkcji aktywacyjnych, wszystko to pochodzi z neuronauki, przeprowadzają wiele eksperymentów, aby dowiedzieæ się, co to jest wģaķciwa funkcja. Jednym z problemów z sieciami neuronowymi byģo to, ŋe wiem, jak trenowaæ cięŋar tej warstwy, im bardziej wewnętrzna jest warstwa, tym trudniej jest ją poprawiæ, poniewaŋ zaleŋy to od wielu rzeczy, które w koņcu się wydarzyģy,i które doprowadziģo do dobra lub zģa. Pomyķl o tym w ten sposób, jeķli poproszę dziecko, aby rozpoznaģo A w porównaniu z 4, neurony, które wykrywają linie, odgrywają rolę, neuron, który wykrywa postaæ A, odgrywa rolę, ŋe neuron otrzyma bezpoķredni wkģad, dziecko powiedziaģo A i to nie jest A. Więc musi się naprawiæ, ale ta fiksacja cofnie się i powie, czy prawidģowo wykryģeķ linię. Czy to moŋe byæ powód, dla którego nie udaģo się prawidģowo wykryæ A? Tak dziaģa backpropagacja. Byģ to duŋy wynalazek w sieciach neuronowych, który sprawia, ŋe sieci neuronowe nawet trenują wewnętrzne węzģy.Jeķli jest to jedna warstwa, jest to ģatwe. To, co robimy, kiedy budzimy się w ciągu dnia, pobieramy dane, które je przedstawiamy, i otrzymujemy informacje zwrotne, odbieramy informacje zwrotne, a następnie propagujemy i uczymy się itd. Spójrzmy na to samo na danych mieszkaniowych _loan, w danych mieszkaniowych _loan ile mamy danych wejķciowych, to 4, i mamy staģą, potem buduję model i mam 3 wyjķcia, nie wiem ile ukryte jednostki, których naprawdę potrzebuję, moŋe byæ mniej lub bardziej niŋ klasa, bawimy się i szkolimy sieæ neuronową dla zestawu danych Housing_loan. Póžniej wezmę jeden przykģad z tego rzędu, ma on pewne cechy, neurony juŋ mają pewne cięŋary, w oparciu o wagi, którym nadam trochę aktywacji tutaj, która powie mi, czy jestem po tej czy po drugiej stronie linii, i mamy trzy klasy, Wyobraž sobie, ŋe zdecydowaģem, ŋe nowy punkt to klasa 3. Jak wygląda wyjķcie, oczekuję 1 w tym miejscu klasy i 0 w pozostaģych dwóch klasach. w ten sposób zamieniasz problem klasyfikacji na problem sieci neuronowej. Poniewaŋ neuron nie jest jeszcze idealny, moŋe daæ ci 0,9, 0,4, 0,6 dla trzech klas, poniewaŋ nie jest jeszcze w peģni wyszkolony, wówczas znajdujemy bģąd i musimy go propagowaæ wstecz, dlatego nazywa się to propagacją wstecznego bģędu. Tutaj, w tym przypadku, muszę z powrotem propagowaæ bģąd -0,9 bģędu, poniewaŋ zawsze mówimy, ŋe cel minus rzeczywisty (0-0,9) jest bģędem. więc wagi powodujące bģąd tak wysokie, ŋe teraz spadną. w drugim przypadku nawet cięŋary spadną, ale nie tak bardzo, jak w pierwszej sytuacji. w trzecim przypadku otrzymujemy 0,4, więc zwiększamy wagi, aby aktywacja byģa teraz wyŋsza. Tak więc bģąd musi byæ propagowany z góry na dóģ, a dane wyjķciowe muszą iķæ z doģu do góry. Wežmy przykģad zastosowaņ Google do wykrywania zdjęæ, które mogą mieæ 100 warstw. Interpretacja staje się znacznie bardziej zģoŋona, ale robi coķ bardzo potęŋnego. Ilekroæ korzystasz z sieci neuronowych, najpierw dowiedz się wystarczająco duŋo o danych, zdecyduj, jak są one zģoŋone, w ten sposób otrzymamy dobry punkt wyjķcia i zaģóŋmy, ŋe trzy wyglądają wystarczająco dobrze, a następnie spróbuj z 2 i 4 parzystymi i zobacz jeķli to się poprawi. jeķli poprawi się na 4, pozwól mi spróbowaæ nawet z 5 i tak dalej. To kwestia trafienia i próby. Z tego powodu praca naukowca danych jest nieco trudna. Moŋe wróciæ do analizy surowej, zbudowaæ bardzo surowy model, a następnie spojrzeæ wstecz, uczyæ się i tworzyæ model ponownie i tak dalej. Prawdziwym przeģomem byģo to, jak uczysz się tej wagi? Iloķæ obciąŋenia idącego w ten sposób jest proporcjonalna do zaangaŋowania tej jednostki w podejmowanie decyzji. Chodzi o to, ŋe im wyŋsza waga, tym więcej winy musisz wziąæ. Pozwólcie, ŋe wezmę scenariusz biznesowy: Ile bģędu popeģniģ ten dyrektor jest proporcjonalne do kilku rzeczy, takich jak: Ile to byģ bģąd caģkowity i co popeģniģ w tej jednostce, a ile bģąd popeģniģ inny i jaki byģ jego udziaģ w tej decyzji razem ile korekcji musi wykonaæ to urządzenie? Wczeķniejsza propagacja kumuluje bģąd i wysyģa go do moich poprzedników. Robię to samo dla moich juniorów, poniewaŋ w oparciu o ich zaangaŋowanie zobowiązaģem się do mojej V.P. To tak, przekazywanie w przód gromadzi informacje i rozpowszechnia oraz wsteczną propagację w gromadzeniu bģędów i rozpowszechniania. Spójrz na piękno sieci neuronowych, tych samych neuronów, które robią dokģadnie to samo, ale sposób, w jakie są poģączone, przekazują informacje i bģędy i uczą się dalej. Więc wagi ciągle się uczą. To byģ przeģom i dlatego wszyscy dzisiaj mamy karty kredytowe. Wyobraž sobie, ŋe gdybyķmy nie zastosowali sieci neuronowych do problemu wykrywania oszustw, banki zostaģyby zamknięte w systemie kart kredytowych. Sieæ neuronowa jest bezstanowa, w zasadzie wymaga jednego wejķcia i daje jedno wyjķcie, i bierze ten bģąd i propaguje się z powrotem. Nic nie wie o następnym przykģadzie. Pamiętaj, IID (niezaleŋne i identycznie rozmieszczone), neurony są bezstanowe, robi to do tyģu i do przodu. W wielu innych sytuacjach potrzebujesz stanu, na przykģad chcesz zdecydowaæ, jak gģoķno chcesz porozmawiaæ z przyjacielem, to zaleŋy od tego, gdzie jesteķ. Tutaj jest stan, w którym przebywasz i jak daleko on jest lub w pobliŋu. Zasadniczo pomyķl o stanie w ķrodowisku, w którym poprzedni stan równieŋ przyczynia się do następnego wyniku. W sytuacji, gdy zwykģe sieci neuronowe nie dziaģają, wymyķlono coķ nowego, zwanego rekurencyjnymi sieciami neuronowymi. W tym przypadku co robi? Pobiera bieŋący sygnaģ wejķciowy, generuje stan, ale potem zapamiętuje stan, który staje się ponownie sygnaģem wejķciowym, teraz mówimy, ŋe tutaj jest twój aktualny sygnaģ wejķciowy, tutaj jest twój stan, razem zdecydujemy, co powinno byæ następnym wyjķciem. Ilekroæ masz sekwencyjne problemy z uczeniem się, takie jak uczenie się przewidywania rynku akcji, musisz pamiętaæ poprzedni stan, a jeķli chcesz przewidzieæ następne sģowo w sekwencji sģów, musisz pamiętaæ stan. Za kaŋdym razem, gdy dzieje się coķ, pojawia się wewnętrzna pętla sprzęŋenia zwrotnego. poniewaŋ jest to częķæ pamięci w nauce. Jak nasz mózg ma pojęcie pamięci. w grę wchodziģaby rozkģadająca się rzecz, poniewaŋ nie mogę przypisaæ takiej samej wagi wczorajszej nauce i jednemu miesiącowi nauki. To jest jak rozkģad wykģadniczy. Pomyķl o tym, wiesz, co zrobiģeķ dziķ rano, ale nie wiesz, co zrobiģeķ 5 dni temu , więc twój stan jest zawsze aktualny. Innym rodzajem sieci neuronowej jest sieæ kompresyjna. Jeķli zrobimy zdjęcie aparatem, dostanę zdjęcie w formacie png, jest ono bardzo duŋe, a następnie go kompresuję. kiedy kompresja nie jest wystarczająco dobra, powinieneķ byæ w stanie ją rozpakowaæ. Tylko wtedy otrzymasz obraz JPEG. W tej sytuacji nie uczy się niczego zwanego nadzorowanym, nie mówi X do Y, to znaczy, X do skompresowanej wersji X, a następnie rozpakowuje się, teraz wejķcie i wyjķcie powinny byæ podobne. Jeķli kompresja jest dobra, to co robią, przyjmują te same liczby, umieszczają te same liczby na wyjķciu, a następnie uczą się sieci, jest to technika uczenia się bez nadzoru, poniewaŋ nie ma zmiennej Y. Moŋesz uŋyæ tego wszędzie tam, gdzie uŋywasz PCA, PCA jest projekcją liniową. Skompresowane sieci neuronowe są projekcjami nieliniowymi. To jest jak koder mowy, nasze telefony uŋywają tego, twój gģos najpierw jest kompresowany, a następnie przesyģany na kanale, a następnie inny facet go odbiera, ma ten sam dekoder-dekoder, uŋywa dekodera do dekompresji i usģyszy niewielką odmianą tego, co oryginalne. Tutaj nie uczymy się mapowania między czymķ a czymķ innym. Tak jak mapujemy funkcje do etykiet klas. Ale ten problem kompresji oznacza, ŋe musisz nauczyæ się kompresji i dekompresji, aby ogólny bģąd rekonstrukcji ogólnego efektu zostaģ zminimalizowany. Szybkoķæ uczenia się jest kolejnym parametrem, który musimy okreķliæ, tak jak podaliķmy Ukryte jednostki. ogólnie rzecz biorąc, zaczynamy od maģej szybkoķci uczenia się i jeķli uwaŋamy, ŋe jest to bardzo powolna, wówczas zwiększamy szybkoķæ uczenia się, ale w pewnym momencie, jeķli zbyt mocno zwiększymy szybkoķæ uczenia się, zostanie ona przetrenowana, więc musimy znaležæ optymalną szybkoķæ uczenia się . Waŋnym czynnikiem jest wspóģczynnik uczenia ?, który okreķla, o ile zmieniamy wagi w na kaŋdym kroku. Jeķli ? jest zbyt maģe, algorytm zbiegnie się dģugo. I odwrotnie, jeķli ? jest zbyt duŋe, moŋemy w koņcu odbiæ się od powierzchni bģędu poza kontrolą, algorytm się rozbiera.
BUDOWANIE SIECI NEURONOWYCH W ZBIOREZ DANYCH HOUSING_LOAN
Krok 1: Zainstaluj i zaģaduj wymagane pakiety
install.packages('neuralnet')
library("neuralnet")
library(dummies)
library(vegan)
Krok 2: Ģadowanie danych do R:
loandata=read.csv(file="D:\\R data\\Housing_loan.csv", header=TRUE, sep=",")
fix(loandata)
Krok 3: Usuņ kolumnę Identyfikator kolumny z danych
loandata2=subset(loandata, select=-c(ID))
fix(loandata2)
Edu_dum =dummy(loandata2$Education)
loandata3=subset(loandata2,select=-c(Education))
fix(loandata3)
loandata4=cbind(loandata3,Edu_dum)
fix(loandata4)
Krok 4: Standaryzuj dane, stosując metodę "Range"
loandata_stan=decostand(loandata4,"range")
fix(loandata_stan)
# Ustaw ziarno, aby uzyskaæ te same dane za kaŋdym razem
set.seed (123)
Krok 5: Pobierz losową próbkę 60% rekordów danych pociągu
train = sample(1:1000,600)
loan_train = loandata_stan[train,]
# Pobierz losową próbkę 40% rekordów dla danych testowych
test = (1:1000) [-train]
loan_test = loandata_stan[test,]
table(loandata_stan$Loan_sanctioned)
table(loan_train$Loan_sanctioned)
table(loan_test$Loan_sanctioned)
rm(loandata2, loandata3, loandata4,loandata_stan, Edu_dum, test, train)
Krok 6: Zbuduj sieæ neuronową
nn <- neuralnet(Loan_sanctioned~ Age+Experience+
Income+Family+ Education1+Education2+ Education3,
data=loan_train, hidden=c(2,3))
out <- cbind(nn$covariate, nn$net.result[[1]])
fix(out)
dimnames(out) = list(NULL,c ("Age","Experience","Income","Family","Education1","
Education2", "Education3","nn-output"))
Krok 7: Wyķwietl najlepsze rekordy w zestawie danych
head(out)
plot(nn)
Krok 8: Przygotowanie danych do matrycy klasyfikacji
p=as.data.frame(nn$net.result)
colnames(p)="pred"
pred_class <- factor(ifelse(p$pred > 0.5, 1, 0))
a <- table(pred_class, loan_train$Loan_sanctioned)
recall <- a[2,2]/(a[2,1]+a[2,2])*100
Krok 9: Pobieranie wymaganych kolumn z danych
test_data2=subset(loan_test, select=-c(Loan_sanctioned))
new.output <- compute(nn,covariate=test_data2)
p=as.data.frame(new.output$net.result)
colnames(p)="pred"
pred_class <- factor(ifelse(p$pred > 0.5, 1, 0))
a <- table(pred_class,loan_test$Loan_sanctioned)
recall <- a[2,2]/(a[2,1]+a[2,2])*100
recall
Krok 10: Zagraj z róŋnymi strukturami węzģów (3), (2,2), (4,3)
Moŋemy wziąæ róŋne ukryte warstwy i róŋne ukryte dane wejķciowe i stworzyæ model, sprawdziæ ich dokģadnoķæ i przywoģaæ procenty. Następnie sfinalizuj model na podstawie dokģadnoķci i przywoģaj zestaw danych sprawdzania poprawnoķci (testowania).
KROK 17
Obsģuga Maszyn Wektorowych
WPROWADZENIE
Support Vector Machine (SVM) to narzędzie do klasyfikacji i regresji, które wykorzystuje teorię uczenia maszynowego, aby zmaksymalizowaæ dokģadnoķæ predykcyjną, jednoczeķnie automatycznie unikając nadmiernego dopasowania do danych. Ilekroæ myķlimy o stworzeniu modelu, myķlimy o kilku rzeczach, takich jak zģoŋonoķæ, determinizm, próbkowanie, cechy itp. Zģoŋonoķæ: w dobrej technice modelowania powinniķmy byæ w stanie kontrolowaæ jej zģoŋonoķæ, w przypadku mieszanki Gaussa zģoŋonoķæ jest liczbą komponentów o zģoŋonoķci sieci neuronowej to liczba ukrytych jednostek i ukrytych warstw. Determinizm: chcę, aby algorytm wytwarzaģ ciągle to samo z tymi samymi danymi treningowymi. Wyobraž sobie inne algorytmy w zaleŋnoķci od punktu początkowego, który idzie gdzie indziej. nie jest to poŋądana wģaķciwoķæ, ale dzieje się tak, gdy masz zģoŋony model. Perceptron, sieci neuronowe, K-oznacza Klastry mają ten sam problem, za kaŋdym razem nie dają tego samego wyniku.
Optimal Hyper Plane: Problem klasyfikacji moŋna ograniczyæ do kontemplacji problemu dwóch klas bez utraty ogólnoķci. W tym problemie celem jest rozróŋnienie dwóch klas za pomocą funkcji indukowanej na podstawie przedstawionych przykģadów. Celem jest stworzenie klasyfikatora, który będzie dziaģaģ dobrze na niewidzialnych przykģadach, tj. dobrze się uogólni. Istnieje wiele potencjalnych klasyfikatorów liniowych, które mogą oddzieliæ dane, ale jest tylko jeden, który maksymalizuje margines (maksymalizuje odlegģoķæ między nim a najbliŋszym punktem danych kaŋdej klasy). Ten liniowy klasyfikator nazywa się optymalną hiperpģaszczyzną oddzielającą. Powiedzmy, ŋe mam zestaw danych z problemem dwóch klas, chcę zbudowaæ klasyfikator i uŋywam Perceptron jako klasyfikatora. Perceptron, bez względu na to, gdzie się zaczyna, kontynuuje naukę i gdy tylko przestaje popeģniaæ bģąd, przestaje się uczyæ. Moŋemy mieæ wiele perceptronów (Infinite) dla zestawu danych, który ma problem z dwiema klasami. Wszystkie te perceptrony mają ten sam koszt bģędnej klasyfikacji, co zero. więc wszystkie te mogą byæ prawidģowymi modelami. Ale co jest z nimi nie tak? Po pierwsze, nie są deterministyczne, co oznacza, ŋe za kaŋdym razem, gdy zaczynam gdzie indziej, daje to inny rezultat. Jest jeszcze jeden problem, są punkty, które są naprawdę blisko granicy. Więc jest to delikatny model. Jeķli otrzymam nieco inny punkt danych, moŋe popeģniæ duŋy bģąd. Nie tego chcemy. Chcieliķmy, aby model byģ bardziej solidny. Teraz, gdy mamy te problemy, powinniķmy spróbowaæ czegoķ lepszego niŋ istniejące modele, takie jak pojawiģ się SVM. Pomyķl teraz intuicyjnie, gdzie powinna byæ granica decyzyjna. Powinien znajdowaæ się daleko od obu punktów danych, czyli w ķrodku najbliŋszych punktów danych. Granica decyzji musi byæ solidna. niewielkie zmiany i haģas nie powinny wpģywaæ na granicę decyzji.
Wyobraž sobie, ŋe są to dwie wioski, a ty chcesz zrobiæ między nimi drogę. Droga musi byæ tak szeroka, jak to moŋliwe, ale istnieje ograniczenie, jeķli chcę zbudowaæ szeroką drogę, ale nie chcę rozbijaæ domów. Próbujemy tutaj zbudowaæ granicę tak solidną, jak to moŋliwe, bez niszczenia domów po obu stronach. Jaki byģby dobry klasyfikator? Chcę liniowego klasyfikatora takiego, ŋe chcę narysowaæ linię po obu stronach i zatrzymaæ się tam, gdzie jest pierwszy dom. a następnie spojrzeæ na szerokoķæ tej drogi. Jest to równieŋ nazywane klasyfikatorem maksymalnego marginesu. Tutaj nie wszystkie punkty danych są waŋne, punkty danych znajdujące się w pobliŋu granicy są waŋne. Pytanie brzmi, czy moŋesz znaležæ domy, wzdģuŋ których mogę zrobiæ drogę. Pozwól nam zobaczyæ jak matematyk rozwiązuje problem uczenia maszynowego. Jeķli mam hiperpģaszczyznę i chcę zmierzyæ odlegģoķæ prostopadģą między początkiem a linią, będzie to tyle (- B / | w |).
Więc chcę znaležæ W i B, próbujemy tutaj, jeķli moglibyķmy znaležæ ķrodek drogi, jeķli pójdziesz +1 tutaj lub -1 tutaj nie powinno byæ nic (ŋadnych domów) pomiędzy nimi. Tak więc równanie wygląda mniej więcej tak: Xi (najbliŋszy punkt danych), dla wszystkich domów, które są po jednej stronie drogi, warunek ten powinien obowiązywaæ (W + B> = +1) dla wszystkich domów, które są na po drugiej stronie drogi, drugi stan powinien się utrzymaæ. (W + B <= -1). Teraz pamiętaj, co robią Perceptron, Perceptron mówi, ŋe Xi W + W0 jest> 0 lub <0. W Perceptron, gdy tylko przekroczysz granicę, znajdziesz się po drugiej stronie. Nie ma pojęcia marginesu. To tylko linia. W SVM potrzebujemy marginesu bģędów, więc zamiast powiedzieæ 0, wstawimy tutaj 1 i -1. Jest to jedyna róŋnica między Perceptronem, który ma zerową marŋę a SVM, która ma maksymalny margines, co oznacza, ŋe zwiększamy gruboķæ perceptronu. Jeķli umieķcimy oba powyŋsze równania w jednym, otrzymamy Yi (Xi.W + B) -1> = 0. W uczeniu nadzorowanym zawsze definiujemy
funkcję celu i rozwiązujemy ją. Funkcja celu skģada się z dwóch częķci. (Maksymalizuj, ograniczenia). Tutaj staramy się zmaksymalizowaæ margines pod warunkiem, ŋe nie będzie szkód dla domów. Powiedz mi teraz, ile tu jest ograniczeņ? Wróæmy do sytuacji programowania liniowego. W programowaniu liniowym rysujemy wiązkę linii, które są uwaŋane za ograniczenia liniowe. Dlatego uwaŋamy, ŋe powinno to znajdowaæ się po jednej stronie linii. Nie mogę narysowaæ linii tak szerokiej, jak to moŋliwe, poniewaŋ mam ograniczenie, ŋe nie mogę rozbiæ domów. Mam teraz N (ģączną liczbę punktów danych), poniewaŋ nie mogę zģamaæ ŋadnego z domów. Na wstępnym schemacie wszystkie linie są moŋliwe, ale musimy dalej dostroiæ moją funkcję celu, aby uzyskaæ unikalną linię lub optymalne rozwiązanie. Linia poģoŋona najdalej z obu stron jest najlepsza, poniewaŋ maksymalizuje margines. Kiedy formuģujemy problem, oznacza to tylko, ŋe gdyby to byģa linia, jaki byģby margines, jakie byģyby ograniczenia, a następnie rozwiązaliķmy dla tego, co byģoby linią. To tak, jakby X byģ rozwiązaniem i rozwiązaģ dla X. Jeķli spojrzymy na matematykę, Geometria mówi: Jeķli narysowaģem prostopadģą linię od początku do dowolnej linii, wówczas dģugoķæ wynosi (-b / w). wtedy, gdy spojrzymy na pozostaģe dwie linie, jedna jest powyŋej, a druga poniŋej, ich dģugoķæ wynosiģaby (1-b / w) i (-1-b / w), Margines byģby jednym równaniem minus inne równanie. B zostaje anulowane, a otrzymujemy 2 / W.
Tutaj mamy funkcję celu i zestaw ograniczeņ. Ograniczenia to liczba punktów danych, poniewaŋ nie moŋemy rozbiæ ŋadnego domu W wiosce kaŋdy punkt danych (Dom) jest moim ograniczeniem. Naszym celem jest optymalizacja funkcji celu przy danych ograniczeniach. W tej sytuacji Lagrange zaproponowaģ Mnoŋnik, który mówi, ŋe musimy zapģaciæ pewną karę za zģamanie kaŋdego ograniczenia. Zaģóŋmy, ŋe w przypadku naruszenia i-tego ograniczenia pģacisz karę Alpha I Ci (x). Ta alfa nazywa się mnoŋnikiem Lagrange'a. Następnie sumujemy wszystkie kary. W algorytmie maszyny wektorowej Wsparcia moŋemy zastosowaæ trzy triki:
1. Konwersja pierwotna na podwójną
2. Zmienne swobodne
3. Wybór jądra
Pomyķl tylko, ŋe naszym celem jest maksymalizacja marginesu, więc naruszenie ograniczenia powinno zminimalizowaæ wartoķæ. Musimy więc odjąæ ogólne sumowanie kar od funkcji celu, którą staramy się maksymalizowaæ.
PODSTAWOWA PODWÓJNA KONWERSJA
Mnoŋnik Lagrange′a: Pozwólcie, ŋe wezmę prosty przykģad, abyķcie mogli zrozumieæ caģą teorię. Wyobražmy sobie, ŋe twoja ŋona dzwoniģa do ciebie i powiedziaģa, ŋe o 19.30 planuje wyjķæ na zakupy. Teraz Twoim celem jest wczesne dotarcie do domu. To jest twoja funkcja celu. Masz zestaw ograniczeņ, takich jak wczeķniejsze zakoņczenie pracy, nie ježdž bardzo szybko, nie przeskakuj sygnaģu, nie uderzaj w ŋaden pojazd itp., Jeķli naruszysz którekolwiek z tych ograniczeņ, zostaniesz ukarany, kara róŋni się od jedno ograniczenie do drugiego. Na koniec sumujemy wszystkie kary i odejmujemy je od funkcji celu, którą próbujesz zmaksymalizowaæ. Musimy pomyķleæ, czy naruszając jakiekolwiek ograniczenie, czy nie, osiągnęliķmy nasz cel. Gdybyķmy nie zģamali ŋadnego ograniczenia, nasza kara wyniósģaby zero.
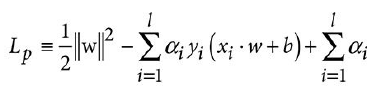
Pierwotny problem Lagrange′a wygląda tak jak powyŋej i musimy zrozumieæ, ŋe chcemy przeksztaģciæ ten pierwotny problem w podwójny problem, abym mógģ pozbyæ się W i B. Poniewaŋ jeķli znam alfę, potrafię obliczyæ w i b. tak jest, jeķli wiem, jakie są domy, których nie powinienem burzyæ podczas ukģadania drogi, mogę odpowiednio zaplanowaæ swoją drogę. Podwójna postaæ równania wygląda tak, ŋe nie mamy wi i b
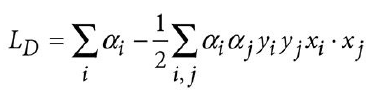
Waŋną rzeczą do zapamiętania jest to, ŋe moŋemy zmaksymalizowaæ margines, identyfikując te punkty danych (domy), które będą stanowiæ granicę, w zasadzie są to tak zwane wektory wsparcia. Są to wektory, poniewaŋ są to punkty w przestrzeni o duŋych wymiarach i są to punkty (wektory) podtrzymujące pģaszczyznę (granica decyzji). Mamy jedno ograniczenie dla jednego punktu danych, a po rozwiązaniu tego wygenerowaliķmy wiązkę wartoķci alfa dla kaŋdego punktu danych. Te wartoķci alfa mówią, ŋe punkt ten znajduje się w pobliŋu granicy decyzji, czy nie. Waŋne jest, aby zrozumieæ, ŋe większoķæ wartoķci alfa wynosi zero, poniewaŋ większoķæ punktów danych znajduje się w granicach (większoķæ domów znajduje się w wiosce). Musimy tu zrozumieæ, ŋe im wyŋsza wartoķæ alfa, tym wyŋszy punkt znajduje się na drodze.
ZMIENNE SWOBODNE
Do tej pory omawiamy dane, które moŋna rozdzieliæ liniowo. Teraz zastanów się, co się stanie, jeķli punktów danych nie da się rozdzieliæ liniowo. Wyobraž sobie tylko dane ze ķwiata rzeczywistego, których zwykle nie moŋna oddzieliæ liniowo. Tutaj musimy zastosowaæ jeszcze jedną sztuczkę zwaną zmiennymi swobodnymi. Jeķli zestawu treningowego nie da się rozdzieliæ liniowo, stosujemy standardowe podejķcie, aby pozwoliæ marginesowi decyzji dotyczącej tģuszczu popeģniæ kilka bģędów dla niektórych punktów danych, takich jak wartoķci odstające lub haģaķliwe przykģady, które znajdują się wewnątrz lub po niewģaķciwej stronie marginesu. Następnie ponosimy koszty za kaŋdy bģędnie sklasyfikowany przykģad, który zaleŋy od tego, jak daleko jest do speģnienia wymogu depozytu zabezpieczającego. Aby to zaimplementowaæ, wprowadzamy zmienne luzu. Niezerowa wartoķæ ?i pozwala xi nie speģniaæ wymogu marŋy przy koszcie proporcjonalnym do wartoķci ?i. Problemem związanym z optymalizacją jest zatem kompromis między tym, jak gruby moŋe zrobiæ margines, a tym, ile punktów naleŋy przesunąæ, aby umoŋliwiæ ten margines. Margines moŋe byæ mniejszy niŋ 1 dla punktu xi poprzez ustawienie >i> 0, ale następnie pģaci się karę C?i w minimalizacji za zrobienie tego. Suma ?i daje górną granicę liczby bģędów treningowych.Miękkie arginesy SVM minimalizują bģąd szkolenia, który jest wymieniany z marginesem. Parametr C jest terminem regularyzacji, który zapewnia sposób kontrolowania nadmiernego dopasowania: poniewaŋ C staje się duŋy, nieatrakcyjne jest nieprzestrzeganie danych kosztem zmniejszenia marginesu geometrycznego; gdy jest maģy, ģatwo jest uwzględniæ niektóre punkty danych za pomocą zmiennych swobodnych i ustawiæ gruby margines , aby modelowaģ większoķæ danych. Obserwuj powyŋsze punkty danych i podane ograniczenia. Z tymi punktami danych moŋliwa jest droga, ale
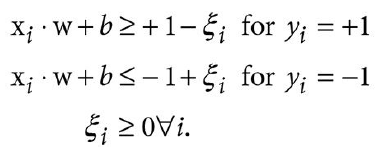
Co to za model?
• Jaki jest model?
• Jakie są parametry?
• Czym jest zģoŋonoķæ?
ZADANIE KERNELA
Jeķli dane moŋna rozdzieliæ nieliniowo, oznacza to, ŋe jeķli danych nie moŋna oddzieliæ linią prostą, to chcemy, aby SVM rzutowaģ dane do przestrzeni o większych wymiarach, aby umoŋliwiæ to liniowo lub wykonaæ separację liniową. To się nazywa sztuczka jądra.
BUDOWANIE MASZYNY WEKTOROWEJ W OPARCIU O ZBIÓR DANYCH HOUSING_LOAN
setwd ("Dane D: / R")
# Ģadowanie danych do R:
loandata=read.csv(file="Housing_loan.csv", header=TRUE)
# Przygotowanie danych: Usuņ identyfikator kolumny z danych
loandata2=subset(loandata, select=-c(ID))
fix(loandata2)
# Zmienna "Edukacja" ma więcej niŋ dwie kategorie (1: licencjackie, 2: magisterskie, 3: zaawansowane / profesjonalne), # więc musimy utworzyæ zmienne zastępcze dla kaŋdej kategorii, aby uwzględniæ je w analizie. Utwórz zmienne zastępcze dla zmiennej kategorialnej
# "Edukacja" i dodaj te zmienne obojętne do oryginalnych danych.
install.packages("dummies")
library(dummies)
#Zainstaluj i zaģaduj pakiet "manekinów", aby utworzyæ zmienne zastępcze
Edu_dum=dummy(loandata2$Education)
head(Edu_dum)
loandata3=subset(loandata2,select=-c(Education))
loandata4=cbind(loandata3,Edu_dum)
head(loandata4)
# Standaryzacja danych: Standaryzuj dane, stosując metodę "Range"
install.packages("vegan")
library(vegan)
loandata5=decostand(loandata4,"range")
#Przygotuj zestawy danych o pociągach i testach. Wež losową próbkę 60% rekordów dotyczących pociągu
data
train = sample(1:1000,600)
train_data = loandata5[train,]
nrow(train_data)
# Wež losową próbkę 40% rekordów dla danych testowych
test = (1:1000) [-train]
test_data = loandata5[test,]
nrow(test_data)
# Podsumowanie danych dla zmiennej odpowiedzi "Loan_sanctioned":
table(loandata5$Loan_sanctioned)
#Train Data
table(train_data $Loan_sanctioned)
#Dane testowe
table(test_data$Loan_sanctioned)
# Klasyfikacja za pomocą SVM:
install.packages("e1071")
library(e1071)
# Zainstaluj i zaģaduj pakiet e1071, aby przeprowadziæ analizę SVM.
x = subset(train_data, select = -Loan_sanctioned)
y = as.factor(train_data$Loan_sanctioned)
?svm
model = svm(x,y, method = "C-classification", kernel = "linear", cost = 10, gamma = 0.1)
# Jądro: Jądro uŋywane podczas szkolenia i przewidywania. Moŋesz rozwaŋyæ zmianę niektórych następujących parametrów, w zaleŋnoķci od typu jądra.
# koszt naruszenia ograniczeņ (domyķlnie: 1) -jest to staģa "C" terminu regularyzacji w sformuģowaniu Lagrange′a.
# Gamma: parametr wymagany dla wszystkich jąder z wyjątkiem liniowego.
summary(model)
# Test z danymi pociągu
pred = predict(model, x)
table(pred, y)
# Test z danymi testowymi
a = subset(test_data, select = -Loan_sanctioned)
b = as.factor(test_data$Loan_sanctioned)
pred= predict(model, a)
table(pred, b)
model2 = svm(x,y, method = "C-classification", kernel = "radial", cost = 10, gamma = 0.1)
summary(model2)
#Test z danymi pociągu
pred = predict(model, x)
table(pred, y)
#Test z danymi testowymi
pred = predict(model, a)
table(pred, b)
KROK 18
Ensemble Learning
WPROWADZENIE
Przejdžmy do innego wymiaru technik modelowania, zwanego metodami zespolonymi. Do tej pory omawialiķmy poszczególne modele i widzimy, jak radziæ sobie z rosnącą zģoŋonoķcią, ale zastanówmy się, co zrobiæ, jeķli te modele nie są wystarczająco dobre? Jeķli liniowy SVM nie wystarczy, idziemy do wielomianowej SVM stopnia 2, a następnie stopnia 3, jeķli to nie wystarczy, przechodzimy do nieliniowej SVM z jądrem RBF, istnieje sposób na zwiększenie zģoŋonoķci, ale jak widzieliķmy, wzrost zģoŋonoķci zwiększy dokģadnoķæ do jednego okreķlonego poziomu. W tej metodzie ciągle zwiększamy zģoŋonoķæ. Kolejnym duŋym obszarem poprawy wydajnoķci modelu jest opracowanie lepszych funkcji. Moŋesz powiedzieæ, ŋe wyodrębniģem wiele funkcji i zbudowaģem model, zbudowaģem najlepszy moŋliwy model z tym zestawem funkcji, nie mogę zrobiæ nic lepszego, pozwól mi wróciæ do moich danych, pozwól mi ulepszyæ moje funkcje , dodaj jeszcze kilka funkcji, ponownie zbuduj model zģoŋony i ten cykl trwa. Z surowymi funkcjami moŋemy potrzebowaæ zģoŋonych modeli, ale przy lepszej inŋynierii funkcji moŋemy potrzebowaæ prostego modelu. Przyjmijmy inne podejķcie do poprawy wydajnoķci naszego modelu, zwane uczeniem się w zespole. W ten sposób, zamiast uczyæ się na zģoŋonym modelu, uczymy się wielu prostych modeli i ģączymy je. Takie jest podejķcie do zwiększenia ogólnej zģoŋonoķci modelu. Zespóģ jest niczym innym jak grupą rzeczy jako pojedynczą kolekcją. Do tej pory zajmujemy się pobieraniem danych, wydobywaniem niektórych funkcji, szkoleniem modelu, zwiększaniem zģoŋonoķci modelu i uzyskiwaniem danych wyjķciowych. Zespóģ to technika ģączenia wielu sģabych uczniów w celu stworzenia silnego ucznia. W statystyce i uczeniu maszynowym metody zespolone wykorzystują wiele modeli, aby uzyskaæ lepszą wydajnoķæ predykcyjną niŋ moŋna by uzyskaæ z dowolnego z gģównych modeli. Termin zespóģ jest zwykle zarezerwowany dla metod generujących wiele hipotez przy uŋyciu tego samego podstawowego ucznia. Ocena predykcji zestawu zwykle wymaga więcej obliczeņ niŋ ocena predykcji pojedynczego modelu, więc zespoģy mogą byæ uwaŋane za sposób na zrekompensowanie sģabych algorytmów uczenia się poprzez wykonanie wielu dodatkowych obliczeņ. Szybkie algorytmy, takie jak drzewa decyzyjne, są powszechnie stosowane w zestawach.
BAGGING
Bagging jest techniką stosowaną do zmniejszania wariancji naszych prognoz poprzez ģączenie wyniku kilku klasyfikatorów modelowanych na róŋnych podpróbkach (próbkowanie danych) tego samego zestawu danych. Utwórz wiele zestawów danych: Próbkowanie jest wykonywane z zastąpieniem oryginalnych danych i tworzone są nowe zestawy danych. Nowe zestawy danych mogą zawieraæ uģamek kolumn, a takŋe wierszy, które są ogólnie hiperparametrami w modelu workowania. Pomaga to w tworzeniu solidnych modeli, mniej podatnych na nadmierne dopasowanie. Budujemy wiele klasyfikatorów na kaŋdym zestawie danych i prognozy są dokonywane. Poģączone klasyfikatory: prognozy wszystkich klasyfikatorów są ģączone przy uŋyciu wartoķci ķredniej lub trybu w zaleŋnoķci od problemu biznesowego. Poģączone wartoķci są w większoķci bardziej niezawodne niŋ pojedynczy model. Większa liczba modeli ma zawsze lepszą wydajnoķæ niŋ niŋsze liczby. Moŋna hipotetycznie wykazaæ, ŋe wariancja poģączonych prognoz jest zmniejszona do 1 / n (n: liczba klasyfikatorów) pierwotnej wariancji. Kroki w agregacji Bootstrap (Bagging):
• Zaczynamy od wielkoķci próbki N.
• Tworzymy duŋą liczbę próbek o tym samym rozmiarze. Nowe próbki są generowane z zestawu danych szkoleniowych przy uŋyciu próbkowania metodą zastępczą. Nie są więc identyczne z oryginalną próbką.
• Powtarzamy to wiele razy, moŋe 1000 razy, i dla kaŋdej z tych próbek ģadowania początkowego obliczamy jego ķrednią, która nazywa się szacunkami ģadowania początkowego.
• Utwórz histogram z tymi szacunkami, jeķli zapewnia oszacowanie ksztaģtu rozkģadu ķredniej, z którego moŋemy dowiedzieæ się, o ile ķrednia się zmienia.
Kluczową zasadą bootstrap jest zapewnienie sposobu symulowania powtarzających się obserwacji z nieznanej populacji na podstawie uzyskanej próbki jako podstawy. Pobieramy n *
LASY LOSOWE
Random Forest to metoda uczenia się przez zestaw do klasyfikacji i regresji, polegająca na tworzeniu wielu drzew decyzyjnych. Losowe lasy są doķæ szybkie i ģatwe w uŋyciu. Potrafią poradziæ sobie z rzadkimi danymi, a dzięki Random Forest moŋemy rozwiązaæ problem nadmiernego dopasowania. Random Forest moŋe pobieraæ inny podzbiór (próbkę) danych z zamiennikiem, a nawet moŋe próbkowaæ cechy, co oznacza, ŋe wykonuje próbkowanie danych (obserwacje), a takŋe próbkowanie cech (zmienne). Ostatecznie decyzję podejmuje się większoķcią gģosów. W drzewie decyzyjnym budowane jest jedno drzewo decyzyjne, a w algorytmie losowego lasu wiele drzew decyzyjnych jest budowanych podczas procesu. Gģosowanie z kaŋdego drzewa decyzyjnego jest brane pod uwagę przy podejmowaniu decyzji o ostatecznej klasie sprawy lub obiektu, nazywa się to procesem zespoģowym. Poniewaŋ wiele drzew decyzyjnych jest budowanych i wykorzystywanych w procesie algorytmu Losowego Lasu, nazywa się to Lasem. Wiemy, ŋe ramka danych ma dwa wymiary: 1. Rzędy i 2. Kolumny. W przypadku budowy drzewa decyzyjnego wybiera się próbki ramki danych zastępując je wraz z wyborem podzestawu kolumn dla kaŋdego drzewa decyzyjnego. Zarówno próbkowanie ramki danych (Próbkowanie danych), jak i wybór podzbioru zmiennych (Próbkowanie cech) odbywa się losowo. Dlatego nazywamy to Losowym Lasem. Losowe lasy poprawiają dokģadnoķæ predykcyjną o generowanie duŋej liczby drzew ģadowanych na podstawie losowych próbek zmiennych, klasyfikowanie przypadku przy uŋyciu kaŋdego drzewa w tym nowym "lesie" oraz podejmowanie ostatecznych przewidywanych wyników poprzez ģączenie wyników we wszystkich drzewach.
BUDOWANIE MODELU PRZY UŊYCIU LASU LOSOWEGO
Krok 1: Zainstaluj i zaģaduj wymagane pakiety i bibliotekę
install.packages('randomForest')
library(randomForest)
Krok 2: Odczytaj dane i utwórz ramkę danych.
Diab<-read.csv(file="D:/R data/Diab.csv",header = T)
Krok 3: Przeglądaj ramkę danych
fix(Diab)
str(Diab)
Krok 4: Ustaw ziarno, aby uzyskaæ powtarzalne wyniki
set.seed (4848)
Krok 5: Utwórz pociąg i przetestuj zestawy danych Pociąg (70%), Test (30%).
# Wež losową próbkę 70% rekordów danych pociągu
train = sample(1:500,350)
train_data = Diab[train,]
nrow(train_data)
# Wež losową próbkę 30% rekordów dla danych testowych
test = (1:500) [-train]
test_data = Diab[test,]
nrow(test_data)
Krok 6: Zbuduj model za pomocą algorytmu losowego lasu
fit <- randomForest(as.factor(Diabetic) ~ Gender + Age + OGTT + DBP + BMI,
data=train_data, importance=TRUE, ntree=400)
Krok 7: Sprawdž, jakie zmienne byģy waŋne:
varImpPlot(fit)
Krok 8: Sprawdž poprawnoķæ modelu, przewidując niewidoczne dane
Prediction <- predict(fit, test_data)
Final <- data.frame(Id = test_data$Pat_Id, Diabetic = Prediction)
fix(Final)
Krok 9: Jeķli nie jesteķ zadowolony z wyników modelu, moŋesz spróbowaæ wnioskowania warunkowego drzewa, które podejmują decyzje za pomocą testu statystycznego, a nie czystoķci pomiaru.
install.packages('party')
library(party)
fit <- cforest(as.factor(Diabetic) ~ Gender + Age + OGTT + DBP + BMI,
data=train_data, controls=cforest_unbiased(ntree=700, mtry=3))
Prediction <- predict(fit, test_data, OOB=TRUE, type = "response")
W losowym lesie zmuszamy model do przewidywania naszej klasyfikacji, tymczasowo zmieniając zmienną docelową na czynnik z tylko dwoma poziomami, uŋywając as.factor(). Argument waŋnoķæ = PRAWDA pozwala nam sprawdzaæ zmienne znaczenie, a argument ntree okreķla, ile drzew chcemy wyhodowaæ. Jeķli pracujesz z większym zestawem danych, spróbuj uŋyæ mniejszej liczby drzew lub ogranicz zģoŋonoķæ kaŋdego drzewa, uŋywając wielkoķci węzģa, a takŋe zmniejsz liczbę wierszy próbkowanych przy pomocy sampsize. Moŋesz równieŋ zastąpiæ domyķlną liczbę zmiennych do wyboru za pomocą mtry, ale domyķlnie jest to pierwiastek kwadratowy z ogólnej liczby, ogólnie dziaģa dobrze. Moŋemy uŋyæ zastępowania Takes True i False i wskazuje, czy pobraæ próbkę z / bez zastępczej bliskoķci Czy obliczyæ miary bliskoķci między wierszami opcji ramki danych. Oszacowanie bģędu braku opakowania (OOB): W losowych lasach nie ma potrzeby weryfikacji krzyŋowej lub oddzielnego zestawu testowego, aby uzyskaæ obiektywną ocenę bģędu zestawu testowego. Kaŋde drzewo jest konstruowane przy uŋyciu innej próbki bootstrap od danych. Okoģo 1/3 przypadków nie zostaģa uwzględniona w próbce ģadowania początkowego i nie zostaģa uŋyta w konstrukcji drzewa Kth. Umieķæ kaŋdą skrzynkę pominiętą w konstrukcji k-tego drzewa w dóģ k-tego drzewa, aby uzyskaæ klasyfikację. W ten sposób uzyskuje się klasyfikację zestawu testowego dla kaŋdego przypadku w okoģo 1/3 drzew. Na koniec biegu bierz j, aby byæ klasą, która zdobyģa większoķæ gģosów za kaŋdym razem, gdy przypadek n byģ nieobliczalny. Proporcja razy, gdy j nie jest równa prawdziwej klasie n uķrednionej we wszystkich przypadkach, jest oszacowaniem bģędu OOB, który okazaģ się byæ bezstronny w wielu testach. Niedociągnięcia w losowym lesie Zmienne znaczenie: Losowy las jest bardzo popularny jako technika selekcji zmiennych. Ma jednak równieŋ pewne wady. Jeķli zmienne niezaleŋne innego rodzaju są losowe, zmienna waŋnoķci lasu moŋe byæ myląca. Jeķli wszystkie zmienne niezaleŋne są kategoryczne, ale mają róŋne kategorie, losowa miara waŋnoķci zmiennej lasu moŋe byæ myląca. Aby rozwiązaæ oba powyŋsze problemy, powinniķmy zastosowaæ warunkowy las wnioskowania, tj. Las. Jeķli zmienne niezaleŋne są skorelowane, miara waŋnoķci losowej zmiennej lasu moŋe byæ myląca. Nawet las warunkowy nie usuwa caģkowicie problemu wielokoliniowoķci. W pewnym stopniu rozwiązuje problem kolinearnoķci.
REZERWACJA
Zwiększenie wydajnoķci jest bardziej systematycznym sposobem poprawy wydajnoķci poprzez ģączenie róŋnych klasyfikatorów. Rozwaŋ utworzenie trójskģadnikowych klasyfikatorów dla problemu dwóch kategorii poprzez wzmocnienie.
1. Losowo wybierz n1
4. Jeķli przybliŋenia replikowane podczas ģadowania początkowego byģy prawidģowe, wówczas pakowanie zmniejszyģoby wariancję bez zmiany obciąŋenia. W praktyce pakowanie moŋe zmniejszyæ zarówno stronniczoķæ, jak i wariancję. W przypadku klasyfikatorów o duŋym odchyleniu moŋe zmniejszaæ odchylenie, a w przypadku klasyfikatorów o duŋej zmiennoķci moŋe zmniejszaæ wariancję.
Adaboost: W Adaboost zamiast kaŋdorazowego pobierania próbek do kaŋdej próbki przypisywana jest waga. Waga to prawdopodobieņstwo, ŋe próbka zostanie wybrana w klasyfikatorze. Dziaģa z klasyfikatorami binarnymi, które są lepsze niŋ losowe rzuty monetą (bģąd mniejszy niŋ 0,5). Pomysģ polega na takim dostosowaniu wagi, aby te rekordy, które zostaģy nieprawidģowo sklasyfikowane, zostaģy wybrane do drugiego poziomu klasyfikacji przez drugi klasyfikator. Tak więc, jeķli klasyfikator popeģni bģąd przy przewidywaniu zmiennej, jej waga wzroķnie. Następnie klasyfikator jest definiowany jako liniowa kombinacja wszystkich sģabych klasyfikatorów. Wynikiem jest tryb przewidywania wszystkich klasyfikatorów. Powiedzmy, ŋe mamy zestaw danych (x1, y1),
(xm, ym), gdzie x to wartoķæ, a y to, czy zostaģ wybrany przez klasyfikator. Zatem y przyjmuje wartoķæ -1 lub 1. Zaczynamy od początkowych wag, wybieramy klasyfikator tak, aby bģąd w odniesieniu do rozkģadu byģ minimalny i mniejszy niŋ 0,5. Sģaby klasyfikator ma mniej niŋ 50% bģędu, ale nadal jest niezadowalający (50% to przypadek rzutu monetą, a zatem bģąd ponad 50% nie jest dopuszczalny nawet dla sģabego klasyfikatora
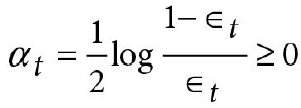
Tutaj jest bģąd pojedynczego klasyfikatora. Po sklasyfikowaniu za pomocą pierwszego sģabego klasyfikatora aktualizujemy wagi tak, aby
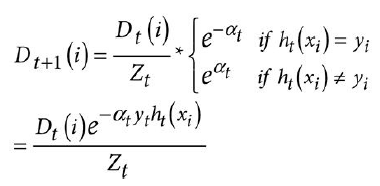
Zt jest czynnikiem normalizacyjnym zapewniającym, ŋe D jest zawsze rozkģadem. Tak więc, jeķli dane pole jest poprawnie sklasyfikowane, wykģadniczy skģadnik jest niski (poniewaŋ y jest dodatnie). Dlatego waga jest niska. Dla tych, którzy są žle sklasyfikowani, y jest ujemne, a zatem wykģadnicze jest duŋe, a zatem wagi rosną. Kontynuujemy wszystkie sģabe klasyfikatory i na kaŋdym etapie wybieramy klasyfikator, który minimalizuje bģąd. W ten sposób jest to chciwy algorytm. We wczesnych iteracjach wzmocnienie jest podstawową metodą zmniejszania uprzedzeņ, aw póžniejszych iteracjach wydaje się byæ przede wszystkim metodą zmniejszania wariancji. Bģąd szkolenia jest definiowany w kaŋdej rundzie stanowi uģamek bģędnie sklasyfikowanych obserwacji.
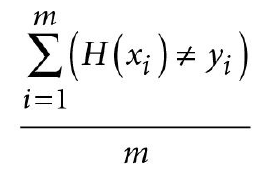
Bģąd treningu spada wykģadniczo szybko. Wybierz ?t, które minimalizują Zt. Nie ma parametrów do dostrojenia (z wyjątkiem liczby rund). Jest szybki, prosty i ģatwy w programowaniu. Zawiera zestaw teoretycznych gwarancji (np. Bģąd szkolenia, bģąd testu) Zamiast próbowaæ zaprojektowaæ algorytm uczenia, który będzie dokģadny w caģej przestrzeni, moŋemy skupiæ się na znalezieniu podstawowych algorytmów uczenia, które muszą byæ lepsze niŋ losowe. Moŋe identyfikowaæ wartoķci odstające: tzn. Przykģady, które są albo bģędnie oznakowane, albo z natury niejednoznaczne i trudne do sklasyfikowania. Jednak faktyczna wydajnoķæ wzmocnienia zaleŋy od danych i podstawowego ucznia. Wzmocnienie wydaje się byæ szczególnie podatne na haģas.
Bagging kontra Boosting: Bagging zawsze wykorzystuje resampling zamiast ponownego waŋenia. Pakowanie nie modyfikuje rozkģadu na przykģadach lub bģędnych etykietach, ale zamiast tego zawsze uŋywa rozkģadu jednolitego. Formuģując ostateczną hipotezę, workowanie przypisuje jednakową wagę kaŋdej ze sģabych hipotez.
BUDOWANIE MODELU ZA POMOCĄ ADABOOST
# Krok 1: Ģadowanie danych do R:
setwd("D:/R data")
loandata=read.csv(file="Housing_loan.csv", header=TRUE)
# Krok 2: Przygotowanie danych:
Usuņ kolumny ID i pģeæ z danych
loandata2=subset(loandata, select=-c(ID, Gender))
fix(loandata2)
# Krok 3: Utwórz zmienne zastępcze dla zmiennej kategorialnej "Edukacja" i dodaj te zmienne zastępcze do pierwotnych danych
#Zainstaluj i zaģaduj pakiet "manekinów", aby utworzyæ zmienne zastępcze
install.packages("dummies")
library(dummies)
Edu_dum=dummy(loandata2$Education)
head(Edu_dum)
loandata3=subset(loandata2,select=-c(Education))
loandata4=cbind(loandata3,Edu_dum)
fix(loandata4)
# Krok 4: Standaryzacja danych:
Standaryzuj dane, stosując metodę "Range"
install.packages("vegan")
library(vegan)
loandata5=decostand(loandata4,"range")
# Krok 5: Przygotuj zestawy danych dotyczące pociągów i testów
# Wež losową próbkę 60% rekordów danych pociągu
train = sample(1:1000,600)
train_data = loandata5[train,]
nrow(train_data)
# Wež losową próbkę 40% rekordów dla danych testowych
test = (1:1000) [-train]
test_data = loandata5[test,]
nrow(test_data)
# Krok 6: Podsumowanie danych dla zmiennej odpowiedzi "Loan_sanctioned":
# Dane ogóģem
table(loandata5$Loan_sanctioned)
#Train Data
table(train_data $Loan_sanctioned)
#Dane testowe
table(test_data$Loan_sanctioned)
# Krok 7: Klasyfikacja za pomocą Adaboost:
#Install & Load pakiet - ada do wykonania analizy SVM.
install.packages("ada")
library(ada)
x = subset(train_data, select = -Loan_sanctioned)
y = as.factor(train_data$Loan_sanctioned)
Ada_20=ada(x,y,iter=20,nu=1,loss="logistic", type="discrete")
summary(Ada_20)
# Krok 8: Dodaj zestaw danych testowych
a = subset(test_data, select = -Loan_sanctioned)
b = as.factor(test_data$Loan_sanctioned)
Ada_t20=addtest(Ada_20,a,b)
pred = predict(Ada_t20, a)
table(pred, b)
# Krok 9: Rysuj Ada_t20
plot(Ada_t20,TRUE,TRUE)
# Krok 10: Spróbuj z 50 iteracjami
Ada_50=ada(x,y,iter=50,nu=1,loss="logistic", type="discrete")
summary(Ada_50)
Ada_t50=addtest(Ada_50,a,b)
pred = predict(Ada_t50, a)
table(pred, b)
#Plot Ada_50
plot(Ada_t50,TRUE,TRUE)
#Krok 11: Spróbuj uŋyæ róŋnych iteracji, takich jak iter = 100.500.1000, aby sprawdziæ dokģadnoķæ i napraw model.frame ()
; •